Spark jdbc postgresql数据库连接和写入操作源代码解读
概述:Spark postgresql jdbc 数据库连接和写入操作源代码解读。具体记录了SparkSQL对数据库的操作,通过java程序。在本地开发和执行。总体为,Spark建立数据库连接,读取数据。将DataFrame数据写入还有一个数据库表中。附带完整项目源代码(完整项目源代码github)。
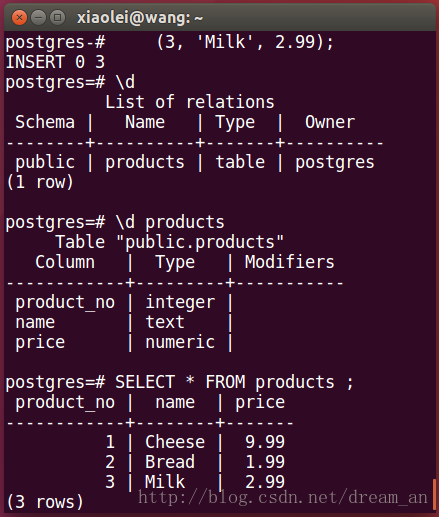
1.首先在postgreSQL中创建一张測试表,并插入数据。(完整项目源代码Github)
1.1. 在postgreSQL中的postgres用户下,创建 products
CREATE TABLE products (
product_no integer,
name text,
price numeric
);1.2. 在 products 插入数据
INSERT INTO products (product_no, name, price) VALUES
(1, 'Cheese', 9.99),
(2, 'Bread', 1.99),
(3, 'Milk', 2.99);查看数据库写入结果。
2.编写SPARK程序。(完整项目源代码Github)
2.1.读取Postgresql某一张表的数据为DataFrame(完整项目源代码Github)
SparkPostgresqlJdbc.javaProperties connectionProperties = new Properties();
//添加数据库的username(user)密码(password),指定postgresql驱动(driver)
connectionProperties.put("user","postgres");
connectionProperties.put("password","123456");
connectionProperties.put("driver","org.postgresql.Driver");
//SparkJdbc读取Postgresql的products表内容
Dataset<Row> jdbcDF = spark.read()
.jdbc("jdbc:postgresql://localhost:5432/postgres","products",connectionProperties).select("name","price");
//显示jdbcDF数据内容
jdbcDF.show();2.2.写入Postgresql某张表中
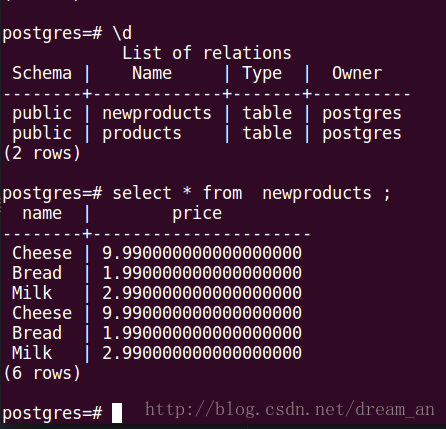
//将jdbcDF数据新建并写入newproducts,append模式是连接模式,默认的是"error"模式。
jdbcDF.write().mode("append")
.jdbc("jdbc:postgresql://localhost:5432/postgres","newproducts",connectionProperties);3.执行程序。并查看结果(假设在IDEA中开发不熟练。能够看我还有一篇博文spark (java API) 在Intellij IDEA中开发并执行)。
3.1.直接在intellij IDEA(社区版)中执行。
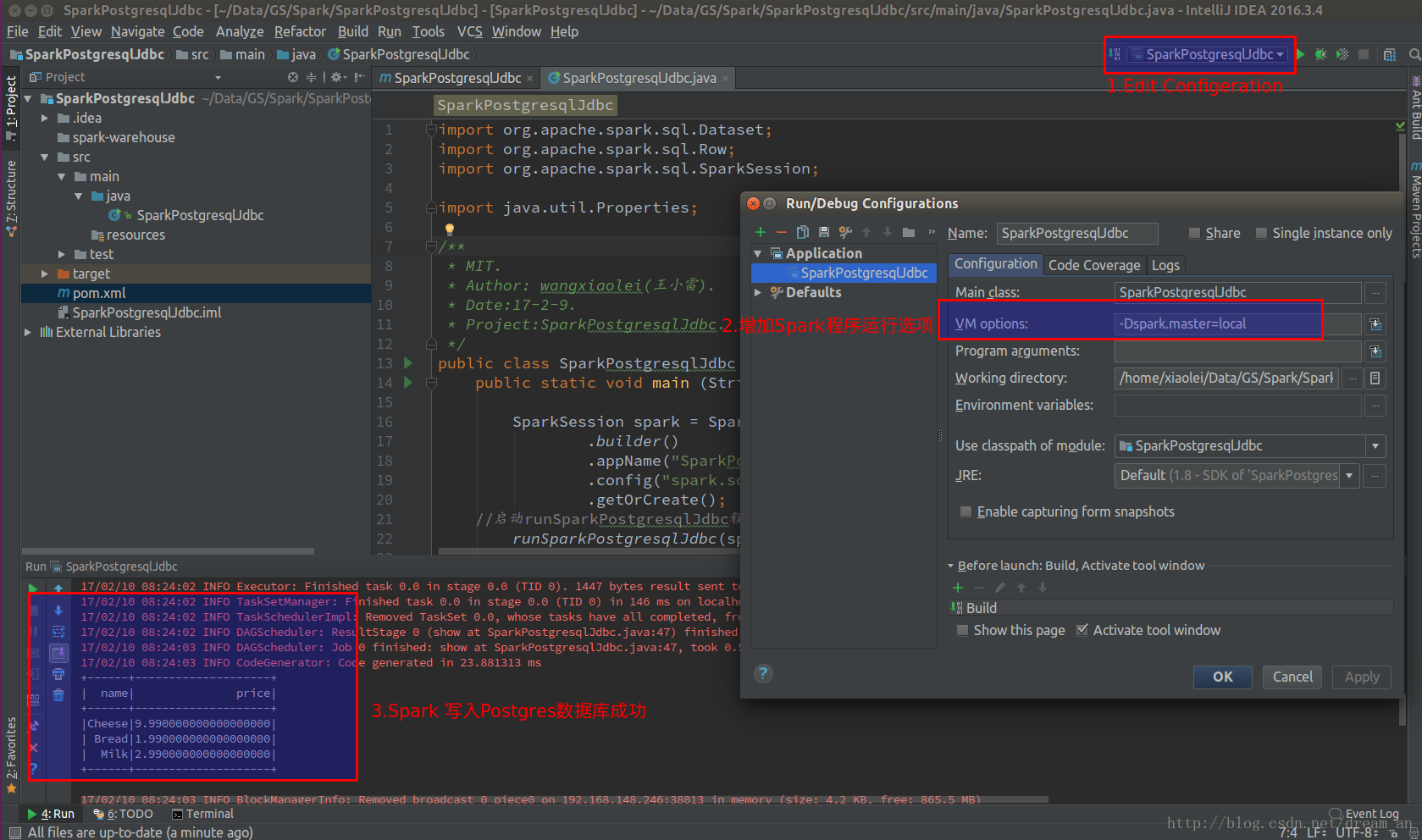
a.在执行button的“Edit Configeration”中的VM option中加入“-Dspark.master=local”
3.2.在终端(Terminal)中执行。
/opt/spark-2.1.0-bin-hadoop2.7/bin/spark-submit \
--class "SparkPostgresqlJdbc" \
--master local[4] \
--driver-class-path /home/xiaolei/.m2/repository/org/postgresql/postgresql/9.4.1212/postgresql-9.4.1212.jar \
target/SparkPostgresqlJdbc-1.0-SNAPSHOT.jar当中 --driver-class-path 指定下载的postgresql JDBC数据
库驱动路径。命令执行要在项目的根文件夹中(/home/xiaolei/Data/GS/Spark/SparkPostgresqlJdbc)。
watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvZHJlYW1fYW4=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/SouthEast" alt="这里写图片描写叙述" title="">
查看Spark写入数据库中的数据
4.下面为项目中主要源代码(完整项目源代码Github):
4.1.项目配置源代码pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>wangxiaolei</groupId>
<artifactId>SparkPostgresqlJdbc</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency> <!-- Spark dependency -->
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>9.4.1212</version>
</dependency>
</dependencies>
</project>4.2.java源代码SparkPostgresqlJdbc.java
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import java.util.Properties;
/**
* MIT.
* Author: wangxiaolei(王小雷).
* Date:17-2-9.
* Project:SparkPostgresqlJdbc.
*/
public class SparkPostgresqlJdbc {
public static void main (String[] args) {
SparkSession spark = SparkSession
.builder()
.appName("SparkPostgresqlJdbc")
.config("spark.some.config.option","some-value")
.getOrCreate();
//启动runSparkPostgresqlJdbc程序
runSparkPostgresqlJdbc(spark);
spark.stop();
}
private static void runSparkPostgresqlJdbc(SparkSession spark){
//new一个属性
System.out.println("确保数据库已经开启,并创建了products表和插入了数据");
Properties connectionProperties = new Properties();
//添加数据库的username(user)密码(password),指定postgresql驱动(driver)
System.out.println("添加数据库的username(user)密码(password),指定postgresql驱动(driver)");
connectionProperties.put("user","postgres");
connectionProperties.put("password","123456");
connectionProperties.put("driver","org.postgresql.Driver");
//SparkJdbc读取Postgresql的products表内容
System.out.println("SparkJdbc读取Postgresql的products表内容");
Dataset<Row> jdbcDF = spark.read()
.jdbc("jdbc:postgresql://localhost:5432/postgres","products",connectionProperties).select("name","price");
//显示jdbcDF数据内容
jdbcDF.show();
//将jdbcDF数据新建并写入newproducts,append模式是连接模式。默认的是"error"模式。
jdbcDF.write().mode("append")
.jdbc("jdbc:postgresql://localhost:5432/postgres","newproducts",connectionProperties);
}
}Spark jdbc postgresql数据库连接和写入操作源代码解读的更多相关文章
- Spark jdbc postgresql数据库连接和写入操作源码解读
概述:Spark postgresql jdbc 数据库连接和写入操作源码解读,详细记录了SparkSQL对数据库的操作,通过java程序,在本地开发和运行.整体为,Spark建立数据库连接,读取数据 ...
- JDBC(1)-数据库连接和CRUD操作
关于jdbc的全部jar包 链接:https://pan.baidu.com/s/1peofgu89SpepTTYuZuphNw 提取码:vd5v 一.获取数据库连接 1. Driver接口介绍 ja ...
- testbench的设计 文件读取和写入操作 源代码
十大基本功之 testbench 1. 激励的产生 对于 testbench 而言,端口应当和被测试的 module 一一对应.端口分为 input,output 和 inout 类型产生激励信号的时 ...
- Spark RDD、DataFrame原理及操作详解
RDD是什么? RDD (resilientdistributed dataset),指的是一个只读的,可分区的分布式数据集,这个数据集的全部或部分可以缓存在内存中,在多次计算间重用. RDD内部可以 ...
- Java Web(九) JDBC及数据库连接池及DBCP,c3p0,dbutils的使用
DBCP.C3P0.DBUtils的jar包和配置文件(百度云盘):点我下载 JDBC JDBC(Java 数据库连接,Java Database Connectify)是标准的Java访问数据库的A ...
- Spark JDBC系列--取数的四种方式
Spark JDBC系列--取数的四种方式 一.单分区模式 二.指定Long型column字段的分区模式 三.高自由度的分区模式 四.自定义option参数模式 五.JDBC To Other Dat ...
- Spark Streaming、Kafka结合Spark JDBC External DataSouces处理案例
场景:使用Spark Streaming接收Kafka发送过来的数据与关系型数据库中的表进行相关的查询操作: Kafka发送过来的数据格式为:id.name.cityId,分隔符为tab zhangs ...
- Spark Streaming、HDFS结合Spark JDBC External DataSouces处理案例
场景:使用Spark Streaming接收HDFS上的文件数据与关系型数据库中的表进行相关的查询操作: 使用技术:Spark Streaming + Spark JDBC External Data ...
- Java学习-015-CSV 文件写入实例源代码
在日常的自动化测试脚本编写的过程中,有时要将获取的测试结果或者测试数据存放在数据文件中,以用作后续的参数化测试.常用的文件文件类型无非 txt.csv.xls.properties.xml 这五种文件 ...
随机推荐
- [bzoj5287] [HNOI2018]毒瘤
题目描述 从前有一名毒瘤. 毒瘤最近发现了量产毒瘤题的奥秘.考虑如下类型的数据结构题:给出一个数组,要求支持若干种奇奇怪怪的修改操作(比如区间加一个数,或者区间开平方),并支持询问区间和.毒瘤考虑了n ...
- 2016-2017 ACM-ICPC, Egyptian Collegiate Programming Contest (ECPC 16)
A.The game of Osho(sg函数+二项展开) 题意: 一共有G个子游戏,一个子游戏有Bi, Ni两个数字.两名玩家开始玩游戏,每名玩家从N中减去B的任意幂次的数,直到不能操作判定为输.问 ...
- iOS-android-windowsphone等移动终端平台开发流程图
到了公司后,半个月时间就是在熟悉下面这张图里的流程, 项目流程图: 下面是我对这张图的一些理解:
- 无法更新 EntitySet“W_ReceiveData”,因为它有一个 DefiningQuery,而 <ModificationFunctionMapping> 元素中没有支持当前操作的 <InsertFunction> 元素。
无法更新 EntitySet“W_ReceiveData”,因为它有一个 DefiningQuery,而 <ModificationFunctionMapping> 元素中没有支持当前操作 ...
- 由做网站操作日志想到的HttpModule应用
背景 在以前的Web项目中,记录用户操作日志,总是在方法里,加一行代码,记录此时用户操作类型与相关信息.该记录日志的方法对原来的业务操作侵入性较强,也比较零散,不便于查看和管理.那么有没有更加通用点的 ...
- Java定义bean实体类中的变量时变量名的问题
首先:TMD,这个问题花了我两个多小时,居然是因为一个字母的大小写导致的,我瞬间就&Y^%^&%&()*%¥%¥¥&^#@%&; 事情是酱紫的: 我定义了一个变 ...
- Optional int parameter 'rows' is not present but cannot be translated into a null value due to being declared as a primitive type.
我的spring mvc 代码: @Controller @RequestMapping("/product") public class Fancy { @RequestMapp ...
- FileReader&FileWriter
FileReader public static void main(String[] args) { //创建文件对象指定要读取的文件路径 File file=new File("d:\\ ...
- JMeter乱码问题的解决
一.JMeter返回数据是乱码 解决办法是: 在JMeter安装路径的bin目录下,以记事本打开文件jmeter.properties, 找到Sampleresult.default.encoding ...
- hdu 5720(贪心+区间合并)
Wool Time Limit: 8000/4000 MS (Java/Others) Memory Limit: 262144/262144 K (Java/Others)Total Subm ...