RandomForestClassifier(随机森林检测每个特征的重要性及每个样例属于哪个类的概率)
- #In the next recipe, we'll look at how to tune the random forest classifier.
- #Let's start by importing datasets:
- from sklearn import datasets
- X, y = datasets.make_classification(1000)
- # X(1000,20)
- #y(1000) 取值范围【0,1】
- from sklearn.ensemble import RandomForestClassifier
- rf = RandomForestClassifier()
- rf.n_jobs=-1
- rf.fit(X, y)
- print ("Accuracy:\t", (y == rf.predict(X)).mean())
- print ("Total Correct:\t", (y == rf.predict(X)).sum())
- #每个例子属于哪个类的概率
- probs = rf.predict_proba(X)
- import pandas as pd
- probs_df = pd.DataFrame(probs, columns=['', ''])
- probs_df['was_correct'] = rf.predict(X) == y
- import matplotlib.pyplot as plt
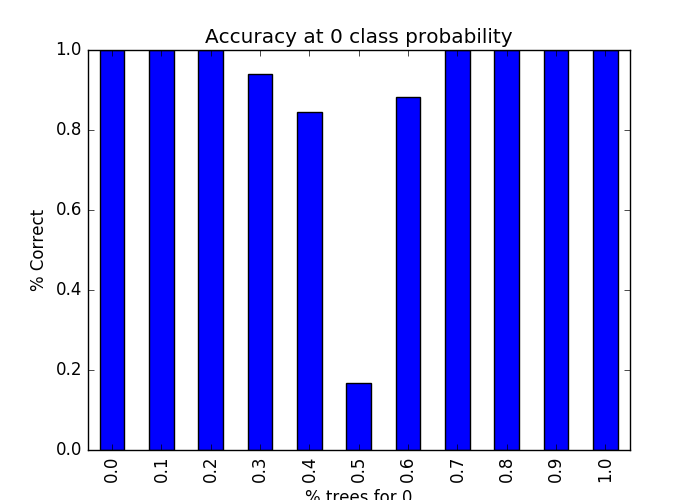
- f, ax = plt.subplots(figsize=(7, 5))
- probs_df.groupby('').was_correct.mean().plot(kind='bar', ax=ax)
- ax.set_title("Accuracy at 0 class probability")
- ax.set_ylabel("% Correct")
- ax.set_xlabel("% trees for 0")
- f.show()
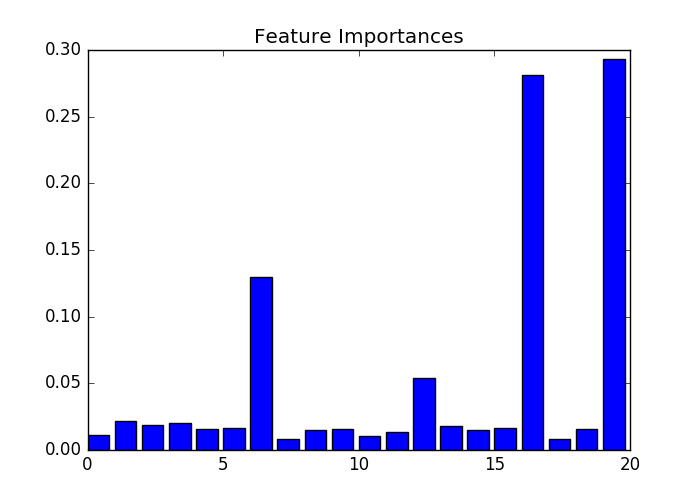
- #检测重要特征
- rf = RandomForestClassifier()
- rf.fit(X, y)
- f, ax = plt.subplots(figsize=(7, 5))
- ax.bar(range(len(rf.feature_importances_)),rf.feature_importances_)
- ax.set_title("Feature Importances")
- f.show()
RandomForestClassifier(随机森林检测每个特征的重要性及每个样例属于哪个类的概率)的更多相关文章
- OpenCV:使用OpenCV3随机森林进行统计特征多类分析
原文链接:在opencv3中的机器学习算法练习:对OCR进行分类 本文贴出的代码为自己的训练集所用,作为参考.可运行demo程序请拜访原作者. CNN作为图像识别和检测器,在分析物体结构分布的多类识别 ...
- 用随机森林分类器和GBDT进行特征筛选
一.决策树(类型.节点特征选择的算法原理.优缺点.随机森林算法产生的背景) 1.分类树和回归树 由目标变量是离散的还是连续的来决定的:目标变量是离散的,选择分类树:反之(目标变量是连续的,但自变量可以 ...
- Python机器学习笔记——随机森林算法
随机森林算法的理论知识 随机森林是一种有监督学习算法,是以决策树为基学习器的集成学习算法.随机森林非常简单,易于实现,计算开销也很小,但是它在分类和回归上表现出非常惊人的性能,因此,随机森林被誉为“代 ...
- CART决策树和随机森林
CART 分裂规则 将现有节点的数据分裂成两个子集,计算每个子集的gini index 子集的Gini index: \(gini_{child}=\sum_{i=1}^K p_{ti} \sum_{ ...
- Python中随机森林的实现与解释
使用像Scikit-Learn这样的库,现在很容易在Python中实现数百种机器学习算法.这很容易,我们通常不需要任何关于模型如何工作的潜在知识来使用它.虽然不需要了解所有细节,但了解机器学习模型是如 ...
- web安全之机器学习入门——3.2 决策树与随机森林
目录 简介 决策树简单用法 决策树检测P0P3爆破 决策树检测FTP爆破 随机森林检测FTP爆破 简介 决策树和随机森林算法是最常见的分类算法: 决策树,判断的逻辑很多时候和人的思维非常接近. 随机森 ...
- spark 机器学习 随机森林 实现(二)
通过天气,温度,风速3个特征,建立随机森林,判断特征的优先级结果 天气 温度 风速结果(0否,1是)天气(0晴天,1阴天,2下雨)温度(0热,1舒适,2冷)风速(0没风,1微风,2大风)1 1:0 2 ...
- kaggle数据挖掘竞赛初步--Titanic<随机森林&特征重要性>
完整代码: https://github.com/cindycindyhi/kaggle-Titanic 特征工程系列: Titanic系列之原始数据分析和数据处理 Titanic系列之数据变换 Ti ...
- 机器学习入门-随机森林温度预测的案例 1.datetime.datetime.datetime(将字符串转为为日期格式) 2.pd.get_dummies(将文本标签转换为one-hot编码) 3.rf.feature_importances_(研究样本特征的重要性) 4.fig.autofmt_xdate(rotation=60) 对标签进行翻转
在这个案例中: 1. datetime.datetime.strptime(data, '%Y-%m-%d') # 由字符串格式转换为日期格式 2. pd.get_dummies(features) ...
随机推荐
- bash: .bashrc: command not found
解决这个错误需要: vi ~/.bashrc 进入以后把 .bashrc 给注释掉 就不会再报错了.
- Spring初学之通过工厂方法配置Bean
工厂方法配置bean分为两种,一种是实例工厂方法,另一种是静态工厂方法. 先来看看实体bean: Car.java: package spring.beans.factory; public clas ...
- dataframe按值(非索引)查找多行
很多情况下,我们会根据一个dataframe里面的值来查找而不是根据索引来查找. 首先我们创建一个dataframe: >>> col = ["id"," ...
- codeforces 798C.Mike and gcd problem 解题报告
题目意思:给出一个n个数的序列:a1,a2,...,an (n的范围[2,100000],ax的范围[1,1e9] ) 现在需要对序列a进行若干变换,来构造一个beautiful的序列: b1,b2, ...
- Jedis源代码探索
[连接池实现] [一致性hash实现] [Redis客户端-Jedis源代码探索][http://blog.sina.com.cn/s/blog_6bc4401501018bgh.html] ...
- CSS基础(float属性与清除浮动)
3.8 这是CSS里比较重要的属性:浮动,这个属性会在以后经常用到,算是一个重点吧 浮动 语法:float:left | right | none 特点: 浮动的元素不占位置,脱离了标准文档流 ...
- 简述redux(1)
简述redux(1) 概念: 是一个有用的架构,应用场景一般为:多交互.多数据源.如: 某个组件的状态需要共享 某个状态需要在任何地方可以看到 一个组件需要改变全局状态. 一个组件需要改变另一个组件的 ...
- C++Builder XE5对于C++11的支持真蛋疼
好不容易下载个XE5,安装,破解,准备测试一下C++11中的lambda,写了一个最简单的表达式: [](){}; 居然编译通不过. 查了帮助文档,才晓得它的编译器分为BCC32和BCC64, BCC ...
- sql生成excel
gosp_configure 'show advanced options',1reconfiguregosp_configure 'xp_cmdshell',1reconfiguregoEXEC m ...
- UVA - 10570 Meeting with Aliens (置换的循环节)
给出一个长度不超过500的环状排列,每次操作可以交换任意两个数,求把这个排列变成有序的环状排列所需的最小操作次数. 首先把环状排列的起点固定使其成为链状排列a,枚举排好序时的状态b(一种有2n种可能) ...