二叉树、红黑树、伸展树、B树、B+树
好多树啊,程序猿砍树记,吼吼。
许多程序要解决的关键问题是:快速定位特定排序项的能力。
第一类:散列
第二类:字符串查找
第三类:树算法
树算法可以在辅助存储器中存储大量的数据。
二叉树、红黑树和伸展树主要适用于内存中的工作
而B树打算用于辅助存储器,比如硬盘。
二叉树
二叉树是最简单的树算法,但是构成了其他树算法的基础。
二叉树至少包含三个数据项:
两个指向其他节点的指针以及一些用户数据。
二叉树的根是没有父节点的节点。
任何给定节点的高度或深度是将其与根节点隔开的节点数。
二叉树除了拓扑结构外,另一个重要的特点就是它的遍历顺序(traversal order)。
你往往希望访问树中的所有节点,确保以某种一致的顺序只访问每个节点一次。
有三种那可能的遍历顺序,它们都是递归式的:
前序(preorder)
中序(inorder)
后序(postorder)
非常重要的是,访问一个子节点意味着将递归地访问该子节点的所有子节点。
RPN Rerverse Polish Notation,逆波兰表示法
当使用二叉树存储大量数据时,只需遵循一条简单的规则:当使用中序遍历时,在每个节点中存储的数据的键将具有递增的顺序。
这种被称为二叉查找树(binary search tree)
所有左子节点所具有的键都在其父节点之前;而右子节点所具有的键都至少等于父节点的键。
二叉查找树的5种基本操作:
树创建;
树查找;
节点插入;
节点删除;
树遍历。
二叉查找树删除考虑的情况要多一些。
二叉查找树的性能
如果有N个随机分布的节点,平均高度应该为lgN。
通过加载一组数据而得到的二叉查找树的形状不仅依赖于数据项,而且依赖于加载它们的顺序。这种类型的树没有内在的机制用于阻止子树之间的失衡。
AVL树
有多种方法可以构建平衡树。
比如如果知道了树中数据项的使用频率,可以构建加权平均树(weight-balanced tree)。
不过一般都假定数据项的使用频率相同。在这种情况下,将强制树是高度平衡的(height-balanced);
也就是说,任何给定的子树都不允许比其兄弟子树高得太多。
AVL树是一种遵守以下规则的二叉查找树:
任何给定节点的子树的高度最多相差1。(这个应该如何实现呢)
这个规则要求我们把树视作森林,并且在整棵树中实施该规则。
虽然该规则听起来有些麻烦,但是事实证明可以通过只执行树的局部操作来维护一颗平衡树。
对于二叉查找树的算法,节点插入和删除以完全相同的方式开始。
在插入或删除之后,如果引入了失衡情况,就必须重新平衡树。
两种修复失衡的操作:
单旋转
双旋转
AVL的规则作用是:确保树永远不会在实质上变为失衡状态,并且可以证明具有N个节点的AVL树的高度将和lgN成正比。
实际上AVL的实现比较麻烦,由于必须考虑很多特殊的情况,并且存在以下可能性:
树的重构可能需要进行多次旋转,以修复由于以前的旋转而产生新的失衡。
红黑树
实现AVL树更容易的一种方式是红黑树(red-black tree)的概念。
红黑树是二叉查找树,不过,它利用了两个新概念。
第一,数据只存储在叶节点中(leaf)。
也就是只有不带子节点的节点才会包含实际的数据,内部节点只用于引用。
第二,将每个节点都视作带有红色或者黑色。
颜色的确定规则为:
所有的叶节点都是黑色的
沿着从根出发的任何路径上都不允许出现2个连续的红色节点。
树的所有叶节点都必须具有相同的黑色深度,它被定义为叶节点与根节点之间的黑色节点的数量减1。
伸展树
伸展树是第三种二叉树的变种。
在节点中没有存储平衡信息或节点颜色的信息。
作为替代,伸展树是链表维护的“上移”方法与二叉树之间的交叉。
无需像我们对红黑树所做的那样尝试保持树处于平衡状态,将实现的是另一种恒定重排的形式:每次访问树时,都使用双旋转和单旋转重排树,
使得访问过的节点位于树的根。
B树
上面描述的几种树算法对于完全可以在内存中维护的数据工作得很好。
否则需要一种适用于磁盘存储器的树算法:
与访问内存中数据的速度比,访问磁盘上的数据非常慢
最好相对于相当大的数据块执行读、写操作。实际上,一次读入越多,就会做得更好。
磁盘存储器的限制意味着必须尝试最高效地使用大块磁盘存储器,应围绕这个来组织算法,并且就将多份数据放入每个块中。
所有的B树都利用了两种截然不同的块:索引块和数据块。
数据块是B树的叶节点,并且所有的数据都存储于其中。
索引块是上层块,它们只包含允许程序描绘从根到数据块中的想要记录的路径所需的足够信息。
B树的关键特性如下:
所有数据块都位于相同层
所有的索引块和数据块都包含某个最低限度的数据量。
索引块中的数据项只是键。
这些特性使得在某种意义上B树至少是平衡的。
由于所有的数据都处于树中的相同深度,对于树的各个部分将具有同样快的访问速度。
通常把B树描述为阶d,其中树中的每个节点都包含d~2d个键或记录。
保持B树平衡
当块变得太空或者太满时,就会发生问题。
太满时,必须把块分割成两块,并在块的父块中插入一个新键。一直到根块。
太空时,就会把相邻两个块合并。
实现B树的算法
分割和合并数据块与索引块需要做的工作很复杂,并且充斥着一些特殊情况。
不过通过几个简化假设,可以大大减小复杂性,同时实现一个令人满意的B树例程。
允许可变长度的键
允许可变长度的记录
把索引和数据保存在单独的文件中。
为实现这些特性,同时轻松应对特殊情况,应该做以下假设:
在创建数据集时,必须提供具有最大键的单个记录。不能删除这个记录,这个记录的存在意味着树永远不会为空。
树将具有固定高度,并且在创建B树时定义这个高度。
这两条假设的实际效果是:空树将包含多个索引块层以及一个最大的数据记录。
高度为4的树甚至对于最苛刻的应用程序也绰绰有余。
B树源代码模块
B树头文件
创建B树
打开现有的数据集
操作数据集
阻塞缓冲
驱动程序头部
示例驱动程序
B树的源程序好复杂啊
B+树
这里有个示例,我擦,牛叉啊
https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
这是我试的,而且还是动态效果

http://www.cburch.com/cs/340/reading/btree/
下面关于B+树的操作图片都是来源于这个网站
如果值都按照顺序排列的话,大部分的查询过程将变得很快。
但是把所有的的数据按顺序一行接一行的存储在表中是不切实际的,因为在每次删除或者插入的时候要重写整个表。
这使得我们想要把数据以树的方式存储。
首先考虑到的是像红黑树这样的平衡二叉搜索树(balanced binary search tree),但是这对于存储在磁盘上的数据库而言意义不大。
你会发现,磁盘的工作方式是通过一次读写数据的整个块,典型的是一次512字节或者4kb。而二叉搜索树的一个节点只用到这些数据中的很少一部分,
因此需要找到一种和磁盘工作方式更为匹配的算法。
由于B+树,由于在一个节点中可以存储d个子代和多达d-1个键。每个引用可以看作在节点的两个键之间的值。
下面是一个d=4的一个很小的树。

一个B+树需要每个叶子和根节点的距离相同,正如图中所示,其中搜索任何11个值中的一个只需涉及到从磁盘中载入3个节点(根块,第二层的块,和叶子)。
实际上,d可以更大,大到可以占满整个块。假设一个块是4kb,我们的键是4个字节的整数,每个引用是6字节文件的偏移量。
那么我们可以选择一个值使得4(d-1) + 6d ≤ 4096;结果是d ≤ 410。
一颗B+树维持下面不变的特性:
- 每个节点的引用比它的键要多1
- 所有的叶子与根节点之间的距离是相同的
- 对于每个有k个键值的非叶节点N:在第一个孩子的子树中所有的键值都要小于N的第一个键;并且在第i个孩子的子树中的键值都是在节点N的第(i-1)个键和第i个键之间。
- 根节点至少有两个娃
- 每个非叶节点和非根节点至少包含floor(d/2)个娃
- 每个叶子至少包含floor(d/2)个键
- 在叶子中出现的每个键,以从左到右有序排列
插入算法
- 如果节点中有空位置,那么插入键/引用对到节点中
- 如果节点已经满了,则将节点分割为两个结点,对半分配键值到两个节点。如果这个节点是叶子,取出第二个节点的最小值,并继续插入算法,然后把这个值插入到父节点。如果节点不是叶子,排除分割时中间的值,并重复插入算法,把排出的这个值插入到父节点。
Initial:
Insert 20: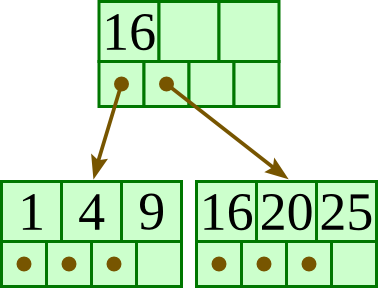
Insert 13: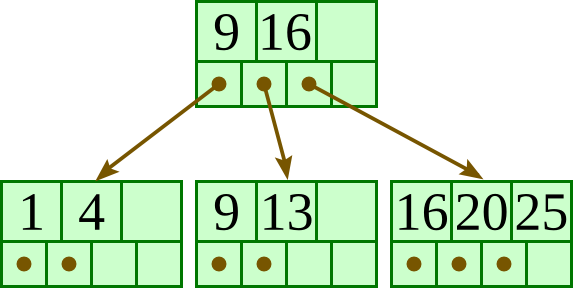
Insert 15: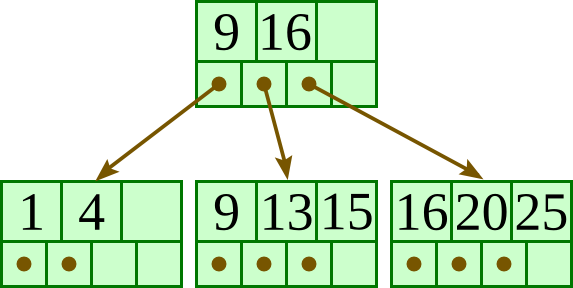
Insert 10:
Insert 11: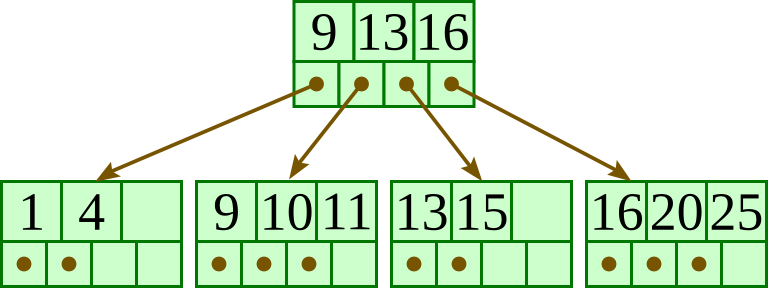
Insert 12: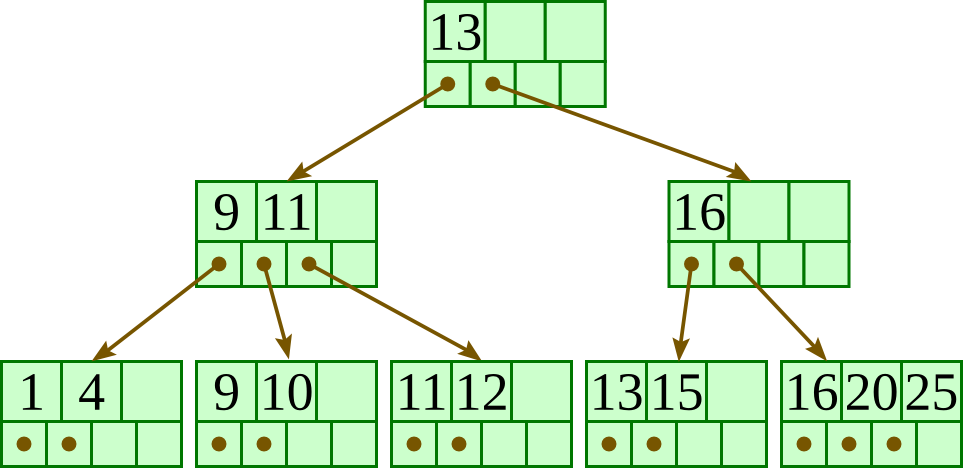
删除算法
- 移除节点中需要删除的键和对应的引用
- 如果节点仍然有足够的键和引用来满足B+树的特征,则可以停止
- 如果节点的键太少了以至于满足不了不变性,如果它旁边同一层中最接近的节点有多余的,则重新分配这些键给这个节点和邻近节点。修复上一层代表这些节点的键,有不同的分割点。这里仅仅涉及到上一层键的改变,而不用插入或者删除键。
- 如果节点的键太少了以至于满足不了特性,而旁边的节点也只是恰好够,然后将该节点和它的兄弟节点合并;如果节点是非叶子,我们需要将父节点的分割键整合到一起。在另外的情况下,需要对父节点重复删除算法来移除这些原来用来分隔这些合并的节点的键,直到父节点是根节点,然后从根节点移除最后的键,直到合并的节点成为新的根节点(然后这棵树的高度要比原来的少1层)。
Initial:
Delete 13: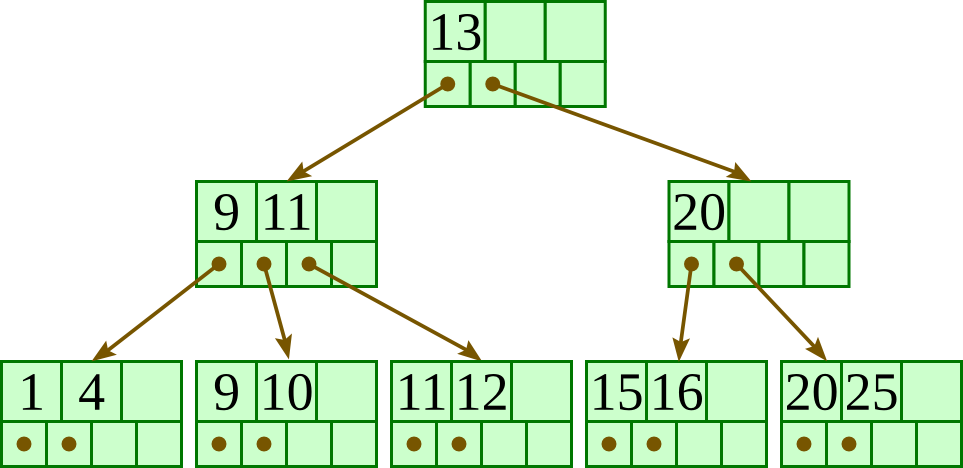
Delete 15: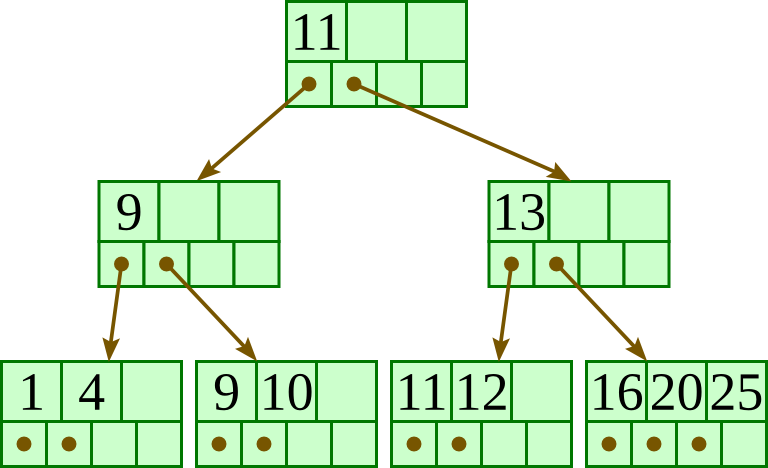
Delete 1: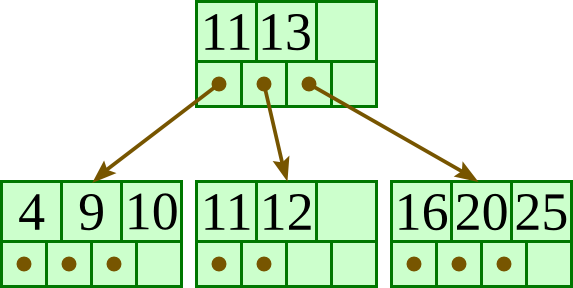
二叉树、红黑树、伸展树、B树、B+树的更多相关文章
- 树形结构_红黑树:平衡2X 哈夫曼树:最优2X
红黑树:平衡2X 哈夫曼树:最优2X 红黑树 :TreeSet.TreeMap 哈夫曼树 1. 将w1.w2.…,wn看成是有n 棵树的森林(每棵树仅有一个结点): 2. 在森林中选出根结点的权值最小 ...
- 有序的数据结构中:内存操作红黑树快,磁盘操作b+树快
红黑树常用于存储内存中的有序数据,增删很快,b+树常用于文件系统和数据库索引,因为b树的子节点大于红黑树,红黑树只能有2个子节点,b树子节点大于2,子节点树多这一特点保证了存储相同大小的数据,树的高度 ...
- 红黑树(RB-tree)比AVL树的优势在哪?
1. 如果插入一个node引起了树的不平衡,AVL和RB-Tree都是最多只需要2次旋转操作,即两者都是O(1):但是在删除node引起树的不平衡时,最坏情况下,AVL需要维护从被删node到root ...
- 二叉树,AVL树和红黑树
为了接下来能更好的学习TreeMap和TreeSet,讲解一下二叉树,AVL树和红黑树. 1. 二叉查找树 2. AVL树 2.1. 树旋转 2.1.1. 左旋和右旋 2.1.2. 左左,右右,左右, ...
- 排序二叉树、平衡二叉树、红黑树、B+树
一.排序二叉树(Binary Sort Tree,BST树) 二叉排序树,又叫二叉搜索树.有序二叉树(ordered binary tree)或排序二叉树(sorted binary tree). 1 ...
- 吐血整理:二叉树、红黑树、B&B+树超齐全,快速搞定数据结构
前言 没有必要过度关注本文中二叉树的增删改导致的结构改变,规则操作什么的了解一下就好,看不下去就跳过,本文过多的XX树操作图片纯粹是为了作为规则记录,该文章主要目的是增强下个人对各种常用XX树的设计及 ...
- B-Tree 漫谈 (从二叉树到二叉搜索树到平衡树到红黑树到B树到B+树到B*树)
关于B树的学习还是需要做点笔记. B树是为磁盘或者其他直接存取辅助存储设备而设计的一种平衡查找树.B树与红黑树的不同在于,B树可以有很多子女,从几个到几千个.比如一个分支因子为1001,高度为2的B树 ...
- AVL树,红黑树
AVL树 https://baike.baidu.com/item/AVL%E6%A0%91/10986648 在计算机科学中,AVL树是最先发明的自平衡二叉查找树.在AVL树中任何节点的两个子树的高 ...
- 二叉排序树、平衡二叉树、B树&B+树、红黑树的设计动机、缺陷与应用场景
之前面试时曾被问到"如果实现操作系统的线程调度应该采用什么数据结构?",因为我看过ucore的源码,知道ucore是采用斜堆的方式实现的,可以做到O(n)的插入.O(1)的查找.我 ...
- AVL树与红黑树(R-B树)的区别与联系
AVL树(http://baike.baidu.com/view/593144.htm?fr=aladdin),又称(严格)高度平衡的二叉搜索树.其他的平衡树还有:红黑树.Treap.伸展树.SBT. ...
随机推荐
- Chrome 编译错误汇总
由于各种你懂的原因,訪问google的服务总是出错,先是hosts不工作.代理也不好使,最后最终能够短暂訪问了.我的版本号还是採用svn维护的,直接svn update也不行.试试git吧,一晚上才下 ...
- HDUOJ-----4510 小Q系列故事——为什么时光不能倒流
小Q系列故事——为什么时光不能倒流 Time Limit: 300/100 MS (Java/Others) Memory Limit: 65535/32768 K (Java/Others)T ...
- HDUOJ--Holding Bin-Laden Captive!
Holding Bin-Laden Captive! Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Ja ...
- nyoj------擅长排列的小明
擅长排列的小明 时间限制:1000 ms | 内存限制:65535 KB 难度:4 描述 小明十分聪明,而且十分擅长排列计算.比如给小明一个数字5,他能立刻给出1-5按字典序 ...
- CoreData数据库升级
如果IOS App 使用到CoreData,并且在上一个版本上有数据库更新(新增表.字段等操作),那在覆盖安装程序时就要进行CoreData数据库的迁移,具体操作如下: 1.选中你的mydata.xc ...
- jmeter ---常用字符串相关函数
主要的函数如下: 1.将字符串转为大写或小写: ${__lowercase(Hello,)} ${__uppercase(Hello,)}2.生成字符串: __RandomString函数 3.取 ...
- Access数据库的连接字符串
<!-- Access2007 --> Provider=Microsoft.ACE.OLEDB.12.0;Data Source=data\myAccess_db.accdb;Persi ...
- Linux内核scatterlist API介绍
1. 前言 我们在那些需要和用户空间交互大量数据的子系统(例如MMC[1].Video.Audio等)中,经常看到scatterlist的影子.对我们这些“非英语母语”的人来说,初见这个词汇,脑袋瞬间 ...
- iOS8开发之iOS8的UIAlertController
在iOS8之前用UIActionSheet和UIAlertView来提供button选择和提示性信息,比方UIActionSheet能够这样写: UIActionSheet *actionSheet ...
- Datatable.Select()用法简介
DataTable是我们在进行开发时经常用到的一个类,并且经常需要对DataTable中的数据进行筛选等操作,下面就介绍一下Datatable中经常用到的一个方法——Select,微软提供了四个函数的 ...