MongoDb Mmap引擎分析
版权声明:本文由孔德雨原创文章,转载请注明出处:
文章原文链接:https://www.qcloud.com/community/article/137
来源:腾云阁 https://www.qcloud.com/community
MongoDB在3.0之前一直使用mmap引擎作为默认存储引擎,本篇从源码角度对mmap引擎作分析,业界一直以来对10gen用mmap实现存储引擎褒贬不一,本文对此不作探讨。
存储按照db来分目录, 每个db目录下有 .ns文件 {dbname}.0, {dbname}.1 等文件。journal 目录下存放的是WAL(write ahead log) 用于故障恢复。 目录结构如下:
db
|------journal
|----_j.0
|----_j.1
|----lsn
|------local
|----local.ns
|----local.0
|----local.1
|------mydb
|----mydb.ns
|----mydb.0
|----mydb.1
这三类文件构成了mmap引擎的持久化单元。本文主要从代码层次分析每类文件的结构。
Namespace元数据管理
.ns文件映射
mmap引擎加载某个database时,首先初始化namespaceIndex,namespaceIndex相当于database的元数据入口。mongo/db/storage/mmap_v1/catalog/namespace_index.cpp
89 DurableMappedFile _f{MongoFile::Options::SEQUENTIAL};
90 std::unique_ptr<NamespaceHashTable> _ht;
154 const std::string pathString = nsPath.string();
159 _f.open(pathString);
232 p = _f.getView();
242 _ht.reset(new NamespaceHashTable(p, (int)len, "namespace index"));
如上,创建对.ns文件的mmap,将内存的view直接映射到hashtable上(不不进行任何解析)。因此.ns文件是一个hashtable的内存镜像。
hashtable的key-value关系string->NamespaceDetails(namespace_details.h),采用的是开放寻址hash。
39 int NamespaceHashTable::_find(const Namespace& k, bool& found) const {
46 while (1) {
47 if (!_nodes(i).inUse()) {
48 if (firstNonUsed < 0)
49 firstNonUsed = i;
50 }
51
52 if (_nodes(i).hash == h && _nodes(i).key == k) {
53 if (chain >= 200)
54 log() << "warning: hashtable " << _name << " long chain " << std::endl;
55 found = true;
56 return i;
57 }
58 chain++;
59 i = (i + 1) % n;
60 if (i == start) {
62 log() << "error: hashtable " << _name << " is full n:" << n << std::endl;
63 return -1;
64 }
65 if (chain >= maxChain) {
66 if (firstNonUsed >= 0)
67 return firstNonUsed;
68 log() << "error: hashtable " << _name << " max chain reached:" << maxChain << std::endl;
69 return -1;
70 }
71 }
72 }
上述过程是开放式寻址hash的经典的查找过程,如果有冲突,向后跳一格,如果跳到查找的起点依然没有找到可用的空槽,则说明hashtable满了。
元数据内容窥探
一个NamespaceDetails对象对应该db下的某张表的元数据(namespace_index.h),大小为496bytes,mongod默认为.ns文件分配16MB的空间,且.ns文件唯一且不可动态伸缩空间,可以推断出一个mongod实例至多可建表大概30000个。该类有22个字段,重要字段有如下6个。
struct NamespaceDetails {
// extent对应于一个内存连续块,由于mmap,也是文件连续区域。一张表有多个extent。
// 以双向链表的形式组织,firstExtent和lastExtent分别对应extent的首尾指针
DiskLoc firstExtent;
DiskLoc lastExtent;
// 有若干种(26种)按照最小尺寸划分的freelist,
// 表中删除掉的行对应的数据块放到freelist中,按照数据块的尺寸划分为若干规则的freelist。
DiskLoc deletedListSmall[SmallBuckets];
// 兼容旧版本mmap引擎的废弃字段
DiskLoc deletedListLegacyGrabBag;
// 该表是否是capped,capped-table是ring-buffer类型的table,MongoDB中用来存放oplog
int isCapped;
// 和deletedListSmall字段一样,都是freelist的一部分,只是大小不同
DiskLoc deletedListLarge[LargeBuckets];
}
为了便于下文阐述,结合上述对namespaceIndex构建过程的描述与对元数据的注解,笔者先勾勒出如下的元数据结构。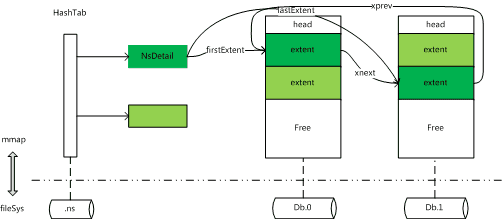
单表结构
上文我们讨论了单表元数据(NamespaceDetails)中重要字段的含义,接下来进行深入探讨。
Extent的组织形式
每张表由若干extent组成,每个extent为一块连续的内存区域(也即连续的硬盘区域),由firstExtent 和 lastExtent 记录首尾位置,每个extent的结构为
/*extents are datafile regions where all the records within the region belong to the same namespace.*/
struct Extent {
DiskLoc myLoc;
DiskLoc xnext; //双向链表中前节点指针
DiskLoc xprev; //双向链表中后节点指针
Namespace nsDiagnstic;
int length;
// 一个Record对应表中的一行,每个extent在物理上由若干地址连续的
// Record组成,但是这些record在逻辑上的前后关系并不等价于物理上
// 的前后关系,first/last Record维护了逻辑上的先后关系,在维护游
// 表迭代时使用
DiskLoc firstRecord;
DiskLoc lastRecord;
char _extentData[4];
}
上述描述的组织结构如下图所示: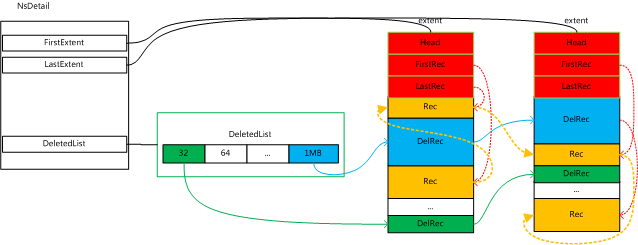
Extent 的分配与回收由ExtentManger管理,ExtentManager 首先尝试从已有文件中分配一个满足条件的连续块,如果没有找到,则生成一个新的{dbname}.i 的文件。
143 void DataFile::open(OperationContext* txn,
144 const char* filename,
145 int minSize,
146 bool preallocateOnly) {
147 long size = _defaultSize();
148
149 while (size < minSize) {
150 if (size < maxSize() / 2) {
151 size *= 2;
152 } else {
153 size = maxSize();
154 break;
155 }
156 }
157
158 if (size > maxSize()) {
159 size = maxSize();
160 }
161
162 invariant(size >= 64 * 1024 * 1024 || mmapv1GlobalOptions.smallfiles);
文件的大小 {dbname}.0的大小默认为64MB。 之后每次新建会扩大一倍,以maxSize(默认为2GB)为上限。
一个extent被分为若干Records,每个Record对应表中的一行(一个集合中的文档),每一张表被RecordStore类封装,并对外提供出CRUD的接口。
Record分配
首先从已有的freelist(上文中提到的deletedBuckets)中分配,每张表按照内存块尺寸维护了不同规格的freelist,每个freelist是一个单向链表,当删除Record时,将record放入对应大小的freelist中。
如下按照从小到大的顺序遍历DeletedBuckets,如果遍历到有空闲且符合大小的空间,则分配:
107 for (myBucket = bucket(lenToAlloc); myBucket < Buckets; myBucket++) {
108 // Only look at the first entry in each bucket. This works because we are either
109 // quantizing or allocating fixed-size blocks.
110 const DiskLoc head = _details->deletedListEntry(myBucket);
111 if (head.isNull())
112 continue;
113 DeletedRecord* const candidate = drec(head);
114 if (candidate->lengthWithHeaders() >= lenToAlloc) {
115 loc = head;
116 dr = candidate;
117 break;
118 }
119 }
上述代码分配出一块尺寸合适的内存块,但是该内存块依然可能比申请的尺寸大一些。mmap引擎在这里的处理方式是:将多余的部分砍掉,并归还给freelist。
133 const int remainingLength = dr->lengthWithHeaders() - lenToAlloc;
134 if (remainingLength >= bucketSizes[0]) {
135 txn->recoveryUnit()->writingInt(dr->lengthWithHeaders()) = lenToAlloc;
136 const DiskLoc newDelLoc = DiskLoc(loc.a(), loc.getOfs() + lenToAlloc);
137 DeletedRecord* newDel = txn->recoveryUnit()->writing(drec(newDelLoc));
138 newDel->extentOfs() = dr->extentOfs();
139 newDel->lengthWithHeaders() = remainingLength;
140 newDel->nextDeleted().Null();
141
142 addDeletedRec(txn, newDelLoc);
143 }
上述分片内存的过程如下图所示: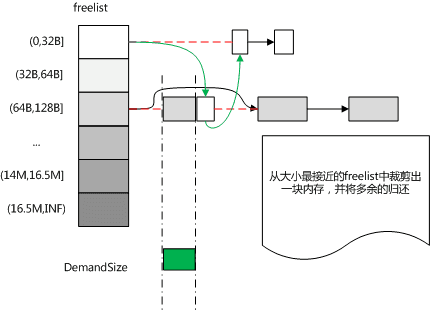
如若从已有的freelist中分配失败,则会尝试申请新的extent,并将新的extent加到尺寸规则最大的freelist中。并再次尝试从freelist中分配内存。
59 const int RecordStoreV1Base::bucketSizes[] = {
...
83 MaxAllowedAllocation, // 16.5M
84 MaxAllowedAllocation + 1, // Only MaxAllowedAllocation sized records go here.
85 INT_MAX, // "oversized" bucket for unused parts of extents.
86 };
87
上述过程为mmap引擎对内存管理的概况,可见每个record在分配时不是固定大小的,申请到的内存块要将多出的部分添加到deletedlist中,record释放后也是链接到对应大小的deletedlist中,这样做时间久了之后会产生大量的内存碎片,mmap引擎也有针对碎片的compact过程以提高内存的利用率。
碎片Compact
compact以命令的形式,暴露给客户端,该命令以collection为维度,在实现中,以extent为最小粒度。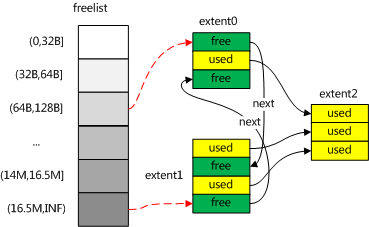
compact整体过程分为两步,如上图,第一步将extent从freelist中断开,第二步将extent中已使用空间copy到新的extent,拷贝过去保证内存的紧凑。从而达到compact的目的。
- orphanDeletedList 过程
将collection 对应的namespace 下的deletedlist 置空,这样新创建的record就不会分配到已有的extent。443 WriteUnitOfWork wunit(txn);
444 // Orphaning the deleted lists ensures that all inserts go to new extents rather than
445 // the ones that existed before starting the compact. If we abort the operation before
446 // completion, any free space in the old extents will be leaked and never reused unless
447 // the collection is compacted again or dropped. This is considered an acceptable
448 // failure mode as no data will be lost.
449 log() << "compact orphan deleted lists" << endl;
450 _details->orphanDeletedList(txn);
- 对于每个extent,每个extent记录了首尾record,遍历所有record,并将record插入到新的extent中,新的extent在插入时由于空间不足而自动分配(参考上面的过程),extent重新设置从最小size开始增长。
452 // Start over from scratch with our extent sizing and growth
453 _details->setLastExtentSize(txn, 0);
454
455 // create a new extent so new records go there
456 increaseStorageSize(txn, _details->lastExtentSize(txn), true);
467 for (std::vector<DiskLoc>::iterator it = extents.begin(); it != extents.end(); it++) {
468 txn->checkForInterrupt();
469 invariant(_details->firstExtent(txn) == *it);
470 // empties and removes the first extent
471 _compactExtent(txn, *it, extentNumber++, adaptor, options, stats);
472 invariant(_details->firstExtent(txn) != *it);
473 pm.hit();
474 }
- 在_compactExtent的过程中,该extent的record逐渐被插入到新的extent里,空间逐步释放,当全部record都清理完后,该extent又变成崭新的,没有使用过的extent了。如下图

324 while (!nextSourceLoc.isNull()) {
325 txn->checkForInterrupt();
326
327 WriteUnitOfWork wunit(txn);
328 MmapV1RecordHeader* recOld = recordFor(nextSourceLoc);
329 RecordData oldData = recOld->toRecordData();
330 nextSourceLoc = getNextRecordInExtent(txn, nextSourceLoc);
371 CompactDocWriter writer(recOld, rawDataSize, allocationSize);
372 StatusWith<RecordId> status = insertRecordWithDocWriter(txn, &writer);
398 _details->incrementStats(txn, -(recOld->netLength()), -1);
}
上述即是_compactExtent函数中遍历该extent的record,并插入到其他extent,并逐步释放空间的过程(398行)。
mmap数据回写
上面我们介绍.ns文件结构时谈到.ns文件是通过mmap 映射到内存中的一个hashtable上,这个映射过程是通过DurableMappedFile 实现的。我们看下该模块是如何做持久化的
在mmap 引擎的 finishInit中
252 void MMAPV1Engine::finishInit() {
253 dataFileSync.go();
这里调用 DataFileSync类的定时任务,在backgroud线程中定期落盘
67 while (!inShutdown()) {
69 if (storageGlobalParams.syncdelay == 0) {
70 // in case at some point we add an option to change at runtime
71 sleepsecs(5);
72 continue;
73 }
74
75 sleepmillis(
76 (long long)std::max(0.0, (storageGlobalParams.syncdelay * 1000) - time_flushing));
83 Date_t start = jsTime();
84 StorageEngine* storageEngine = getGlobalServiceContext()->getGlobalStorageEngine();
85
86 dur::notifyPreDataFileFlush();
87 int numFiles = storageEngine->flushAllFiles(true);
88 dur::notifyPostDataFileFlush();
97 }
98 }
flushAllFiles最终会调用每个memory-map-file的flush方法
245 void MemoryMappedFile::flush(bool sync) {
246 if (views.empty() || fd == 0 || !sync)
247 return;
248
249 bool useFsync = !ProcessInfo::preferMsyncOverFSync();
250
251 if (useFsync ? fsync(fd) != 0 : msync(viewForFlushing(), len, MS_SYNC) != 0) {
252 // msync failed, this is very bad
253 log() << (useFsync ? "fsync failed: " : "msync failed: ") << errnoWithDescription()
254 << " file: " << filename() << endl;
255 dataSyncFailedHandler();
256 }
257 }
fsync vs msync
不管调用fsync 还是msync落盘,我们的预期都是内核会高效的查找出数据中的脏页执行写回,但是根据https://jira.mongodb.org/browse/SERVER-14129 以及下面的代码注释中
在有些操作系统上(比如SmartOS与 Solaris的某些版本), msync并不能高效的寻找脏页,因此mmap引擎在这里对操作系统区别对待了。
208 // On non-Solaris (ie, Linux, Darwin, *BSD) kernels, prefer msync.
209 // Illumos kernels do O(N) scans in memory of the page table during msync which
210 // causes high CPU, Oracle Solaris 11.2 and later modified ZFS to workaround mongodb
211 // Oracle Solaris Bug:
212 // 18658199 Speed up msync() on ZFS by 90000x with this one weird trick
213 bool preferMsyncOverFSync;
MongoDb Mmap引擎分析的更多相关文章
- MongoDB存储引擎选择
MongoDB存储引擎选择 MongoDB存储引擎构架 插件式存储引擎, MongoDB 3.0引入了插件式存储引擎API,为第三方的存储引擎厂商加入MongoDB提供了方便,这一变化无疑参考了MyS ...
- [mongodb] MMAP 和wiredTiger 的比较
mongodb 现在有两款存储引擎 MMAPv1 和 WireTiger,当然了除了这两款存储引擎还有其他的存储引擎了. 如: 内存引擎:现在的mongodb 版本中已经有了,主要的cache 服务 ...
- MongoDB存储引擎(上)——MMAPv1
3.0版本以前,MongoDB只有一个存储引擎——MMAP,MongoDB3.0引进了一个新的存储引擎——WiredTiger,同时对原有的MMAP引擎进行改进,产生MMAPv1存储引擎,并将其设置为 ...
- MongoDB学习笔记(五、MongoDB存储引擎与索引)
目录: mongoDB存储引擎 mongoDB索引 索引的属性 MongoDB查询优化 mongoDB存储引擎: 目前mongoDB的存储引擎分为三种: 1.WiredTiger存储引擎: a.Con ...
- MongoDB 存储引擎选择
MongoDB存储引擎选择 MongoDB存储引擎构架 插件式存储引擎, MongoDB 3.0引入了插件式存储引擎API,为第三方的存储引擎厂商加入MongoDB提供了方便,这一变化无疑参考了MyS ...
- MongoDB 存储引擎和数据模型设计
标签: MongoDB NoSQL MongoDB 存储引擎和数据模型设计 1. 存储引擎 1.1 存储引擎是什么 1.2 MongoDB中的默认存储引擎 2. 数据模型设计 2.1 内嵌和引用 2. ...
- Freetype字体引擎分析与指南
Freetype字体引擎分析与指南,很不错的一篇教程,推荐!!
- MongoDB Sharding 机制分析
MongoDB Sharding 机制分析 MongoDB 是一种流行的非关系型数据库.作为一种文档型数据库,除了有无 schema 的灵活的数据结构,支持复杂.丰富的查询功能外,MongoDB 还自 ...
- MongoDB源码分析——mongo与JavaScript交互
mongo与JavaScript交互 源码版本为MongoDB 2.6分支 之前已经说过mongo是MongoDB提供的一个执行JavaScript脚本的客户端工具,执行js其实就是一个js和 ...
随机推荐
- 数据库——IN、ANY、SOME 和 ALL 操作符的使用
sql中all,any,some用法 简介: --All:对所有数据都满足条件,整个条件才成立,例如:5大于所有返回的id select * from #A where 5>All(select ...
- 【高可用HA】Apache (2) —— Mac下安装多个Apache Tomcat实例
Mac 下安装多个Apache Tomcat实例 tomcat版本:tomcat-8.0.29 参考来源: Installing Tomcat 7.0.x on OS X 在mac系统安装Apache ...
- datanode与namenode的通信
在分析DataNode时, 因为DataNode上保存的是数据块, 因此DataNode主要是对数据块进行操作. A. DataNode的主要工作流程1. 客户端和DataNode的通信: 客户端向D ...
- kettle7.1无法从Mongo中读取数据
今天使用kettle读取mongo数据库时,刚开始一直无法读取数据: 在配置项中偶然选择了一个nearest然后成功了,麻蛋. 然后百度查询了下Read Reference是干嘛的,原来是读取源的模式 ...
- MongoDB 集群搭建(主从复制、副本及)(五)
六:架构管理 mongodb的主从集群分为两种: 1:master-Slave 复制(主从) --从server不会主动变成主server,须要设置才行 2:replica Sets 复制(副本 ...
- iOS边练边学--UITabBarController的简单使用
一.UITabBarController的使用步骤 初始化UITabBarController 设置UIWindow的rootViewController为UITabBarController 根据具 ...
- java判断邮件是否发送成功
http://www.cnblogs.com/winner-0715/p/5136392.html
- PCL,VTK及其依赖库的编译-十分详细
所有库的编译教程都很详细,全都上传到百度文库. 1.VS2013-Qt5.5.1-动态编译-VTK7.0.0http://wenku.baidu.com/view/749528a433687e21ae ...
- SQL Server 查询分析器键盘快捷方式
下表列出 SQL Server 查询分析器提供的所有键盘快捷方式. 活动 快捷方式 书签:清除所有书签. CTRL-SHIFT-F2 书签:插入或删除书签(切换). CTRL+F2 书签:移动到下一个 ...
- javascript时钟代码 DEMO-002
转载自:http://www.cnblogs.com/Mygirl/archive/2012/03/30/2425832.html 正常时间显示 复制代码 <SCRIPT language=ja ...