Go语言数组和切片的原理
数组和切片是 Go 语言中常见的数据结构,很多刚刚使用 Go 的开发者往往会混淆这两个概念,数组作为最常见的集合在编程语言中是非常重要的,除了数组之外,Go 语言引入了另一个概念 — 切片,切片与数组有一些类似,但是它们的不同之处导致使用上会产生巨大的差别。
这里我们将从 Go 语言 编译期间 的工作和运行时来介绍数组以及切片的底层实现原理,其中会包括数组的初始化以及访问、切片的结构和常见的基本操作。
数组
数组是由相同类型元素的集合组成的数据结构,计算机会为数组分配一块连续的内存来保存数组中的元素,我们可以利用数组中元素的索引快速访问元素对应的存储地址,常见的数组大多都是一维的线性数组,而多维数组在数值和图形计算领域却有比较常见的应用。
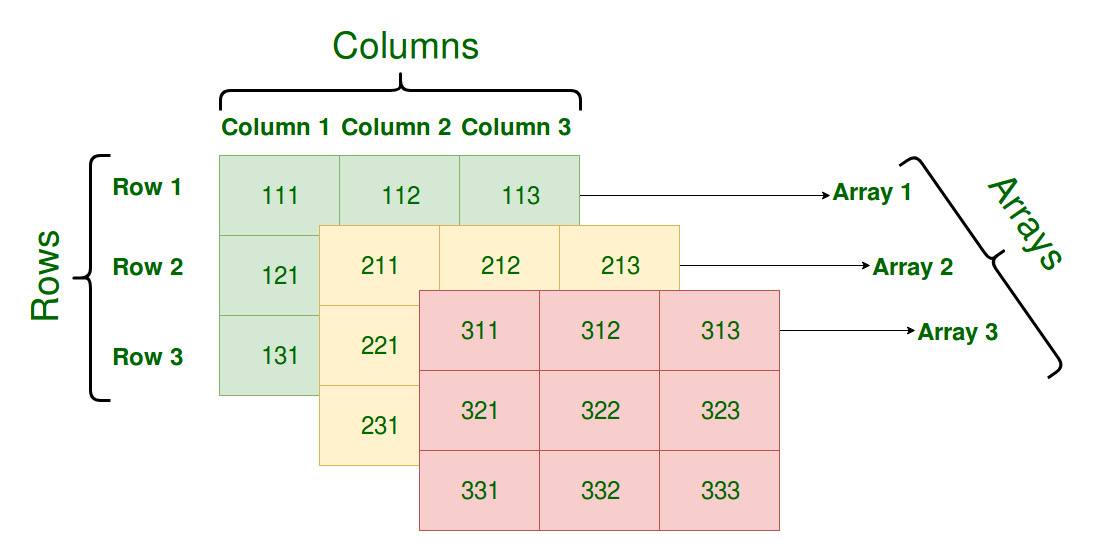
数组作为一种数据类型,一般情况下由两部分组成,其中一部分表示了数组中存储的元素类型,另一部分表示数组最大能够存储的元素个数,Go 语言的数组类型一般是这样的:
[10]int
[200]interface{}
Go 语言中数组的大小在初始化之后就无法改变,数组存储元素的类型相同,但是大小不同的数组类型在 Go 语言看来也是完全不同的,只有两个条件都相同才是同一个类型。
func NewArray(elem *Type, bound int64) *Type {
if bound < 0 {
Fatalf("NewArray: invalid bound %v", bound)
}
t := New(TARRAY)
t.Extra = &Array{Elem: elem, Bound: bound}
t.SetNotInHeap(elem.NotInHeap())
return t
}
编译期间的数组类型 Array 就包含两个结构,一个是元素类型 Elem,另一个是数组的大小上限 Bound,这两个字段构成了数组类型,而当前数组是否应该在堆栈中初始化也在编译期间就确定了。
创建
Go 语言中的数组有两种不同的创建方式,一种是我们显式指定数组的大小,另一种是编译器通过源代码自行推断数组的大小:
arr1 := [3]int{1, 2, 3}
arr2 := [...]int{1, 2, 3}
后一种声明方式在编译期间就会被『转换』成为前一种,下面我们先来介绍数组大小的编译期推导过程。
上限推导
这两种不同的方式会导致编译器做出不同的处理,如果我们使用第一种方式 [10]T,那么变量的类型在编译进行到 类型检查 阶段就会被推断出来,在这时编译器会使用 NewArray 创建包含数组大小的 Array 类型,而如果使用 [...]T 的方式,虽然在这一步也会创建一个 Array 类型 Array{Elem: elem, Bound: -1},但是其中的数组大小上限会是 -1 的结构,这意味着还需要后面的 typecheckcomplit 函数推导该数组的大小:
func typecheckcomplit(n *Node) (res *Node) {
// ...
switch t.Etype {
case TARRAY, TSLICE:
var length, i int64
nl := n.List.Slice()
for i2, l := range nl {
i++
if i > length {
length = i
}
}
if t.IsDDDArray() {
t.SetNumElem(length)
}
}
}
这个删减后的 typecheckcomplit 函数通过遍历元素来推导当前数组的长度,我们能看出 [...]T 类型的声明不是在运行时被推导的,它会在类型检查期间就被推断出正确的数组大小。
语句转换
虽然 [...]T{1, 2, 3} 和 [3]T{1, 2, 3} 在运行时是完全等价的,但是这种简短的初始化方式也只是 Go 语言为我们提供的一种语法糖,对于一个由字面量组成的数组,根据数组元素数量的不同,编译器会在负责初始化字面量的 anylit 函数中做两种不同的优化:
func anylit(n *Node, var_ *Node, init *Nodes) {
t := n.Type
switch n.Op {
case OSTRUCTLIT, OARRAYLIT:
if n.List.Len() > 4 {
vstat := staticname(t)
vstat.Name.SetReadonly(true)
fixedlit(inNonInitFunction, initKindStatic, n, vstat, init)
a := nod(OAS, var_, vstat)
a = typecheck(a, ctxStmt)
a = walkexpr(a, init)
init.Append(a)
break
}
fixedlit(inInitFunction, initKindLocalCode, n, var_, init)
// ...
}
}
- 当元素数量小于或者等于 4 个时,会直接将数组中的元素放置在栈上;
- 当元素数量大于 4 个时,会将数组中的元素放置到静态区并在运行时取出;
当数组的元素小于或者等于四个时,fixedlit 会负责在函数编译之前将批了语法糖外衣的代码转换成原有的样子:
func fixedlit(ctxt initContext, kind initKind, n *Node, var_ *Node, init *Nodes) {
var splitnode func(*Node) (a *Node, value *Node)
// ...
for _, r := range n.List.Slice() {
a, value := splitnode(r)
a = nod(OAS, a, value)
a = typecheck(a, ctxStmt)
switch kind {
case initKindStatic:
genAsStatic(a)
case initKindLocalCode:
a = orderStmtInPlace(a, map[string][]*Node{})
a = walkstmt(a)
init.Append(a)
default:
Fatalf("fixedlit: bad kind %d", kind)
}
}
}
由于传入的类型是 initKindLocalCode,上述代码会将原有的初始化语法拆分成一个声明变量的语句和 N 个用于赋值的语句:
var arr [3]int
arr[0] = 1
arr[1] = 2
arr[2] = 3
但是如果当前数组的元素大于 4 个时,anylit 方法会先获取一个唯一的 staticname,然后调用 fixedlit 函数在静态存储区初始化数组中的元素并将临时变量赋值给当前的数组:
func fixedlit(ctxt initContext, kind initKind, n *Node, var_ *Node, init *Nodes) {
var splitnode func(*Node) (a *Node, value *Node)
// ...
for _, r := range n.List.Slice() {
a, value := splitnode(r)
setlineno(value)
a = nod(OAS, a, value)
a = typecheck(a, ctxStmt)
switch kind {
case initKindStatic:
genAsStatic(a)
default:
Fatalf("fixedlit: bad kind %d", kind)
}
}
}
假设,我们在代码中初始化 []int{1, 2, 3, 4, 5} 数组,那么我们可以将上述过程理解成以下的伪代码:
var arr [5]int
statictmp_0[0] = 1
statictmp_0[1] = 2
statictmp_0[2] = 3
statictmp_0[3] = 4
statictmp_0[4] = 5
arr = statictmp_0
总结起来,如果数组中元素的个数小于或者等于 4 个,那么所有的变量会直接在栈上初始化,如果数组元素大于 4 个,变量就会在静态存储区初始化然后拷贝到栈上,这些转换后的代码才会继续进入 中间代码生成 和 机器码生成 两个阶段,最后生成可以执行的二进制文件。
访问和赋值
无论是在栈上还是静态存储区,数组在内存中其实就是一连串的内存空间,表示数组的方法就是一个指向数组开头的指针,这一片内存空间不知道自己存储的是什么变量:

数组访问越界的判断也都是在编译期间由静态类型检查完成的,typecheck1 函数会对访问的数组索引进行验证:
func typecheck1(n *Node, top int) (res *Node) {
switch n.Op {
case OINDEX:
ok |= ctxExpr
l := n.Left
r := n.Right
t := l.Type
switch t.Etype {
case TSTRING, TARRAY, TSLICE:
why := "string"
if t.IsArray() {
why = "array"
} else if t.IsSlice() {
why = "slice"
}
if n.Right.Type != nil && !n.Right.Type.IsInteger() {
yyerror("non-integer %s index %v", why, n.Right)
break
}
if !n.Bounded() && Isconst(n.Right, CTINT) {
x := n.Right.Int64()
if x < 0 {
yyerror("invalid %s index %v (index must be non-negative)", why, n.Right)
} else if t.IsArray() && x >= t.NumElem() {
yyerror("invalid array index %v (out of bounds for %d-element array)", n.Right, t.NumElem())
} else if Isconst(n.Left, CTSTR) && x >= int64(len(n.Left.Val().U.(string))) {
yyerror("invalid string index %v (out of bounds for %d-byte string)", n.Right, len(n.Left.Val().U.(string)))
}
}
}
//...
}
}
无论是编译器还是字符串,它们的越界错误都会在编译期间发现,但是数组访问操作 OINDEX 会在编译期间被转换成两个 SSA 指令:
PtrIndex <t> ptr idx
Load <t> ptr mem
编译器会先获取数组的内存地址和访问的下标,然后利用 PtrIndex 计算出目标元素的地址,再使用 Load 操作将指针中的元素加载到内存中。
数组的赋值和更新操作 a[i] = 2 也会生成 SSA 期间就计算出数组当前元素的内存地址,然后修改当前内存地址的内容,其实会被转换成如下所示的 SSA 操作:
LocalAddr {sym} base _
PtrIndex <t> ptr idx
Store {t} ptr val mem
在这个过程中会确实能够目标数组的地址,再通过 PtrIndex 获取目标元素的地址,最后将数据存入地址中,从这里我们可以看出无论是数组的寻址还是赋值都是在编译阶段完成的,没有运行时的参与。
切片
数组其实在 Go 语言中没有那么常用,更加常见的数据结构其实是切片,切片其实就是动态数组,它的长度并不固定,可以追加元素并会在切片容量不足时进行扩容。
在 Golang 中,切片类型的声明与数组有一些相似,由于切片是『动态的』,它的长度并不固定,所以声明类型时只需要指定切片中的元素类型:
[]int
[]interface{}
从这里的定义我们其实也能推测出,切片在编译期间的类型应该只会包含切片中的元素类型,NewSlice 就是编译期间用于创建 Slice 类型的函数:
func NewSlice(elem *Type) *Type {
if t := elem.Cache.slice; t != nil {
if t.Elem() != elem {
Fatalf("elem mismatch")
}
return t
}
t := New(TSLICE)
t.Extra = Slice{Elem: elem}
elem.Cache.slice = t
return t
}
我们可以看到上述方法返回的类型 TSLICE 的 Extra 字段是一个只包含切片内元素类型的 Slice{Elem: elem}结构,也就是说切片内元素的类型是在编译期间确定的。
结构
编译期间的切片其实就是一个 Slice 类型,但是在运行时切片其实由如下的 SliceHeader 结构体表示,其中 Data 字段是一个指向数组的指针,Len 表示当前切片的长度,而 Cap 表示当前切片的容量,也就是 Data 数组的大小:
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
Data 作为一个指针指向的数组其实就是一片连续的内存空间,这片内存空间可以用于存储切片中保存的全部元素,数组其实就是一片连续的内存空间,数组中的元素只是逻辑上的概念,底层存储其实都是连续的,所以我们可以将切片理解成一片连续的内存空间加上长度与容量标识。

与数组不同,数组中大小、其中的元素还有对数组的访问和更新在编译期间就已经全部转换成了直接对内存的操作,但是切片是运行时才会确定的结构,所有的操作还需要依赖 Go 语言的运行时来完成,我们接下来就会介绍切片的一些常见操作的实现原理。
初始化
首先需要介绍的就是切片的创建过程,Go 语言中的切片总共有两种初始化的方式,一种是使用字面量初始化新的切片,另一种是使用关键字 make 创建切片:
slice := []int{1, 2, 3}
slice := make([]int, 10)
字面量
我们先来介绍如何使用字面量的方式创建新的切片结构,[]int{1, 2, 3} 其实会在编译期间由 slicelit 转换成如下所示的代码:
var vstat [3]int
vstat[0] = 1
vstat[1] = 2
vstat[2] = 3
var vauto *[3]int = new([3]int)
*vauto = vstat
slice := vauto[:]
- 根据切片中的元素数量对底层数组的大小进行推断并创建一个数组;
- 将这些字面量元素存储到初始化的数组中;
- 创建一个同样指向
[3]int类型的数组指针; - 将静态存储区的数组
vstat赋值给vauto指针所在的地址; - 通过
[:]操作获取一个底层使用vauto的切片;
[:] 以及类似的操作 [:10] 其实都会在 SSA 代码生成 阶段被转换成 OpSliceMake 操作,这个操作会接受四个参数创建一个新的切片,切片元素类型、数组指针、切片大小和容量。
关键字
如果使用字面量的方式创建切片,大部分的工作就都会在编译期间完成,但是当我们使用 make 关键字创建切片时,在 类型检查 期间会检查 make『函数』的参数,调用方必须传入一个切片的大小以及可选的容量:
func typecheck1(n *Node, top int) (res *Node) {
switch n.Op {
// ...
case OMAKE:
args := n.List.Slice()
i := 1
switch t.Etype {
case TSLICE:
if i >= len(args) {
yyerror("missing len argument to make(%v)", t)
return n
}
l = args[i]
i++
var r *Node
if i < len(args) {
r = args[i]
}
// ...
if Isconst(l, CTINT) && r != nil && Isconst(r, CTINT) && l.Val().U.(*Mpint).Cmp(r.Val().U.(*Mpint)) > 0 {
yyerror("len larger than cap in make(%v)", t)
return n
}
n.Left = l
n.Right = r
n.Op = OMAKESLICE
}
// ...
}
}
make 参数的检查都是在 typecheck1 函数中完成的,它不仅会检查 len,而且会保证传入的容量 cap 一定大于或者等于 len;随后的中间代码生成阶段会把这里的 OMAKESLICE 类型的操作都转换成如下所示的函数调用:
makeslice(type, len, cap)
当切片的容量和大小不能使用 int 来表示时,就会实现 makeslice64 处理容量和大小更大的切片,无论是 makeslice 还是 makeslice64,这两个方法都是在结构逃逸到堆上初始化时才需要调用的,如果当前的切片不会发生逃逸并且切片非常小的时候,make([]int, 3, 4) 才会被转换成如下所示的代码:
var arr [4]int
n := arr[:3]
在这时,数组的初始化和 [:3] 操作就都会在编译阶段完成大部分的工作,前者会在静态存储区被创建,后者会被转换成 OpSliceMake 操作。
接下来,我们回到用于创建切片的 makeslice 函数,这个函数的实现其实非常简单:
func makeslice(et *_type, len, cap int) unsafe.Pointer {
mem, overflow := math.MulUintptr(et.size, uintptr(cap))
if overflow || mem > maxAlloc || len < 0 || len > cap {
mem, overflow := math.MulUintptr(et.size, uintptr(len))
if overflow || mem > maxAlloc || len < 0 {
panicmakeslicelen()
}
panicmakeslicecap()
}
return mallocgc(mem, et, true)
}
上述代码的主要工作就是用切片中元素大小和切片容量相乘计算出切片占用的内存空间,如果内存空间的大小发生了溢出、申请的内存大于最大可分配的内存、传入的长度小于 0 或者长度大于容量,那么就会直接报错,当然大多数的错误都会在编译期间就检查出来,mallocgc 就是用于申请内存的函数,这个函数的实现还是比较复杂,如果遇到了比较小的对象会直接初始化在 Golang 调度器里面的 P 结构中,而大于 32KB 的一些对象会在堆上初始化。
初始化后会返回指向这片内存空间的指针,在之前版本的 Go 语言中,指针会和长度与容量一起被合成一个 slice 结构返回到 makeslice 的调用方,但是从 020a18c5 这个 commit 开始,构建结构体 SliceHeader的工作就都由上层在类型检查期间完成了:
func typecheck1(n *Node, top int) (res *Node) {
switch n.Op {
// ...
case OSLICEHEADER:
switch
t := n.Type
n.Left = typecheck(n.Left, ctxExpr)
l := typecheck(n.List.First(), ctxExpr)
c := typecheck(n.List.Second(), ctxExpr)
l = defaultlit(l, types.Types[TINT])
c = defaultlit(c, types.Types[TINT])
n.List.SetFirst(l)
n.List.SetSecond(c)
// ...
}
}
OSLICEHEADER 操作会创建一个如下所示的结构体,其中包含数组指针、切片长度和容量,它是切片在运行时的表示:
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
正是因为大多数对切片类型的操作并不需要直接操作原 slice 结构体,所以 SliceHeader 的引入能够减少切片初始化时的开销,这个改动能够减少 0.2% 的 Go 语言包大小并且能够减少 92 个 panicindex 的调用。
访问
对切片常见的操作就是获取它的长度或者容量,这两个不同的函数 len 和 cap 其实被 Go 语言的编译器看成是两种特殊的操作 OLEN 和 OCAP,它们会在 SSA 生成阶段 被转换成 OpSliceLen 和 OpSliceCap 操作:
func (s *state) expr(n *Node) *ssa.Value {
switch n.Op {
case OLEN, OCAP:
switch {
case n.Left.Type.IsSlice():
op := ssa.OpSliceLen
if n.Op == OCAP {
op = ssa.OpSliceCap
}
return s.newValue1(op, types.Types[TINT], s.expr(n.Left))
// ...
}
// ...
}
}
除了获取切片的长度和容量之外,访问切片中元素使用的 OINDEX 操作也都在 SSA 中间代码生成期间就转换成对地址的获取操作:
func (s *state) expr(n *Node) *ssa.Value {
switch n.Op {
case OINDEX:
switch {
case n.Left.Type.IsSlice():
p := s.addr(n, false)
return s.load(n.Left.Type.Elem(), p)
// ...
}
// ...
}
}
切片的操作基本都是在编译期间完成的,除了访问切片的长度、容量或者其中的元素之外,使用 range 遍历切片时也是在编译期间被转换成了形式更简单的代码,我们会在后面的章节中介绍 range 关键字的实现原理。
追加
向切片中追加元素应该是最常见的切片操作,在 Go 语言中我们会使用 append 关键字向切片中追加元素,追加元素会根据是否 inplace 在中间代码生成阶段转换成以下的两种不同流程,如果 append 之后的切片不需要赋值回原有的变量,也就是如 append(slice, 1, 2, 3) 所示的表达式会被转换成如下的过程:
ptr, len, cap := slice
newlen := len + 3
if newlen > cap {
ptr, len, cap = growslice(slice, newlen)
newlen = len + 3
}
*(ptr+len) = 1
*(ptr+len+1) = 2
*(ptr+len+2) = 3
return makeslice(ptr, newlen, cap)
我们会先对切片结构体进行解构获取它的数组指针、大小和容量,如果新的切片大小大于容量,那么就会使用 growslice 对切片进行扩容并将新的元素依次加入切片并创建新的切片,但是 slice = apennd(slice, 1, 2, 3) 这种 inplace 的表达式就只会改变原来的 slice 变量:
a := &slice
ptr, len, cap := slice
newlen := len + 3
if uint(newlen) > uint(cap) {
newptr, len, newcap = growslice(slice, newlen)
vardef(a)
*a.cap = newcap
*a.ptr = newptr
}
newlen = len + 3
*a.len = newlen
*(ptr+len) = 1
*(ptr+len+1) = 2
*(ptr+len+2) = 3
上述两段代码的逻辑其实差不多,最大的区别在于最后的结果是不是赋值会原有的变量,不过从 inplace 的代码可以看出 Go 语言对类似的过程进行了优化,所以我们并不需要担心 append 会在数组容量足够时导致发生切片的复制。
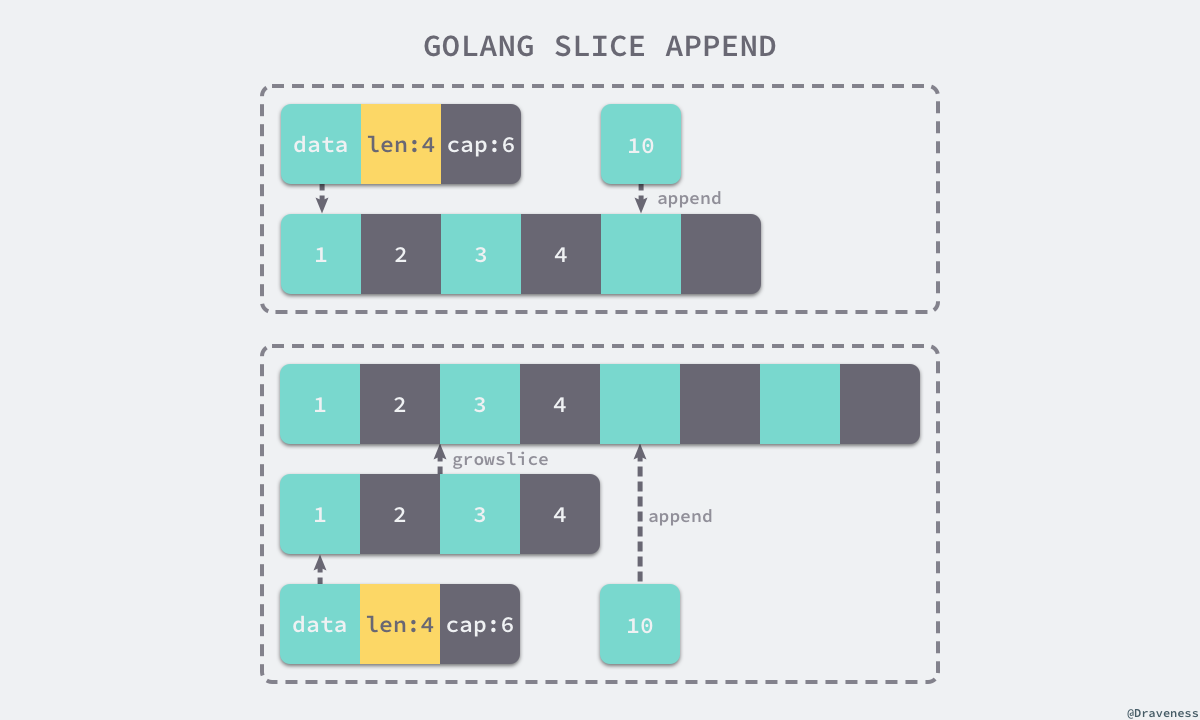
到这里我们已经了解了在切片容量足够时如何向切片中追加元素,但是如果切片的容量不足时就会调用 growslice 为切片扩容:
func growslice(et *_type, old slice, cap int) slice {
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
if old.len < 1024 {
newcap = doublecap
} else {
for 0 < newcap && newcap < cap {
newcap += newcap / 4
}
if newcap <= 0 {
newcap = cap
}
}
}
扩容其实就是需要为切片分配一块新的内存空间,分配内存空间之前需要先确定新的切片容量,Go 语言根据切片的当前容量选择不同的策略进行扩容:
- 如果期望容量大于当前容量的两倍就会使用期望容量;
- 如果当前切片容量小于 1024 就会将容量翻倍;
- 如果当前切片容量大于 1024 就会每次增加 25% 的容量,直到新容量大于期望容量;
确定了切片的容量之后,我们就可以开始计算切片中新数组的内存占用了,计算的方法就是将目标容量和元素大小相乘:
var overflow bool
var lenmem, newlenmem, capmem uintptr
switch {
// ...
default:
lenmem = uintptr(old.len) * et.size
newlenmem = uintptr(cap) * et.size
capmem, overflow = math.MulUintptr(et.size, uintptr(newcap))
capmem = roundupsize(capmem)
newcap = int(capmem / et.size)
}
var p unsafe.Pointer
if et.kind&kindNoPointers != 0 {
p = mallocgc(capmem, nil, false)
memclrNoHeapPointers(add(p, newlenmem), capmem-newlenmem)
} else {
p = mallocgc(capmem, et, true)
if writeBarrier.enabled {
bulkBarrierPreWriteSrcOnly(uintptr(p), uintptr(old.array), lenmem)
}
}
memmove(p, old.array, lenmem)
return slice{p, old.len, newcap}
}
如果当前切片中元素不是指针类型,那么就会调用 memclrNoHeapPointers 函数将超出当前长度的位置置空并在最后使用 memmove 将原数组内存中的内容拷贝到新申请的内存中, 不过无论是 memclrNoHeapPointers 还是 memmove 函数都使用目标机器上的汇编指令进行实现,例如 WebAssembly 使用如下的命令实现 memclrNoHeapPointers 函数:
TEXT runtime·memclrNoHeapPointers(SB), NOSPLIT, $0-16
MOVD ptr+0(FP), R0
MOVD n+8(FP), R1
loop:
Loop
Get R1
I64Eqz
If
RET
End
Get R0
I32WrapI64
I64Const $0
I64Store8 $0
Get R0
I64Const $1
I64Add
Set R0
Get R1
I64Const $1
I64Sub
Set R1
Br loop
End
UNDEF
growslice 函数最终会返回一个新的 slice 结构,其中包含了新的数组指针、大小和容量,这个返回的三元组最终会改变原有的切片,帮助 append 完成元素追加的功能。
拷贝
切片的拷贝虽然不是一个常见的操作类型,但是却是我们学习切片实现原理必须要谈及的一个问题,当我们使用 copy(a, b) 的形式对切片进行拷贝时,编译期间会被转换成 slicecopy 函数:
func slicecopy(to, fm slice, width uintptr) int {
if fm.len == 0 || to.len == 0 {
return 0
}
n := fm.len
if to.len < n {
n = to.len
}
if width == 0 {
return n
}
// ...
size := uintptr(n) * width
if size == 1 {
*(*byte)(to.array) = *(*byte)(fm.array)
} else {
memmove(to.array, fm.array, size)
}
return n
}
上述函数的实现非常直接,它将切片中的全部元素通过 memmove 或者数组指针的方式将整块内存中的内容拷贝到目标的内存区域:
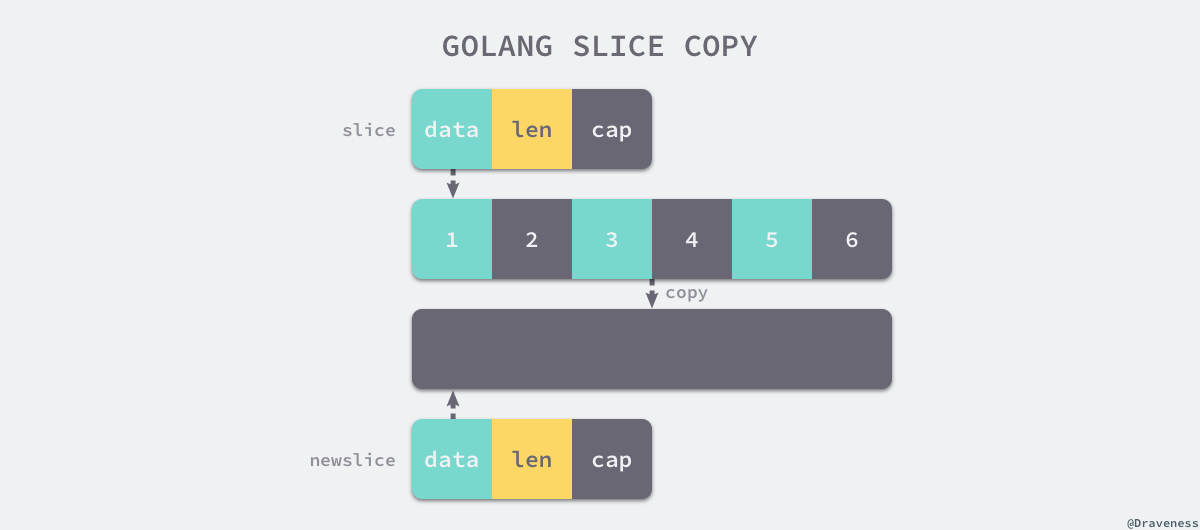
相比于依次对元素进行拷贝,这种方式能够提供更好的性能,但是需要注意的是,哪怕使用 memmove 对内存成块进行拷贝,但是这个操作还是会占用非常多的资源,在大切片上执行拷贝操作时一定要注意性能影响。
总结
数组和切片是 Go 语言中重要的数据结构,所以了解它们的实现能够帮助我们更好地理解这门语言,通过对它们实现的分析,我们知道了数组和切片的实现同时依赖编译器和运行时两部分。
数组的大多数操作在 编译期间 都会转换成对内存的直接读写;而切片的很多功能就都是在运行时实现的了,无论是初始化切片,还是对切片进行追加或扩容都需要运行时的支持,需要注意的是在遇到大切片扩容或者复制时可能会发生大规模的内存拷贝,一定要在使用时减少这种情况的发生避免对程序的性能造成影响。
转载自:
Go语言数组和切片的原理的更多相关文章
- GO语言数组和切片实例详解
本文实例讲述了GO语言数组和切片的用法.分享给大家供大家参考.具体分析如下: 一.数组 与其他大多数语言类似,Go语言的数组也是一个元素类型相同的定长的序列. (1)数组的创建. 数组有3种创建方式: ...
- Go语言--数组、切片、
3.1 数组--固定大小的连续空间 3.1.1 声明数组 写法 var 数组变量名 [元素数量]T 说明: 变量名就是使用时的变量 元素的数量可以是表达式,最后必须为整型数值 T 可是是任意基本类型, ...
- 第四章 go语言 数组、切片和映射
文章由作者马志国在博客园的原创,若转载请于明显处标记出处:http://www.cnblogs.com/mazg/ 数组是由同构的元素组成.结构体是由异构的元素组成.数据和结构体都是有固定内存大小的数 ...
- go语言数组与切片比较
一.数组 与其他大多数语言类似,Go语言的数组也是一个元素类型相同的定长的序列. (1)数组的创建. 数组有3种创建方式:[length]Type .[N]Type{value1, value2, . ...
- GO语言数组,切片,MAP总结
数组 数组是具有相同唯一类型的一组已编号且长度固定的数据项序列,这种类型可以是任意的原始类型例如整形.字符串或者自定义类型. 数组的长度必须是常量,并且长度是数组类型的一部分.一旦定义,长度不能变.数 ...
- GO语言总结(3)——数组和切片
上篇博文简单介绍了一下Go语言的基本类型——GO语言总结(2)——基本类型,本篇博文开始介绍Go语言的数组和切片. 一.数组 与其他大多数语言类似,Go语言的数组也是一个元素类型相同的定长的序列. ( ...
- go语言之行--数组、切片、map
一.内置函数 append :追加元素到slice里,返回修改后的slice close :关闭channel delete :从map中删除key对应的value panic : 用于异常处理,停 ...
- 《Go语言实战》笔记之第四章 ----数组、切片、映射
原文地址: http://www.niu12.com/article/11 ####数组 数组是一个长度固定的数据类型,用于存储一段具有相同的类型的元素的连续块. 数组存储的类型可以是内置类型,如整型 ...
- Go语言入门——数组、切片和映射
按照以往开一些专题的风格,第一篇一般都是“从HelloWorld开始” 但是对于Go,思来想去,感觉真的从“HelloWorld”说起,压根撑不住一篇的篇幅,因为Go的HelloWorld太简单了. ...
随机推荐
- 怎样解决if __name__ == "__main__":下面的代码没有执行的问题
很多初学者可能在用pycharm运行代码时会出现if __name__ == "__main__":下面的代码没有执行的问题,出现这类问题的原因是unittest运行姿势造成的,如 ...
- 想明白为什么C->D
C公司为什么不行? 钱不够 第一个原因是在新世界,C能够给我的钱是远远低于市场价的.如果按照现公司的行情,也就一个社招人员的白菜价. 领导不行 C公司的领导,从面相上看就无法让我信服.领导力中下,忽悠 ...
- Android OS 源码 引入和编译 jar / so库
Android -- 源码平台下JAR包的引入与编译https://blog.csdn.net/csdn_of_coder/article/details/64538227 BUILD_JAVA_LI ...
- WebDriver Selenium eclipse环境搭建
jdk环境 首先就是下载安装包,然后安装 然后设置环境变量,主要就是Path和CLASSPATH 由于我path已经有一个java值了,所以刚开始一直都失败 全部弄好,用cmd,java -versi ...
- pycharm中range的应用
v = range(100) for item in v: print (item) #输出结果是0 1 2 3 ......99 这是在python3中实现的,python2中不一样 下面是一个从大 ...
- SQL Server Agent Job 中用Powershell将备份文件拷贝到AWS S3
SQL Server 数据库备份后,如何再复制一份到AWS S3 上,步骤和需要注意的地方如下: 1. 首先在SQL Server 中创建一个Credential 2. 授权这个Credential ...
- vue 调用摄像头拍照以及获取相片本地路径(实测有效)
在学习这个的时候有一点前提:这是针对手机功能的,所以最重要的是要用手机进行实时调试 包含图片的增加和删除功能 <template> <div> <!--照片区域--> ...
- B站资源索引
自从搭建了B站的监控之后,就收集了一堆up主,下面分类整理一下,排名不分先后,内容会持续更新……2019-4-10 19:04:08 一.酷玩&装机&开箱 1.AS极客 2.Virtu ...
- 关闭或启动linux防火墙后,docker启动容器报错
# docker启动报错 # 解决办法:重建docker0网络恢复 #按照进程名杀死docker进程 [root@localhost mysqlconf]# pkill docker #清空防 ...
- firefox添加post插件
附加组件 - > 插件 -> 搜索RESTClient