深度学习基础(四) Dropout_Improving neural networks by preventing co-adaptation of feature detectors
该笔记是我快速浏览论文后的记录,部分章节并没有仔细看,所以比较粗糙。
从摘要中可以得知,论文提出在每次训练时通过随机忽略一半的feature detectors(units)可以极大地降低过拟合。该方法能够防止feature detectors之间的complex co-adaptations,即feature detectors只有在一些其它特定的feature detectors存在时才能发挥作用的情况。经过实验证明,随机dropout能够在许多任务中带来很大的性能提升。
在训练集上通过使用dropout防止complex co-adatation能够有效地减少ovefitting。在每次训练时,每个hidden unit随机的以0.5的概率被网络忽略,所以最终训练好的模型中,hidden unit可以不依靠其它hidden units的存在就能得到correct output。我们都知道通过平均多个不同网络的预测输出可以很好地降低error,尽管这种方法训练和测试时计算代价巨大。Dropout的本质其实与之类似,当每次训练随机忽略部分hidden units的时候,就相当于在训练不同的模型。不同的是,dropout的时间开销和计算代价较低,因为a huge number of different networks 的hidden units共享相同的权重。
论文中提到,Dropout networks训练过程使用标准的随机梯度下降法,但是不再惩罚所有权重向量的L2 norm(penalty term)以防止权重太大,而是为每个hidden units的输入权重的L2 norm设定上界。使用约束而不是惩罚项除了能够防止权重太大,另一个好处是每次训练时的权重更新量多大都没关系。这样一来,网络在训练起始时就可以使用一个非常大的learnign rate,然后再随着训练衰减。很明显,这比刚开始使用较小的权重和学习速率要好很多。
在测试时,网络中的所有hidden uints都会被用来进行计算,但是网络最终的计算结果会被减半(*0.5),这是因为测试时激活的神经元数目是训练时的两倍。这实际上相当于对训练时的dropout networks的输出取平均。以一个单隐层网络为例,隐含层有N个units,输出层是softmax,用来计算类别概率。使用 ‘mean network’ 就相当于对所有2N个dropout networks的输出取均值。如果部分dropout networks的预测不正确,mean network输出log probability能够纠正,而不是对所有dropout networks的输出log probabilities取均值。在回归问题上也是如此。
dropout可以与预训练结合,但是训练时使用较小的学习速率并且不设权重约束以避免丢失预训练发现的feature detectors
dropout用于所有隐层比只用于一层隐层的效果要好很多,并且极端的dropout概率往往会使结果变差,这也是作者在论文中通篇使用0.5的原因。dropout也可以用于输入,使用时最好保留输入的50%以上不变。
Dropout过程
假如我们要训练如下的网络
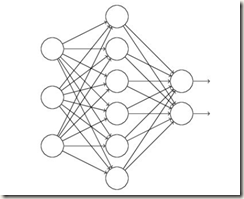
当输入是x,输出是y时,正常的流程是:先将x通过网络前向传播,然后将误差反向传播以更新参数,循环直至满足条件
使用Dropout后如下:
- 先忽略网络中一半的隐层神经元(每个神经元以0.5的概率被忽略),输入输出神经元不变(下图中虚线绘制的神经元表示被忽略的隐层神经元)
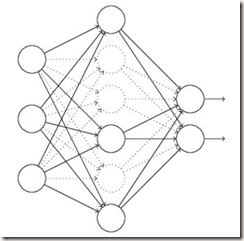
- 输入一批样本x通过删减后的网络前向传播,然后反向传播更新该网络的参数
- 网络恢复最初的结构,原先被忽略的神经元依然使用未更新的权重,保留的神经元使用更新的权重
- 重复这一过程直至停止
至于dropout为何可以减少过拟合?总结如下:
- 取平均的作用:我们用相同的数据取训练不同的N个网络,测试时会得到N个测试结果。此时我们可以利用N个结果取均值或采用多数取胜的投票策略决定最终的预测结果。这种综合多个模型取平均的策略可以有效的减少过拟合问题。因为不同的网络可能产生不同程度的拟合,取平均可能会让过拟合和欠拟合的结果相互抵消。Dropout在训练时忽略部分神经元其实就是在改变网络的结构,训练不同的网络。与多个网络不同的是这些网络会共享权重,因而训练测试的花销较低。最后测试时会恢复所有神经元,也就是所有dropout网络被交织在一起,这些网络中欠拟合和过拟合的dropout网络同样会相互抵消减轻过拟合,相当于多模型取平均
- 减少神经元之间复杂的共适应关系:因为dropout导致两个神经元不一定每次训练时都在同一个dropout网络中存在,那些原先依赖其它feature detectors才能发挥作用的feature detectors在训练时就不得不增强自身的作用,从而提高了网络的鲁棒性
Dropout和传统的bagging方法主要有以下两个方面不同:
- Dropout的每个子模型的权值是共享的;
- 在训练的每个step中,Dropout每次会使用不同的样本子集训练不同的子网络
此外,native bayes是dropout的一个特例。Native bayes有个错误的前提,即假设各个特征之间相互独立,这样在训练样本比较少的情况下,单独对每个特征进行学习,测试时将所有的特征都相乘,且在实际应用时效果还不错。而Droput每次不是训练一个特征,而是一部分隐含层特征。
还有一个比较有意思的解释是,Dropout类似于性别在生物进化中的角色,物种为了使适应不断变化的环境,性别的出现有效的阻止了过拟合,即避免环境改变时物种可能面临的灭亡。
参考资料
- Deep learning:四十一(Dropout简单理解)
- Dropout解决过拟合问题
- 理解dropout
- GoogLeNet, Maxout and NIN
- 论文:Improving neural networks by preventing co-adaptation of feature detectors
深度学习基础(四) Dropout_Improving neural networks by preventing co-adaptation of feature detectors的更多相关文章
- 深度学习基础系列(九)| Dropout VS Batch Normalization? 是时候放弃Dropout了
Dropout是过去几年非常流行的正则化技术,可有效防止过拟合的发生.但从深度学习的发展趋势看,Batch Normalizaton(简称BN)正在逐步取代Dropout技术,特别是在卷积层.本文将首 ...
- 深度学习基础系列(五)| 深入理解交叉熵函数及其在tensorflow和keras中的实现
在统计学中,损失函数是一种衡量损失和错误(这种损失与“错误地”估计有关,如费用或者设备的损失)程度的函数.假设某样本的实际输出为a,而预计的输出为y,则y与a之间存在偏差,深度学习的目的即是通过不断地 ...
- 算法工程师<深度学习基础>
<深度学习基础> 卷积神经网络,循环神经网络,LSTM与GRU,梯度消失与梯度爆炸,激活函数,防止过拟合的方法,dropout,batch normalization,各类经典的网络结构, ...
- TensorFlow深度学习基础与应用实战高清视频教程
TensorFlow深度学习基础与应用实战高清视频教程,适合Python C++ C#视觉应用开发者,基于TensorFlow深度学习框架,讲解TensorFlow基础.图像分类.目标检测训练与测试以 ...
- [笔记] 基于nvidia/cuda的深度学习基础镜像构建流程 V0.2
之前的[笔记] 基于nvidia/cuda的深度学习基础镜像构建流程已经Out了,以这篇为准. 基于NVidia官方的nvidia/cuda image,构建适用于Deep Learning的基础im ...
- Deep Learning 23:dropout理解_之读论文“Improving neural networks by preventing co-adaptation of feature detectors”
理论知识:Deep learning:四十一(Dropout简单理解).深度学习(二十二)Dropout浅层理解与实现.“Improving neural networks by preventing ...
- 论文笔记(1)-Dropout-Improving neural networks by preventing co-adaptation of feature detectors
Improving neural networks by preventing co-adaptation of feature detectors 是Hinton在2012年6月份发表的,从这篇文章 ...
- 深度学习基础(二)AlexNet_ImageNet Classification with Deep Convolutional Neural Networks
该论文是深度学习领域的经典之作,因为自从Alex Krizhevsky提出AlexNet并使用GPUs大幅提升训练的效率之后,深度学习在图像识别等领域掀起了研究使用的热潮.在论文中,作者训练了一个含有 ...
- 深度学习基础系列(四)| 理解softmax函数
深度学习最终目的表现为解决分类或回归问题.在现实应用中,输出层我们大多采用softmax或sigmoid函数来输出分类概率值,其中二元分类可以应用sigmoid函数. 而在多元分类的问题中,我们默认采 ...
随机推荐
- Java_Number(装箱和拆箱)
所有的包装类(Integer.Long.Byte.Double.Float.Short)都是抽象类Number子类 装箱: 自动将基本数据类型装换为包装器类型 拆箱: 自动将包装器类型转换为基本数据类 ...
- svn忽略不需要同步的文件夹或文件
如果某个文件已经提交到了svn,这个时候需要通过svn来把服务器上的改文件删除,然后再在本地,点击该文件 选择把该文件删除,recursively表示递归删除(文件下->下级文件夹->下级 ...
- nodejs入门篇之linux版的nodejs简易环境安装部署
第一步:下载二进制安装包 根据linux的不同版本选择32位或64位,因为我的linux的虚拟机是64位的,所以我选择的是64位二进制安装文件(Linux Binariesx64),可以右键选择在新窗 ...
- hdu5707-Combine String(DP)
Problem Description Given three strings a, b and c , your mission is to check whether c is the combi ...
- PTA L2-001 紧急救援 (带权最短路)
<题目链接> 题目大意: 作为一个城市的应急救援队伍的负责人,你有一张特殊的全国地图.在地图上显示有多个分散的城市和一些连接城市的快速道路.每个城市的救援队数量和每一条连接两个城市的快速道 ...
- Problem B. Beer Refrigerator
http://codeforces.com/gym/241680/problem/B比赛的时候考虑的是,它们3个尽可能接近,然后好麻烦,不如暴力枚举,这里不需要质因数分解,而是两重循环枚举所有因数,第 ...
- Hashmap误区
HashMap简介 HashMap 是一个散列表,它存储的内容是键值对(key-value)映射.HashMap 继承于AbstractMap,实现了Map.Cloneable.java.io.Ser ...
- 对《将Unreal4打包后的工程嵌入到Qt或者桌面中》一文的补充
在上一文中本人尝试将Ue4嵌入到Qt中,但依然有一些问题没有去尝试解决.今天因为帮助知乎专栏作者@大钊的关系,顺便进行补完. 2018.7.18更新: 正好在参加杭州UnrealCircle的时候见到 ...
- PageHelper补充
统计总数 Page<?> page = PageHelper.startPage(1,-1); long count = page.getTotal(); 分页 pageNum - 第N页 ...
- 【安全性测试】一个简单地绕前端暴XSS漏洞
在appscan暴出一个关于跨站点脚本编制的漏洞,但是appscan并不能完整地显示该漏洞.于是,工具是否出现误报,需要通过自己手工验证. 然后,我们需要找到目标参数的包并分析是从哪个步骤提交给服务器 ...