python基础概念(转)
基础回顾:
1、集合
集合有2个重要作用:关系测试(并集,差集,交集)和去重。
2、文件编码
2.7上默认文件编码是ASCII码,因为不支持中文,就出了GB2312,在2.7上要支持中文就必须申明文件编码以UTF-8的格式,UTF-8与GB2312的关系?
UTF-8是Unicode的扩展集合,Unicode包括全国地区的编码,中国很多开始程序还是以GBK的格式,GBK向下兼容GB2312,Windows默认编码是GBK。
Unicode为何要做出来?为了节省空间,存英文中文都是2个字节,本来我用ASCII码存英文只用1个字节,但是现在用你2个,所以出了UTF-8 ,存英文是1个字节,中文统一3个字节。
假如1个文件是GBK编码的,另外一个是UTF-8,如果它要读这个文件,就要进行一个转换,但是他们之间不能直接转换,这个时候就涉及到了转码的问题。所以GBK转换成UTF-8,语法是先decode 成Unicode,然后在encode成utf-8,见下图:
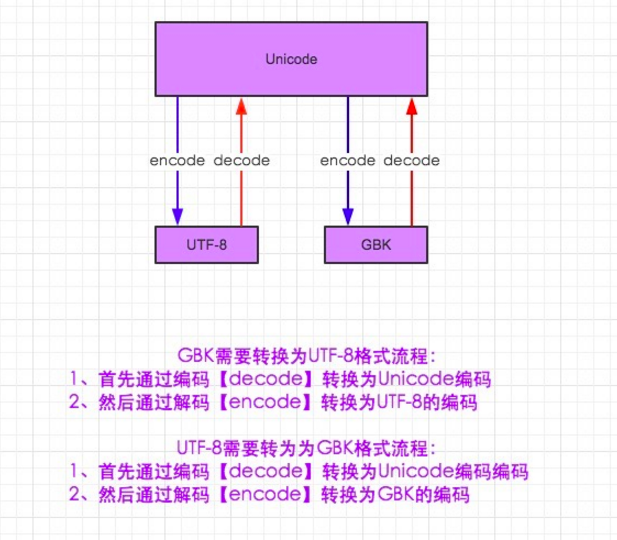
在3.0中,默认编码是Unicode,在2.7中要打印中文就得申明字符编码 # -*- coding:utf-8 -*-
在3.0可以不写,默认文件编码就是Unicode,那么现在文件编码就是Unicode,因为Unicode本来也支持中文,按2个字节存放,不需要转换成utf-8,要想变成utf-8也得encode一下,如下所示:
a= '我是'.encode("utf-8")
。当然也可以申明字符编码 # -*- coding:utf-8 -*- ,那么现在的文件编码就是utf-8了。
3、函数
格式如下:
def func_name():
pass
位置参数,比如 arg1 和 arg2
def func_name(arg1,arg2):
pass func_name(5,3)
5对应的是arg1 3对应的是arg2
关键参数,可以指定参数名,比如:
def func_name(arg1,arg2,arg3):
pass func_name(1,2,arg3=5)
注意,关键参数不能写在位置参数前面。
多个参数,就用到了*args,比如:

def func_name(arg1,arg2,*args):
pass func_name(4,5,6,7,8)
那么打印出来效果
4,5,(6,7,8)
把后面非固定参数写成了元祖
**kwargs ,打印出来是一个字典,例如
def func_name(arg1,arg2,arg3,*args,**kwargs):
pass func_name(3,4,55,666,77,name=xiedi) 打印出来的结果
3,4,55,(666,77),{'name':'xiedi'}
4、局部变量和全局变量
总的来说,局部变量只对函数内生效,对函数外不起作用。
它涉及到一个作用域的问题,只是在函数里生效的,函数执行完毕,变量就没了,作用域只允许在函数里改东西。
找变量的顺序,先从内到外找变量。
如果非得改变它的作用域,就加一个global,但是不建议这么做,例如
age = 22
def change_age():
global age
age = 24
5、返回值
返回值是因为我想得到函数的执行结果,它还代表着程序的结束
6、递归
递归相当于自己调自己,有几个条件:
1、要有一个明确的结束条件。
因为递归相当于一层进入一层。
2、问题规模每递归一次都应该比上一次的问题规模有所减少。
3、效率低
7、高阶函数
把一个函数当做另一个函数的参数传进去,返回的时候要用到这个函数。
函数式编程是不需要变量的,纯粹是一个映射关系,函数式编程是没有副作用的,就是传进去的数据是确定的,得出来的结果也是固定的。
8、文件操作
打开模式:
f = open
r,w,a
r是读,w是写,它会覆盖,a是追加,r+是读写模式,写到后面,追加的模式。
w+ 是写读,以写的模式打开文件,如果文件存在,直接覆盖。
a+追加写读
rb二进制模式打开,全部是字节格式
获得文件句柄
操作:
f.
关闭:
f.close
接下来就是重点了,先来个装饰器。顾名思义,装饰一下。
一、装饰器
从字面意思来看,器代表函数的意思,可以说,装饰器本身就是函数,都是用def语法来定义的。
装饰器:
定义:本质是函数,(装饰其他函数)
为其他函数添加附加功能。
①先来看个简单的,在没学函数之前,我想给定义的函数打个日志,写法如下:
def test1():
pass
print('logging') def test2():
pass
print('logging')
#调用
test1()
test2()
②接下来学了函数,我就把打日志定义成一个函数
# -*- coding: utf-8 -*-
#Author: Leon xie def logger():
print('logging') def test1():
pass
logger() def test2():
pass
logger()
#调用
test1()
test2()
假设我写的函数已经上线运行了,某一天,我有个需求,在这个里面新增一个功能,那怎么去做这个事?
最简单的就是:挨个找到100个函数,加上去。但是问题是程序已经运行了,我刚才操作是修改我程序的源代码,会有风险发生。
所以说,我要新增一个功能,不能够修改函数的源代码,函数一旦写好了,原则上不能动源代码了。
所以就有了下面的原则:
原则:
1、不能修改被装饰函数的源代码。
2、不能修改被装饰的函数的调用方式。
装饰器对于被装饰函数是完全透明的。他没有动我的源代码,我该怎么调用运行就怎么运行。
举例子:
定义1个函数
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#Author: Leon xie import time def test1():
time.sleep(3)
print('in the test1') test1()
这个函数实现的就是 睡3秒然后打印
接下来写个装饰器:
用的时候只要在函数前面加一个“@函数名”, 即可
先睡3s然后打印,随后统计了一个test1函数的运行时间。
第一:装饰器本质就是一个函数
第二:装饰器不修改被装饰函数的源代码和调用方式
第三:对于函数 test1来说,装饰器完全不存在。
实现这个装饰器的功能需要哪些知识呢?
1、函数即变量
2、高阶函数
3、嵌套函数
最终:
高阶函数+嵌套函数===>装饰器
我们来复习一下变量:
变量是存在内存当中,比如我x=1,那么它是如何存在变量中呢?如下图:
其实我要说的就是函数即变量。
变量调用加上变量名直接调用。
函数调用呢就是函数加个小括号。 test()

python解释器中有一个概念叫做引用计数。
比如x=1 ,y=x,那么就是2次计数。
x和y相当于房间的门牌号,如果没有门牌号了,那么内存里的1就会被清空。
匿名函数:
有的函数是不定义名字的。
例如:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#Author: Leon xie
#为了后面调用,我起了一个变量名,这个函数没有名字
calc = lambda x:x*3
print(calc(3))
输出结果
9
匿名函数没有def起函数名。
小结:
函数就是一个变量,定义一个函数,就是把函数体付给了这个函数名。
变量特性是:内存回收。
既然说函数即变量那么下面这个函数如何存放呢?
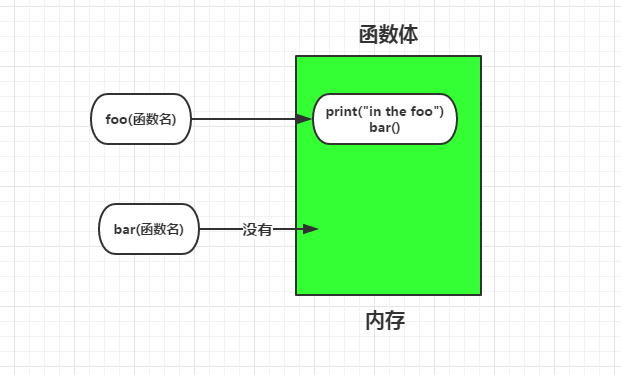
def foo():
print('in the foo')
bar()
foo()
这个函数就回报错,如下图所示:
变量是先定义,后引用,函数也是一样。
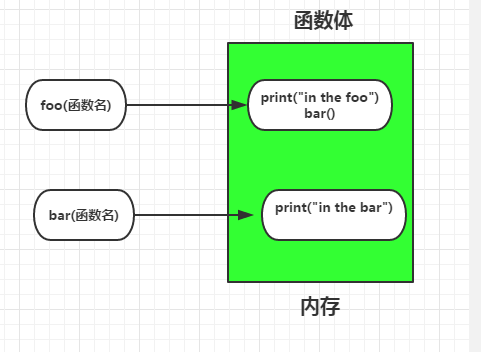
看下面这个例子:可以正常调用,只要在调用之前存在就可以调用
def foo():
print('in the foo')
bar()
def bar():
print('in the bar')
foo()
高阶函数:(满足下面2个条件)
a:把一个函数名当做实参传给另外一个函数(在不修改被装饰函数源代码的情况下为其添加功能)
b:返回值中包含函数名
按照第一条原则写一个
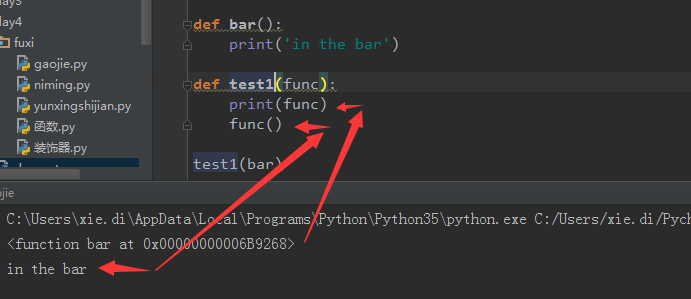
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#Author: Leon xie def bar():
print('in the bar') def test1(func):
print(func) test1(bar)
输出结果
<function bar at 0x0000000000A69268>
一段内存地址
上面相当于
func= bar 是一个门牌地址
func()是可以运行的,所以可以写成这样 类似于x=1 y=x
那么就有了下面的函数,附加一个计数的功能。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#Author: Leon xie import time
def bar():
time.sleep(3)
print('in the bar') def test1(func):
start_time =time.time()
#运行一下func
func()
stop_time =time.time()
#传进来的运行时间不是test1
print("the func run time is %s" %(stop_time-start_time)) test1(bar) 输出结果
in the bar
the func run time is 3.0002999305725098
这里在没有修改源代码的基础上新增了一个计数的功能。不过我们知道装饰器还有一个条件就是不改变调用方式。所以我们接着往下看

嵌套函数举例:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#Author: Leon xie def foo():
print('in the foo')
def bar():
print('in the bar') bar()
foo()
输出结果
in the foo
in the bar
最后装饰器效果:
#写个装饰器统计运行的时间 import time def timer(func): #timer(test1) test1 的内存地址给了func
def deco(*args,**kwargs):
start_time=time.time()
func(*args,**kwargs)
stop_time= time.time()
print('the func run time is %s' %(stop_time-start_time))
return deco #返回了deco的内存地址 #嵌套函数写成下面的形式
#def timer():
# def deco():
# pass @timer #test1= timer(test1)
def test1():
time.sleep(1)
print('in the test1') @timer #test2= timer(test2)
def test2(name,age):
time.sleep(1)
print("test2:",name,age) test1()
test2("xiedi",22) 输出结果
in the test1
the func run time is 1.0
test2: xiedi 22
the func run time is 1.0
升级
输出结果
welcome to index page
Username:xiedi
Password:123
User has passed authentication
welcome to hoem page
--afterauthenticaion
from home
Username:
升级,加入新的判断,登录判断
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#Author: Leon xie #需求:公司有网站,有很多页面,模拟1个页面1个函数,在之前情况谁都可以登录没有任何验证
#100个页面有20个登录以后才能看到,就说给20个加入验证功能。 #可不可以让home认证的时候使用本地认证,bbs用远程认证 import time
user,passwd = 'xiedi','123'
def auth(auth_type):
print("auth func:",auth_type)
def outer_wrapper(func):
def wrapper(*args,**kwargs):
print("wrapper func args:",args,**kwargs)
username = input("Username:").strip()
password = input("Password:").strip() if user == username and passwd == password:
print("\033[32;1mUser has passed authentication\033[0m")
res = func(*args,**kwargs)
print("--afterauthenticaion")
return res
else:
exit("\033[31;1mInvalid username or password\033[0m")
return wrapper
return outer_wrapper def index():
print("welcome to index page") @auth(auth_type = "local")
def home():
print("welcome to hoem page")
return "from home" @auth(auth_type = "ldap")
def bbs():
print("welcome to bbs page") index()
home()
bbs()
输出结果
auth func: local
auth func: ldap
welcome to index page
wrapper func args: ()
Username:xiedi
Password:123
User has passed authentication
welcome to hoem page
--afterauthenticaion
wrapper func args: ()
Username:xiedi
Password:123
User has passed authentication
welcome to bbs page
--afterauthenticaion Process finished with exit code 0
二、迭代器和生成器
列表生成式:
我们到列表的定义,比如a=[1,2,3],我们还可以这么写[i*2 for i in range(10)]

就是i在range(10)做一个for循环,然后乘以2得到一个列表。这个就叫做列表生成式。主要作用是使代码更简洁。
还可以在前面执行一个函数,如下图:

生成器:
通过列表生成式,我们可以直接创建一个列表,但是,收到内存限制,列表容量肯定是有限的。
比如我创建100W元素的列表,我只用前面几个,后面都不用,是不是浪费?
所以,如果列表元素可以按照某种算法推算出来,那我们就不必创建完整的list,从而节省大量的空间,在Python中,这种一边循环一边计算的机制,称为生成器:generator。
怎么去节省内存呢?循环列表是1个1个循环,列表从头循环到尾的时候,我循环10次,循环到第5次的时候,后面的5个数据是已经准备好的。剩下的就很占用空间,那么我能不能搞个机制出来,我循环到第4次的时候,第4次的数据才刚生成。剩下的我不调用就没有
这样我就不需要提前把数据准备好了,省了空间了。
那么数据是怎么生成呢?有规律的做法
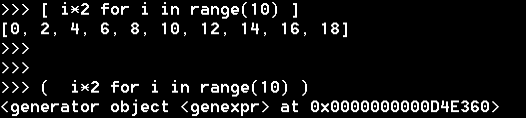
这样就是没循环一次乘以2了。你访问它,它才会生成。
生成器,只有在调用时才会生成相应的数据。
生成器只记住当前这个位置,它也不知道前面,也不知道后面,前面用完了对它来讲没了,它只保存一个值。
1、只记录当前位置
2、只有一个_next_()方法。
(i*i for i in range(10))这个语句高了一个生成器。
如果后面生成数据没有规律那怎么办?
再次,创建一个生成器:
用函数来做一个生成器。
斐波拉契数列,除第一个和第二个数外,任意一个数都可以由前面2个数相加得到
1,1,2,3,5,8,13,21,34。。。。
规则就是如此。
他是有一定规律就可以推导出来。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#Author: Leon xie def fib(max):
n, a, b = 0,0,1
while n <max:
print(b)
a,b =b ,a+b
n=n+1
return 'done' fib(10) 结果
1
1
2
3
5
8
13
21
34
55
分析:
a,b=1,2
a=1
b=2
t=(b,a+b)
所以这个时候
a=2 b=3了
把上面函数改成生成器,1步即可
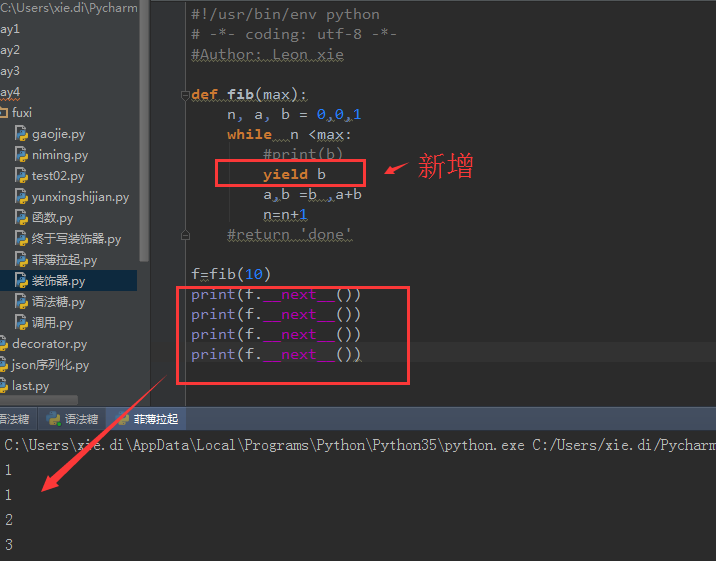
变成了一个生成器。
这样做的好处在哪呢?
之前,我们调用函数,如果函数在执行时候需要花费10分钟,那么我接下来的操作就要在10分钟后进行。程序就卡在这了
现在这个呢?现在函数变成生成器之后,我直接调用一下next,它就在里面循环一次,停在这了,程序就跑到外面了,我可以干点别的事在回去。例如:
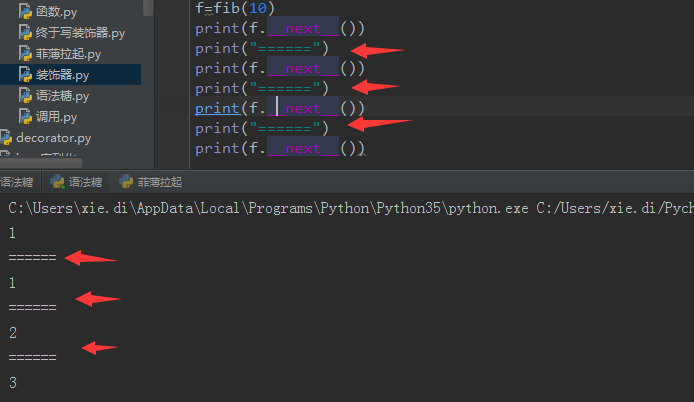
这样就把函数做成了一个生成器。
接下来有个问题,就是如果我取得数大于10,用next 方法取不到就会报一个异常。如何解决呢?
就是要抓住这个异常: try一下
g = fib(6) while True:
try:
x = next(g)
print('g:',x)
except StopIteration as e:
print('Generator return value:',e.value)
break
yield是保存了函数的中断状态,返回当前状态的值,函数停在这了,一会还可以回来。
工作中如何使用呢?
我们可以通过yield来实现单线程的情况下实现并发运算的效果
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#Author: Leon xie import time #典型的生产者消费者模型
def consumer(name):
print("%s 准备吃包子啦!!" %name) while True:
baozi = yield print("包子[%s]来了,被[%s]吃了" %(baozi,name)) c = consumer("xiedi")
c.__next__() b1 = "韭菜馅"
c.send(b1)
#c.__next__() def producer(name):
c = consumer('A')
c2 = consumer('B')
c.__next__()
c2.__next__()
print("老子开始准备做包子了!")
for i in range(10):
time.sleep(1)
print("做了2个包子")
c.send(i)
producer("dd")
输出结果
xiedi 准备吃包子啦!!
包子[韭菜馅]来了,被[xiedi]吃了
A 准备吃包子啦!!
B 准备吃包子啦!!
老子开始准备做包子了!
做了2个包子
包子[0]来了,被[A]吃了
做了2个包子
包子[1]来了,被[A]吃了
做了2个包子
包子[2]来了,被[A]吃了
做了2个包子
包子[3]来了,被[A]吃了
做了2个包子
包子[4]来了,被[A]吃了
做了2个包子
包子[5]来了,被[A]吃了
做了2个包子
包子[6]来了,被[A]吃了
做了2个包子
包子[7]来了,被[A]吃了
做了2个包子
包子[8]来了,被[A]吃了
做了2个包子
包子[9]来了,被[A]吃了
迭代器:
可直接作用于for循环的数据类型有以下几种:
一类是集合数据类型,如list,tuple ,dict ,set ,str等。
一类是generator,包括生成器和带yield的 generator function。
可以使用isinstance()判断一个对象是否是Iterable对象。

可以被next()函数调用并不断返回下一个值得对象统称为迭代器。
可以直接作用于for循环的对象统称为可迭代对象:Iterable 。
三、软件目录结构规范
目录结构目的
- 可读性高: 不熟悉这个项目的代码的人,一眼就能看懂目录结构,知道程序启动脚本是哪个,测试目录在哪儿,配置文件在哪儿等等。从而非常快速的了解这个项目。
- 可维护性高: 定义好组织规则后,维护者就能很明确地知道,新增的哪个文件和代码应该放在什么目录之下。这个好处是,随着时间的推移,代码/配置的规模增加,项目结构不会混乱,仍然能够组织良好。
假设你的项目名为foo, 我比较建议的最方便快捷目录结构这样就足够了:
Foo/ 项目名 |-- bin/ 可执行放的目录 | |-- foo 启动foo调用main | |-- foo/ 主程序目录 | |-- tests/ 测试的,程序的主逻辑,测试代码 | | |-- __init__.py | | |-- test_main.py | | | |-- __init__.py 必须有,这是一个空文件 | |-- main.py 程序主入口,启动foo去调用main | |-- docs/ 文档 | |-- conf.py | |-- abc.rst | |-- setup.py 安装部署的脚步 |-- requirements.txt 依赖关系,比如依赖安装mysql |-- README
---conf 配置文件目录简要解释一下:
bin/: 存放项目的一些可执行文件,当然你可以起名script/之类的也行。foo/: 存放项目的所有源代码。(1) 源代码中的所有模块、包都应该放在此目录。不要置于顶层目录。(2) 其子目录tests/存放单元测试代码; (3) 程序的入口最好命名为main.py。docs/: 存放一些文档。setup.py: 安装、部署、打包的脚本。requirements.txt: 存放软件依赖的外部Python包列表。README: 项目说明文件。- conf:配置文件目录
关于README的内容
这个我觉得是每个项目都应该有的一个文件,目的是能简要描述该项目的信息,让读者快速了解这个项目。
它需要说明以下几个事项:
- 软件定位,软件的基本功能。
- 运行代码的方法: 安装环境、启动命令等。
- 简要的使用说明。
- 代码目录结构说明,更详细点可以说明软件的基本原理。
- 常见问题说明。
我觉得有以上几点是比较好的一个README。在软件开发初期,由于开发过程中以上内容可能不明确或者发生变化,并不是一定要在一开始就将所有信息都补全。但是在项目完结的时候,是需要撰写这样的一个文档的。
可参考:https://github.com/antirez/redis#what-is-redi
python基础概念(转)的更多相关文章
- Python 简明教程 --- 3,Python 基础概念
微信公众号:码农充电站pro 个人主页:https://codeshellme.github.io 控制复杂性是计算机编程的本质. -- Brian Kernighan 了解了如何编写第一个Pytho ...
- 第4章 基础知识进阶 第4.1节 Python基础概念之迭代、可迭代对象、迭代器
第四章 基础知识进阶第十七节 迭代.可迭代对象.迭代器 一. 引言 本来计划讲完元组和字典后就讲列表解析和字典解析,但要理解列表解析和字典解析,就需要掌握Python的高级的类型迭代器,因此本节 ...
- Python基础概念
一.Python中执行代码的方式 直接在编译器中交互执行: 在编译器中通过Python和文件的路径执行: 在linux系统中可以./test.py(需要代码第一行增加# !/usr/bin/env p ...
- python学习笔记(0)python基础概念
一.字符集 说字符集之前,先说下2进制的故事,计算机比较傻只认识2进制,什么是2进制,就是0,1,计算机只认识这俩数字,其他的都不认识,这样的0或1为一"位",规定8位为一个字节, ...
- Python笔记002-Python编程基础概念
第二章(1):Python编程基础概念 1. Python 程序的构成 Python 程序有模块组成.一个模块对应 Python 源文件,一般后缀名是:.py. 模块有语句组成.运行 Python程序 ...
- python3 速查参考- python基础 8 -> 面向对象基础:类的创建与基础使用,类属性,property、类方法、静态方法、常用知识点概念(封装、继承等等见下一章)
基础概念 1.速查笔记: #-- 最普通的类 class C1(C2, C3): spam = 42 # 数据属性 def __init__(self, name): # 函数属性:构造函数 self ...
- Python基础篇(四)_组合数据类型的基本概念
Python基础篇——组合数据类型的基本概念 集合类型:元素的集合,元素之间无序 序列类型:是一个元素向量,元素之间存在先后关系,通过序号进行访问,没有排他性,具体包括字符串类型.元组类型.列表类型 ...
- (数据科学学习手札102)Python+Dash快速web应用开发——基础概念篇
本文示例代码与数据已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 这是我的新系列教程Python+Dash快 ...
- 【Machine Learning】机器学习及其基础概念简介
机器学习及其基础概念简介 作者:白宁超 2016年12月23日21:24:51 摘要:随着机器学习和深度学习的热潮,各种图书层出不穷.然而多数是基础理论知识介绍,缺乏实现的深入理解.本系列文章是作者结 ...
随机推荐
- Odd-e CSD Course Day 3
Mocking 在提到Mocking時,其實有提到為什麼我們需要 Mocking from: Odd-e CSD course 可以透過上圖來了解這個概念,當我們需要用到 Mock 時,其實是因為我們 ...
- JQuery官方学习资料(译):Utility方法
JQuery提供了一些utility方法在$命名空间里,这些方法对完成常规的编程任务非常有帮助. $.trim() 删除前后部的空白内容. // 返回 "lots of ex ...
- C# 在PDF中绘制动态图章
我们知道,动态图章,因图章中的时间.日期可以动态的生成,因而具有较强的时效性.在本篇文章中将介绍通过C#编程在PDF中绘制动态图章的方法,该方法可自动获取当前系统登录用户名.日期及时间信息并生成图章. ...
- 看Android Stuido教程有感
毕业两年了,之前一直都在另外的博客里写之前大学的经历,以及转载一些学习Android的点滴,原创的并不多.因为现在更多的是在博客园里逛,所以直到上个月还是鼓起勇气开通了博客,算来到今天也有一段时间了, ...
- 史上最全python面试题详解(四)(附带详细答案(关注、持续更新))
python高级进阶-网络编程和并发(?道题详解) 1.简述 OSI 七层协议. OSI是Open System Interconnection的缩写,意为开放式系统互联. OSI七层协议模型主要是: ...
- JavaScript类型化数组(二进制数组)
0.前言 对于前端程序员来说,平时很少和二进制数据打交道,所以基本上用不到ArrayBuffer,大家对它很陌生,但是在使用WebGL的时候,ArrayBuffer无处不在.浏览器通过WebGL和显卡 ...
- Thinkphp5整合微信扫码支付开发实例
ThinkPHP框架是比较多人用的,曾经做过的一个Thinkphp5整合微信扫码支付开发实例,分享出来大家一起学习 打开首页生成订单,并显示支付二维码 public function index() ...
- (办公)MojoExecutionException
MojoExecutionException : mavan打包错误. 通过以下命令解决:mvn clean install (新改的内容生效)
- SQL 日期时间比较
原先的判断是 ae.首次受理时刻 >= '2015/12/1 0:00:00' AND ae.首次受理时刻 <= '2015/12/25 0:00:00' ,改为如下和时间变量比较 效率 ...
- asp.net网页上获取其中表格中的数据(爬数据)
下面的方法获取页面中表格数据,每个页面不相同,获取的方式(主要是正则表达式)不一样,只是提供方法参考.大神勿喷,刚使用了,就记下来了. 其中数据怎么存,主要就看着怎么使用了.只是方便记录就都放在lis ...