日志服务Python消费组实战(三):实时跨域监测多日志库数据
解决问题
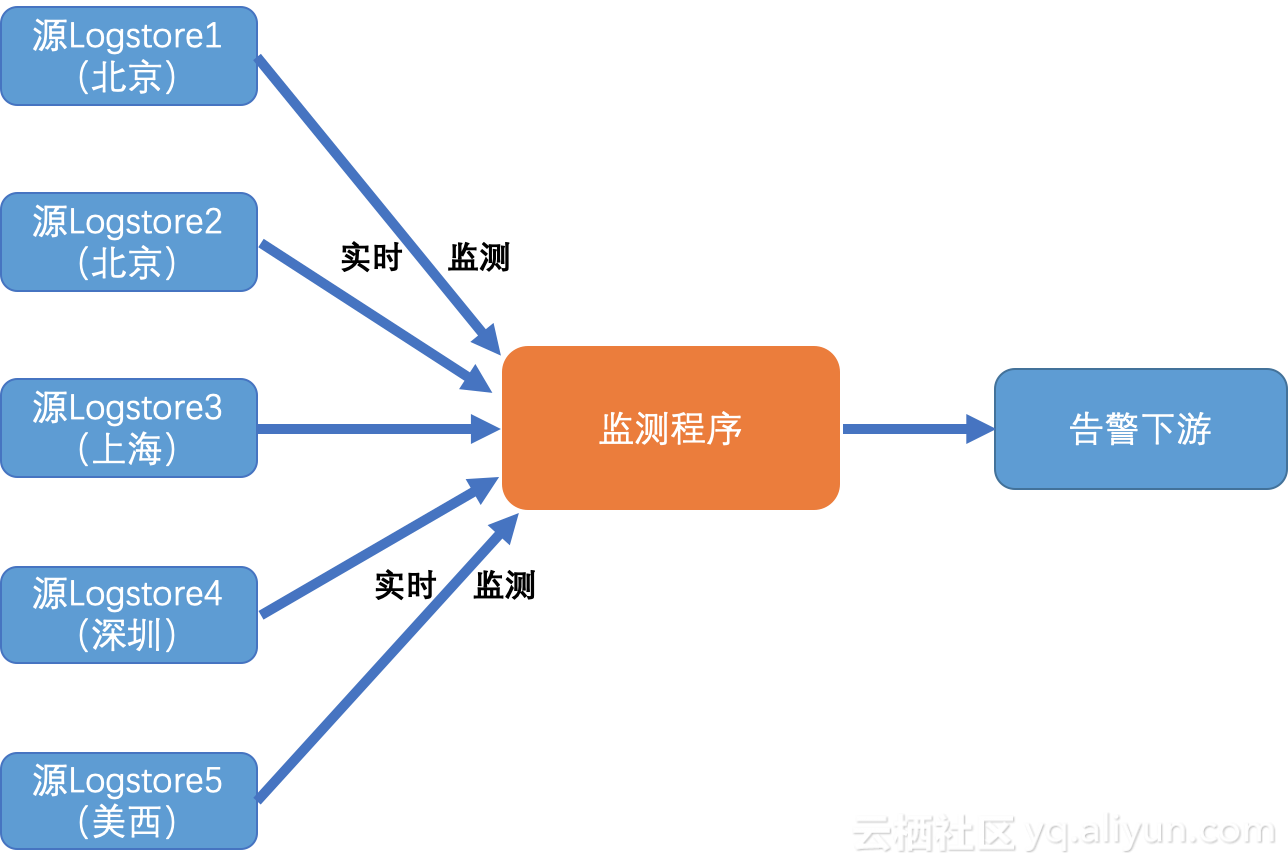
使用日志服务进行数据处理与传递的过程中,你是否遇到如下监测场景不能很好的解决:
- 特定数据上传到日志服务中需要检查数据内的异常情况,而没有现成监控工具?
- 需要检索数据里面的关键字,但数据没有建立索引,无法使用日志服务的告警功能?
- 数据监测要求实时性(<5秒,例如Web访问500错误),而特定功能都有一定延迟(1分钟以上)?
- 存在多个域的多个日志库(例如每个Region的错误文件对应的日志库),数据量不大,但监控逻辑类似,每个目标都要监控与配置,比较繁琐?
如果是的,您可以考虑使用日志服务Python消费组进行跨域实时数据监控,本文主要介绍如何使用消费组实时监控多个域中的多个日志库中的异常数据,并进行下一步告警动作。可以很好解决以上问题,并利用消费组的特点,达到自动平衡、负载均衡和高可用性。
基本概念
协同消费库(Consumer Library)是对日志服务中日志进行消费的高级模式,提供了消费组(ConsumerGroup)的概念对消费端进行抽象和管理,和直接使用SDK进行数据读取的区别在于,用户无需关心日志服务的实现细节,只需要专注于业务逻辑,另外,消费者之间的负载均衡、failover等用户也都无需关心。
消费组(Consumer Group) - 一个消费组由多个消费者构成,同一个消费组下面的消费者共同消费一个logstore中的数据,消费者之间不会重复消费数据。
消费者(Consumer) - 消费组的构成单元,实际承担消费任务,同一个消费组下面的消费者名称必须不同。
在日志服务中,一个logstore下面会有多个shard,协同消费库的功能就是将shard分配给一个消费组下面的消费者,分配方式遵循以下原则:
- 每个shard只会分配到一个消费者。
- 一个消费者可以同时拥有多个shard。
新的消费者加入一个消费组,这个消费组下面的shard从属关系会调整,以达到消费负载均衡的目的,但是上面的分配原则不会变,分配过程对用户透明。
协同消费库的另一个功能是保存checkpoint,方便程序故障恢复时能接着从断点继续消费,从而保证数据不会被重复消费。
使用消费组进行实时分发
这里我们描述用Python使用消费组进行编程,实时跨域监测多个域的多个日志库,全文或特定字段检查
注意:本篇文章的相关代码可能会更新,最新版本在这里可以找到:Github样例.
安装
环境
- 建议程序运行在靠近源日志库同Region下的ECS上,并使用局域网服务入口,这样好处是网络速度最快,其次是读取没有外网费用产生。
- 强烈推荐PyPy3来运行本程序,而不是使用标准CPython解释器。
- 日志服务的Python SDK可以如下安装:
pypy3 -m pip install aliyun-log-python-sdk -U更多SLS Python SDK的使用手册,可以参考这里
程序配置
如下展示如何配置程序:
- 配置程序日志文件,以便后续测试或者诊断可能的问题(跳过,具体参考样例)。
- 基本的日志服务连接与消费组的配置选项。
- 目标Logstore的一些连接信息
请仔细阅读代码中相关注释并根据需要调整选项:
#encoding: utf8
def get_option():
##########################
# 基本选项
##########################
# 从环境变量中加载SLS参数与选项,endpoint、project、logstore可以多个并配对
endpoints = os.environ.get('SLS_ENDPOINTS', '').split(";") # ;分隔
projects = os.environ.get('SLS_PROJECTS', '').split(";") # ;分隔
logstores = os.environ.get('SLS_LOGSTORES', '').split(";") # ;分隔,同一个Project下的用,分隔
accessKeyId = os.environ.get('SLS_AK_ID', '')
accessKey = os.environ.get('SLS_AK_KEY', '')
consumer_group = os.environ.get('SLS_CG', '')
# 消费的起点。这个参数在第一次跑程序的时候有效,后续再次运行将从上一次消费的保存点继续。
# 可以使”begin“,”end“,或者特定的ISO时间格式。
cursor_start_time = "2018-12-26 0:0:0"
# 一般不要修改消费者名,尤其是需要并发跑时
consumer_name = "{0}-{1}".format(consumer_group, current_process().pid)
# 设定共享执行器
exeuctor = ThreadPoolExecutor(max_workers=2)
# 构建多个消费组(每个logstore一个)
options = []
for i in range(len(endpoints)):
endpoint = endpoints[i].strip()
project = projects[i].strip()
if not endpoint or not project:
logger.error("project: {0} or endpoint {1} is empty, skip".format(project, endpoint))
continue
logstore_list = logstores[i].split(",")
for logstore in logstore_list:
logstore = logstore.strip()
if not logstore:
logger.error("logstore for project: {0} or endpoint {1} is empty, skip".format(project, endpoint))
continue
option = LogHubConfig(endpoint, accessKeyId, accessKey, project, logstore, consumer_group,
consumer_name, cursor_position=CursorPosition.SPECIAL_TIMER_CURSOR,
cursor_start_time=cursor_start_time, shared_executor=exeuctor)
options.append(option)
# 设定检测目标字段与目标值,例如这里是检测status字段是否有500等错误
keywords = {'status': r'5\d{2}'}
return exeuctor, options, keywords注意,配置了多个endpoint、project、logstore,需要用分号分隔,并且一一对应;如果一个project下有多个logstore需要检测,可以将他们直接用逗号分隔。如下是一个检测3个Region下的4个Logstore的配置:
export SLS_ENDPOINTS=cn-hangzhou.log.aliyuncs.com;cn-beijing.log.aliyuncs.com;cn-qingdao.log.aliyuncs.com
export SLS_PROJECTS=project1;project2;project3
export SLS_LOGSTORES=logstore1;logstore2;logstore3_1,logstore3_2数据监测
如下代码展示如何构建一个关键字检测器,针对数据中的目标字段进行检测,您也可以修改逻辑设定为符合需要的场景(例如多个字段的组合关系等)。
class KeywordMonitor(ConsumerProcessorBase):
"""
this consumer will keep monitor with k-v fields. like {"content": "error"}
"""
def __init__(self, keywords=None, logstore=None):
super(KeywordMonitor, self).__init__() # remember to call base init
self.keywords = keywords
self.kw_check = {}
for k, v in self.keywords.items():
self.kw_check[k] = re.compile(v)
self.logstore = logstore
def process(self, log_groups, check_point_tracker):
logs = PullLogResponse.loggroups_to_flattern_list(log_groups)
match_count = 0
sample_error_log = ""
for log in logs:
m = None
for k, c in self.kw_check.items():
if k in log:
m = c.search(log[k])
if m:
logger.debug('Keyword detected for shard "{0}" with keyword: "{1}" in field "{2}", log: {3}'
.format(self.shard_id, log[k], k, log))
if m:
match_count += 1
sample_error_log = log
if match_count:
logger.info("Keyword detected for shard {0}, count: {1}, example: {2}".format(self.shard_id, match_count, sample_error_log))
# TODO: 这里添加通知下游的代码
else:
logger.debug("No keyword detected for shard {0}".format(self.shard_id))
self.save_checkpoint(check_point_tracker)控制逻辑
如下展示如何控制多个消费者,并管理退出命令:
def main():
exeuctor, options, keywords = get_monitor_option()
logger.info("*** start to consume data...")
workers = []
for option in options:
worker = ConsumerWorker(KeywordMonitor, option, args=(keywords,) )
workers.append(worker)
worker.start()
try:
for i, worker in enumerate(workers):
while worker.is_alive():
worker.join(timeout=60)
logger.info("worker project: {0} logstore: {1} exit unexpected, try to shutdown it".format(
options[i].project, options[i].logstore))
worker.shutdown()
except KeyboardInterrupt:
logger.info("*** try to exit **** ")
for worker in workers:
worker.shutdown()
# wait for all workers to shutdown before shutting down executor
for worker in workers:
while worker.is_alive():
worker.join(timeout=60)
exeuctor.shutdown()
if __name__ == '__main__':
main()
启动
假设程序命名为"monitor_keyword.py",可以如下启动:
export SLS_ENDPOINTS=cn-hangzhou.log.aliyuncs.com;cn-beijing.log.aliyuncs.com;cn-qingdao.log.aliyuncs.com
export SLS_PROJECTS=project1;project2;project3
export SLS_LOGSTORES=logstore1;logstore2;logstore3_1,logstore3_2
export SLS_AK_ID=<YOUR AK ID>
export SLS_AK_KEY=<YOUR AK KEY>
export SLS_CG=<消费组名,可以简单命名为"dispatch_data">
pypy3 monitor_keyword.py性能考虑
启动多个消费者
如果您的目标logstore存在多个shard,或者您的目标监测日志库较多,您可以进行一定划分并并启动多次程序:
# export SLS_ENDPOINTS, SLS_PROJECTS, SLS_LOGSTORES
nohup pypy3 dispatch_data.py &
# export SLS_ENDPOINTS, SLS_PROJECTS, SLS_LOGSTORES
nohup pypy3 dispatch_data.py &
# export SLS_ENDPOINTS, SLS_PROJECTS, SLS_LOGSTORES
nohup pypy3 dispatch_data.py &
...注意:
所有消费者使用了同一个消费组的名字和不同的消费者名字(因为消费者名以进程ID为后缀)。
但数据量较大或者目标日志库较多时,单个消费者的速度可能无法满足需求,且因为Python的GIL的原因,只能用到一个CPU核。强烈建议您根据目标日志库的Shard数以及CPU的数量进行划分,启动多次以便重复利用CPU资源。
性能吞吐
基于测试,在没有带宽限制、接收端速率限制(如Splunk端)的情况下,以推进硬件用pypy3运行上述样例,单个消费者占用大约10%的单核CPU下可以消费达到5 MB/s原始日志的速率。因此,理论上可以达到50 MB/s原始日志每个CPU核,也就是每个CPU核每天可以消费4TB原始日志。
注意: 这个数据依赖带宽、硬件参数等。
高可用性
消费组会将检测点(check-point)保存在服务器端,当一个消费者停止,另外一个消费者将自动接管并从断点继续消费。
可以在不同机器上启动消费者,这样当一台机器停止或者损坏的清下,其他机器上的消费者可以自动接管并从断点进行消费。
理论上,为了备用,也可以启动大于shard数量的消费者。
其他
限制与约束
每一个日志库(logstore)最多可以配置10个消费组,如果遇到错误ConsumerGroupQuotaExceed则表示遇到限制,建议在控制台端删除一些不用的消费组。
监测
- 在控制台查看消费组状态
- 通过云监控查看消费组延迟,并配置报警
Https
如果服务入口(endpoint)配置为https://前缀,如https://cn-beijing.log.aliyuncs.com,程序与SLS的连接将自动使用HTTPS加密。
服务器证书*.aliyuncs.com是GlobalSign签发,默认大多数Linux/Windows的机器会自动信任此证书。
原文链接
本文为云栖社区原创内容,未经允许不得转载。
日志服务Python消费组实战(三):实时跨域监测多日志库数据的更多相关文章
- 日志服务Python消费组实战(二):实时分发数据
场景目标 使用日志服务的Web-tracking.logtail(文件极简).syslog等收集上来的日志经常存在各种各样的格式,我们需要针对特定的日志(例如topic)进行一定的分发到特定的logs ...
- 孤荷凌寒自学python第四十七天通用跨数据库同一数据库中复制数据表函数
孤荷凌寒自学python第四十七天通用跨数据库同一数据库中复制数据表函数 (完整学习过程屏幕记录视频地址在文末) 今天继续建构自感觉用起来顺手些的自定义模块和类的代码. 今天打算完成的是通用的(至少目 ...
- 从壹开始前后端分离【 .NET Core2.0 +Vue2.0 】框架之十二 || 三种跨域方式比较,DTOs(数据传输对象)初探
更新反馈 1.博友@落幕残情童鞋说到了,Nginx反向代理实现跨域,因为我目前还没有使用到,给忽略了,这次记录下,为下次补充.此坑已填 2.提示:跨域的姊妹篇——<三十三║ ⅖ 种方法实现完美跨 ...
- 前端笔记之Vue(五)TodoList实战&拆分store&跨域&练习代理跨域
一.TodoList 1.1安装依赖 安装相关依赖: npm install --save-dev webpack npm install --save-dev babel-loader babel- ...
- 一.rest-framework之版本控制 二、Django缓存 三、跨域问题 四、drf分页器 五、响应器 六、url控制器
一.rest-framework之版本控制 1.作用 用于版本的控制 2.内置的版本控制 from rest_framework.versioning import QueryParameterVer ...
- Asp.Net Core WebAPI入门整理(三)跨域处理
一.Core WebAPI中的跨域处理 1.在使用WebAPI项目的时候基本上都会用到跨域处理 2.Core WebAPI的项目中自带了跨域Cors的处理,不需要单独添加程序包 3.使用方法简单 ...
- 同源策略(same-origin policy)及三种跨域方法
同源策略(same-origin policy)及三种跨域方法 1.同源策略 含义: 同源是指文档的来源相同,主要包括三个方面 协议 主机 载入文档的URL端口 所以同源策略就是指脚本只能读取和所属文 ...
- Spring Cloud架构教程 (八)消息驱动的微服务(消费组)【Dalston版】
使用消费组实现消息消费的负载均衡 通常在生产环境,我们的每个服务都不会以单节点的方式运行在生产环境,当同一个服务启动多个实例的时候,这些实例都会绑定到同一个消息通道的目标主题(Topic)上. 默认情 ...
- python接口自动化(三十七)-封装与调用--读取excel 数据(详解)
简介 在进行软件接口测试或设计自动化测试框架时,一个不比可避免的过程就是: 参数化,在利用python进行自动化测试开发时,通常会使用excel来做数据管理,利用xlrd.xlwt开源包来读写exce ...
随机推荐
- vs2012开发基于MFC的ActiveX控件
1.新建工程 2.一直点击下一步,直到出现一下界面,注意红色标注选项,点击完成. 3.进入工程的属性界面,设置工程属性 4.添加对话框资源及其他控件,添加对话框类, 5.设置对话框属性 6.设置Dia ...
- python爬虫第三天
DebugLog实战 有时候我们需要在程序运行时,一边运行一边打印调试日志.此时需要开启DebugLog. 如何开启: 首先将debugleve ...
- Content-Type: application/www-form-urlencoded
默认的方式 1.Content-Type: application/www-form-urlencoded id=3&fgf=56&908rr=767 2.Content-Type:a ...
- 微信小程序用户信息解密失败导致的内存泄漏问题。
微信小程序获取用户解密的Session_key 然后对 encryptedData进行解密 偶尔报错 时间长了之后会报内存溢出: java.lang.OutOfMemoryError: GC over ...
- 简单实用而不追求时髦的 Vim 配置
前言 由于 Vim 的广泛流行,在网络上关于 Vim 的自定义配置汗牛充栋.既有高手 Tim Pope 的极简配置 tpope/vim-sensible(这个配置一个插件都没有),也有 spf13/s ...
- [译]async/await中阻塞死锁
这篇博文主要是讲解在async/await中使用阻塞式代码导致死锁的问题,以及如何避免出现这种死锁.内容主要是从作者Stephen Cleary的两篇博文中翻译过来. 原文1:Don'tBlock o ...
- CSS怎么在项目里引入自定义字体(@font-face)
前言: 以前我一直用内置的默认字体给文字设置字体,直到一天UI妹纸给了我下面的字体 当时我是蒙蔽的,这个字体的效果如下 默认字体并无该字体,直接设置是没有效果的,这时就需要用到自定义字体了 下面 ...
- [Swift]LeetCode470. 用 Rand7() 实现 Rand10() | Implement Rand10() Using Rand7()
Given a function rand7 which generates a uniform random integer in the range 1 to 7, write a functio ...
- [Swift]LeetCode659. 分割数组为连续子序列 | Split Array into Consecutive Subsequences
You are given an integer array sorted in ascending order (may contain duplicates), you need to split ...
- [Swift]LeetCode674. 最长连续递增序列 | Longest Continuous Increasing Subsequence
Given an unsorted array of integers, find the length of longest continuous increasing subsequence (s ...