一. kafka 入门
一、基本概念
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据.这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素.
- 通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
- 高吞吐量[2] :即使是非常普通的硬件Kafka也可以支持每秒数百万[2] 的消息。
- 支持通过Kafka服务器和消费机集群来分区消息。
- 支持Hadoop并行数据加载。
kafka对消息保存时根据Topic进行归类,发送消息者成为Producer,消息接受者成为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)成为broker。无论是kafka集群,还是producer和consumer都依赖于zookeeper来保证系统可用性集群保存一些meta信息。
术语:
- BrokerKafka集群包含一个或多个服务器,这种服务器被称为broker[5]
- Topic每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)。一个Topic可以认为是一类消息,每个topic将被分成多个partition(区),每个partition在存储层面是append log文件。任何发布到此partition的消息都会被直接追加到log文件的尾部,每条消息在文件中的位置称为offset(偏移量),offset为一个long型数字,它是唯一标记一条消息。kafka并没有提供其他额外的索引机制来存储offset,因为在kafka中几乎不允许对消息进行“随机读写”。
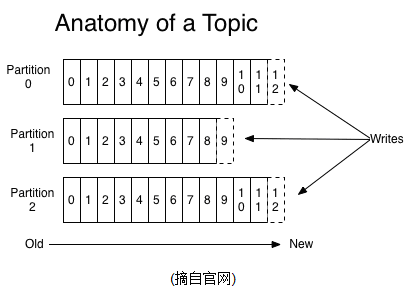
- Partition Partition是物理上的概念,每个Topic包含一个或多个Partition. 即使消息被消费,消息仍然不会被立即删除.日志文件将会根据broker中的配置要求,保留一定的时间之后删除;比如log文件保留2天,那么两天后,文件会被清除,无论其中的消息是否被消费.kafka通过这种简单的手段,来释放磁盘空间,以及减少消息消费之后对文件内容改动的磁盘IO开支. partitions的设计目的有多个.最根本原因是kafka基于文件存储.通过分区,可以将日志内容分散到多个server上,来避免文件尺寸达到单机磁盘的上限,每个partiton都会被当前server(kafka实例)保存;可以将一个topic切分多任意多个partitions,来消息保存/消费的效率.此外越多的partitions意味着可以容纳更多的consumer,有效提升并发消费的能力.(具体原理参见下文).
- Producer负责发布消息到Kafka broker。 kafka集群几乎不需要维护任何consumer和producer状态信息,这些信息有zookeeper保存;因此producer和consumer的客户端实现非常轻量级,它们可以随意离开,而不会对集群造成额外的影响. Producer将消息发布到指定的Topic中,同时Producer也能决定将此消息归属于哪个partition;比如基于"round-robin"方式或者通过其他的一些算法等.
- Consumer消息消费者,向Kafka broker读取消息的客户端。 对于consumer而言,它需要保存消费消息的offset,对于offset的保存和使用,有consumer来控制;当consumer正常消费消息时,offset将会"线性"的向前驱动,即消息将依次顺序被消费.事实上consumer可以使用任意顺序消费消息,它只需要将offset重置为任意值..(offset将会保存在zookeeper中,参见下文) 。本质上kafka只支持Topic.每个consumer属于一个consumer group;反过来说,每个group中可以有多个consumer.发送到Topic的消息,只会被订阅此Topic的每个group中的一个consumer消费(同一个Group的多个consumer不会消费相同的message).
- Consumer Group每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。如果所有的consumer都具有相同的group,这种情况和queue模式很像;消息将会在consumers之间负载均衡. 如果所有的consumer都具有不同的group,那这就是"发布-订阅";消息将会广播给所有的消费者.
一个Topic的多个partitions,被分布在kafka集群中的多个server上;每个server(kafka实例)负责partitions中消息的读写操作;此外kafka还可以配置partitions需要备份的个数(replicas),每个partition将会被备份到多台机器上,以提高可用性.Kafka将每个Topic进行分区Patition,以提高消息的并行处理,同时为保证高可用性,每个分区都有一定数量的副本 Replica,这样当部分服务器不可用时副本所在服务器就可以接替上来,保证系统可用性
基于replicated方案,那么就意味着需要对多个备份进行调度;每个partition都有一个server为"leader";leader负责所有的读写操作,如果leader失效,那么将会有其他follower来接管(成为新的leader);follower只是单调的和leader跟进,同步消息即可..由此可见作为leader的server承载了全部的请求压力,因此从集群的整体考虑,有多少个partitions就意味着有多少个"leader",kafka会将"leader"均衡的分散在每个实例上,来确保整体的性能稳定.
在kafka中,一个partition中的消息只会被group中的一个consumer消费;每个group中consumer消息消费互相独立;我们可以认为一个group是一个"订阅"者,一个Topic中的每个partions,只会被一个"订阅者"中的一个consumer消费,不过一个consumer可以消费多个partitions中的消息.kafka只能保证一个partition中的消息被某个consumer消费时,消息是顺序的.事实上,从Topic角度来说,消息仍不是有序的.
二、使用场景
一. kafka 入门的更多相关文章
- 《OD大数据实战》Kafka入门实例
官网: 参考文档: Kafka入门经典教程 Kafka工作原理详解 一.安装zookeeper 1. 下载zookeeper-3.4.5-cdh5.3.6.tar.gz 下载地址为: http://a ...
- kafka 入门笔记 #1
kafka 入门笔记(#1) 单机测试 下载版本,解压 tar -xzf kafka_2.11-0.10.1.1.tgz cd kafka_2.11-0.10.1.1 启动服务 Kafka用到了Zoo ...
- Kafka入门介绍
1. Kafka入门介绍 1.1 Apache Kafka是一个分布式的流平台.这到底意味着什么? 我们认为,一个流平台具有三个关键能力: ① 发布和订阅消息.在这方面,它类似一个消息队列或企业消息系 ...
- Kafka入门 --安装和简单实用
一.安装Zookeeper 参考: Zookeeper的下载.安装和启动 Zookeeper 集群搭建--单机伪分布式集群 二.下载Kafka 进入http://kafka.apache.org/do ...
- 转 Kafka入门经典教程
Kafka入门经典教程 http://www.aboutyun.com/thread-12882-1-1.html 问题导读 1.Kafka独特设计在什么地方?2.Kafka如何搭建及创建topic. ...
- Kafka 入门和 Spring Boot 集成
目录 Kafka 入门和 Spring Boot 集成 标签:博客 概述 应用场景 基本概念 基本结构 和Spring Boot 集成 集成概述 集成环境 kafka 环境搭建 Spring Boot ...
- _00017 Kafka的体系结构介绍以及Kafka入门案例(0基础案例+Java API的使用)
博文作者:妳那伊抹微笑 itdog8 地址链接 : http://www.itdog8.com(个人链接) 博客地址:http://blog.csdn.net/u012185296 博文标题:_000 ...
- 全网最通俗易懂的Kafka入门!
前言 只有光头才能变强. 文本已收录至我的GitHub仓库,欢迎Star:https://github.com/ZhongFuCheng3y/3y 在这篇之前已经写过两篇基础文章了,强烈建议先去阅读: ...
- 【转帖】全网最通俗易懂的Kafka入门
全网最通俗易懂的Kafka入门 http://www.itpub.net/2019/12/04/4597/ 前言 只有光头才能变强. 文本已收录至我的GitHub仓库,欢迎Star:https://g ...
- 【转帖】Kafka入门介绍
Kafka入门介绍 https://www.cnblogs.com/swordfall/p/8251700.html 最近在看hdoop的hdfs 以及看了下kafka的底层存储,发现分布式的技术基本 ...
随机推荐
- Spring 拦截器——HandlerInterceptor
采用Spring拦截器的方式进行业务处理.HandlerInterceptor拦截器常见的用途有: 1.日志记录:记录请求信息的日志,以便进行信息监控.信息统计.计算PV(Page View)等. 2 ...
- [原创]Scala学习:流程控制,异常处理
1.流程控制 1)do..while def doWhile(){ var line="" do{ line = readLine() println("readline ...
- [原创]Scala学习:关于变量(val,var,类型推断)
1.常量定义: val val 类似于java中的final变量.一旦初始化了,val就不能再被赋值 val megs = "hello world" 2.变量的定义: var ...
- 第二十二篇、IO多路复用 一
一.简介io多路复用 可以监听多个文件描述符(socket对象)(文件句柄),一旦文件句柄出现变化,就会感知到 Linux中的 select,poll,epoll(内核2.6以上) 都是IO多路复用的 ...
- hd acm1013
Problem Description(数根) The digital root of a positive integer is found by summing the digits of the ...
- 在unigui中为组件添加hint
//改变hint的样式procedure TUniForm1.UniFormShow(Sender: TObject);var i: Integer;begin for I := 0 to Self. ...
- C++的异常捕获
听课笔记: #define _CRT_SECURE_NO_WARNINGS #include<iostream> using namespace std; void fun() { ;// ...
- c#基础综述
一个相关的博客:http://blog.csdn.net/zhang_xinxiu/article/details/8605980 很好的一个网站:http://www.runoob.com/
- linux下安装rpm格式的mysql
1.下载安装包官网下载.rpm格式安装包,需要下面两个文件: MySQL-server-5.0.26-0.i386.rpm MySQL-client-5.0.26-0.i386.rpm 注:官网下载时 ...
- codeforces 707B B. Bakery(水题)
题目链接: B. Bakery 题意: 是否存在一条连接特殊和不特殊的边,存在最小值是多少; 思路: 扫一遍所有边: AC代码: #include <iostream> #include ...