CentOS7 分布式安装 Hadoop 2.8
1. 基本环境
1.1 操作系统
操作系统:CentOS7.3
1.2 三台虚拟机
172.20.20.100 master
172.20.20.101 slave1
172.20.20.102 slave2
1.3 软件包
jdk-8u121-linux-x64.gz
hadoop-2.8.4.tar.gz
2. 环境配置
2.1 新建hadoop用户
useradd hadoop
通过passwd命令修改hadoop用户密码,启用hadoop用户。
passwd hadoop
2.2 配置ssh免密码登录
root和hadoop用户都进行ssh配置以方便主机间操作
详细配置参考另外一篇文章:ssh多台主机实现互相认证
2.3 修改hosts文件
需要在root用户下操作,hadoop用户没有修改权限
修改master主机hosts文件
vi /etc/hosts
添加以下内容:
172.20.20.100 master
172.20.20.101 slave1
172.20.20.102 slave2
2.4 同步hosts文件到其他主机
需要在root用户下操作,hadoop用户没有修改权限
2.1 步骤已经实现了ssh无密码登录,通过scp命令拷贝master主机hosts文件到slave1、slave2主机。
2.5 关闭主机防火墙
每台主机均需操作
# 关闭防火墙
systemctl stop firewalls.service #禁止防火墙开机启动
systemctl disable firewalls.service
2.6 关闭 selinux
每台主机均需操作
setenforce
vi /etc/sysconfig/selinux
修改 SELINUX 值为disabled
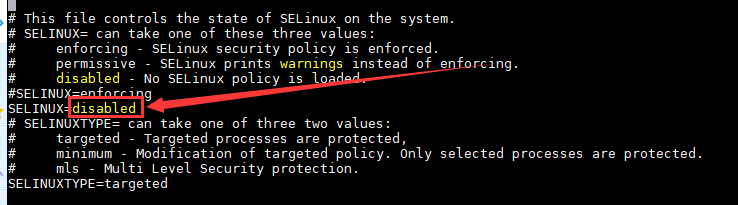
getenforce 命令查看 selinux状态为disabled

2.7 安装Java JDK
(1)oracle官网下载 jdk-8u121-linux-x64.gz,版本可以根据自己情况做调整。
(2)解压 jdk-8u121-linux-x64.gz 到 /opt/java 目录下。
(3)配置 jdk环境变量。修改/etc/profile 文件,追加以下内容:
#Java
export JAVA_HOME=/opt/java/jdk1..0_121
export PATH=$PATH:${JAVA_HOME}/bin
export CLASSPATH=.:${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar
修改完毕后,执行 source /etc/profile,通过 java -version 命令查看是否安装成功。

(4)在每台机器上都安装jdk(也可同通过scp命令拷贝/etc/profile 和 /opt/java 实现),hadoop集群要求每台运行主机必须安装jdk。
3. Hadoop 安装
3.1 服务器功能规划
| master | slave1 | slave2 |
|---|---|---|
| NameNode | ResourceManage | |
| DataNode | DataNode | DataNode |
| NodeManager | NodeManager | NodeManager |
| HistoryServer | SecondaryNameNode |
3.2 在master主机上安装hadoop
注意:切换到hadoop用户
(1) 解压hadoop-2.8.4.tar.gz至 /opt目录下
tar -zxvf hadoop-2.8..tar.gz
(2) 配置Hadoop JDK路径
修改 hadoop 解压缩后 etc目录下 hadoop-env.sh、mapred-env.sh、yarn-env.sh文件中的JDK路径
export JAVA_HOME=/opt/java/jdk1..0_121
(3) 配置core-site.xml
<configuration>
<!-- 指定NameNode主机和hdfs端口 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
<!-- 指定tmp文件夹路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/data/tmp</value>
</property>
</configuration>
fs.defaultFS 为 NameNode 的地址,hadoop.tmp.dir 为hadoop临时目录的地址,默认情况下,NameNode和DataNode的数据文件都会存在这个目录下的对应子目录下。应该保证此目录是存在的,如果不存在,先创建。
(4) 配置hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave2:50090</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/data/dfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/data/dfs/datanode</value>
</property>
dfs.namenode.secondary.http-address是指定secondaryNameNode的http访问地址和端口号,因为在规划中,我们将slave2规划为SecondaryNameNode服务器。所以这里设置为:slave2:50090;dfs.namenode.name.dir 指定 NameNode 数据存放路径;dfs.datanode.data.dir 指定 DataNode 数据存放路径;注意,要提前创建好/home/hadoop/data/dfs 文件夹。
(5) 配置slaves
修改hadoop etc目录下slaves文件
vi slaves
修改其内容为:
master
slave1
slave2
slaves文件是指定HDFS DataNode 工作节点。
(6) 配置 yarn-site.xml
vi yarn-site.xml
添加以下属性:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>slave1</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>106800</value>
</property>
根据规划yarn.resourcemanager.hostname这个指定resourcemanager服务器指向slave1。
yarn.log-aggregation-enable是配置是否启用日志聚集功能。
yarn.log-aggregation.retain-seconds是配置聚集的日志在HDFS上最多保存多长时间。
(7) 配置mapred-site.xml
从mapred-site.xml.template复制一个mapred-site.xml文件。
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
mapreduce.framework.name设置mapreduce任务运行在yarn上。
mapreduce.jobhistory.address是设置mapreduce的历史服务器安装在master机器上。
mapreduce.jobhistory.webapp.address是设置历史服务器的web页面地址和端口号。
(8) 分发Hadoop文件
master主机hadoop解压目录为 /opt/software,在slave1和slave2 分别新建目录 /opt/software
mkdir /opt/software
然后通过scp分发hadoop安装文件。
scp -r /opt/software/hadoop-2.8. slave1:/opt/software/
scp -r /opt/software/hadoop-2.8. slave2:/opt/software/
(9) 配置Hadoop 环境变量
su root
vi /etc/profile
添加如下配置:
#hadoop
export HADOOP_HOME=/opt/software/hadoop-2.8.
export PATH=$PATH:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
修改完成,保存后执行 source /etc/profile 命令,然后scp命令,拷贝/etc/profile 文件至 slave1和 slave2 主机。
scp /etc/profile slave1:/etc/profile
scp /etc/profile slave2:/etc/profile
同样在slave1和slave2 主机上执行 source /etc/profile 重新加载配置信息。
(10) NameNode 格式化
在NameNode机器上执行格式化
$HADOOP_HOME/bin/hdfs namenode –format
注意:
如果需要重新格式化NameNode,需要先将原来NameNode和DataNode下的文件全部删除,不然会报错,NameNode和DataNode所在目录是在hdfs-site.xml中hadoop.tmp.dir、dfs.namenode.name.dir、dfs.datanode.data.dir属性配置的。
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/data/dfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/data/dfs/datanode</value>
</property>
因为每次格式化,默认是创建一个集群ID,并写入NameNode和DataNode的VERSION文件中(VERSION文件所在目录为dfs/name/current 和 dfs/data/current),重新格式化时,默认会生成一个新的集群ID,如果不删除原来的目录,会导致NameNode中的VERSION文件中是新的集群ID,而DataNode中是旧的集群ID,不一致时会报错。
另一种方法是格式化时指定集群ID参数,指定为旧的集群ID。
4. 启动集群
4.1 启动HDFS
[hadoop@master ~]$ $HADOOP_HOME/sbin/start-dfs.sh

jps 命令查看进程启动情况,能看到master主机启动了 NameNode 和 DataNode进程。
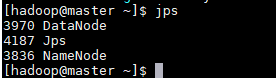
从启动输出信息可以看出NameNode、DataNode和 SecondaryNameNode 启动情况。
4.2 启动YARN
ssh连接到slave1主机,ResourceManager 服务运行主机。
ssh slave1
$HADOOP_HOME/sbin/start-yarn.sh

jps命令,查看slave1主机运行进程。
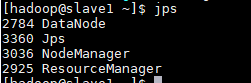
注意,如果不在ResourceManager主机上运行 $HADOOP_HOME/sbin/start-yarn.sh 命令的话,ResourceManager 进程将不会启动,需要到 ResourceManager 主机上执行yarn-daemon.sh start resourcemanager 命令来启动ResourceManager进程。
$HADOOP_HOME/sbin/yarn-daemon.sh start resourcemanager
4.3 启动日志服务器
因为我们规划的是在master服务器上运行MapReduce日志服务,所以要在slave2上启动。
[hadoop@master ~]$ $HADOOP_HOME/sbin/mr-jobhistory-daemon.sh start historyserver

4.4 查看HDFS Web页面
地址为 NameNode 进程运行主机ip,端口为50070,http://172.20.20.100:50070 。

4.5 查看YARN Web页面
地址为ResourceManager 进程运行主机,http://172.20.20.101:8088

4.6 查看JobHistory Web 页面
地址为JobHistoryServer 进程运行主机ip,端口为19888,通过配置文件查看自己的JobHistory web端口,http://172.20.20.100:19888
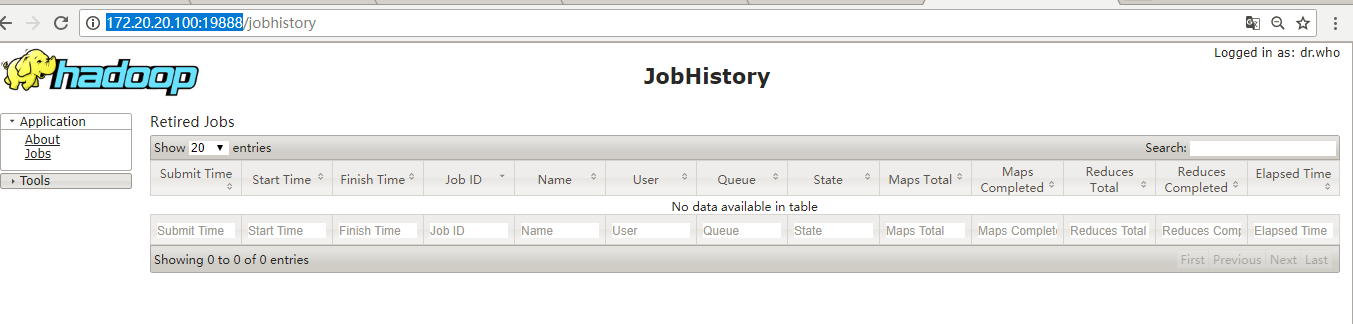
至此,已经完成Hadoop 分布式安装。
5. 测试Job
5.1 准备mapreduce输入文件wc.input
[hadoop@master ~]$ cat wc.input
hadoop mapreduce hive
hbase spark storm
sqoop hadoop hive
spark hadoop
5.2 在HDFS创建输入目录input
[hadoop@master ~]$ $HADOOP_HOME/bin/hdfs dfs -mkdir input
5.3 将wc.input 上传到HDFS
[hadoop@master ~]$ $HADOOP_HOME/bin/hdfs dfs -put wc.input /input
5.4 运行hadoop自带的mapreduce Demo
[hadoop@master ~]$ yarn jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8..jar wordcount /input/wc.input /output
因为/etc/profile文件中已配置过hadoop环境变量,所以可以直接运行yarn命令,如下所示为执行结果。


5.5 查看输出文件
[hadoop@master ~]$ hdfs dfs -ls /output/ [hadoop@master ~]$ hdfs dfs -cat /output/part-r-

CentOS7 分布式安装 Hadoop 2.8的更多相关文章
- 指导手册02:伪分布式安装Hadoop(ubuntuLinux)
指导手册02:伪分布式安装Hadoop(ubuntuLinux) Part 1:安装及配置虚拟机 1.安装Linux. 1.安装Ubuntu1604 64位系统 2.设置语言,能输入中文 3.创建 ...
- 第二章 伪分布式安装hadoop hbase
安装单机模式的hadoop无须配置,在这种方式下,hadoop被认为是一个单独的java进程,这种方式经常用来调试.所以我们讲下伪分布式安装hadoop. 我们继续上一章继续讲解,安装完先试试SSH装 ...
- 伪分布式安装Hadoop
Hadoop简单介绍 Hadoop:适合大数据分布式存储与计算的平台. Hadoop两大核心项目: 1.HDFS:Hadoop分布式文件系统 HDFS的架构: 主从结构: 主节点,只有一个:namen ...
- Hadoop(一) centos7 jdk安装,hadoop安装|3
安装JDK 下载jdk https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html 选择最 ...
- CentOS7.0分布式安装HADOOP 2.6.0笔记-转载的
三台虚拟机,IP地址通过路由器静态DHCP分配 (这样就无需设置host了). 三台机器信息如下 - 1. hadoop-a: 192.168.0.20 #master 2. ha ...
- 完全分布式安装hadoop集群
0.安装jdk 1.配置hosts文件 2.建立hadoop运行账号 3.配置ssh免密码登录 4.在namenode上配置hadoop 4.1.修改hadoop-env.sh文件 4.2.修改yar ...
- CentOS 6.5 伪分布式 安装 hadoop 2.6.0
安装 jdk -openjdk* 检查安装:java -version 创建Hadoop用户,设置Hadoop用户使之可以免密码ssh到localhost su - hadoop ssh-keygen ...
- 完全分布式安装hadoop
以三个节点为例的服务器集群来安装和配置hadoop 以下是各服务器ip地址和对应所做的节点 192.168.61.128 master 192.168.61.129 slave1 192.168.61 ...
- 在centos7上安装hadoop
1.使用hadoop是需要jdk环境的,因为hadoop里面有java程序,而运行java程序需要jdk. 2.从宿主机上传文件到虚拟机有很多方法,我选择的是在虚拟机安装lrzsz,安装lrzsz命令 ...
随机推荐
- [译]async/await中阻塞死锁
这篇博文主要是讲解在async/await中使用阻塞式代码导致死锁的问题,以及如何避免出现这种死锁.内容主要是从作者Stephen Cleary的两篇博文中翻译过来. 原文1:Don'tBlock o ...
- Java打包商用化软件
这是我在博客中写的第一篇文章.还请各位大神们多多指教!我会详细讲解如何将我们由java的swing以及awt组件编写出的java可视化窗口程序编制成一个我们能够让用户使用的,商业化,可安装的软件.网上 ...
- Spring使用支付宝扫码支付
前一段一直在研究支付宝的扫码支付,不得不说,支付宝的文档写的真是一个烂(起码在下刚开始看的时候是mengbi的).文档上面的示例和demo里面的示例长的完全不一样.往往文档上面的例子很简单,而demo ...
- 大数据核心知识点:Hbase、Spark、Hive、MapReduce概念理解,特点及机制
今天,上海尚学堂大数据培训班毕业的一位学生去参加易普软件公司面试,应聘的职位是大数据开发.面试官问了他10个问题,主要集中在Hbase.Spark.Hive和MapReduce上,基础概念.特点.应用 ...
- Android 音视频开发(六): MediaCodec API 详解
在学习了Android 音视频的基本的相关知识,并整理了相关的API之后,我们应该对基本的音视频有一定的轮廓了. 下面开始接触一个Android音视频中相当重要的一个API: MediaCodec.通 ...
- [Swift]LeetCode100. 相同的树 | Same Tree
Given two binary trees, write a function to check if they are the same or not. Two binary trees are ...
- [Swift]LeetCode508. 出现次数最多的子树元素和 | Most Frequent Subtree Sum
Given the root of a tree, you are asked to find the most frequent subtree sum. The subtree sum of a ...
- [Swift]LeetCode883. 三维形体投影面积 | Projection Area of 3D Shapes
On a N * N grid, we place some 1 * 1 * 1 cubes that are axis-aligned with the x, y, and z axes. Each ...
- [Swift]LeetCode903. DI 序列的有效排列 | Valid Permutations for DI Sequence
We are given S, a length n string of characters from the set {'D', 'I'}. (These letters stand for &q ...
- 【spring】静态资源的访问受限解决方法
前言 我们知道在整合spring mvc框架的时候需要在web.xml中配置一个servlet 代码如下 <!--spring mvc 的DispatcherServlet--> < ...