es简单打造站内搜索
最近挺忙的,在外出差,又同时干两个项目。白天一个晚上一个,特别是白天做的项目,马上就要上线了,在客户这里 三天两头开会,问题很多真的很想好好静下来怼代码,半夜做梦都能fix bugs~ 和客户交流真的是门技术,一不小心你就会掉坑里,慢慢来吧~
站内搜素其实也是老生常谈,估计很多程序员门都做过或者接触过,记得大三那会 那是比较常见的解决方案就是lucene.net 和盘古分词,后来又用jieba分词,
首先就是和数据库同步,我们把数据扔给lucene.net ,lucene.net 拿到数据 进行分词,然后保存在索引库中,当用户搜索的时候,就从索引库中进行搜索。lucene.net 对中文分词不是太优化,所以常用的就是盘古分词 庖丁解牛 jieba分词,这种方式适合个人站点 数据量不是太大的情况下,目前很少有采用这种解决方案的,看官们感兴趣的可以百度了解一波,实现起来也不难。
前端时间elastc上市,市值50亿美金,刚开始我还吓一大跳~ 接触es是去年, 项目做日志统计使用exceptionless,所以也就初步了解了elasticsearch 也逐步了解logstash kibana 速度是真的快,吊打sqlserver啊! 哈哈 毕竟不是一系列的东西=
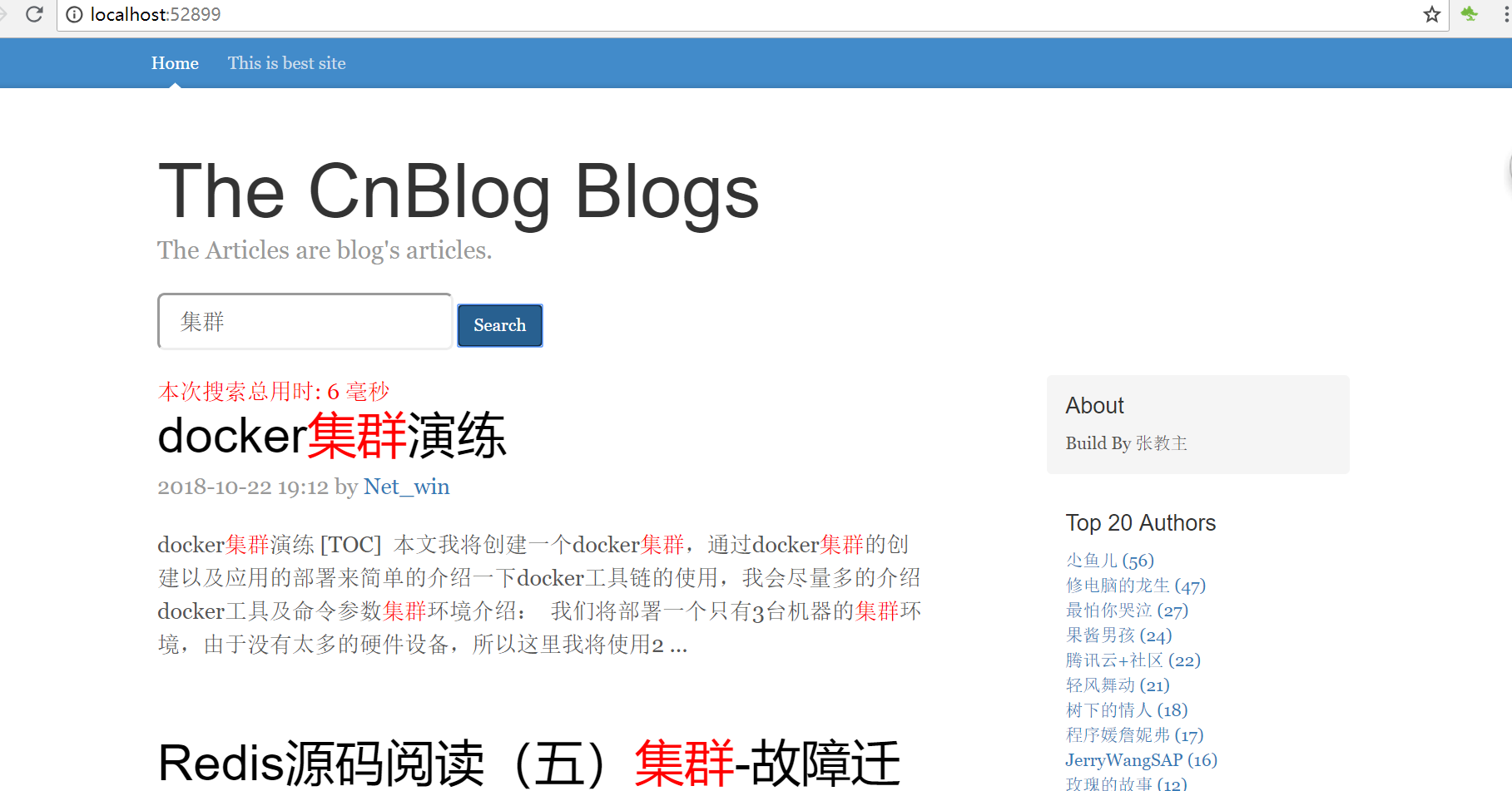
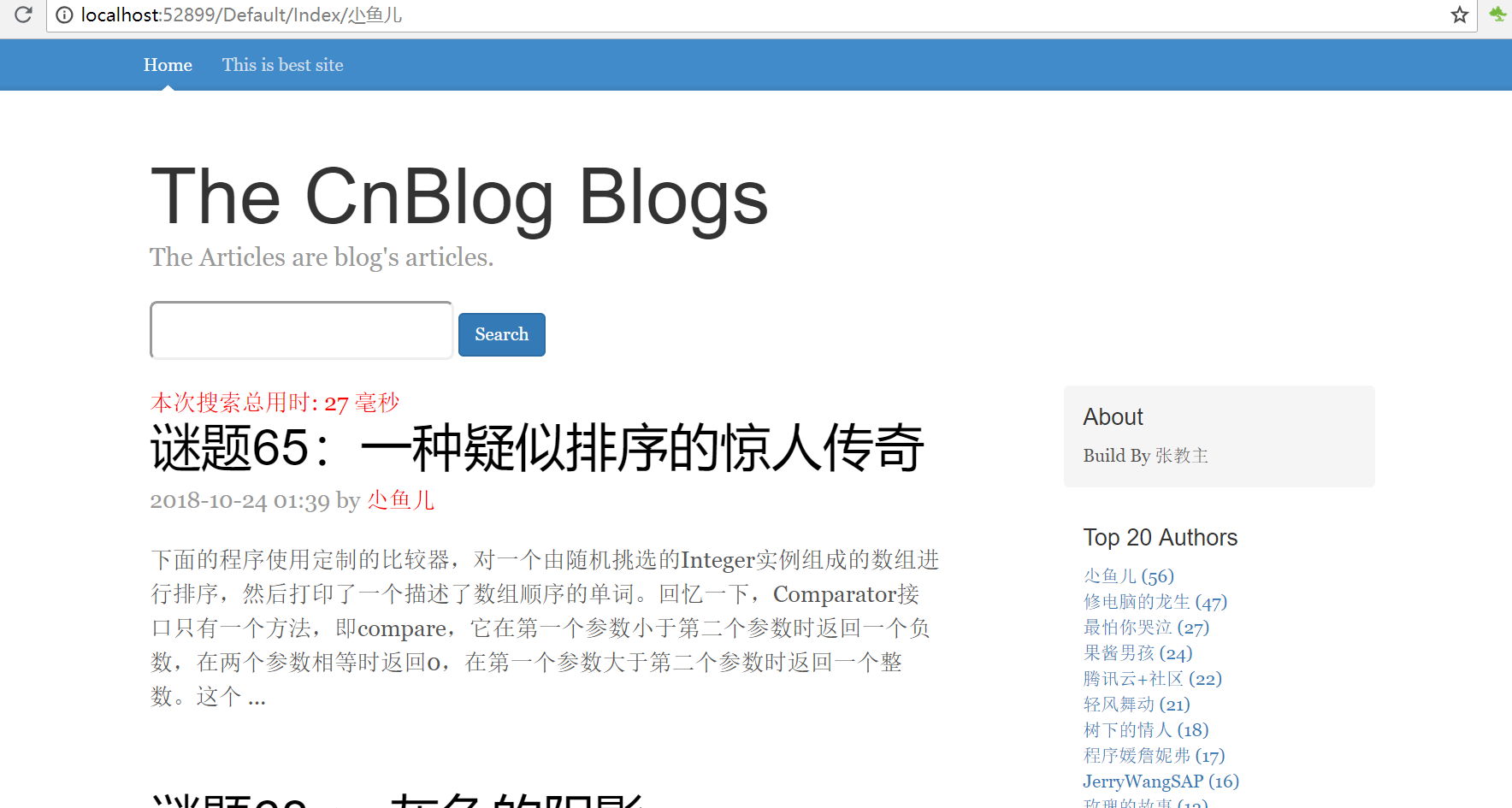
今天简单实现的站内搜索采用的就是 elasticsearch,数据源就是这段时间每天爬取博客园获取到的将近6000篇文章,放到sqlserver了,后续会共享
起初 想要搞sqlserver 和 es的数据同步,我写的这个服务每小时就会爬取博客园一次 获取最新50条数据,重复的就不算了。数据同步可以采用logstash,首先就是全量同步,再次就是增量同步,可能是因为版本原因吧,都是采用的最新版本,采用logstash进行数据同步 老是失败,有待探索,索性就用ef 先做个全量同步,再靠这个定时服务做以后的增量,数据本身就是经过去重处理的,况且也不存在修改 删除的情况
首先就是配置java环境变量 然后部署 elk 官网地址是 : https://www.elastic.co/cn/
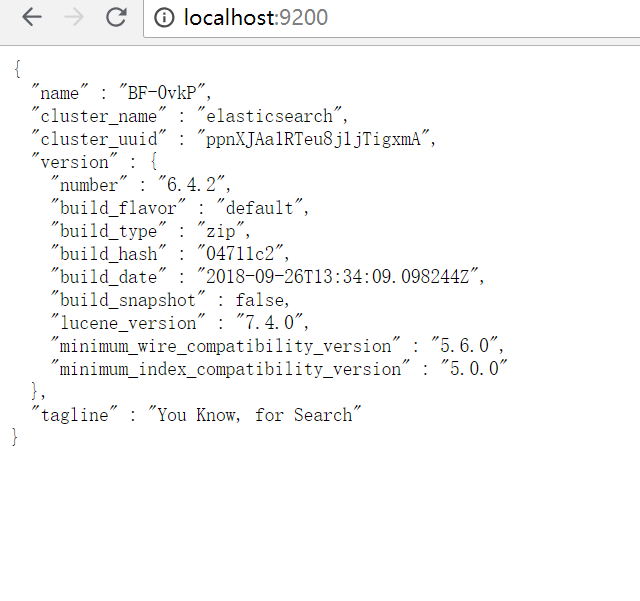
下载好三件套之后 我们可以把es部署成windows服务 在bin目录下 运行elasticsearch-service.bat
服务开启后,es默认http地址是 http://localhost:9200/
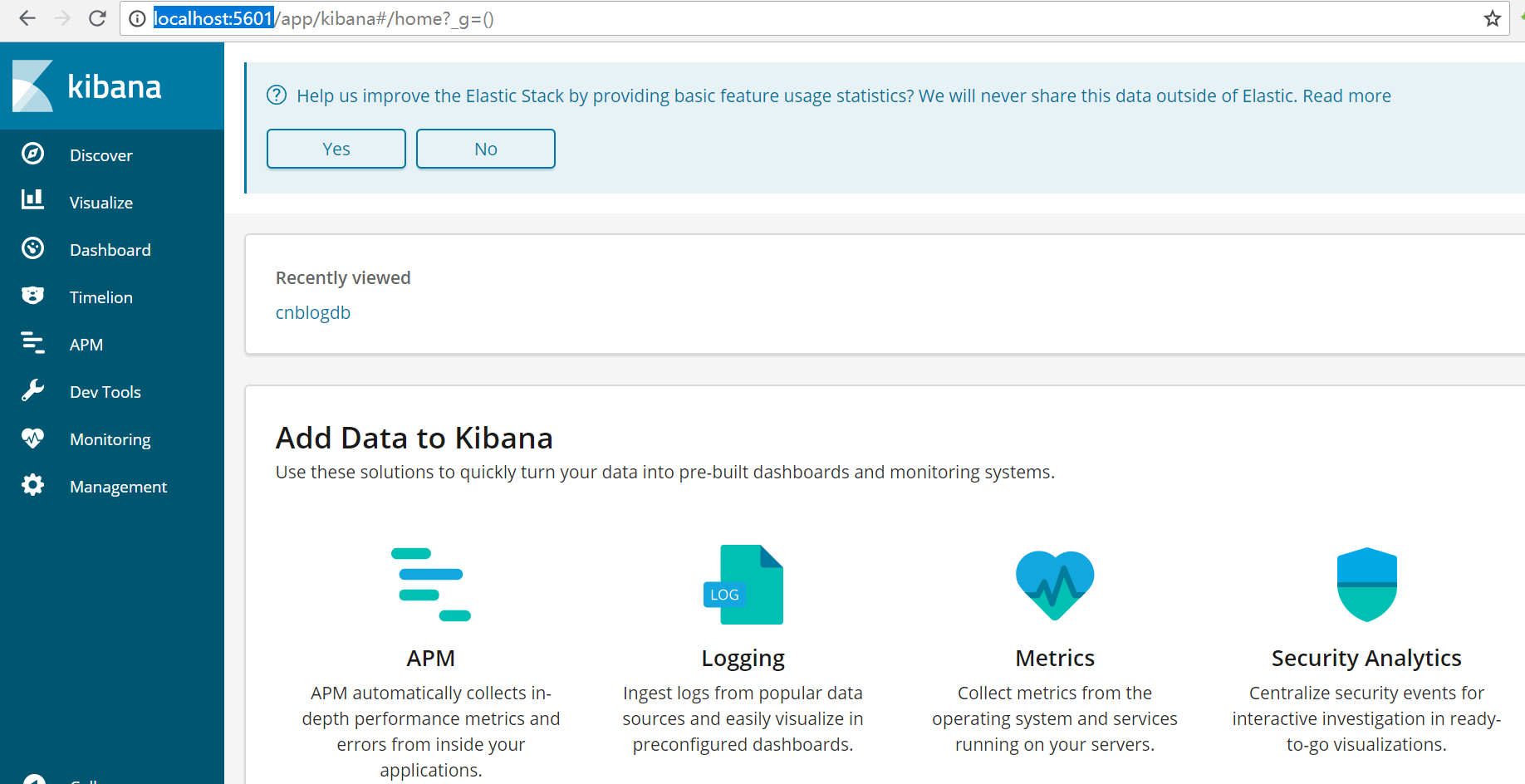
es启动成功后 启动kibana 服务 同样也是在bin目录下执行kibana.bat,kibana对es来说 真的是一个神器,
可以在上面操作dsl 做数据分析等待 默认地址是http://localhost:5601
然后就是安装ik了,ik是中文分词插件,github地址是:https://github.com/medcl/elasticsearch-analysis-ik
从releases下载 我下载的最新版 6.4.2 下载后复制到es的plugins 目录下,解压就行了。然后去kibana检查是否安装成功,具体操作见github
ik分词策略有ik_max_word 和 ik_smart ik_max_word会将文本做最细粒度的拆分,例如「中华人民共和国国歌」会被拆分为「中华人民共和国、中华人民、中华、华人、人民共和国、人民、人、民、共和国、共和、和、国国、国歌」,会穷尽各种可能的组合;
ik_smart会将文本做最粗粒度的拆分,例如「中华人民共和国国歌」会被拆分为「中华人民共和国、国歌」;
ik安装后之后 就是在kibana创建index 和mapping了
es和我们常用的sqlserver等关系型数据库对比如下:
DB:DataBases=>Tables=>Rows=>Columns
ES:Indices=>Types=>Documents=>Fields
创建Index
在kibana Dev Tools 操作dsl
PUT /cnblogdb (注意 必须为小写)
POST /cnblogdb/articles/_mapping
{
"properties": {
"content": {
"type": "text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart"
},
"title":{
"type":"text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart"
},
"summary":{
"type":"text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart" },
"author":{
"type":"text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart",
"fielddata": true,
"fields": {
"raw":{
"type":"keyword"
}
}
}
}
}
可以看到 在_mapping 的时候 author字段 加了fielddata 属性 和fields
关于fielddata 详细介绍可移步https://www.elastic.co/guide/cn/elasticsearch/guide/current/preload-fielddata.html
在这里设置fielddata为true是因为 后续的根据author字段进行聚合检索 es在默认情况下对text类型的字段是不可聚合的
设置 fields :{raw:{type:keyword }} 是因为我们在对author字段进行聚合的时候,因为上面的ik分词策略,所以我们聚合到的结果是分词后的结果,
比如author为 张教主 聚合结果就成了张,教主 这样的结果,设置他就类似有了个别名。
c#中操作es 使用Nest
github地址是 https://github.com/elastic/elasticsearch-net
数据源地址是: http://zycoder.oss-cn-qingdao.aliyuncs.com/ali/blog.sql
这个数据是sqlserver的脚本数据 整到es也是很简单的
创建esclient es多见于分布式 多节点 我们搞着学习就不必要了
var node = new Uri("http://localshot:9200");
var settings = new ConnectionSettings(node);
var client = new ElasticClient(settings);
看项目 界面截图 就是一个简单的多字段匹配检索 和 聚合
创建Model 此model是与type相对应的
[ElasticsearchType(Name ="articles")]
public partial class Articles
{
public int Id { get; set; } [Text(Analyzer = "ik_smart")]
public string Title { get; set; } public string ItemUrl { get; set; }
[Text(Analyzer = "ik_smart")]
public string Sumary { get; set; }
[Text(Analyzer = "ik_smart", Fielddata = true)]
public string Author { get; set; } public string PubDate { get; set; }
[Text(Analyzer = "ik_smart")]
public string Content { get; set; }
}
首先就是首页的高亮检索了 代码如下:
public ActionResult GetArticles()
{
Stopwatch sw = new Stopwatch();
sw.Start();
string keyWords = Request.Params["keyWords"];
string author = Request.Params["author"];
int.TryParse(Request.Params["page"], out int page);
page = page <= ? : page;
int start = (page - ) * ; var query = new SearchDescriptor<Articles>();
if (!string.IsNullOrWhiteSpace(author))
{
query= query.Query(q => q.Match(m => m.Field("author").Query(author)));
}
else
{
query = query.Query(q => q.MultiMatch(m => m.Fields(
fd => fd.Fields("title", "sumary", "author")
).Query(keyWords)
));
}
query = query.Highlight(h => h
.PreTags(@"<span style='color:red'>")
.PostTags("</span>")
.Fields(
f => f.Field(obj => obj.Title),
f => f.Field(obj => obj.Sumary),
f => f.Field(obj => obj.Author)
)
).Sort(c => c.Field("_score", SortOrder.Descending).Field("id", SortOrder.Descending))
.From(start).Size(); var response = _client.Search<Articles>(query); var list = response.Hits.Select(c => new Articles
{
Id = c.Source.Id,
Title = c.Highlights == null ? c.Source.Title : c.Highlights.Keys.Contains("title") ? string.Join("",
c.Highlights["title"].Highlights) : c.Source.Title,
Author = c.Highlights == null ? c.Source.Author : c.Highlights.Keys.Contains("author") ? string.Join("",
c.Highlights["author"].Highlights) : c.Source.Author,
Sumary = c.Highlights == null ? c.Source.Sumary : c.Highlights.Keys.Contains("sumary") ? string.Join("",
c.Highlights["sumary"].Highlights) : c.Source.Sumary,
PubDate = c.Source.PubDate
});
sw.Stop();
ViewBag.Times = sw.ElapsedMilliseconds;
ViewBag.PageIndx = page;
ViewData["list"] = list.ToList();
return View();
}
在Sort(c => c.Field("_score", SortOrder.Descending).Field("id", SortOrder.Descending)) 这里我们可以多留意一下,在匹配搜索的时候,
默认排序是根据匹配得分进行排序的,所以我们想要获取最新最匹配的数据,首先就是根据匹配得分进行排序 在根据时间
面板结果如下:
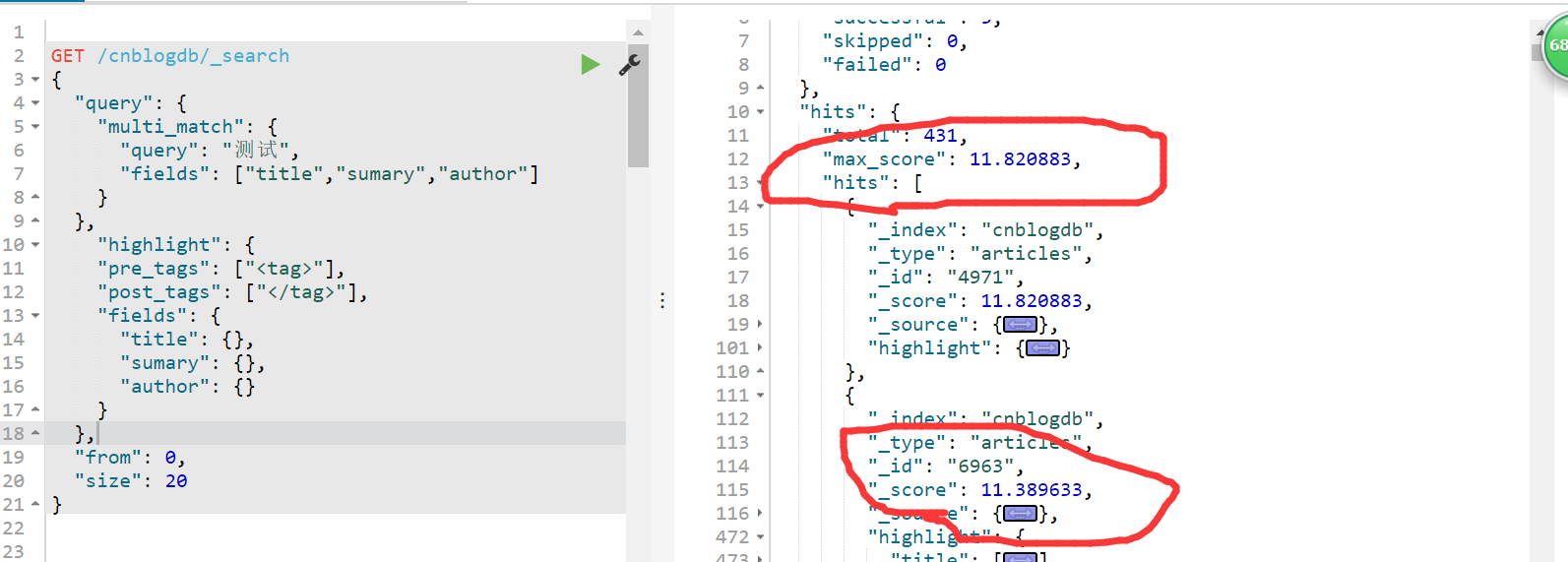
Nest进行搜索 语法不做过多讨论 谷歌 百度
然后就是根据author进行聚合 类似数据库语法就是 select author,count(author) from article group by author
dsl 结果如下所示:
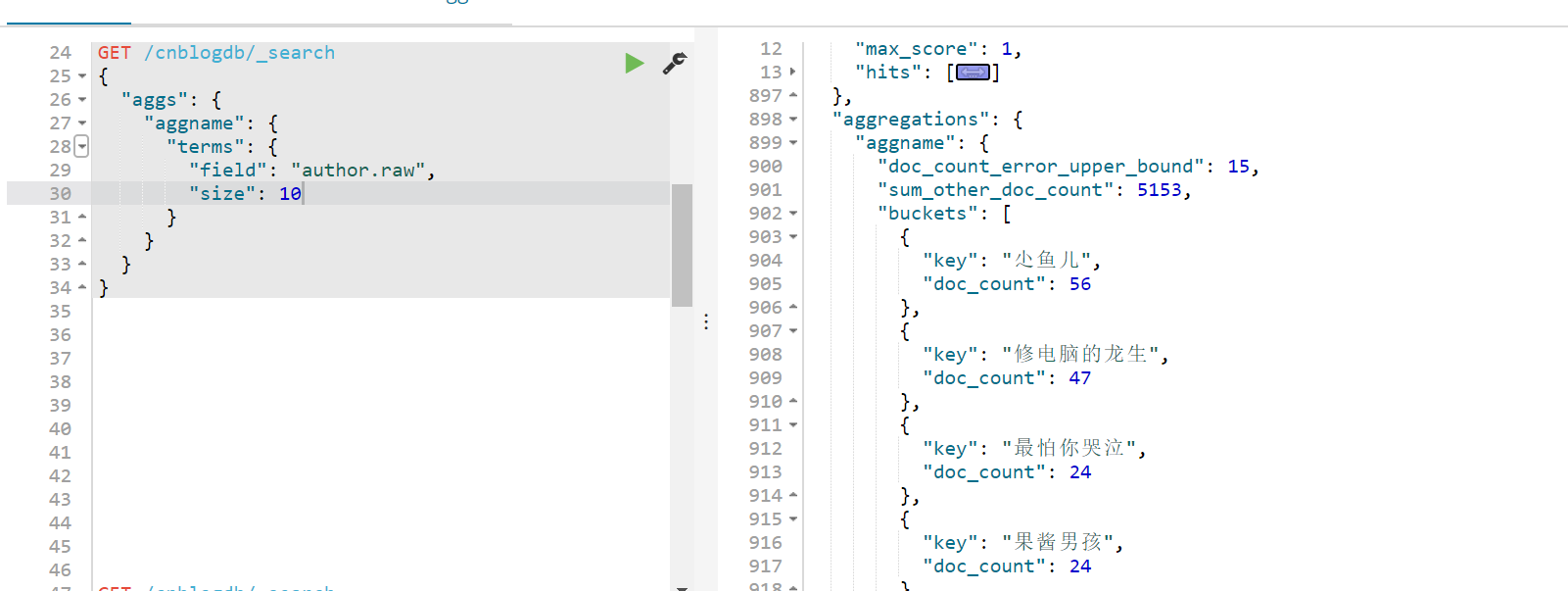
size就是最靠前的10位了 小鱼儿同志贡献最多 我所提供的数据源里有56篇文章~
代码如下:
public ActionResult HomeRight()
{
var response= _client.Search<Articles>(s => s.Aggregations(aggs => aggs.Terms(
"aggs", t => t.Field("author.raw").Size().CollectMode(TermsAggregationCollectMode.BreadthFirst)
)).Size());
var buckets= response.Aggregations.Terms("aggs").Buckets;
var authorGroups= buckets.Select(q => new AuthorGroup
{
AuthorName = q.Key,
Count = (int)q.DocCount
}).ToList();
ViewData["list"] = authorGroups;
return View();
}
在c#中 我们就是把dsl 改为lambda去查询
在聚合的时候 最后 Size(0); 不是取0条数据 而是在聚合搜索的时候 默认也会获取documents 默认为10条 但是我们只是聚合并不需要搜索文档 所以就设置为0
也减小了内存开销,增加查询速度。
更多资料就是看官方文档了,提供的很全面。
Share End!
es简单打造站内搜索的更多相关文章
- 使用Lucene.NET实现简单的站内搜索
使用Lucene.NET实现简单的站内搜索 导入Lucene.NET 开发包 Lucene 是apache软件基金会一个开放源代码的全文检索引擎工具包,是一个全文检索引擎的架构,提供了完整的查询引擎和 ...
- es站内站内搜索笔记(一)
es站内站内搜索笔记(一) 第一节: 概述 使用elasticsearch进行网站搜索,es是当下最流行的分布式的搜索引擎及大数据分析的中间件,搜房网的主要功能:强大的搜索框,与百度地图相结合,实现地 ...
- Lucene.net站内搜索—4、搜索引擎第一版技术储备(简单介绍Log4Net、生产者消费者模式)
目录 Lucene.net站内搜索—1.SEO优化 Lucene.net站内搜索—2.Lucene.Net简介和分词Lucene.net站内搜索—3.最简单搜索引擎代码Lucene.net站内搜索—4 ...
- Lucene.net站内搜索—3、最简单搜索引擎代码
目录 Lucene.net站内搜索—1.SEO优化 Lucene.net站内搜索—2.Lucene.Net简介和分词Lucene.net站内搜索—3.最简单搜索引擎代码Lucene.net站内搜索—4 ...
- hexo干货系列:(五)hexo添加站内搜索
前言 本来想用百度站内搜索,但是没成功,所以改用swiftype,用起来还是很棒的,这里分享一下我的安装步骤 正文 注册 去swiftype官网注册个账号,然后登陆,对了不要去在意30天试用,30天过 ...
- 一步步开发自己的博客 .NET版(5、Lucenne.Net 和 必应站内搜索)
前言 这次开发的博客主要功能或特点: 第一:可以兼容各终端,特别是手机端. 第二:到时会用到大量html5,炫啊. 第三:导入博客园的精华文章,并做分类.(不要封我) 第四:做 ...
- Lucene.net站内搜索—6、站内搜索第二版
目录 Lucene.net站内搜索—1.SEO优化 Lucene.net站内搜索—2.Lucene.Net简介和分词Lucene.net站内搜索—3.最简单搜索引擎代码Lucene.net站内搜索—4 ...
- Lucene.net站内搜索—5、搜索引擎第一版实现
目录 Lucene.net站内搜索—1.SEO优化 Lucene.net站内搜索—2.Lucene.Net简介和分词Lucene.net站内搜索—3.最简单搜索引擎代码Lucene.net站内搜索—4 ...
- Lucene.net站内搜索—2、Lucene.Net简介和分词
目录 Lucene.net站内搜索—1.SEO优化 Lucene.net站内搜索—2.Lucene.Net简介和分词Lucene.net站内搜索—3.最简单搜索引擎代码Lucene.net站内搜索—4 ...
随机推荐
- 微信小程序----没有 DOM 对象,一切基于组件化 ---- mpvue
封装好用的 类库 和 组件,复用且灵活度高 抽取相同的部分放在函数内部(组件内部) 抽取不同的部分放在形参(组件 props 传参,或者插槽) new Promise 运行时 初始化实例对象的状态为 ...
- Android Gradle Task
Tasks runnable from root project ------------------------------------------------------------ Androi ...
- thinkphp 单图上传组建成数组然后追加到一个字段
//上传的数组字段 $note1 = input('note1'); $note2 = input('note2'); $note3 = input('note3'); $note4 = input( ...
- java简单的双色球摇号程序
import java.util.HashSet; import java.util.Random; import java.util.Set; /** * LotteryClient * @auth ...
- 非对称加密技术里面,最近出现了一种奇葩的密钥生成技术,iFace人脸密钥技术
要说到非对称加密技术啊,得先说说对称加密技术 什么是对称加密技术 对称加密采用了对称密码编码技术,它的特点是文件加密和解密使用相同的密钥加密. 也就是密钥也可以用作解密密钥,这种方法在密码学中叫做对称 ...
- oracle 合并多个sys_refcursor
一.背景 在数据开发中,有时你需要合并两个动态游标sys_refcursor. 开发一个存储过程PROC_A,这个过程业务逻辑相当复杂,代码篇幅较长.一段时间后要开发一个PROC_B,要用PROC_A ...
- python之定义参数模块argparse(二)高级使用 --传参为函数的实现
我们在文章python之定义参数模块argparse的基本使用中介绍了argparse模块的基本使用方法 当前传入的参数只能是int.str.float.comlex类型,不能为函数,这有点不方便,但 ...
- virtuoso操作graph的方法--查询和删除
在virtuoso中查看某个graph的数据,直接用sparql语句查询就可以了,对graph进行查询也可以通过sparql实现,删除graph则要在isql中操作. 1 查询graph的命令 在lo ...
- Scala安装教程
首先去Java官网下载Java的安装包 jdk-8u121-windows-x64.exe 再去Scala官网下载Scala的安装包 Scala2.12.1 安装Java: 配置Java环境变量(系统 ...
- 【Sqoop篇】----Sqoop从搭建到应用案例
一.前述 今天开始讲解Sqoo的用法搭建和使用.Sqoop其实功能非常简单.主要用于在Hadoop(Hive)与传统的数据库(mysql.postgresql...)间进行数据的传递,可以将一个关系型 ...