我眼里K-Means算法
在我眼里一切都是那么简单,复杂的我也看不懂,最讨厌那些复杂的人际关系,唉,像孩子一样交流不好吗。
学习K-Means算法时,会让我想起三国志这个游戏,界面是一张中国地图,诸侯分立,各自为据。但是游戏开始,玩家会是一个人一座城池(我比较喜欢这样,就有挑战性),然后不断的征战各方,占领城池
不断的扩大地盘,正常来说,征战的城池是距离自己较为近的,然后选择这些城池的中心位置作为主城。所以过来一段时间后,地图上就会出现几个主要的势力范围,三足鼎立正是如此。这个过程和K-Means算法十分相似。
接下来我们以下图为游戏地图为例来讲解K-Means算法,地图中的每一个城池为一个数据样例(包含城池的坐标),假如游戏开始设定三个游戏玩家(三个聚类中心K),游戏目的希望最后三个玩家各自为据形成右图的格局。开始游戏!
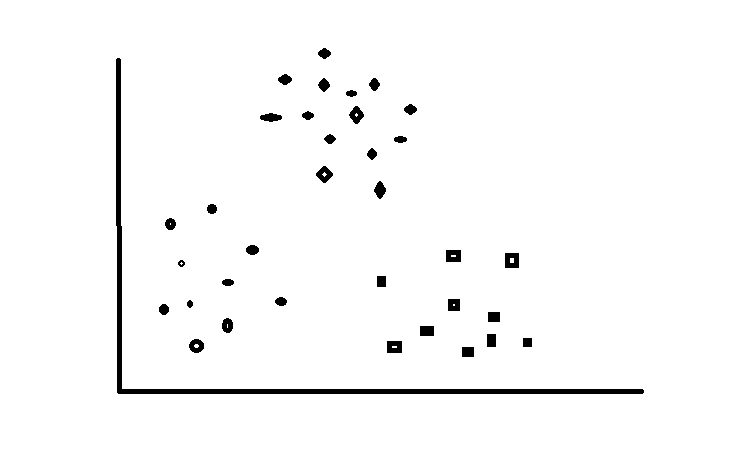
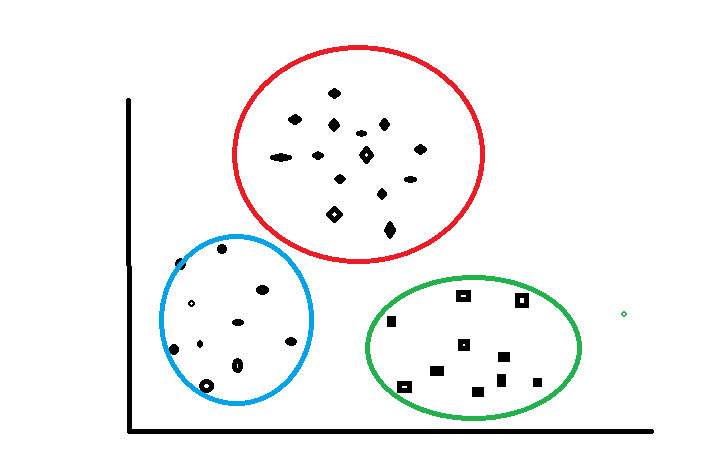
K-Means(k均值算法):
一开始先要介绍算法的整体流程
(1)随机初始化聚类中心的位置
(2)计算每一个点到聚类中心的距离,选取最小值分配给k(i)
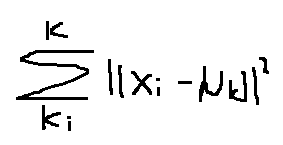
(3)移动聚类中心(其实就是对所属它的样本点求平均值,就是它移动是位置)

(4)重复(2),(3)直到损失函数(也就是所有样本点到其所归属的样本中心的距离的和最小)
最后整体分类格局会变得稳定。
优化目标,也就是之前我们经常提到的损失函数
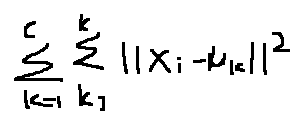
在不断的循环过程中,聚类中心也在不断地更新,直到上式距离总和收敛精确值的时候,获得最优解。
(1) 随机初始化
为了游戏的公平性,使用随机的方式把三个游戏玩家分配到地图上三个城池中(这里需要注意聚类中心的个数一定要小于数据样本的个数)。随机初始化会遇见下面几种情况
1 好的情况

这种情况最为好,因为三个聚类中心已经很好的散布在三个主要的样本类上,再执行下面的算法就可以形成我们想要的分类。
2

这种情况就不太好,红点和绿点一开始就分配在以起,所以一开就会产生对立,对于不好的初始化可能会产生以下聚类结果

这种情况就是就很糟糕了,不符合要求。
对于这种情况我们没有很好的解决办法,可以尝试多次初始化,获取最好的结果,例如设置1000次随机初始化,选取损失函数值最小的一个。
还有一种情况,对于有些数据集天生分布不明显的数据集,怎么才能正确的选择聚类中心的个数,例如:

使用(elbow method)“胳膊肘算法”:
获取损失函数和聚类中心K的函数图像,大致有两种图像类型
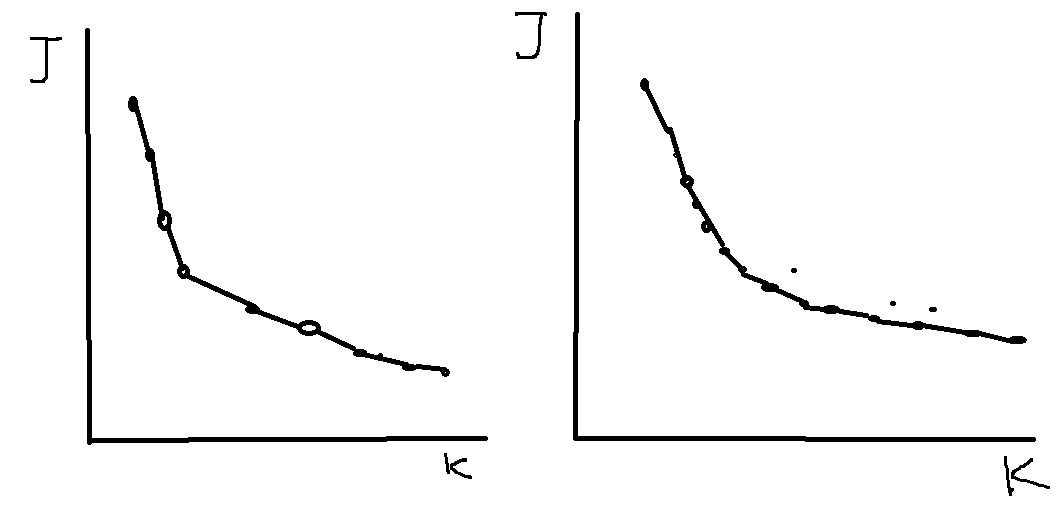
左图的拐点明显,而右图的拐点不是很明显,对于左图我们可以选取拐点处的k作为聚类中心的个数,而如果是右图,那么就需要根据情况选取,比如说,如果数据集是衣服的尺码的数据,如果你想确定这些衣服的尺码类型,那么根据你想要分成几种尺码类型决定(例如:L,M,S)(还有,M,L,XL,XXL,S)
我眼里K-Means算法的更多相关文章
- KNN 与 K - Means 算法比较
KNN K-Means 1.分类算法 聚类算法 2.监督学习 非监督学习 3.数据类型:喂给它的数据集是带label的数据,已经是完全正确的数据 喂给它的数据集是无label的数据,是杂乱无章的,经过 ...
- K-means算法
K-means算法很简单,它属于无监督学习算法中的聚类算法中的一种方法吧,利用欧式距离进行聚合啦. 解决的问题如图所示哈:有一堆没有标签的训练样本,并且它们可以潜在地分为K类,我们怎么把它们划分呢? ...
- 机器学习实战笔记--k近邻算法
#encoding:utf-8 from numpy import * import operator import matplotlib import matplotlib.pyplot as pl ...
- 《机器学习实战》学习笔记一K邻近算法
一. K邻近算法思想:存在一个样本数据集合,称为训练样本集,并且每个数据都存在标签,即我们知道样本集中每一数据(这里的数据是一组数据,可以是n维向量)与所属分类的对应关系.输入没有标签的新数据后,将 ...
- [Machine-Learning] K临近算法-简单例子
k-临近算法 算法步骤 k 临近算法的伪代码,对位置类别属性的数据集中的每个点依次执行以下操作: 计算已知类别数据集中的每个点与当前点之间的距离: 按照距离递增次序排序: 选取与当前点距离最小的k个点 ...
- k近邻算法的Java实现
k近邻算法是机器学习算法中最简单的算法之一,工作原理是:存在一个样本数据集合,即训练样本集,并且样本集中的每个数据都存在标签,即我们知道样本集中每一数据和所属分类的对应关系.输入没有标签的新数据之后, ...
- 基本分类方法——KNN(K近邻)算法
在这篇文章 http://www.cnblogs.com/charlesblc/p/6193867.html 讲SVM的过程中,提到了KNN算法.有点熟悉,上网一查,居然就是K近邻算法,机器学习的入门 ...
- 聚类算法:K-means 算法(k均值算法)
k-means算法: 第一步:选$K$个初始聚类中心,$z_1(1),z_2(1),\cdots,z_k(1)$,其中括号内的序号为寻找聚类中心的迭代运算的次序号. 聚类中心的向量值可任意设 ...
- 从K近邻算法谈到KD树、SIFT+BBF算法
转自 http://blog.csdn.net/v_july_v/article/details/8203674 ,感谢july的辛勤劳动 前言 前两日,在微博上说:“到今天为止,我至少亏欠了3篇文章 ...
- Python实现kNN(k邻近算法)
Python实现kNN(k邻近算法) 运行环境 Pyhton3 numpy科学计算模块 计算过程 st=>start: 开始 op1=>operation: 读入数据 op2=>op ...
随机推荐
- Spring 事务与脏读、不可重复读、幻读
索引: 目录索引 参看代码 GitHub: 1.Spring 事务 2.事务行为 一.Spring 事务: Spring 的事务机制是用统一的机制来处理不同数据访问技术的事务处理. Spring 的事 ...
- SQLServer之修改标量值函数
修改标量值函数注意事项 更改先前通过执行 CREATE FUNCTION 语句创建的现有 Transact-SQL 或 CLR 函数,但不更改权限,也不影响任何相关的函数.存储过程或触发器. 不能用 ...
- chrome总是提示“请停用开发者模式运行的扩展程序”
方法1:通过组策略的扩展白名单.要下载一个组策略管理模板 1.开始 -> 运行 -> 输入gpedit.msc -> 回车确定打开计算机本地组策略编辑器(通过Win + R快捷键可以 ...
- LeetCode算法题-Reverse String II(Java实现)
这是悦乐书的第256次更新,第269篇原创 01 看题和准备 今天介绍的是LeetCode算法题中Easy级别的第123题(顺位题号是541).给定一个字符串和一个整数k,你需要反转从字符串开头算起的 ...
- 《常见排序算法--PHP实现》
原文地址: 本文地址:http://www.cnblogs.com/aiweixiao/p/8202360.html Original 2018-01-02 关注 微信公众号 程序员的文娱情怀 1.概 ...
- 周末班:Python基础之并发编程
进程 相关概念 进程 进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础.在早期面向进程设计的计算机结构中,进程是程序的基本 ...
- Python进程池Pool
''' 进程池,启动一个进程就要克隆一份数据,假设父进程1G,那么启动进程开销很大 避免启动太多造成系统瘫痪,就有进程池,即同一时间允许的进程数量 ps:线程没有池,因为线程启动开销小,线程有类似信号 ...
- Python开发【字符串格式化篇】
1.百分号 __author__ = "Tang" # + 号 拼接 msg = "i am " + " tang" print(msg) ...
- How To Size Your Apache Flink® Cluster: A Back-of-the-Envelope Calculation
January 11, 2018- Apache Flink Robert Metzger and Chris Ward A favorite session from Flink Forward B ...
- MySQL之库相关操作
一 系统数据库 information_schema: 虚拟库,不占用磁盘空间,存储的是数据库启动后的一些参数,如用户表信息.列信息.权限信息.字符信息等performance_schema: MyS ...