jieba库
Note of Jieba
jieba库是python 一个重要的第三方中文分词函数库,但需要用户自行安装。
一、jieba 库简介
(1) jieba 库的分词原理是利用一个中文词库,将待分词的内容与分词词库进行比对,通过图结构和动态规划方法找到最大概率的词组;除此之外,jieba 库还提供了增加自定义中文单词的功能。
(2) jieba 库支持3种分词模式:
精确模式:将句子最精确地切开,适合文本分析。
全模式:将句子中所以可以成词的词语都扫描出来,速度非常快,但是不能消除歧义。
搜索引擎模式:在精确模式的基础上,对长分词再次切分,提高召回率,适合搜索引擎分词。
二、安装库函数
(1) 在命令行下输入指令:
pip install jieba
(2) 安装进程:

三、调用库函数
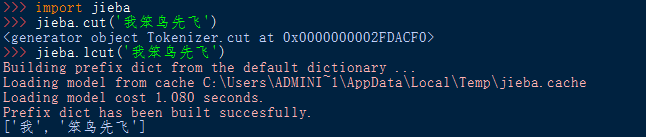
(1) 导入库函数:import <库名>
使用库中函数:<库名> . <函数名> (<函数参数>)
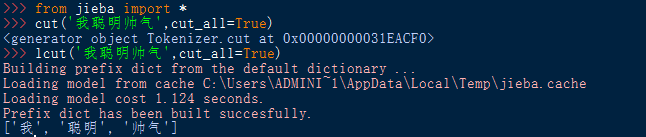
(2) 导入库函数:from <库名> import * ( *为通配符 )
使用库中函数:<函数名> (<函数参数>)
四、jieba 库函数
(1) 库函数功能
|
模式 |
函数 |
说明 |
|
精确模式 |
cut(s) |
返回一个可迭代数据类型 |
|
lcut(s) |
返回一个列表类型 (建议使用) |
|
|
全模式 |
cut(s,cut_all=True) |
输出s中所以可能的分词 |
|
lcut(s,cut_all=True) |
返回一个列表类型 (建议使用) |
|
|
搜索引擎模式 |
cut_for_search(s) |
适合搜索引擎建立索引的分词结果 |
|
lcut_for_search(s) |
返回一个列表类型 (建议使用) |
|
|
自定义新词 |
add_word(w) |
向分词词典中增加新词w |
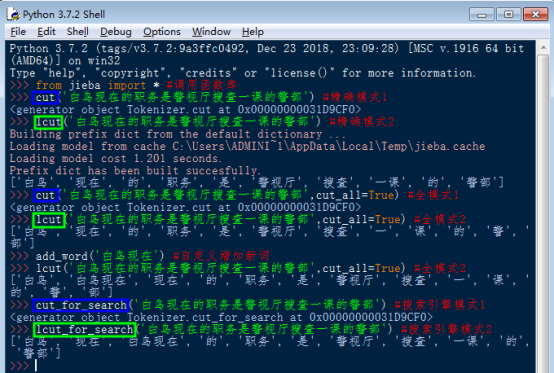
(2) 函数使用实例
五、对一篇文档进行词频统计
(1) jieba 库单枪匹马
A. 代码实现
注:代码使用的文档 >>> Detective_Novel(utf-8).zip[点击下载],也可自行找 utf-8 编码格式的txt文件。

1 # -*- coding:utf-8 -*-
2 from jieba import *
3
4 def Replace(text,old,new): #替换列表的字符串
5 for char in old:
6 text = text.replace(char,new)
7 return text
8
9 def getText(filename): #读取文件内容(utf-8 编码格式)
10 #特殊符号和部分无意义的词
11 sign = '''!~·@¥……*“”‘’\n(){}【】;:"'「,」。-、?'''
12 txt = open('{}.txt'.format(filename),encoding='utf-8').read()
13 return Replace(txt,sign," ")
14
15 def word_count(passage,N): #计算passage文件中的词频数,并将前N个输出
16 words = lcut(passage) #精确模式分词形式
17 counts = {} #创建计数器 --- 字典类型
18 for word in words: #消除同意义的词和遍历计数
19 if word == '小五' or word == '小五郎' or word == '五郎':
20 rword = '毛利'
21 elif word == '柯' or word == '南':
22 rword = '柯南'
23 elif word == '小' or word == '兰':
24 rword = '小兰'
25 elif word == '目' or word == '暮' or word == '警官':
26 rword = '暮目'
27 else:
28 rword = word
29 counts[rword] = counts.get(rword,0) + 1
30 excludes = lcut_for_search("你我事他和她在这也有什么的是就吧啊吗哦呢都了一个")
31 for word in excludes: #除去意义不大的词语
32 del(counts[word])
33 items = list(counts.items()) #转换成列表形式
34 items.sort(key = lambda x : x[1], reverse = True ) #按次数排序
35 for i in range(N): #依次输出
36 word,count = items[i]
37 print("{:<7}{:>6}".format(word,count))
38
39 if __name__ == '__main__':
40 passage = getText('Detective_Novel') #输入文件名称读入文件内容
41 word_count(passage,20) #调用函数得到词频数
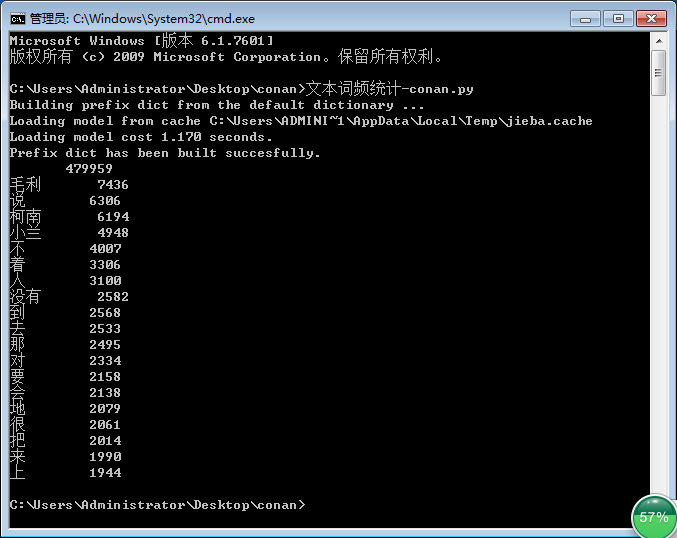
B. 执行结果
(2) jieba 库 和 wordcloud 库 强强联合 --- 词云图
A. 代码实现
1 # -*- coding:utf-8 -*-
2 from wordcloud import WordCloud
3 import matplotlib.pyplot as plt
4 import numpy as np
5 from PIL import Image
6 from jieba import *
7
8 def Replace(text,old,new): #替换列表的字符串
9 for char in old:
10 text = text.replace(char,new)
11 return text
12
13 def getText(filename): #读取文件内容(utf-8 编码格式)
14 #特殊符号和部分无意义的词
15 sign = '''!~·@¥……*“”‘’\n(){}【】;:"'「,」。-、?'''
16 txt = open('{}.txt'.format(filename),encoding='utf-8').read()
17 return Replace(txt,sign," ")
18
19 def creat_word_cloud(filename): #将filename 文件的词语按出现次数输出为词云图
20 text = getText(filename) #读取文件
21 wordlist = lcut(text) #jieba库精确模式分词
22 wl = ' '.join(wordlist) #生成新的字符串
23
24 #设置词云图
25 font = r'C:\Windows\Fonts\simfang.ttf' #设置字体路径
26 wc = WordCloud(
27 background_color = 'black', #背景颜色
28 max_words = 2000, #设置最大显示的词云数
29 font_path = font, #设置字体形式(在本机系统中)
30 height = 1200, #图片高度
31 width = 1600, #图片宽度
32 max_font_size = 100, #字体最大值
33 random_state = 100, #配色方案的种类
34 )
35 myword = wc.generate(wl) #生成词云
36 #展示词云图
37 plt.imshow(myword)
38 plt.axis('off')
39 plt.show()
40 #以原本的filename命名保存词云图
41 wc.to_file('{}.png'.format(filename))
42
43 if __name__ == '__main__':
44 creat_word_cloud('Detective_Novel') #输入文件名生成词云图
B. 执行结果

jieba库的更多相关文章
- jieba库词频统计练习
在sypder上运行jieba库的代码: import matplotlib.pyplot as pltfracs = [2,2,1,1,1]labels = 'houqin', 'jiemian', ...
- 如何运用jieba库分词
使用jieba库分词 一.什么是jieba库 1.jieba库概述 jieba是优秀的中文分词第三方库,中文文本需要通过分词获得单个词语. 2.jieba库的使用:(jieba库支持3种分词模式) 通 ...
- jieba库与好玩的词云的学习与应用实现
经过了一些学习与一些十分有意义的锻(zhe)炼(mo),我决定尝试一手新接触的python第三方库 ——jieba库! 这是一个极其优秀且强大的第三方库,可以对一个文本文件的所有内容进行识别,分词,甚 ...
- jieba库的使用与词频统计
1.词频统计 (1)词频分析是对文章中重要词汇出现的次数进行统计与分析,是文本 挖掘的重要手段.它是文献计量学中传统的和具有代表性的一种内容分析方法,基本原理是通过词出现频次多少的变化,来确定热点及其 ...
- 广师大学习笔记之文本统计(jieba库好玩的词云)
1.jieba库,介绍如下: (1) jieba 库的分词原理是利用一个中文词库,将待分词的内容与分词词库进行比对,通过图结构和动态规划方法找到最大概率的词组:除此之外,jieba 库还提供了增加自定 ...
- jieba 库的使用和好玩的词云
jieba库的使用: (1) jieba库是一款优秀的 Python 第三方中文分词库,jieba 支持三种分词模式:精确模式.全模式和搜索引擎模式,下面是三种模式的特点. 精确模式:试图将语句最精 ...
- 用jieba库统计文本词频及云词图的生成
一.安装jieba库 :\>pip install jieba #或者 pip3 install jieba 二.jieba库解析 jieba库主要提供提供分词功能,可以辅助自定义分词词典. j ...
- jieba库和好玩的词云
首先,通过pip3 install jieba安装jieba库,随后在网上下载<斗破>. 代码如下: import jieba.analyse path = '小说路径' fp = ope ...
- jieba库初级应用
1.jieba库基本介绍 (1).jieba库概述 jieba是优秀的中文分词第三方库 - 中文文本需要通过分词获得单个的词语 - jieba是优秀的中文分词第三方库,需要额外安装 - ...
随机推荐
- SQL SERVER服务器登录名、角色、数据库用户、角色、架构的关系
原创链接:https://www.cnblogs.com/junfly/articles/2798023.html SQL SERVER 基础教程中关于服务器登录名.服务器角色.数据库用户.数据库角色 ...
- centos7.2下部署 python3
安装Python3 1.环境准备 yum -y install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel read ...
- mysql并发控制之MVCC
1.MVCC(Multiversion concurrency control) :多版本并发控制,当我们并发访问数据库(读或写)时,对事物内正在处理的数据做多版本控制,用以防止写操作的阻塞影响读操作 ...
- SVN clean失败解决方法
一.问题描述 1.svn 更新或者提交时,报错:svn cleanup failed–previous operation has not finished; run cleanup if it wa ...
- java程序设计习题总结
---恢复内容开始--- main()方法的参数名可以改变:main()方法的参数个数不可以改变. 当一个程序没有main()方法是,是可以编译通过的,但是不能给运行,因为找不到一个主函数入口. 标识 ...
- 前端笔记知识点整合之JavaScript(二)关于运算符&初识条件判断语句
运算符 数学运算符的正统,number和number的数学运算,结果是number.出于面试的考虑,有一些奇奇怪怪的数学运算: 数学运算中:只有纯字符串.布尔值.null能够进行隐式转换. //隐 ...
- C++多态、虚函数、纯虚函数、抽象类、虚基类
一.C++多态 C++的多态包括静态多态和动态多态.静态多态包括函数重载和泛型编程,动态多态包括虚函数.静态多态是指在编译期间就可以确定,动态多态是指在程序运行时才能确定. 二.虚函数 1.虚函数为类 ...
- .net mvc的“从客户端中检测到有潜在危险的 Request.Form 值”问题解决
第一种解决方案 : 在控制器调用的方法上添加[ValidateInput(false)] 第二种解决方案 : 在对应的asp.net web页面上加上ValidateRequest="fal ...
- UiAutomator2.0 - 控件实现点击操作原理
目录 一.UiObject 二.UiObject2 穿梭各大技术博客网站,每天都能看到一些的新的技术.突然感觉UiAutomator 2.0相对于现在来说已经是个很久远的东西了ε=(´ο`*))).写 ...
- 04-HTTP协议和静态Web服务器
一.HTTP协议(HyperText Transfer Protocol) 超文本传输协议,超文本是超级文本的缩写,是指超越文本限制或者超链接,比如:图片.音乐.视频.超链接等等都属于超文本. ...