[Python数据挖掘]第5章、挖掘建模(下)
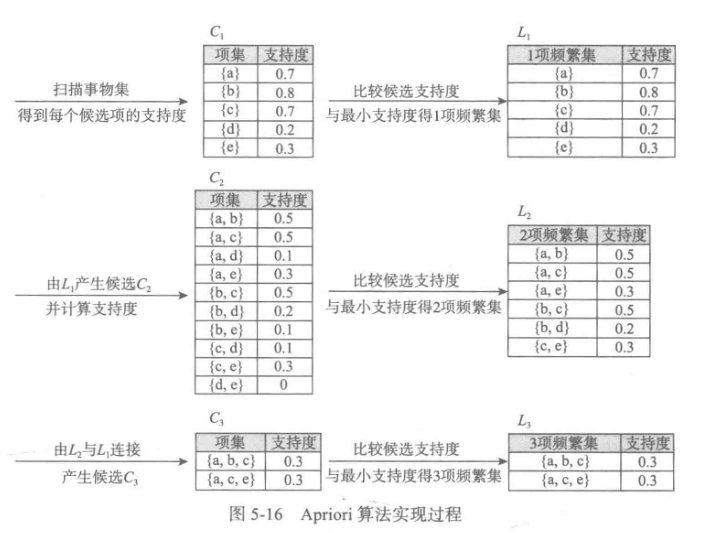
四、关联规则

Apriori算法代码(被调函数部分没怎么看懂)
from __future__ import print_function
import pandas as pd #自定义连接函数,用于实现L_{k-1}到C_k的连接
def connect_string(x, ms):
x = list(map(lambda i:sorted(i.split(ms)), x))
l = len(x[0])
r = []
for i in range(len(x)):
for j in range(i,len(x)):
if x[i][:l-1] == x[j][:l-1] and x[i][l-1] != x[j][l-1]:
r.append(x[i][:l-1]+sorted([x[j][l-1],x[i][l-1]]))
return r #寻找关联规则的函数
def find_rule(d, support, confidence, ms = u'--'):
result = pd.DataFrame(index=['support', 'confidence']) #定义输出结果 support_series = 1.0*d.sum()/len(d) #支持度序列
column = list(support_series[support_series > support].index) #初步根据支持度筛选
k = 0 while len(column) > 1:
k = k+1
print(u'\n正在进行第%s次搜索...' %k)
column = connect_string(column, ms)
print(u'数目:%s...' %len(column))
sf = lambda i: d[i].prod(axis=1, numeric_only = True) #新一批支持度的计算函数 #创建连接数据,这一步耗时、耗内存最严重。当数据集较大时,可以考虑并行运算优化。
d_2 = pd.DataFrame(list(map(sf,column)), index = [ms.join(i) for i in column]).T support_series_2 = 1.0*d_2[[ms.join(i) for i in column]].sum()/len(d) #计算连接后的支持度
column = list(support_series_2[support_series_2 > support].index) #新一轮支持度筛选
support_series = support_series.append(support_series_2)
column2 = [] for i in column: #遍历可能的推理,如{A,B,C}究竟是A+B-->C还是B+C-->A还是C+A-->B?
i = i.split(ms)
for j in range(len(i)):
column2.append(i[:j]+i[j+1:]+i[j:j+1]) cofidence_series = pd.Series(index=[ms.join(i) for i in column2]) #定义置信度序列 for i in column2: #计算置信度序列
cofidence_series[ms.join(i)] = support_series[ms.join(sorted(i))]/support_series[ms.join(i[:len(i)-1])] for i in cofidence_series[cofidence_series > confidence].index: #置信度筛选
result[i] = 0.0
result[i]['confidence'] = cofidence_series[i]
result[i]['support'] = support_series[ms.join(sorted(i.split(ms)))] result = result.T.sort_values(['confidence','support'], ascending = False) #结果整理,输出
print(u'\n结果为:')
print(result)
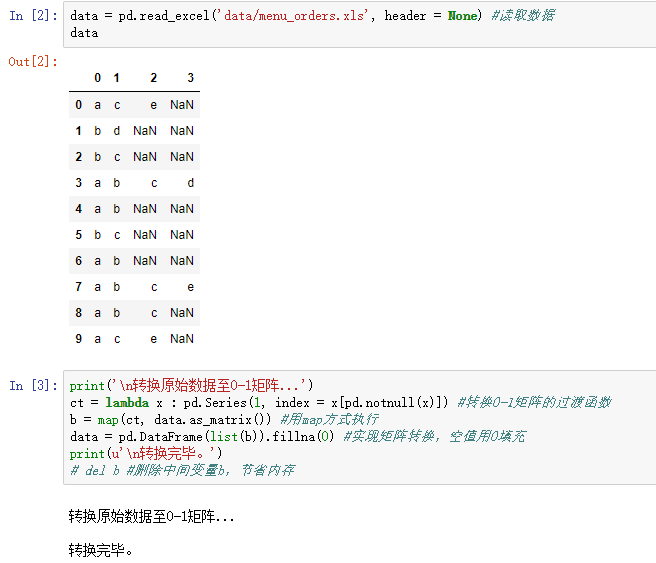
return result ## 上面部分可以封装在一个类中,然后在下面的主程序中直接调用find_rule函数 data = pd.read_excel('data/menu_orders.xls', header = None) #读取数据
print(u'\n转换原始数据至0-1矩阵...')
ct = lambda x : pd.Series(1, index = x[pd.notnull(x)]) #转换0-1矩阵的过渡函数
b = map(ct, data.as_matrix()) #用map方式执行
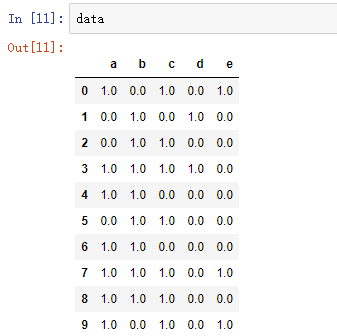
data = pd.DataFrame(list(b)).fillna(0) #实现矩阵转换,空值用0填充
print(u'\n转换完毕。')
del b #删除中间变量b,节省内存 support = 0.2 #最小支持度
confidence = 0.5 #最小置信度
ms = '---' #连接符,默认'--',用来区分不同元素,如A--B。需要保证原始表格中不含有该字符 find_rule(data, support, confidence, ms)

五、时序模式
以下代码全程懵逼
#arima时序模型
import matplotlib.pyplot as plt
import pandas as pd
%matplotlib inline
plt.rcParams['axes.unicode_minus']=False #正常显示负号 #读取数据,指定日期列为指标,Pandas自动将“日期”列识别为Datetime格式
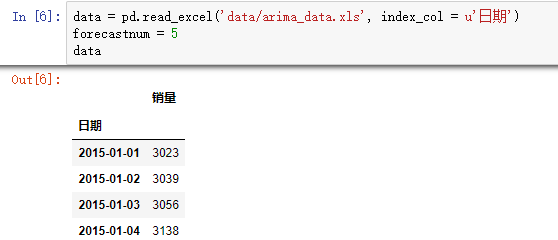
data = pd.read_excel('data/arima_data.xls', index_col = u'日期')
forecastnum = 5 #时序图
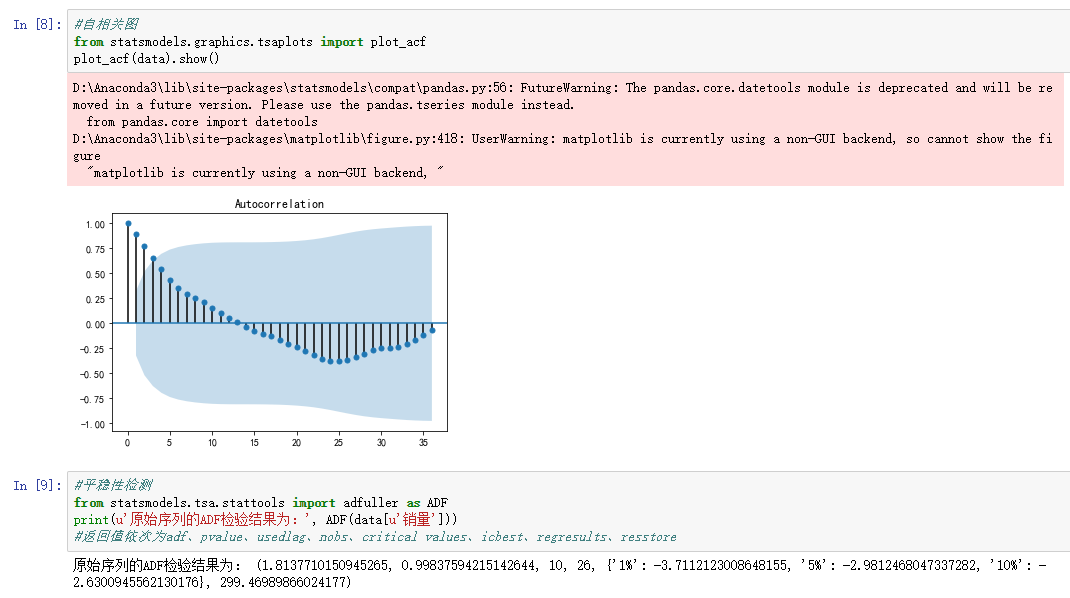
data.plot() #自相关图
from statsmodels.graphics.tsaplots import plot_acf
plot_acf(data).show() #平稳性检测
from statsmodels.tsa.stattools import adfuller as ADF
print(u'原始序列的ADF检验结果为:', ADF(data[u'销量']))
#返回值依次为adf、pvalue、usedlag、nobs、critical values、icbest、regresults、resstore #差分后的结果
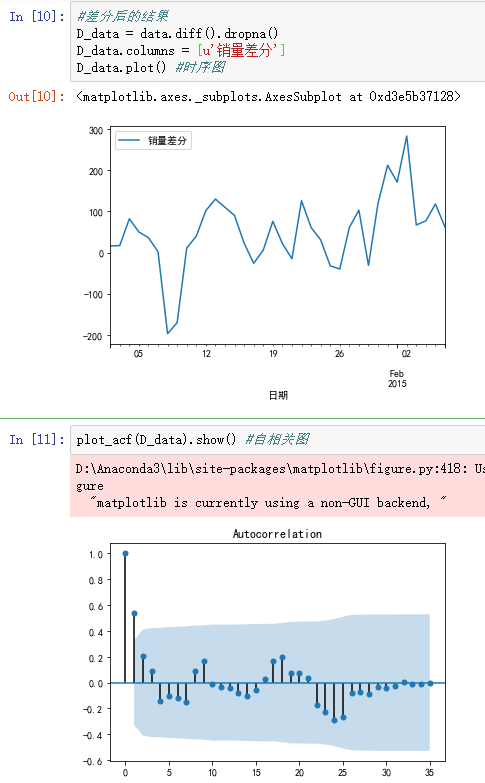
D_data = data.diff().dropna()
D_data.columns = [u'销量差分']
D_data.plot() #时序图
plot_acf(D_data).show() #自相关图
from statsmodels.graphics.tsaplots import plot_pacf
plot_pacf(D_data).show() #偏自相关图
print(u'差分序列的ADF检验结果为:', ADF(D_data[u'销量差分'])) #平稳性检测 #白噪声检验
from statsmodels.stats.diagnostic import acorr_ljungbox
print(u'差分序列的白噪声检验结果为:', acorr_ljungbox(D_data, lags=1)) #返回统计量和p值 from statsmodels.tsa.arima_model import ARIMA data[u'销量'] = data[u'销量'].astype(float)
#定阶
pmax = int(len(D_data)/10) #一般阶数不超过length/10
qmax = int(len(D_data)/10) #一般阶数不超过length/10
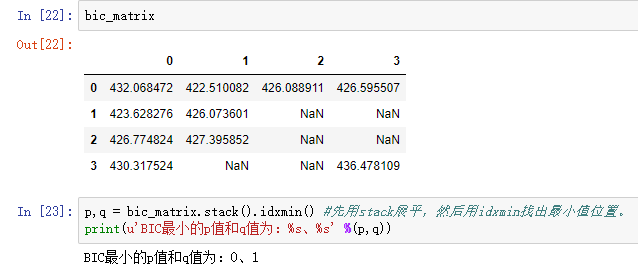
bic_matrix = [] #bic矩阵
for p in range(pmax+1):
tmp = []
for q in range(qmax+1):
try: #存在部分报错,所以用try来跳过报错。
tmp.append(ARIMA(data, (p,1,q)).fit().bic)
except:
tmp.append(None)
bic_matrix.append(tmp) bic_matrix = pd.DataFrame(bic_matrix) #从中可以找出最小值 p,q = bic_matrix.stack().idxmin() #先用stack展平,然后用idxmin找出最小值位置。
print(u'BIC最小的p值和q值为:%s、%s' %(p,q))
model = ARIMA(data, (p,1,q)).fit() #建立ARIMA(0, 1, 1)模型
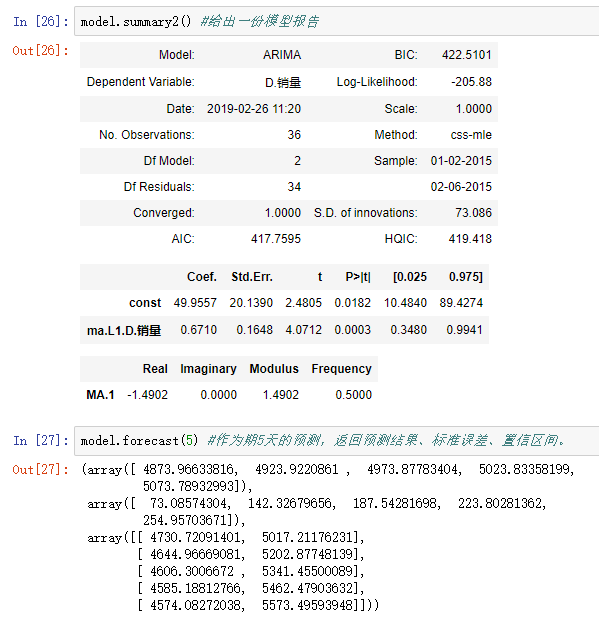
model.summary2() #给出一份模型报告
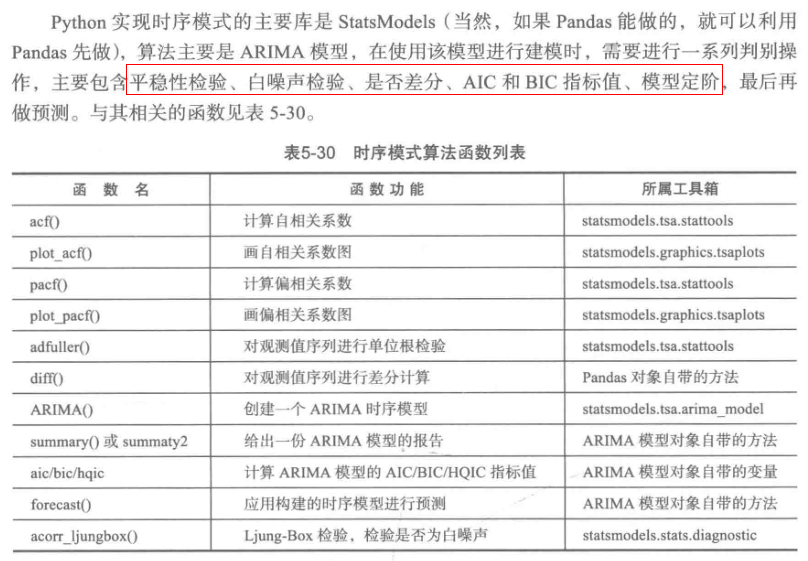
model.forecast(5) #作为期5天的预测,返回预测结果、标准误差、置信区间。


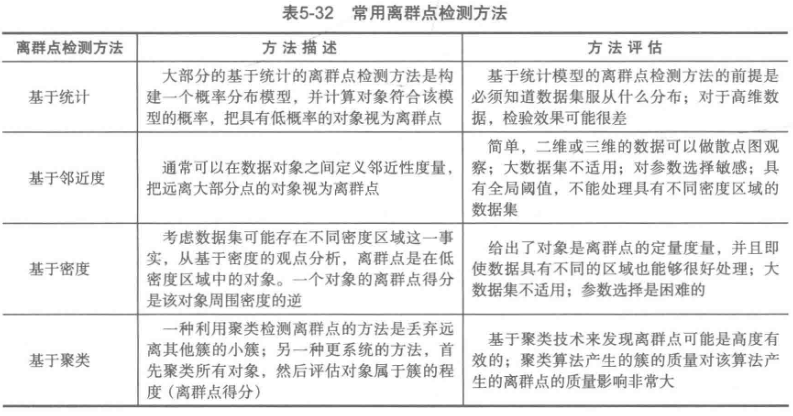
六、离群点检测
#使用K-Means算法聚类消费行为特征数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
%matplotlib inline
plt.rcParams['axes.unicode_minus']=False #正常显示负号 #参数初始化
k = 3 #聚类的类别
threshold = 2 #离散点阈值
iteration = 500 #聚类最大循环次数 data = pd.read_excel('data/consumption_data.xls', index_col = 'Id') #读取数据
data_zs = 1.0*(data - data.mean())/data.std() #数据标准化 model = KMeans(n_clusters = k, n_jobs = 4, max_iter = iteration) #分为k类,并发数4
model.fit(data_zs) #开始聚类 #标准化数据及其类别
r = pd.concat([data_zs, pd.Series(model.labels_, index = data.index)], axis = 1) #每个样本对应的类别
r.columns = list(data.columns) + [u'聚类类别'] #重命名表头 norm = []
for i in range(k): #逐一处理
norm_tmp = r[['R', 'F', 'M']][r[u'聚类类别'] == i]-model.cluster_centers_[i]
norm_tmp = norm_tmp.apply(np.linalg.norm, axis = 1) #求出绝对距离
norm.append(norm_tmp/norm_tmp.median()) #求相对距离并添加
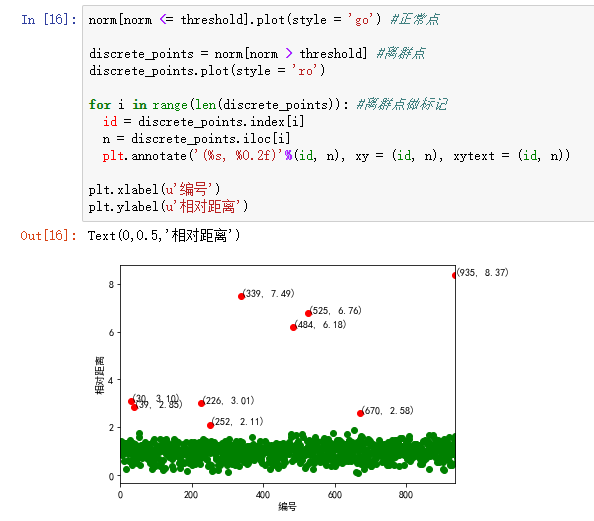
norm = pd.concat(norm) #合并 norm[norm <= threshold].plot(style = 'go') #正常点
discrete_points = norm[norm > threshold] #离群点
discrete_points.plot(style = 'ro')
for i in range(len(discrete_points)): #离群点做标记
id = discrete_points.index[i]
n = discrete_points.iloc[i]
plt.annotate('(%s, %0.2f)'%(id, n), xy = (id, n), xytext = (id, n))
plt.xlabel(u'编号')
plt.ylabel(u'相对距离')
plt.show()


七、小结

[Python数据挖掘]第5章、挖掘建模(下)的更多相关文章
- [Python数据挖掘]第5章、挖掘建模(上)
一.分类和回归 回归分析研究的范围大致如下: 1.逻辑回归 #逻辑回归 自动建模 import pandas as pd from sklearn.linear_model import Logist ...
- [Python数据挖掘]第8章、中医证型关联规则挖掘
一.背景和挖掘目标 二.分析方法与过程 1.数据获取 2.数据预处理 1.筛选有效问卷(根据表8-6的标准) 共发放1253份问卷,其中有效问卷数为930 2.属性规约 3.数据变换 ''' 聚类 ...
- [Python数据挖掘]第7章、航空公司客户价值分析
一.背景和挖掘目标 二.分析方法与过程 客户价值识别最常用的是RFM模型(最近消费时间间隔Recency,消费频率Frequency,消费金额Monetary) 1.EDA(探索性数据分析) #对数据 ...
- [Python数据挖掘]第6章、电力窃漏电用户自动识别
一.背景与挖掘目标 相关背景自查 二.分析方法与过程 1.EDA(探索性数据分析) 1.分布分析 2.周期性分析 2.数据预处理 1.数据清洗 过滤非居民用电数据,过滤节假日用电数据(节假日用电量明显 ...
- [Python数据挖掘]第4章、数据预处理
数据预处理主要包括数据清洗.数据集成.数据变换和数据规约,处理过程如图所示. 一.数据清洗 1.缺失值处理:删除.插补.不处理 ## 拉格朗日插值代码(使用缺失值前后各5个未缺失的数据建模) impo ...
- [Python数据挖掘]第2章、Python数据分析简介
<Python数据分析与挖掘实战>的数据和代码,可从“泰迪杯”竞赛网站(http://www.tipdm.org/tj/661.jhtml)下载获得 1.Python数据结构 2.Nump ...
- [Python数据挖掘]第3章、数据探索
1.缺失值处理:删除.插补.不处理 2.离群点分析:简单统计量分析.3σ原则(数据服从正态分布).箱型图(最好用) 离群点(异常值)定义为小于QL-1.5IQR或大于Qu+1.5IQR import ...
- Ubuntu系统下创建python数据挖掘虚拟环境
虚拟环境: 虚拟环境是用于创建独立的python环境,允许我们使用不同的python模块和版本,而不混淆. 让我们了解一下产品研发过程中虚拟环境的必要性,在python项目中,显然经常要使用不 ...
- ROS机器人程序设计(原书第2版)补充资料 (柒) 第七章 3D建模与仿真 urdf Gazebo V-Rep Webots Morse
ROS机器人程序设计(原书第2版)补充资料 (柒) 第七章 3D建模与仿真 urdf Gazebo V-Rep Webots Morse 书中,大部分出现hydro的地方,直接替换为indigo或ja ...
随机推荐
- 解决vue webApp使用lib-flexible和px2rem引用第三方ui库后,样式变小问题
首先,需要卸载项目中的postcss-px2rem. npm uninstall postcss-px2rem --save-dev 其次,安装postcss-px2rem-exclude npm i ...
- task CancellationTokenSource
使用CancellationTokenSource对象需要与Task对象进行配合使用,Task会对当前运行的状态进行控制(这个不用我们关心是如何控制的).而CancellationTokenSourc ...
- springboot整合微软的ad域,采用ldap的api来整合,实现用户登录验证、
流程: 1.用户调登录接口,传用户名和密码2.用户名和密码在ad验证,验证通过后,返回当前用户的相关信息.(注:ldap为java自带的api不需要maven引入其他的)3.根据返回的用户信息,实现自 ...
- 从零开始搭建vue开发环境及构建vue项目
1.安装node.js 安装完成之后,打开dos(windows+R或者直接windows键打开,输入cmd,按回车键)窗口,输入命令node -v可以查看安装的 node.js版本 node.js自 ...
- netcorec程序部署配置
IIS方式: 1:iis配置netcore发布的文件 2:iis设置运行库无托管模式 3:安装DotNetCore.1.0.4_1.1.1-WindowsHosting.exe 4:安装dotnet- ...
- Java面向对象——类,对象和方法
1.类的概念 在生活中,说到类,可以联想到类别,同类,会想到一类人,一类事物等等.而这一类人或事物都是具有相同特征或特点和行为的,我们根据不同的特征或特点和行为将他们归类或分类.同时,当我们认识一个新 ...
- C++ MFC万能的类向导
MFC的类向导 只要你掌握了类向导,你基本就已经掌握了MFC了,毕竟布局和代码都是自动生成,再加上C++基础上手还是挺快的,剩下的就是多多练习了. 转自: https://blog.csdn.net/ ...
- MongoDB3.2新特性之文档验证
官方参考: https://docs.mongodb.org/master/core/document-validation/ 文档验证是3.2的重要新特性,添加验证条件的情形无非两种,一是在创建集合 ...
- crypto 简单了解
阅读前:文章记录crypto库的简单了解,和一些简单的用法,与具体加解密算法的实现无关. 文中例子使用到了node的crypto模块 和 npm sjcl(Stanford Javascript C ...
- Ubuntu16.04彻底删除PHP7.2
一.删除php的相关包及配置 apt-get autoremove php7* 二.删除关联 sudo find /etc -name "*php*" |xargs rm -rf ...