MapReduce实战:邮箱统计及多输出格式实现
紧接着上一篇博文我们学习了MapReduce得到输出格式之后,在这篇博文里,我们将通过一个实战小项目来熟悉一下MultipleOutputs(多输出)格式的用法。
项目需求:
假如这里有一份邮箱数据文件,我们期望统计邮箱出现次数并按照邮箱的类别,将这些邮箱分别输出到不同文件路径下(MultipleOutputs)。数据集示例如下所示。
wolys@21cn.com zss1984@126.com 294522652@qq.com simulateboy@163.com zhoushigang_123@163.com sirenxing424@126.com lixinyu23@qq.com chenlei1201@gmail.com 370433835@qq.com cxx0409@126.com viv093@sina.com q62148830@163.com 65993266@qq.com summeredison@sohu.com zhangbao-autumn@163.com diduo_007@yahoo.com.cn fxh852@163.com
下面我们编写 MapReduce 程序,实现上述业务需求。
项目实现:
新建一个EmailCount.java类,在其中编写一下程序
package com.hadoop.OutputFormat; import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; public class EmailCount extends Configured implements Tool{ public static class MailMapper extends Mapper< LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1); @Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
context.write(value, one);
}
} public static class MailReducer extends Reducer< Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
private MultipleOutputs< Text, IntWritable> multipleOutputs; @Override
protected void setup(Context context) throws IOException ,InterruptedException{
multipleOutputs = new MultipleOutputs< Text, IntWritable>(context);
}
protected void reduce(Text Key, Iterable< IntWritable> Values,Context context) throws IOException, InterruptedException {
//294522652@qq.com
int begin = Key.toString().indexOf("@");
int end = Key.toString().indexOf(".");
if(begin>=end){
return;
}
//获取邮箱类别,比如 qq
String name = Key.toString().substring(begin+1, end);
int sum = 0;
for (IntWritable value : Values) {
sum += value.get();
}
result.set(sum);
multipleOutputs.write(Key, result, name);
}
@Override
protected void cleanup(Context context) throws IOException ,InterruptedException
{
multipleOutputs.close();
}
} @Override
public int run(String[] args) throws Exception {
Configuration conf = new Configuration();// 读取配置文件 Path mypath = new Path(args[1]);
FileSystem hdfs = mypath.getFileSystem(conf);//创建输出路径
if (hdfs.isDirectory(mypath)) {
hdfs.delete(mypath, true);
}
Job job = Job.getInstance();// 新建一个任务
job.setJarByClass(EmailCount.class);// 主类 FileInputFormat.addInputPath(job, new Path(args[0]));// 输入路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));// 输出路径 job.setMapperClass(MailMapper.class);// 设置Mapper类
job.setReducerClass(MailReducer.class);// 设置Reducer类 job.setOutputKeyClass(Text.class);// key输出类型
job.setOutputValueClass(IntWritable.class);// value输出类型 job.waitForCompletion(true);
return 0;
} public static void main(String[] args) throws Exception {
String[] args0 = {
"hdfs://Centpy:9000/email/email.txt",
"hdfs://Centpy:9000/email/outputs/"
};
int ec = ToolRunner.run(new Configuration(), new EmailCount(), args0);
System.exit(ec);
}
}
项目测试:
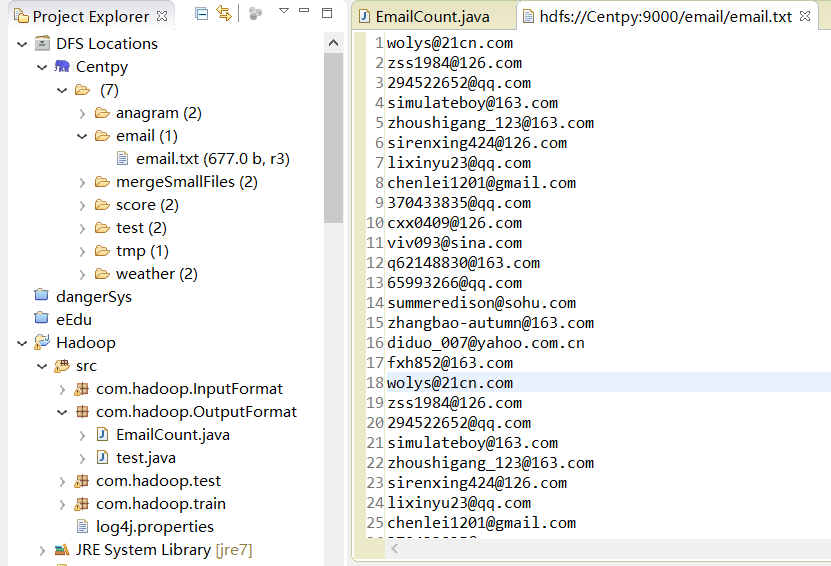
首先,我们的输入文件如下所示。
将项目文件导出为JAR文件,然后上传到Hadoop集群上。
运行以下指令
hadoop jar EmailCount.jar com.hadoop.OutputFormat.EmailCount /email /email/outputs
项目结果:
项目测试结果如下所示
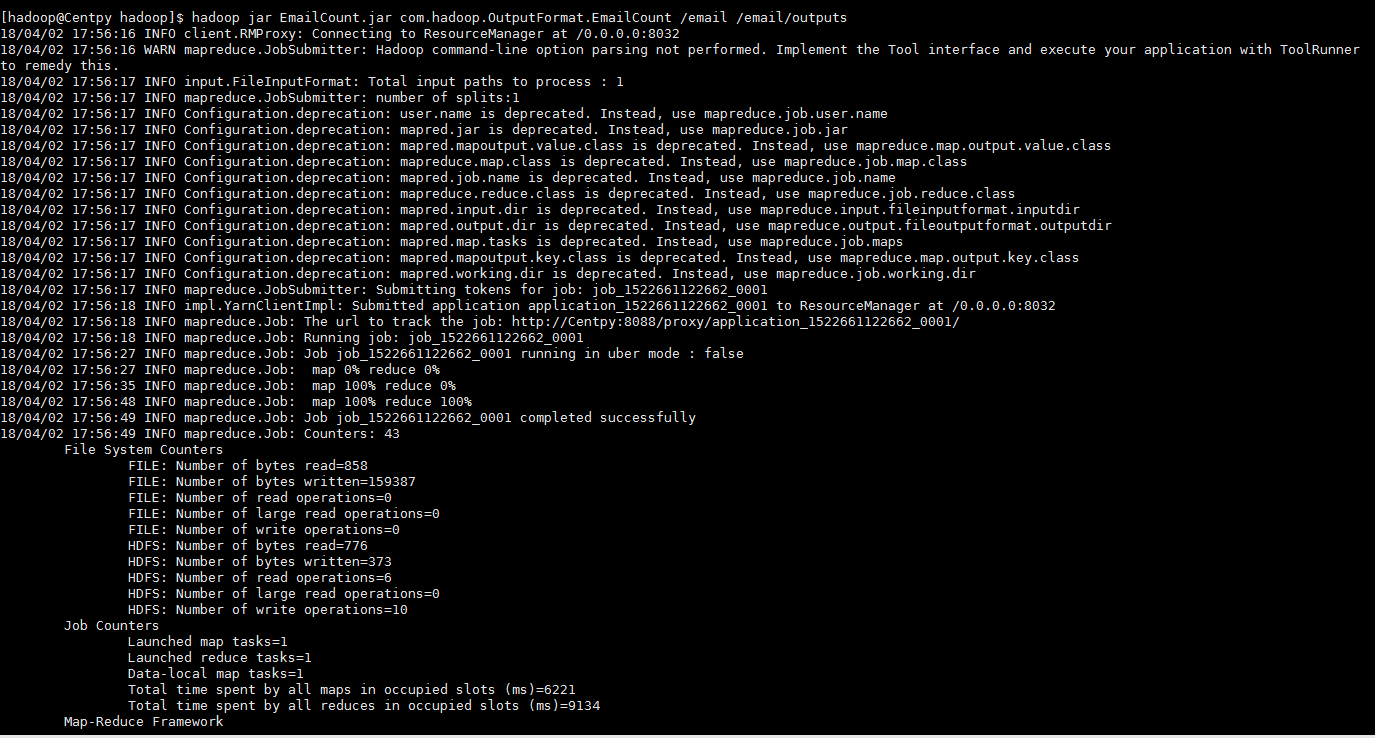
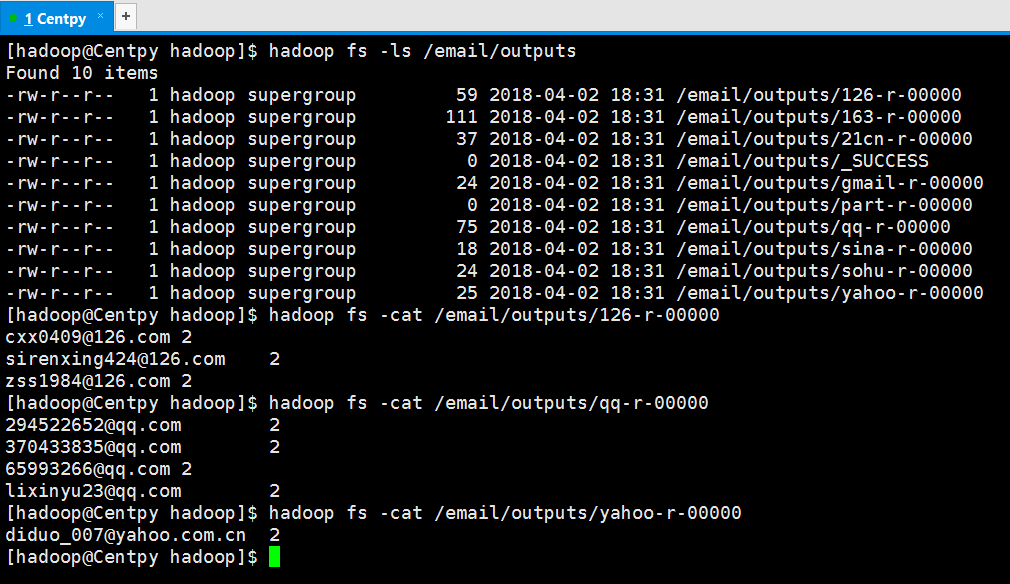
从结果可以看出,我们通过MapReduce成功实现了邮箱统计的MultipleOutputs格式,即将邮箱进行分类,然后每一个类型的邮箱单独存储到一个输出文件中,并在其中显示邮箱的统计次数。
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!
版权声明:本文为博主原创文章,未经博主允许不得转载。
MapReduce实战:邮箱统计及多输出格式实现的更多相关文章
- MapReduce实战:统计不同工作年限的薪资水平
1.薪资数据集 我们要写一个薪资统计程序,统计数据来自于互联网招聘hadoop岗位的招聘网站,这些数据是按照记录方式存储的,因此非常适合使用 MapReduce 程序来统计. 2.数据格式 我们使用的 ...
- mapreduce实战:统计美国各个气象站30年来的平均气温项目分析
气象数据集 我们要写一个气象数据挖掘的程序.气象数据是通过分布在美国各地区的很多气象传感器每隔一小时进行收集,这些数据是半结构化数据且是按照记录方式存储的,因此非常适合使用 MapReduce 程序来 ...
- MapReduce实战:自定义输入格式实现成绩管理
1. 项目需求 我们取有一份学生五门课程的期末考试成绩数据,现在我们希望统计每个学生的总成绩和平均成绩. 样本数据如下所示,每行数据的数据格式为:学号.姓名.语文成绩.数学成绩.英语成绩.物理成绩.化 ...
- Hadoop实战5:MapReduce编程-WordCount统计单词个数-eclipse-java-windows环境
Hadoop研发在java环境的拓展 一 背景 由于一直使用hadoop streaming形式编写mapreduce程序,所以目前的hadoop程序局限于python语言.下面为了拓展java语言研 ...
- Hadoop实战3:MapReduce编程-WordCount统计单词个数-eclipse-java-ubuntu环境
之前习惯用hadoop streaming环境编写python程序,下面总结编辑java的eclipse环境配置总结,及一个WordCount例子运行. 一 下载eclipse安装包及hadoop插件 ...
- 《OD大数据实战》MapReduce实战
一.github使用手册 1. 我也用github(2)——关联本地工程到github 2. Git错误non-fast-forward后的冲突解决 3. Git中从远程的分支获取最新的版本到本地 4 ...
- MapReduce实战--倒排索引
本文地址:http://www.cnblogs.com/archimedes/p/mapreduce-inverted-index.html,转载请注明源地址. 1.倒排索引简介 倒排索引(Inver ...
- MapReduce实战(三)分区的实现
需求: 在实战(一)的基础 上,实现自定义分组机制.例如根据手机号的不同,分成不同的省份,然后在不同的reduce上面跑,最后生成的结果分别存在不同的文件中. 对流量原始日志进行流量统计,将不同省份的 ...
- MapReduce实战项目:查找相同字母组成的字谜
实战项目:查找相同字母组成的字谜 项目需求:一本英文书籍中包含有成千上万个单词或者短语,现在我们要从中找出相同字母组成的所有单词. 数据集和期望结果举例: 思路分析: 1)在Map阶段,对每个word ...
随机推荐
- 删除老的Azure Blob Snapshot
客户有这样的需求:每天需要对VM的数据进行备份,但如果备份的时间超过一定的天数,需要进行清除. 本文也是在前一篇Azure Blob Snapshot上的优化. "Azure blob St ...
- Cypress USB3014 C++DLL 导入问题
VS2017编译cpp工程出现问题 硬件型号:芯片版本 Cypress FX3 USB3014(和芯片无关)) 重现步骤: 1.解压 FX3_SDK_Windows_v1.3.3.exe 2.VS20 ...
- == Equals ReferenceEquals 比较
== 为操作符 ReferenceEquals和Equals为函数 ========================================================= Referenc ...
- js比较日期字串的大小
function checkTime() { var startTime = $('#startTime').val(); var endTime = $('#endTime').val(); if( ...
- .net 缓存之应用程序数据缓存
CaCheHelp类中代码如下: #region 根据键从缓存中读取保持的数据 /// <summary> /// 根据键从缓存中读取保持的数据 /// </summary> ...
- redis GEO地理位置命令介绍
GEOADD keylongitude latitude member [longitude latitude member ...] Available since 3.2.0. Time comp ...
- 3.Windows应急响应:蠕虫病毒
0x00 前言 蠕虫病毒是一种十分古老的计算机病毒,它是一种自包含的程序(或是一套程序),通常通过网络途径传播, 每入侵到一台新的计算机,它就在这台计算机上复制自己,并自动执行它自身的程序.常见的蠕虫 ...
- 18. CTF综合靶机渗透(十一)
靶机描述: SkyDog Con CTF 2016 - Catch Me If You Can 难度:初学者/中级 说明:CTF是虚拟机,在虚拟箱中工作效果最好.下载OVA文件打开虚拟框,然后选择文件 ...
- 从CGI到FastCGI到PHP-FPM
从CGI到FastCGI到PHP-FPM 背景 笔者在学习这几个名词的时候,也是被百度到的相关文章迷惑.涉及到的主要名词包括 1. CGI协议 2. CGI脚本 3. PHP-CGI 4. FastC ...
- 树的直径-CF592D Super M
给定一颗n个节点树,边权为1,树上有m个点被标记,问从树上一个点出发,经过所有被标记的点的最短路程(起终点自选).同时输出可能开始的编号最小的那个点.M<=N<=123456. 先想:如果 ...