recurrent model for visual attention
paper url: https://papers.nips.cc/paper/5542-recurrent-models-of-visual-attention.pdf
year: 2014
abstract
这篇文章出发点是如何减少图像相关任务的计算量, 提出通过使用 attention based RNN 模型建立序列模型(recurrent attention model, RAM), 每次基于上下文和任务来适应性的选择输入的的 image patch, 而不是整张图片, 从而使得计算量独立于图片大小, 从而缓解 CNN 模型中计算量与输入图片的像素数成正比的缺点. 该文通过强化学习的方式来学习任务明确的策略, 从而解决模型是不可微的问题.
RAM 模型在几个图像分类任务上,在处理杂乱图像(cluttered images)时, 它明显优于基于CNN的模型,并且在动态视觉控制问题上,无需明确的训练信号, 它就能学习跟踪一个简单的对象。
introduction
该文将注意力问题视为与视觉环境交互时以目标为导向的序列决策过程。
人类感知的一个重要特性是人们不会倾向于一次完整地处理整个场景。 相反,人们将注意力有选择地集中在视觉空间的某些部分,以便在需要的时间和地点获取信息,并随着时间的推移组合来自不同固定位置(fixation)的信息,以建立场景的内部表示,指导下一步眼睛看下哪里以及决策。 将计算资源聚焦在场景的各部分上节省了“带宽”,因为需要处理的“像素”更少。 但它也大大降低了任务复杂性,因为感兴趣的对象可以置于固定位置(fixation)的中心,并且固定区域外的视觉环境(“混乱”)的不相关特征自然被忽略。
model architecture
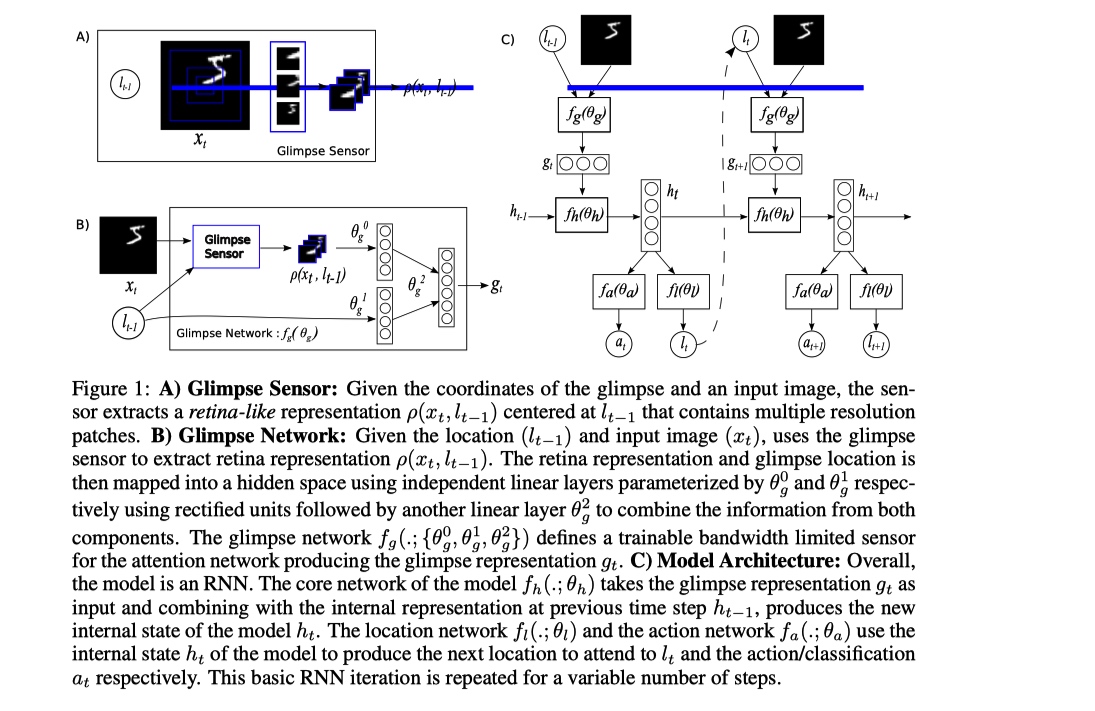 

thought
这篇论文时间比较早, 在当时 CNN backbone 以及目标检测的发展和现在相比相差太多. 在解决 CNN 的计算量问题上, 通过不输出整张图片, 而是利用 RNN 模型建模, 然后使用 attention+强化算法 来决定序列每一个阶段模型看向图片的哪一个 patch, 从而获取与任务相关的关键信息, 过滤掉了无关信息, 从而使得模型计算量独立于图片的输入尺寸, 减小计算量.
利用 RNN 模型来进行视觉任务特征提取, 对于我个人来说是很新颖的思想. 个人觉得, 就视觉 attention 来说, 我感觉不将整张图片作为输入, 而是每次只送入 image patch 的做法是当时妥协的产物. 我觉的视觉 attention 只有在获取全局信息之后, 然后才能基于相关性, 选择的关注一些相关性高的区域来提升处理效率. 如果一开始就是盲人摸象, 我不知道该如何相信系统的决策, ps:个人不了解强化学习相关知识.
总之, 思想很新, 但是实现过于复杂, 而且这种基于局部信息的 attention 感觉并不可靠.
recurrent model for visual attention的更多相关文章
- 论文笔记之: Recurrent Models of Visual Attention
Recurrent Models of Visual Attention Google DeepMind 模拟人类看东西的方式,我们并非将目光放在整张图像上,尽管有时候会从总体上对目标进行把握,但是也 ...
- A Survey of Visual Attention Mechanisms in Deep Learning
A Survey of Visual Attention Mechanisms in Deep Learning 2019-12-11 15:51:59 Source: Deep Learning o ...
- A Model of Saliency-Based Visual Attention for Rapid Scene Analysis
A Model of Saliency-Based Visual Attention for Rapid Scene Analysis 题目:A Model of Saliency-Based Vis ...
- 图像显著性论文(一)—A Model of saliency Based Visual Attention for Rapid Scene Analysis
这篇文章是图像显著性领域最具代表性的文章,是在1998年Itti等人提出来的,到目前为止引用的次数超过了5000,是多么可怕的数字,在它的基础上发展起来的有关图像显著性论文更是数不胜数,论文的提出主要 ...
- 论文笔记之:Multiple Object Recognition With Visual Attention
Multiple Object Recognition With Visual Attention Google DeepMind ICRL 2015 本文提出了一种基于 attention 的用 ...
- paper 27 :图像/视觉显著性检测技术发展情况梳理(Saliency Detection、Visual Attention)
1. 早期C. Koch与S. Ullman的研究工作. 他们提出了非常有影响力的生物启发模型. C. Koch and S. Ullman . Shifts in selective visual ...
- 论文笔记:Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention 2018-08-10 10:15:06 Pap ...
- visual attention
The visual attention mechanism may have at least the following basic components [Tsotsos, et. al. 19 ...
- Paper Reading - Show, Attend and Tell: Neural Image Caption Generation with Visual Attention ( ICML 2015 )
Link of the Paper: https://arxiv.org/pdf/1502.03044.pdf Main Points: Encoder-Decoder Framework: Enco ...
随机推荐
- git命令的理解与扩展
Git的模式如图: Workspace:工作区 Index / Stage:暂存区 Repository:仓库区(或本地仓库) Repository:仓库区(或本地仓库) 一.新建代码库 # 查看gi ...
- java集合-HashMap源码解析
HashMap 键值对集合 实现原理: HashMap 是基于数组 + 链表实现的. 通过hash值计算 数组索引,将键值对存到该数组中. 如果多个元素hash值相同,通过链表关联,再头部插入新添加的 ...
- 每次用 selenium 操作浏览器都还原了 (比如没有浏览器历史记录)
每次用 selenium 操作浏览器都还原了 (比如没有浏览器历史记录)
- 使用C++进行WMI查询的简单封装
封装WMI查询的简单类CWMIUtil 头文件WMIUtil.h #pragma once #include <Wbemidl.h> class CWMIUtil { public: CW ...
- jsonp原理详解
1.一个众所周知的问题,Ajax直接请求普通文件存在跨域无权限访问的问题,甭管你是静态页面.动态网页.web服务.WCF,只要是跨域请求,一律不准. 2.不过我们又发现,Web页面上调用js文件时则不 ...
- 微信支付之01------获取订单微信支付二维码的接口------Java实现
[ 前言:以前写过一个获取微信二维码支付的接口,发现最近公司新开的项目会经常用到,现在我又翻出代码看了一遍,觉得还是把整个代码流程记下来的好 ] 借鉴博客: 他这篇博客写得不错,挺全的:https:/ ...
- Java的String和StringBuilder
一.String 1.创建String对象的方法: String s1="haha"; String s2=new String(); String s3=new String(& ...
- python正则匹配示例
text="山东省临沂市兰山区 市委大院中区21号楼4单元 276002 奥特曼1号 18254998111" #匹配手机号 m=re.findall(r"1\d{10} ...
- mac下安装maven
在mac下 使用 brew安装,brew install maven 查看maven版本 mvn -version 打开Terminal,输入以下命令,设置Maven classpath 添加下列两行 ...
- 运行adb命令报错adb server version (31) doesn't match this client (39); killing...
执行adb devices 报错 原因分析: 这个是socket 的端口被占用了,我这里是因为360手机助手占用了这个端口,所以其他的就不能够用了. 解决办法: 卸载了360的手机助手就可以了 首先 ...