POJ1034 The dog task
题目来源:http://poj.org/problem?id=1034
题目大意:
一个猎人在遛狗。猎人的路径由一些给定的点指定。狗跟随着猎人,要与主人同时到达那些指定的点。在丛林里有一些有趣的地方,狗很喜欢去。狗在从一个指定点到达另一个指定点之间最多可以去访问一个有趣的地方。每个有趣的地方狗最多去访问一次。猎人总是匀速沿直线从一个点去往下一个点,狗的速度不超过猎人速度的两倍。(如下图,图中直线为猎人路线,虚线为狗的路径,黑点为有趣的地方。)
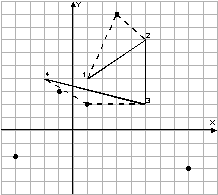
现给出猎人的路径,和所有有趣的点的坐标,求狗的路径,使得狗可以访问最多有趣的地方。
输入:第一行两个整数N(2<=N<=100)和M(0<=M<=100),N表示猎人的路径中指定的点数,M为有趣的地方的数目。第二行N对整数,指定猎人路径中指定点的坐标。第三行M对整数,指定有趣的地方的坐标。
输出:第一行输出一个整数K表明输出的狗的路径中顶点的个数。第三行K对整数表示狗的路径顶点坐标。
Sample Input
4 5
1 4 5 7 5 2 -2 4
-4 -2 3 9 1 2 -1 3 8 -3
Sample Output
6
1 4 3 9 5 7 5 2 1 2 -2 4
本题用到了很巧妙的建模方法,把问题转化为二部图的最大匹配问题,然后用经典的匈牙利算法解决。
二部图如下图所示:
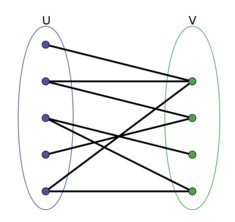
图的顶点(这里称之为node)分为两个部分,图的边所连接的两个顶点均分别属于两个部分。
在我们的问题里,可以为每个猎人路径的相邻顶点(称之为vertex)之间的边建立一个node,把所有这些node的集合作为二部图的一边,所有有趣的地点作为二部图的另一部分的node。
node之间是否相连取决于狗在访问两个相邻vertex之间能否访问这个有趣的地方(有速度的约束,通过距离求解)。若可以访问,将对应的node连接起来。
建立起了二部图之后,就是要求解一个二部图的最大匹配了。匹配即图两部分顶点之间的配对,最大匹配即配对数对多的配对方式,显然求出最大匹配就解决了我们的问题。
有一种经典的匈牙利算法可以很简单的解决这个问题。依我的理解匈牙利算法应该用了贪心和dfs的思想。
首先,需要理解增广路的概念,下面用一个实例来解释。假设现有一个初始匹配(二部图中一些被选中的边的集合):
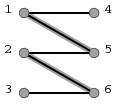
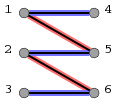
图1 图2
如图1粗线所示。一条增广路就是:假设从左边的顶点开始查找,找到一个没有被匹配的点(3),从3出发找一条没有被选中的边(3-6),到达一个顶点6,发现6已经被匹配了,那么沿着与6匹配的边(6-2)到达2,再由2找一条不在匹配中的边(2-5)到达顶点5,5已被匹配,则继续沿匹配中的边(5-1)到达1,选与1相连但未在匹配中的边(1-4)找到4,此时顶点4无法再找到与之匹配的点,则一条增广路径(3->6->2->5->1->4)找到了。增广路的实质特点是:
1.路径段数一定是奇数,第一条边和最后一条边都没有被初始匹配选中。
2.路径中选中的边和未选中的边交替出现。
3.被选中的边数比未选中的边数多1。
基于上述三个特点,对于一个初始匹配,若能找到一条增广路径,只要把路径中选中的边从匹配中删除,把路径中未选中的边加入匹配,则匹配数增加了1.如果对于一个匹配无法再找到增广路,说明已经是最大匹配。
没明白的话看一下别人总结的“一句话”描述:“从二部图中找出一条路径来,让路径的起点和终点都是还没有匹配过的点,并且路径经过的连线是一条没被匹配、一条已经匹配过,再下一条又没匹配这样交替地出现。找到这样的路径后,路径里没被匹配的连线比已经匹配了的连线多一条,于是修改匹配图,把路径里所有匹配过的连线去掉匹配关系,把没有匹配的连线变成匹配的,这样匹配数就比原来多1个。不断执行上述操作,直到找不到这样的路径为止。”
个人认为找增广路的思想属于贪心的方法,而找增广路的过程是一个dfs的过程。
//////////////////////////////////////////////////////////////////////////
// POJ1034 The dog task
// Memory: 296K Time: 47MS
// Language: C++ Result: Accepted
////////////////////////////////////////////////////////////////////////// #include <iostream>
#include <math.h> using namespace std; struct Point{
int x;
int y;
};
bool graph[][];
Point hunterRoute[];
int hunterRouteCnt;
Point interestingPlaces[];
int interestingPlacesCnt;
int link[];
int ans[];
int linkCnt;
bool visited[]; void readData() {
cin >> hunterRouteCnt >> interestingPlacesCnt;
for (int i = ; i <= hunterRouteCnt; ++i) {
cin >> hunterRoute[i].x >> hunterRoute[i].y;
}
for (int i = ; i <= interestingPlacesCnt; ++i) {
cin >> interestingPlaces[i].x >> interestingPlaces[i].y;
}
} bool check (int x, int y) {
double x1 = hunterRoute[x].x;
double y1 = hunterRoute[x].y;
double x2 = hunterRoute[x + ].x;
double y2 = hunterRoute[x + ].y;
double xd = interestingPlaces[y].x;
double yd = interestingPlaces[y].y;
double distance1 = sqrt((x1 - x2) * (x1 - x2) + (y1 - y2) * (y1 - y2));
double distance2 = sqrt((x1 - xd) * (x1 - xd) + (y1 - yd) * (y1 - yd));
double distance3 = sqrt((xd - x2) * (xd - x2) + (yd - y2) * (yd - y2));
return distance2 + distance3 <= distance1 * ? true : false;
}
void createGraph() {
memset(graph, false, sizeof(graph));
for (int i = ; i < hunterRouteCnt; ++i) {
for (int j = ; j <= interestingPlacesCnt; ++j) {
graph[i][j] = check(i, j);
}
}
} bool dfs(int i) {
for (int k = ; k <= interestingPlacesCnt; ++k) {
if (graph[i][k] == true && visited[k] == false) {
visited[k] = true;
if (link[k] == || dfs(link[k])) {
link[k] = i;
ans[i] = k;
return true;
}
}
}
return false;
} void findMaxMatch() {
memset(ans, , sizeof(ans));
memset(link, , sizeof(link));
linkCnt = ;
for (int i = ; i < hunterRouteCnt; ++i) {
memset(visited, false, sizeof(visited));
if (dfs(i) == true) {
++linkCnt;
}
}
} void output() {
cout << linkCnt + hunterRouteCnt<<endl;
for (int i = ; i < hunterRouteCnt; ++i) {
cout << hunterRoute[i].x << " " << hunterRoute[i].y << " ";
if (ans[i] != ) {
cout << interestingPlaces[ans[i]].x << " " << interestingPlaces[ans[i]].y << " ";
}
}
cout << hunterRoute[hunterRouteCnt].x << " " << hunterRoute[hunterRouteCnt].y;
}
int main() {
while (cin >> hunterRouteCnt >> interestingPlacesCnt) {
memset(graph,false,sizeof(graph));
for (int i = ; i <= hunterRouteCnt; ++i) {
cin >> hunterRoute[i].x >> hunterRoute[i].y;
}
for (int i = ; i <= interestingPlacesCnt; ++i) {
cin >> interestingPlaces[i].x >> interestingPlaces[i].y;
}
createGraph();
findMaxMatch();
output();
}
system("pause");
return ;
}
POJ1034 The dog task的更多相关文章
- poj 1034 The dog task (二分匹配)
The dog task Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 2559 Accepted: 1038 Sp ...
- 二分图最大匹配(匈牙利算法) UVA 670 The dog task
题目传送门 /* 题意:bob按照指定顺序行走,他的狗可以在他到达下一个点之前到一个景点并及时返回,问狗最多能走多少个景点 匈牙利算法:按照狗能否顺利到一个景点分为两个集合,套个模板 */ #incl ...
- POJ 1034 The dog task(二分图匹配)
http://poj.org/problem?id=1034 题意: 猎人和狗一起出去,狗的速度是猎人的两倍,给出猎人的路径坐标,除了这些坐标外,地图上还有一些有趣的点,而我们的狗,就是要尽量去多的有 ...
- 北大poj- 1034
The dog task Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 3272 Accepted: 1313 Sp ...
- POJ题目排序的Java程序
POJ 排序的思想就是根据选取范围的题目的totalSubmittedNumber和totalAcceptedNumber计算一个avgAcceptRate. 每一道题都有一个value,value ...
- C# 基于任务的异步模式的创建与使用的简单示例
对于窗体程序,使用基于任务的异步模式需要用到Task类,下面示例下非常简单的用法. 1.创建一个拥有异步方法的类 该类拥有一个异步方法DoSomthingAsync,根据微软建议的命名规则该方法要带A ...
- REX系统了解1
REX是高通开发出来的一个操作系统,起初它是为了在Inter 80186处理器上应用而开发的,到后来才转变成应用在ARM这种微处理器上.他历经了很多版本,代码也越来越多,功能也越来越完善.REX只用不 ...
- 《Monitoring and Tuning the Linux Networking Stack: Receiving Data》翻译
Overview 从宏观的角度来看,一个packet从网卡到socket接收缓冲区的路径如下所示: 驱动加载并初始化 packet到达网卡 packet通过DMA被拷贝到内核中的一个ring buff ...
- cvpr2015papers
@http://www-cs-faculty.stanford.edu/people/karpathy/cvpr2015papers/ CVPR 2015 papers (in nicer forma ...
随机推荐
- ACM学习历程—UESTC 1219 Ba Gua Zhen(dfs && 独立回路 && xor高斯消元)
题目链接:http://acm.uestc.edu.cn/#/problem/show/1219 题目大意是给了一张图,然后要求一个点通过路径回到这个点,使得xor和最大. 这是CCPC南阳站的一道题 ...
- 洛谷【P2115】[USACO14MAR]破坏Sabotage
我对二分的理解:https://www.cnblogs.com/AKMer/p/9737477.html 题目传送门:https://www.luogu.org/problemnew/show/P21 ...
- centos 6 rsync+inotify 实时同步
主机名.ip: server 172.31.82.184 client 172.31.82.185 需求: 1.server端 ”/data/server“ 做为client端 “/data/cli ...
- asp.net C#操作存储过程读取存储过程输出参数值
这段时间在做一个价格平台的项目时候,同事让我写一个存储过程.该存储过程是根据查询条件得出一组新数据,并且返回该组数据的总条数,此处的存储过程我用到了分页,其中主要知识点和难点是之前做项目的时候没有用到 ...
- shell入门-wc
命令:wc 选项:-l 查看行数 -w 以空白字符为分隔符 查看有多少单词 -m 查看字符数,文件大小 说明:统计指定文件中的字节数.字数.行数. -l [root@wangshaojun 11 ...
- ansible案例-安装nginx
一.创建目录: mkidr -p playbook/{files,templates} 二.自定义index.html文件 $ vim playbook/templates/index.html. ...
- ViewPageIndicator--仿网易的使用
仿微信(网易的界面) 第一步: AndroidManifest.xml 的配置 <?xml version="1.0" encoding="utf-8"? ...
- Elasticsearch2.x --DeleteByQuery
一.安装插件 要删除某个索引的一个type下的所有文档,相当于关系型数据库中的清空表操作.查阅了一些资料可以通过Delete-by-Query插件删除,首先使用插件管理器安装Delete-by-Que ...
- Asp.net 微信企业号网页开发流程
一.在pageload方法中获取code var code = GetCode(); private string GetCode() { return HttpContext.Current.Req ...
- 8、泛型程序设计与c++标准模板库2.4列表容器
列表容器主要用于存放链表,其中的链表是双向链表,可以从任意一端开始遍历.列表容器是需要按顺序访问的容器.另外,列表容器不支持随机访问迭代器,因此某些算法不能适合于列表容器.列表容器还提供了另一种操作- ...