How MapReduce Works(转)
原文地址:http://www.cnblogs.com/ggjucheng/archive/2012/04/23/2465820.html
一、从Map到Reduce
MapReduce其实是分治算法的一种实现,其处理过程亦和用管道命令来处理十分相似,一些简单的文本字符的处理甚至也可以使用Unix的管道命令来替代,从处理流程的角度来看大概如下:
cat input | grep | sort | uniq -c | cat > output
# Input -> Map -> Shuffle & Sort -> Reduce -> Output
简单的流程图如下:
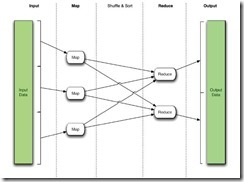
对于Shuffle,简单地说就是将Map的输出通过一定的算法划分到合适的Reducer中进行处理。Sort当然就是对中间的结果进行按key排序,因为Reducer的输入是严格要求按key排序的。
Input->Map->Shuffle&Sort->Reduce->Output只是从宏观的角度对MapReduce的简单描述,实际在MapReduce的框架中,即从编程的角度来看,其处理流程是Input->Map->Sort->Combine->Partition->Reduce->Output。用之前的对温度进行统计的例子来讲述这些过程。
Input Phase
输入的数据需要以一定的格式传递给Mapper的,格式有多种,如TextInputFormat、DBInputFormat、SequenceFileInput等等,可以使用JobConf.setInputFormat来设置,这个过程还应该包括对输入的数据进行任务粒度划分(split)然后再传递给Mapper。在温度的例子中,由于处理的都是文本数据,输入的格式使用默认的TextInputFormat即可。
Map Phase
对输入的key、value对进行处理,输出的是key、value的集合,即map (k1, v1) -> list(k2, v2),使用JobConf.setMapperClass设置自己的Mapper。在例子中,将(行号、温度的文本数据)作为key/value输入,经过处理后,从温度的文件数据中提取出日期中的年份和该日的温度数据,形成新的key/value对,最后以list(年, 温度)的结果输出,如[(1950, 10), (1960, 40), (1960, 5)]。
Sort Phase
对Mapper输出的数据进行排序,可以通过JobConf.setOutputKeyComparatorClass来设置自己的排序规则。在例子中,经过排序之后,输出的list集合是按年份进行排序的list(年, 温度),如[(1950, 10), (1950, 5), (1960, 40)]。
Combine Phase
这个阶段是将中间结果中有相同的key的<key, value>对合并成一对,Combine的过程与Reduce很相似,使用的甚至是Reduce的接口。通过Combine能够减少<key, value>的集合数量,从而减少网络流量。Combine只是一个可选的优化过程,并且无论Combine执行多少次(>=0),都会使Reducer产生相同的输出,使用JobConf.setCombinerClass来设置自定义的Combine Class。在例子中,假如map1产生出的结果为[(1950, 0), (1950, 20), (1950, 10)],在map2产生出的结果为[(1950, 15), (1950, 25)],这两组数据作为Reducer的输入并经过Reducer处理后的年最高温度结果为(1950, 25),然而当在Mapper之后加了Combine(Combine先过滤出最高温度),则map1的输出是[(1950, 20)]和map2的输出是[(1950, 25)],虽然其他的三组数据被抛弃了,但是对于Reducer的输出而言,处理后的年最高温度依然是(1950, 25)。
Partition Phase
把Mapper任务输出的中间结果按key的范围划分成R份(R是预先定义的Reduce任务的个数),默认的划分算法是”(key.hashCode() & Integer.MAX_VALUE) % numPartitions”,这样保证了某一范围的key一定是由某个Reducer来处理,简化了Reducer的处理流程,使用JobConf.setPartitionClass来设置自定义的Partition Class。在例子中,默认就自然是对年份进行取模了。
Reduce Phase
Reducer获取Mapper输出的中间结果,作为输入对某一key范围区间进行处理,使用JobConf.setReducerClass来设置。在例子中,与Combine Phase中的处理是一样的,把各个Mapper传递过来的数据计算年最高温度。
Output Phase
Reducer的输出格式和Mapper的输入格式是相对应的,当然Reducer的输出还可以作为另一个Mapper的输入继续进行处理。
二、Details of Job Run
上面只是从task运行中描述了Map和Reduce的过程,实际上当从运行”hadoop jar”开始还涉及到很多其他的细节。从整个Job运行的流程来看,如下图所示:
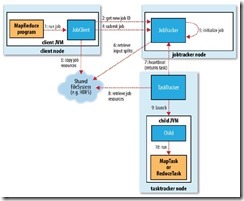
从上图可以看到,MapReduce运行过程中涉及有4个独立的实体:
1. Client,用于提交MapReduce job。
2. JobTracker,负责协调job的运行。
3. TaskTrackers,运行 job分解后的多个tasks,task主要是负责运行Mapper和Reducer。
4. Distributed filesystem,用于存储上述实体运行时共享的job文件(如中间结果文件)。
Job Submission
当调用了JobClient.runJob()之后,Job便开始被提交了,在Job提交这个步骤中,经历了以下的过程:
1. Client向JobTacker申请一个新的job ID(step 2),job ID形如job_200904110811_0002的格式,是由JobTracker运行当前的job的时间和一个由JobTracker维护的自增计数(从1开始)组成的。
2. 检查job的output specification,比如输出目录是否已经存在(存在则抛异常)、是否有权限写等等。
3. Computes the input splits for the job,这些input splits就是作为Mapper的输入。
4. Copies the resources needed to run the job, including the job JAR file, the configuration file and the computed input splits, to the jobtracker’s filesystem in a direcotry named after the job ID(step 3)。
5. Tells the jobtracker that the job is ready for execution(step 4)。
Job Initialization
当JobTracker收到Job提交的请求后,将job保存在一个内部队列,并让Job Scheduler处理并初始化。初始化涉及到创建一个封装了其tasks的job对象,并保持对task的状态和进度的根据(step 5)。当创建要运行的一系列task对象后,Job Scheduler首先开始从文件系统中获取由JobClient计算的input splits(step 6),然后再为每个split创建map task。
Task Assignment
TaskTrackers会使用一个简单的loop为定期向JobTracker发送heartbeat调用,发送的间隔时间大约5秒,一般取决于集群服务器的规模和繁忙程度以及网络拥挤程度。这个heartbeat一方面是告知JobTracker当前TaskTracker处于live状态,同时是用于JobTracker和TaskTracker进行通信,TaskTracker会根据heartbeat的返回值来执行一定的操作(step 7)。
To choose a reduce task the JobTracker simply takes the next in its list of yet-to-be-run reduce tasks, since there are no data locality considerations. For a map task, however, it takes account of the TaskTracker’s network location and picks a task whose input splits is as close as possible to the tasktracker. In the optimal case, the task is data-local, that is , running on the same node that the split resides on. Alternatively, the task may be rack-local: on the same rack, but not the same node, as the split.
Task Execution
当TaskTrack被分配到一个task之后,接下来就是运行这个task。首先,它会需要的job JAR文件从shared filesystem拷贝到local filesystem,然后创建一个working direcotry并un-jars拷贝的JAR文件到该directory,最后就创建一个TaskRunner对象运行task。
TaskRunner在运行的时候是启动了一个新的JVM来run each task(step 10),这样是为了防止在用户自定义的Mapper出现异常令JVM挂了,从而连累到TaskTracker。TaskRunner子进程会使用umbilical接口和TaskTracker通信并每隔几秒向TaskTracker汇报进度。
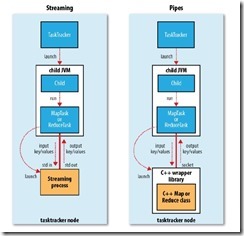
对于使用Streaming和Pipes方式来创建的Mapper,也是作为TaskTracker的子进程来运行的。Streaming是使用标准输入输出来通信,而Pipes是使用socket来进行通信,如下图:
Progress and Status Updates
进度和状态是通过heartbeat来更新和维护的。来对于Map Task,进度就是已处理数据和所有输入数据的比例。对于Reduce Task,情况就有点复杂,包括3部分,拷贝中间结果文件、排序、Reduce调用,每部分占1/3。
Job Completion
当Job完成后,JobTracker会收一个Job Complete的通知,并将当前的Job状态更新为Successful,同时JobClient也会轮循获知提交的Job已经完成,将信息显示给用户。最后,JobTracker会清理和回收该Job的相关资源,并通知TaskTracker进行相同的操作(比如删除中间结果文件)。
How MapReduce Works(转)的更多相关文章
- How MapReduce Works
转自:http://blog.csdn.net/luyee2010/article/details/8624470 一.从Map到Reduce MapReduce其实是分治算法的一种实现,其处理过程亦 ...
- hadoop权威指南 chapter2 MapReduce
MapReduce MapReduce is a programming model for data processing. The model is simple, yet not too sim ...
- MapReduce剖析笔记之三:Job的Map/Reduce Task初始化
上一节分析了Job由JobClient提交到JobTracker的流程,利用RPC机制,JobTracker接收到Job ID和Job所在HDFS的目录,够早了JobInProgress对象,丢入队列 ...
- 关于MapReduce中自定义Combine类(一)
MRJobConfig public static fina COMBINE_CLASS_ATTR 属性COMBINE_CLASS_ATTR = "mapreduce.j ...
- Kettle实现MapReduce之WordCount
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 欢迎转载 抽空用kettle配置了一个Mapreduce的Word count,发现还是很方便快捷的,废话不多说 ...
- MapReduce基础知识
hadoop版本:1.1.2 一.Mapper类的结构 Mapper类是Job.setInputFormatClass()方法的默认值,Mapper类将输入的键值对原封不动地输出. org.apach ...
- MapReduce之Mapper类,Reducer类中的函数(转载)
Mapper类4个函数的解析 Mapper有setup(),map(),cleanup()和run()四个方法.其中setup()一般是用来进行一些map()前的准备工作,map()则一般承担主要的处 ...
- Writing an Hadoop MapReduce Program in Python
In this tutorial I will describe how to write a simpleMapReduce program for Hadoop in thePython prog ...
- Python & MapReduce
使用Python实现Hadoop MapReduce程序 原文请参考: http://blog.csdn.net/zhaoyl03/article/details/8657031/ 下面只是将mapp ...
随机推荐
- Android文章收藏
Android集 1.Himi李华明的<Android游戏开发专栏>http://blog.csdn.net/column/details/androidgame.html2.老罗的&l ...
- struts2中怎样处理404?
眼下在做一个网络应用程序,struts2 + spring + hibernate,server是tomcat.希望用户在IE地址栏乱敲的时候.所敲入的全部没有定义的URL都能被程序捕捉到,然后转到一 ...
- python判断值是否为空
代码中经常会有变量是否为None的判断,有三种主要的写法: 第一种是`if x is None`: 第二种是 `if not x:`: 第三种是`if not x is None`(这句这样理解更清晰 ...
- oracle复合索引的选择和使用
声明:虽然题目是Oracle.但同样适合MySQL InnoDB索引 在大多数情况下.复合索引比单字段索引好 很多系统就是靠新建一些合适的复合索引.使效率大幅度提高 ...
- iOS UIView添加阴影
_bottomView.layer.masksToBounds = NO; _bottomView.backgroundColor = [UIColor whiteColor]; _bottomVie ...
- JAVA读取文件夹大小的几种方式
(一)单线程递归方式 package com.taobao.test; import java.io.File; public class TotalFileSizeSequential { publ ...
- 机器学习10—K-均值聚类学习笔记
机器学习实战之K-Means算法 test10.py #-*- coding:utf-8 import sys sys.path.append("kMeans.py") impor ...
- Google Code Jam 资格赛: Problem A. Magic Trick
Note: To advance to the next rounds, you will need to score 25 points. Solving just this problem wil ...
- Power of Cryptography - poj 2109
Time Limit: 1000MS Memory Limit: 30000K Total Submissions: 20351 Accepted: 10284 Description C ...
- shell 遍历所有文件包括子目录
1.代码简单,但是难在校验,不像python那么好理解 建议在Notepad++下编辑. 2.注意引用linux命令的`是[tab]键上面那个 3.if[] 这里 Error : syntax er ...