解读人:刘佳维,Spectral Clustering Improves Label-Free Quantification of Low-Abundant Proteins(谱图聚类改善了低丰度蛋白的无标记定量)
发表时间:(2019年4月)
IF:3.95
单位:
- 维也纳医科大学;
- 欧洲生物信息研究所(EMBL-EBI);
- 分子病理学研究所;
- 奥地利科学院分子生物技术研究所;
- Gregor Mendel分子植物生物学研究所。
对象:质谱无标记定量结果
技术:聚类分析
一、 概述:(用精炼的语言描述文章的整体思路及结果)
本文选择四个不同的数据集,分为基于谱图数计数和基于峰值强度计数的无标记定量两种情况,对谱图进行聚类算法分析,提高了低丰度蛋白的可检测性,并开发了可直接使用的聚类方法的PD节点。
二、 研究背景:
无标记量化已成为许多基于质谱的蛋白质组学实验中的常见做法。近年来,聚类方法可以改善蛋白质组学数据集的分析的结论已广泛被人们所接受。本文旨在利用光谱聚类推断额外的肽谱匹配,并提高数据集中的无标记定量蛋白质组学数据的质量,改善低丰度蛋白的定量结果,同时提高了衍生定量数据的准确性,且没有增加数据集的噪声。
三、 实验设计:

图 1:基于谱图计数和基于强度计数两种方法对LFQ进行聚类以得到额外PSMs的工作流程。
名词解释:
LFQ:Label-Free Quantification,无标记定量;
MGF:Mascot genetic format,一种文件格式;
PSMs:peptide spectrum matches,匹配到的肽段谱图;
MSGF+/X!tandem:常用的搜库软件;
MS-Amanda:PD中常用的搜索算法;
apQuant:通过质量过滤使LFQ的结果更准确。
四、研究成果:
1、以在酵母蛋白环境下加入不同浓度的做了标记的UPS1蛋白的样品进行常规蛋白分析得到ms谱图,这些UPS1蛋白即为所用样品中的用来检测结果的低丰度蛋白,然后在搜库时选择是否使用聚类方法并将检测到的标记低丰度蛋白量进行比对,结果如图2。可以看出在低浓度情况下使用聚类方法检测到的低丰度蛋白量提升更明显。
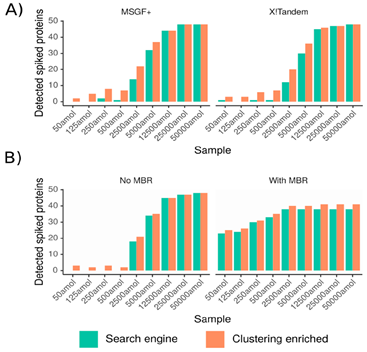
图 2:横坐标为加入的不同摩尔数的标记UPS1蛋白,纵坐标为检测到的标记UPS1蛋白量,并根据是否使用聚类算法将结果表示为橙绿两种颜色。其中:(A)基于谱图数计数,分别使用MSGF+与X!Tandem搜索引擎;(B)基于峰强计数,并分为是否使用MBR(match-between-runs,边运行边匹配)两种情况。
2、将结果蛋白中有标记的视为真阳性,属于背景蛋白的视为假阳性,通过改变判断结果蛋白是否达标的阈值,绘制出聚类方法在不同情况下与常规方法效果的比对图,曲线面积越大说明越能在更低的假阳性率下获得更高的真阳性率。从图中我们可以看出聚类方法在大部分情况下都对结果有所改善。

图 3:分别使用limma对(A,B)和edgeR对(C)做出统计分析,横坐标为假阳性率,纵坐标为真阳性率,线的颜色代表是否使用聚类方法,虚实代表是否使用MBR(A,B)或所用搜索引擎种类(C)。 其中:(A)基于峰强计数,使用三个CPTAC数据集得到的结果。 (B)基于峰强计数,三种浓度比得出结果。(C)基于谱图数计数,三种浓度比得出结果。
文章亮点:
本文最大的亮点在于将其开发的光谱聚类算法整合到了广泛使用的PD软件套件中,使其更容易被更广泛的蛋白质组学界所用。能直接使用的PD节点可在http://ms.imp.ac.at/?goto=spectra-cluster 下载。此外,聚类方法不依赖数据库,但可以直接使用库里的谱图,这使其有着更高的灵敏度。
解读人:刘佳维,Spectral Clustering Improves Label-Free Quantification of Low-Abundant Proteins(谱图聚类改善了低丰度蛋白的无标记定量)的更多相关文章
- Comparing Data-Independent Acquisition and Parallel Reaction Monitoring in Their Abilities To Differentiate High-Density Lipoprotein Subclasses 比较DIA和PRM区分高密度脂蛋白亚类的能力 (解读人:陈凌云)
文献名:Comparing Data-Independent Acquisition and Parallel Reaction Monitoring in Their Abilities To Di ...
- 【聚类算法】谱聚类(Spectral Clustering)
目录: 1.问题描述 2.问题转化 3.划分准则 4.总结 1.问题描述 谱聚类(Spectral Clustering, SC)是一种基于图论的聚类方法——将带权无向图划分为两个或两个以上的最优子图 ...
- Dysregulation of Exosome Cargo by Mutant Tau Expressed in Human-induced Pluripotent Stem Cell (iPSC) Neurons Revealed by Proteomics Analyses(蛋白质组学揭示了人诱导的多能干细胞(iPSC)神经元中表达的突变Tau对外泌体的失调) 解读人:梁玉婷
期刊名:MCP 发表时间:(2020年4月) IF:4.828 单位:Skaggs School of Pharmacy and Pharmaceutical Sciences, University ...
- Quantitative Proteomics of Enriched Esophageal and Gut Tissues from the Human Blood Fluke Schistosoma mansoni Pinpoints Secreted Proteins for Vaccine Development (解读人:张聪敏)
文献名:Quantitative Proteomics of Enriched Esophageal and Gut Tissues from the Human Blood Fluke Schist ...
- Fast and accurate bacterial species identification in urine specimens using LC-MS/MS mass spectrometry and machine learning (解读人:闫克强)
文献名:Fast and accurate bacterial species identification in urine specimens using LC-MS/MS mass spectr ...
- Multi-batch TMT reveals false positives, batch effects and missing values(解读人:胡丹丹)
文献名:Multi-batch TMT reveals false positives, batch effects and missing values (多批次TMT定量方法中对假阳性率,批次效应 ...
- Uncovering thousands of new peptides with sequence-mask-search hybrid de novo peptide sequencing framework (使用序列掩码搜索结合肽段从头测序框架发现了数千个新肽段)-解读人:刘佳维
期刊名:Molecular & Cellular Proteomics 发表时间:(2019年12月) IF:4.828 单位: 朱拉隆功大学 费城威斯塔研究所 物种:人 技术:de novo ...
- 谱聚类 Spectral Clustering
转自:http://www.cnblogs.com/wentingtu/archive/2011/12/22/2297426.html 如果说 K-means 和 GMM 这些聚类的方法是古代流行的算 ...
- 漫谈 Clustering (4): Spectral Clustering
转:http://blog.pluskid.org/?p=287 如果说 K-means 和 GMM 这些聚类的方法是古代流行的算法的话,那么这次要讲的 Spectral Clustering 就可以 ...
随机推荐
- 表达式计算-----------eval()运算符
1.java的eval()方法(或称之为运算符)可以将字符串解析成可以运行的javaScript代码,例如 eval()只有一个参数.如果传入的参数不是一个字符串,那么它会直接返回这个参数.如果传入的 ...
- IP通信中音频编解码技术与抗丢包技术概要
此文较长,建议收藏起来看. 一.一个典型的IP通信模型 二.Server2Server技术分类 Server2Server这块也是一个专门的领域,这里只简单分个类. 1.同一国家相同运营商之间: 同一 ...
- bzoj 1941 [Sdoi2010]Hide and Seek——KDtree
题目:https://www.lydsy.com/JudgeOnline/problem.php?id=1941 第二道KDtree! 枚举每个点,求出距离它的最远和最近距离.O( n * logn ...
- MongoDB优化之三:如何排查MongoDB CPU利用率高的问题
遇到这个问题,99.9999% 的可能性是「用户使用上不合理导致」,本文主要介绍从应用的角度如何排查 MongoDB CPU 利用率高的问题. Step1: 分析数据库正在执行的请求 用户可以通过 M ...
- java内存模型(netty权威指南)
1.Java内存模型 Java虚拟机规范中试图定义一种java内存模型(java Memory Model,jmm)来屏蔽掉各种操作系统.虚拟机实现厂商和硬件的内存访问差异,以确保Java程序在所有操 ...
- Centos开启telnet/ssh/ftp/sftp服务
Telnet 开启telnet服务步骤: 1. 查看CentOS/Telnet_server版本:#cat /etc/issue, #rpm -qa | grep telnet 2. 安装 ...
- Debain install Jupyter
1. install Anaconda https://www.anaconda.com/download/#linux 2. config jupyter $ ipython from notebo ...
- python 基础 进程与线程
多进程 使用multipprocessing模块创建多进程 multiprocessing模块提供了一个Process类来描述一个进程对象.创建子进程时,需要传入一个执行函数和函数的参数.用start ...
- LAMP 1.6 Discuz打开错误
打开discuz失败, ps aux |grep mysql ps aux |grep httpd 查看mysql apache有没有打开. 重启mysql service mysqld restar ...
- #410div2C. Mike and gcd problem
C. Mike and gcd problem time limit per test 2 seconds memory limit per test 256 megabytes input stan ...