Convolutional Neural Networks for Visual Recognition 4
Modeling one neuron
下面我们开始介绍神经网络,我们先从最简单的一个神经元的情况开始,一个简单的神经元包括输入,激励函数以及输出。如下图所示:
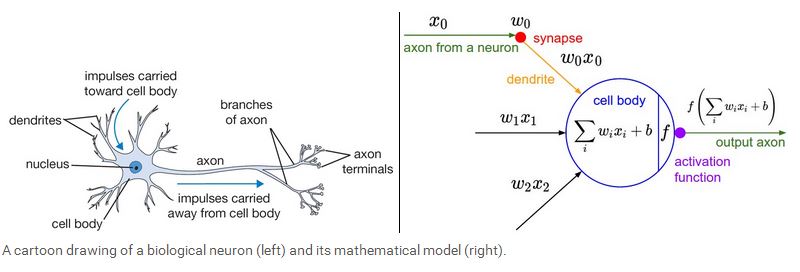
一个神经元类似一个线性分类器,如果激励函数是sigmoid 函数(σ(x)=1/(1+e−x)),那么σ(∑iwixi+b)相当于是求该输入所对应的输出为1的概率,P(y=1|xi;w),那么该输入所对应的输出为0的概率为 P(y=0|xi;w)=1−P(y=1|xi;w)。在神经网络中,常用的激励函数一个是sigmoid函数,另一个是tanh 函数。他们的曲线如下图所示:
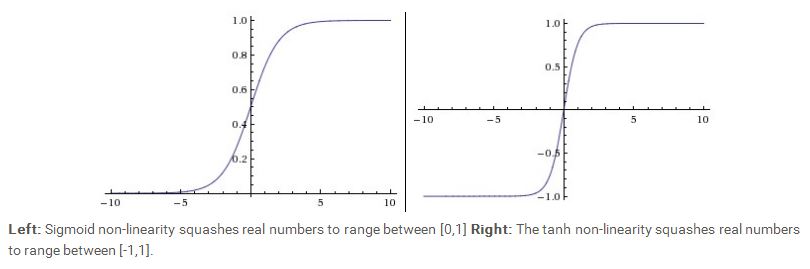
我们可以看到,sigmoid 函数的取值范围在(0,1)之间,而tanh 函数的取值范围在 (-1,1)之间。从图中可以看到,当sigmoid 函数的取值靠近0或者1时,它的梯度接近0,由于梯度在back propagation中有着非常重要的传递作用,因此如果梯度值太小,信息将无法传递。另外还有常见的几种激励函数比如Rectified Linear Unit(RLU), f(x)=max(0,x),这个函数相当于保证所有的输出都大于0,这个函数的优点是它收敛地比sigmoid,tanh函数要快,而且运算代价相对要低。这个函数的一个缺陷是在训练的过程中,可能导致神经元最后处于“休克”状态,基本毫无反应。因为梯度有可能为0,这样的话,信息就无法传递。为了克服这个hard threshold带来的这个问题,所以有一种激励函数称为 Leaky ReLU,f(x)=1{x<0}(αx)+1{x>=0}(x),对于x<0的情况,梯度不再为0,而是一个很小的常数α。有的实验证明用这种激励函数可以取得不错的分类效果,但是性能不是很稳定。还有一类激励函数称为maxout,这类激励函数用一个非线性运算max(wT1x1+b,wT2x2+b)来求得输出,maxout拥有RLU 的优点,而且避免了神经元“休克”的问题,不过maxout的一个缺陷是运算的参数增加了一倍。
我们将几种常见的激励函数归纳如下:
Sigmoid 函数:f(x)=1/(1+e−x))
tanh 函数:f(x)=1−e−2x1+e−2x
RLU 函数: f(x)=max(0,x)
Leak ReLU 函数:f(x)=1{x<0}(αx)+1{x>=0}(x)
maxout 函数:f(x)=max(wT1x1+b,wT2x2+b)
Neural Network architectures
下面我们开始介绍神经网络,一个完整的神经网络包括输入层,隐含层,以及输出层。最常见的一种神经网络就是 fully-connected 型。如下图所示。我们可以看到,上一层的每一个神经元与下一层的每一个神经元都相连,左边的神经网络含有一个隐含层,右边的神经网络含有两个隐含层,当我们计算神经网络的层数时,我们会忽略输入层,所以左边的神经网络是一个两层的(一个隐含层加一个输出层),右边的神经网络是一个三层的(两个隐含层加一个输出层),输出层有的时候可以含有激励函数,也可以不含有激励函数,看网络设计的需求而定。
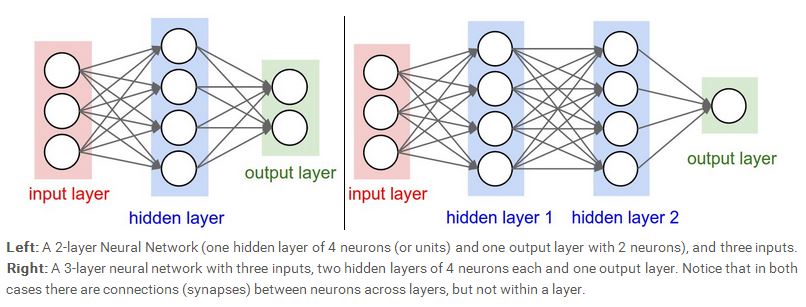
那么,神经网络的presentation power到底有多大呢,理论上,一个只含一层隐含层的神经网络模型可以表示任何复杂的函数。所以在机器学习领域,还在争论的一个问题
就是有没有必要利用deep神经网络,既然一个隐含层的shallow神经网络已经足够应付所有复杂的函数,deep 神经网络的优势目前看来是一种经验上的观察,虽然在理论上
与shallow神经网络相比没有太大优势。而且在实际使用中,三层的神经网络比两层的性能要好,但是再深一点的神经网络,比如四,五,六层的神经网络性能已经没有什么
提高了,这点与Convoluational 神经网络有点不太一样,在Convoluational 神经网络结构中,deepth 是一个很重要的保证网络性能的指标。
我们在设计神经网络的时候,要根据实际的问题,选择神经网络的结构,层数,隐含层神经元的个数,因为输入层和输出层基本由问题本身决定。一般来说,随着隐含层数的增加,以及隐含层里神经元个数的增加,网络的representation power会越大。我们可以看看如下的示例图。下图表示的是一个二分类问题,红点表示一类,绿点表示另外一类,利用一个两层的神经网络去学习这些数据,我们看到,随着神经元个数的增加,网络的拟合功能越来越强,当N=20时,所有的红点与绿点都完全区分开来了,所以说,神经元越多,网络就能表示越复杂的函数,但是随之而来的另外一个问题就是overfitting,如果一个网络过于专注数据中的噪声,而忽略了数据潜在的联系,就会出现overfitting。如下图所示,当N=20时,网络可以拟合所有的红点,但是却将平面分割地支离破碎,这种情况下,虽然网络的拟合能力很好,但是generalization能力却很差,意味着测试的性能会很糟糕。从这个例子看来,当数据不是很复杂的时候,似乎小的神经网络可以更好的控制overfitting的问题,但是事实上并非如此,我们一般不会用减少神经元个数的方法来控制overfitting,我们会用很多其他的方法来控制(比如 L2 regularization, dropout, input noise),这些会在后面的课程中介绍。
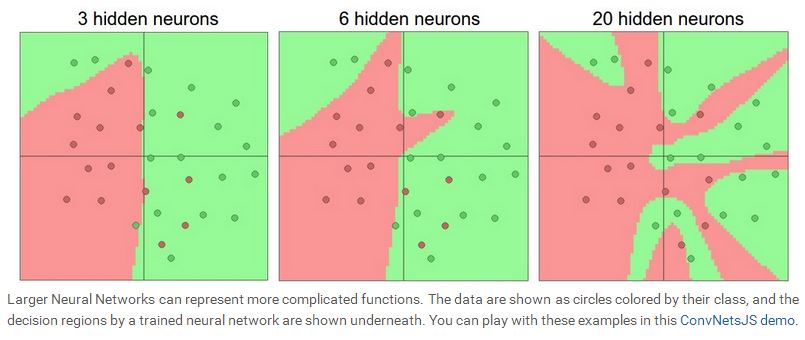
事实上,小规模的神经网络的一个缺点在于训练的难度,因为小的神经网络representation power有限,所以训练的自由度也相对较小,用梯度下降算法训练的时候,有可能陷入局部最小值,小规模的神经网络的局部最小值相对也较少,但是可能会很快收敛到这些局部最小值,这些极值有些会使网络的性能会很好,但是有些可能让网络性能很差,而大规模的神经网络局部最小值会很多,而且这些与实际误差相关的局部最小值会使网络的性能相对稳定。一般来说,小规模的神经网络性能会有很大的起伏,有的时候严重依赖于权值的初始值,而大规模的神经网络性能相对稳定,对权值的初始值依赖较少。
事实上,我们会利用regularization 去控制大规模网络的overfitting问题,下图给出了引入regularization 之后,N=20的神经网络的训练结果:
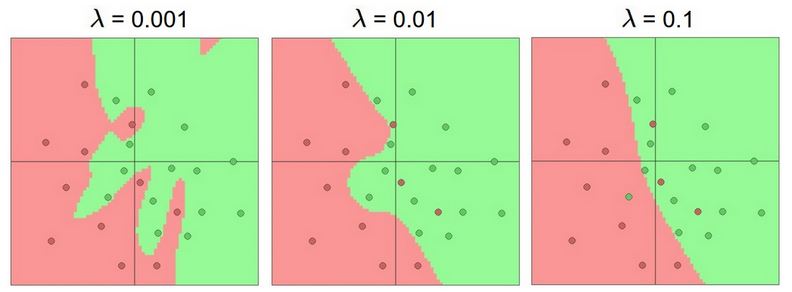
我们看到,随着regularization的增加,神经网络的分界面越来越平滑。
声明:lecture notes里的图片都来源于该课程的网站,只能用于学习,请勿作其它用途.
如需转载,请说明该课程为引用来源。http://cs231n.stanford.edu/
Convolutional Neural Networks for Visual Recognition 4的更多相关文章
- Convolutional Neural Networks for Visual Recognition 1
Introduction 这是斯坦福计算机视觉大牛李菲菲最新开设的一门关于deep learning在计算机视觉领域的相关应用的课程.这个课程重点介绍了deep learning里的一种比较流行的模型 ...
- Convolutional Neural Networks for Visual Recognition
http://cs231n.github.io/ 里面有很多相当好的文章 http://cs231n.github.io/convolutional-networks/ Table of Cont ...
- 卷积神经网络用于视觉识别Convolutional Neural Networks for Visual Recognition
Table of Contents: Architecture Overview ConvNet Layers Convolutional Layer Pooling Layer Normalizat ...
- Convolutional Neural Networks for Visual Recognition 8
Convolutional Neural Networks (CNNs / ConvNets) 前面做了如此漫长的铺垫,现在终于来到了课程的重点.Convolutional Neural Networ ...
- Convolutional Neural Networks for Visual Recognition 5
Setting up the data and the model 前面我们介绍了一个神经元的模型,通过一个激励函数将高维的输入域权值的点积转化为一个单一的输出,而神经网络就是将神经元排列到每一层,形 ...
- Convolutional Neural Networks for Visual Recognition 2
Linear Classification 在上一讲里,我们介绍了图像分类问题以及一个简单的分类模型K-NN模型,我们已经知道K-NN的模型有几个严重的缺陷,第一就是要保存训练集里的所有样本,这个比较 ...
- Convolutional Neural Networks for Visual Recognition 7
Two Simple Examples softmax classifier 后,我们介绍两个简单的例子,一个是线性分类器,一个是神经网络.由于网上的讲义给出的都是代码,我们这里用公式来进行推导.首先 ...
- cs231n spring 2017 lecture1 Introduction to Convolutional Neural Networks for Visual Recognition 听课笔记
1. 生物学家做实验发现脑皮层对简单的结构比如角.边有反应,而通过复杂的神经元传递,这些简单的结构最终帮助生物体有了更复杂的视觉系统.1970年David Marr提出的视觉处理流程遵循这样的原则,拿 ...
- Stanford CS231n - Convolutional Neural Networks for Visual Recognition
网易云课堂上有汉化的视频:http://study.163.com/course/courseLearn.htm?courseId=1003223001#/learn/video?lessonId=1 ...
随机推荐
- mysql 存储过程初探
使用存储过程好处在于: 1.隐藏敏感的算法,避免被正常的开发人员看到,把业务逻辑隐藏在数据库中,而非程序代码里 2.简化应用代码程序,放到数据库里肯定就对程序代码简化有好处了 3.不同的开发语言都可以 ...
- Vue实现组件props双向绑定解决方案
注意: 子组件不能直接修改prop过来的数据,会报错 方案一: 用data对象中创建一个props属性的副本 watch props属性 赋予data副本 来同步组件外对props的修改 watch ...
- LR报错 No buffer space available Try changing the registry value 端口号不够用了
报错:Action.c(6): Error -27796: Failed to connect to server "10.16.137.8:10035": [10055] No ...
- 【BZOJ2422】Times 树状数组
[BZOJ2422]Times Description 小y作为一名资深的dotaer,对视野的控制有着深刻的研究.每个单位在一段特定的时间内会出现在小y的视野内,除此之外的时间都在小y看不到的地方. ...
- [转]linux terminal中使用proxy
转自:http://www.cnblogs.com/JoJosBizarreAdventure/p/5892383.html 在linux terminal中使用代理 方法一: terminal中输入 ...
- 小团队Git协作流程
git和svn 最大的差异在于git是分布式的管理方式而svn是集中式的管理方式. 集中式 集中式代码管理的核心是服务器,所有开发者在开始coding之前必须从服务器获取代码,然后开发,最后解决冲突, ...
- ubuntu 安装wine
笔记 1.安装源 sudo add-apt-repository ppa:wine/wine-builds sudo apt-get update 2.安装wine sudo apt-get inst ...
- Linux显示网络相关信息
netstat -tlun 查看本机监听的端口 netstat -an 查看本机所有的网络连接 netstat -rn 查看本机路由表 -t TCP协议 -u UDP协议 - ...
- Python 中奇妙的下划线
单个下划线(_) 通常有三种用法: 在python解释器: 单个下划线代表上次在交互解释期对话中(控制台)执行的结果.这种情况在标准的CPython解释器中首次被实现,接下来这种习惯也被保持下来: & ...
- 两个Java项目之间相互调用
转自:http://dysfzhoulong.iteye.com/blog/1008747 一个项目A另一个项目B:(项目A和项目B都是Java写的项目) 在A项目中怎么调用B项目中的类和方法 有两种 ...