JDK(六)JDK1.8源码分析【集合】LinkedHashMap
本文转载自joemsu,原文连接 【JDK1.8】JDK1.8集合源码阅读——LinkedHashMap
LinkedHashMap的数据结构
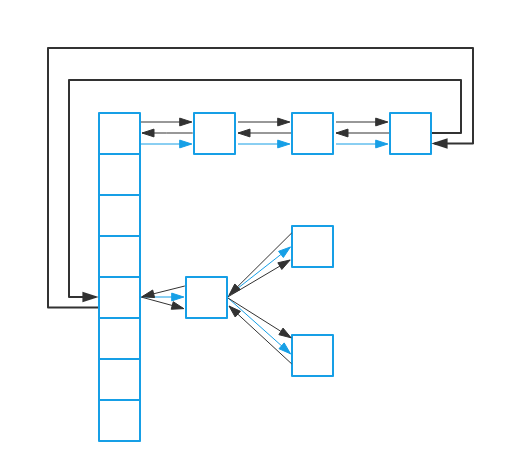
可以从上图中看到,LinkedHashMap数据结构相比较于HashMap来说,添加了双向指针,分别指向前一个节点——before和后一个节点——after,从而将所有的节点已链表的形式串联一起来,从名字上来看LinkedHashMap与HashMap有一定的联系,实际上也确实是这样,LinkedHashMap继承了HashMap,重写了HashMap的一部分方法,从而加入了链表的实现。
本节我们将结合HashMap的部分源码一起分析一下LinkedHashMap。
LinkedHashMap的继承关系
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V>
LinkedHashMap的成员变量
// 用于指向双向链表的头部
transient LinkedHashMap.Entry<K,V> head;
//用于指向双向链表的尾部
transient LinkedHashMap.Entry<K,V> tail;
/**
* 用来指定LinkedHashMap的迭代顺序,
* true则表示按照基于访问的顺序来排列,意思就是最近使用的entry,放在链表的最末尾
* false则表示按照插入顺序来
*/
final boolean accessOrder;
注意:accessOrder的final关键字,说明我们要在构造方法里给它初始化。
LinkedHashMap的构造方法
跟HashMap的构造方法类似,里面唯一的区别就是添加了前面提到的accessOrder,默认赋值为false——按照插入顺序来排列
//多了一个 accessOrder的参数,用来指定按照LRU排列方式还是顺序插入的排序方式
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
LinkedHashMap的get()方法
public V get(Object key) {
Node<K,V> e;
//调用HashMap的getNode的方法,详见上一篇HashMap源码解析
if ((e = getNode(hash(key), key)) == null)
return null;
//在取值后对参数accessOrder进行判断,如果为true,执行afterNodeAccess
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
从上面的代码可以看到,LinkedHashMap的get方法,调用HashMap的getNode方法后,对accessOrder的值进行了判断,我们之前提到:
accessOrder为true则表示按照基于访问的顺序来排列,意思就是最近使用的entry,放在链表的最末尾
由此可见,afterNodeAccess(e)就是基于访问的顺序排列的关键,让我们来看一下它的代码:
//此函数执行的效果就是将最近使用的Node,放在链表的最末尾
void afterNodeAccess(Node<K,V> e) {
LinkedHashMap.Entry<K,V> last;
//仅当按照LRU原则且e不在最末尾,才执行修改链表,将e移到链表最末尾的操作
if (accessOrder && (last = tail) != e) {
//将e赋值临时节点p, b是e的前一个节点, a是e的后一个节点
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
//设置p的后一个节点为null,因为执行后p在链表末尾,after肯定为null
p.after = null;
//p前一个节点不存在,情况一
if (b == null) // ①
head = a;
else
b.after = a;
if (a != null)
a.before = b;
//p的后一个节点不存在,情况二
else // ②
last = b;
//情况三
if (last == null) // ③
head = p;
//正常情况,将p设置为尾节点的准备工作,p的前一个节点为原先的last,last的after为p
else {
p.before = last;
last.after = p;
}
//将p设置为尾节点
tail = p;
// 修改计数器+1
++modCount;
}
}
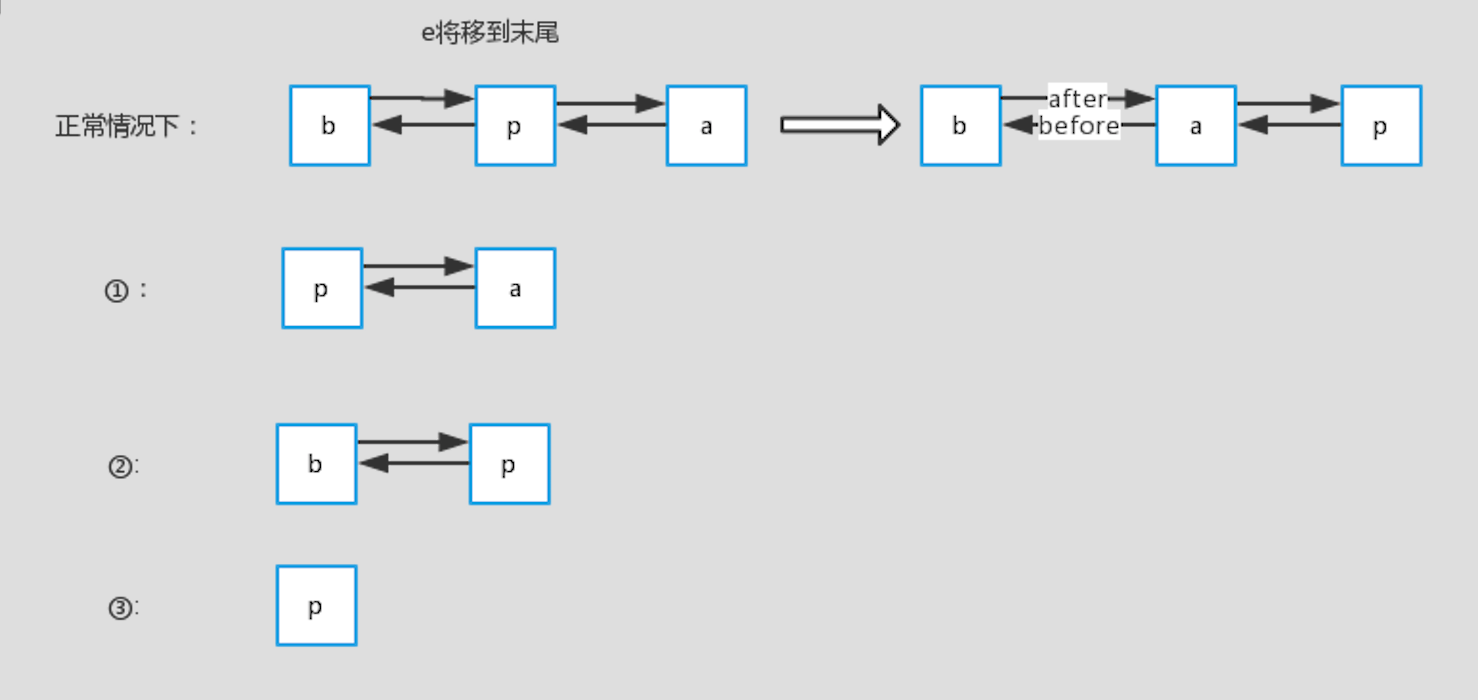
标注的情况如下图所示(特别说明一下,这里是显示链表的修改后指针的情况,实际上在桶里面的位置是不变的,只是前后的指针指向的对象变了):
下面来简单说明一下:
正常情况下:查询的p在链表中间,那么将p设置到末尾后,它原先的前节点b和后节点a就变成了前后节点;
- 情况一:p为头部,前一个节点b不存在,那么考虑到p要放到最后面,则设置p的后一个节点a为head;
- 情况二:p为尾部,后一个节点a不存在,那么考虑到统一操作,设置last为b;
情况三:p为链表里的第一个节点,head=p。
LinkedHashMap的put()方法
接下来,让我们来看一下LinkedHashMap是怎么插入Entry的:LinkedHashMap的put方法调用的还是HashMap里的put,不同的是重写了里面的部分方法:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
...
tab[i] = newNode(hash, key, value, null);
...
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
...
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
...
afterNodeAccess(e);
...
afterNodeInsertion(evict);
return null;
}
这里省略了部分代码,LinkedHashMap将其中newNode方法以及之前设置下的钩子方法afterNodeAccess和afterNodeInsertion进行了重写,从而实现了加入链表的目的:
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
//秘密就在于 new的是自己的Entry类,然后调用了linkedNodeLast
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
//顾名思义就是把新加的节点放在链表的最后面
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
//将tail给临时变量last
LinkedHashMap.Entry<K,V> last = tail;
//把new的Entry给tail
tail = p;
//若没有last,说明p是第一个节点,head=p
if (last == null)
head = p;
//否则就把p的before指针指向last,last的after指针指向p
else {
p.before = last;
last.after = p;
}
}
//这里把TreeNode的重写也加了进来,因为putTreeVal里有调用了这个
TreeNode<K,V> newTreeNode(int hash, K key, V value, Node<K,V> next) {
TreeNode<K,V> p = new TreeNode<K,V>(hash, key, value, next);
linkNodeLast(p);
return p;
}
//插入后把最老的Entry删除,不过removeEldestEntry总是返回false,所以不会删除,估计又是一个钩子方法给子类用的
void afterNodeInsertion(boolean evict) {
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
总结:设计者灵活的运用了Override,以及设置的钩子方法,实现了双向链表。
LinkedHashMap的remove()方法
remove里面也设置了一个钩子方法:
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
...
//node即是要删除的节点
afterNodeRemoval(node);
...
}
void afterNodeRemoval(Node<K,V> e) {
//与afterNodeAccess一样,记录e的前后节点b,a
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
//p已删除,前后指针都设置为null,便于GC回收
p.before = p.after = null;
//与afterNodeAccess一样类似,一顿判断,然后b,a互为前后节点
if (b == null)
head = a;
else
b.after = a;
if (a == null)
tail = b;
else
a.before = b;
}
JDK(六)JDK1.8源码分析【集合】LinkedHashMap的更多相关文章
- 【集合框架】JDK1.8源码分析之LinkedHashMap(二)
一.前言 前面我们已经分析了HashMap的源码,已经知道了HashMap可以用在哪种场合,如果这样一种情形,我们需要按照元素插入的顺序来访问元素,此时,LinkedHashMap就派上用场了,它保存 ...
- 【集合框架】JDK1.8源码分析HashSet && LinkedHashSet(八)
一.前言 分析完了List的两个主要类之后,我们来分析Set接口下的类,HashSet和LinkedHashSet,其实,在分析完HashMap与LinkedHashMap之后,再来分析HashSet ...
- 【集合框架】JDK1.8源码分析之HashMap(一) 转载
[集合框架]JDK1.8源码分析之HashMap(一) 一.前言 在分析jdk1.8后的HashMap源码时,发现网上好多分析都是基于之前的jdk,而Java8的HashMap对之前做了较大的优化 ...
- 【集合框架】JDK1.8源码分析之ArrayList详解(一)
[集合框架]JDK1.8源码分析之ArrayList详解(一) 一. 从ArrayList字表面推测 ArrayList类的命名是由Array和List单词组合而成,Array的中文意思是数组,Lis ...
- 集合之TreeSet(含JDK1.8源码分析)
一.前言 前面分析了Set接口下的hashSet和linkedHashSet,下面接着来看treeSet,treeSet的底层实现是基于treeMap的. 四个关注点在treeSet上的答案 二.tr ...
- 集合之LinkedHashSet(含JDK1.8源码分析)
一.前言 上篇已经分析了Set接口下HashSet,我们发现其操作都是基于hashMap的,接下来看LinkedHashSet,其底层实现都是基于linkedHashMap的. 二.linkedHas ...
- 集合之HashSet(含JDK1.8源码分析)
一.前言 我们已经分析了List接口下的ArrayList和LinkedList,以及Map接口下的HashMap.LinkedHashMap.TreeMap,接下来看的是Set接口下HashSet和 ...
- JUC源码分析-集合篇(六)LinkedBlockingQueue
JUC源码分析-集合篇(六)LinkedBlockingQueue 1. 数据结构 LinkedBlockingQueue 和 ConcurrentLinkedQueue 一样都是由 head 节点和 ...
- JUC源码分析-集合篇:并发类容器介绍
JUC源码分析-集合篇:并发类容器介绍 同步类容器是 线程安全 的,如 Vector.HashTable 等容器的同步功能都是由 Collections.synchronizedMap 等工厂方法去创 ...
- JUC源码分析-集合篇(三)ConcurrentLinkedQueue
JUC源码分析-集合篇(三)ConcurrentLinkedQueue 在并发编程中,有时候需要使用线程安全的队列.如果要实现一个线程安全的队列有两种方式:一种是使用阻塞算法,另一种是使用非阻塞算法. ...
随机推荐
- 使用javascript调用android代码
1.使用webview对象的addJavascriptInterface方法 2.addJavascriptInterface方法有两个参数,第一个参数就是我们一般会实现一个自己的类,类里面提供我们要 ...
- Css选择器(上) 让样式无孔不入
css选择器 一个可以选择样式的工具, 这里适用于无论是内部代码还是外部引用 abc.css 这类型的文件. 基本选择器*{ } 就是一个简单的*, 代表应用于全部. 不适合于个性 ...
- Java 社区论坛 - Sym 1.5.0 发布
简介 Sym 是一个用 Java 写的实时论坛,欢迎来 体验!(如果你需要搭建一个企业内网论坛,请使用 SymX) 非常详细的 Sym 功能点脑图 如果你在搭建或者二次开发时碰到问题,欢迎加 Q 群 ...
- Evernote Markdown Sublime实现
版权声明: 欢迎转载,但请保留文章原始出处 作者:GavinCT 出处:http://www.cnblogs.com/ct2011/p/3996164.html Evernote无法实现markdow ...
- Alaya Webdav Server 0.0.10 发布
Alaya Webdav Server 0.0.10 修复了很多 bug,Webdav 'Copy' 可以使用了. Alaya 是一个提供 WebDAV 支持的 Web 服务器,支持 HTTPS 和 ...
- 通过注解实现Spring 声明式事务管理
小Alan接着上一篇Spring事务管理入门与进阶做一些补充,如果对Spring事务管理还不了解的可以看看上一篇文章. 实例 在我们开始之前,至少有两个数据库表是至关重要的,在事务的帮助下,我们可以实 ...
- PRINCE2认证与其他项目管理认证标准有何不同?
国际项目管理协会 (IPMA)根据国际能力基线建立了一种国际公认的标准,并由其各国协会译成各国语言.这是IPMA四级证书的基础,现在已在全世界推广.可喜的是,PRINCE2与这个标准高度一致. 美国项 ...
- python 待关注库
Python待关注库 GUI 图形 Tkinter/wxPython/PyGTK/PyQt/PySide Web框架 django/web2py/flask/bottle/tornadoweb/web ...
- Java多线程学习笔记(二)
三 多线程执行的共享数据和非共享数据: 共享数据:就是每个线程执行的时候共享数据使用,比如这个线程一个为5的数据,减少为4之后,另一个线程执行拿到的数据是4,两个线程执行的数据是共享的. 非共享数据: ...
- HTML5盒子模型。
盒子模型. 盒子由 margin.border.padding.content 四部分组成. margin :外边距 border:边框 padding:内边距 (内容与边框的距离) content: ...