Hive学习之路 (十)Hive的高级操作
一、负责数据类型
1、array
现有数据如下:
- 1 huangbo guangzhou,xianggang,shenzhen a1:30,a2:20,a3:100 beijing,112233,13522334455,500
- 2 xuzheng xianggang b2:50,b3:40 tianjin,223344,13644556677,600
- 3 wangbaoqiang beijing,zhejinag c1:200 chongqinjg,334455,15622334455,20
建表语句
- use class;
- create table cdt(
- id int,
- name string,
- work_location array<string>,
- piaofang map<string,bigint>,
- address struct<location:string,zipcode:int,phone:string,value:int>)
- row format delimited
- fields terminated by "\t"
- collection items terminated by ","
- map keys terminated by ":"
- lines terminated by "\n";
导入数据
- 0: jdbc:hive2://hadoop3:10000> load data local inpath "/home/hadoop/cdt.txt" into table cdt;
查询语句
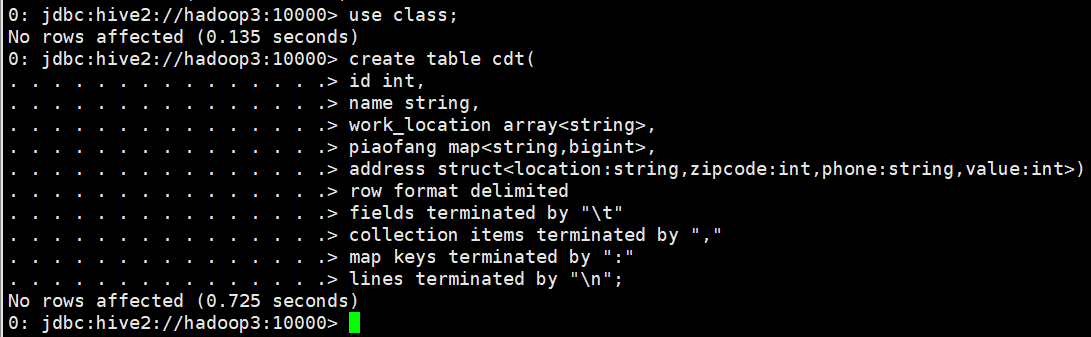
- select * from cdt;
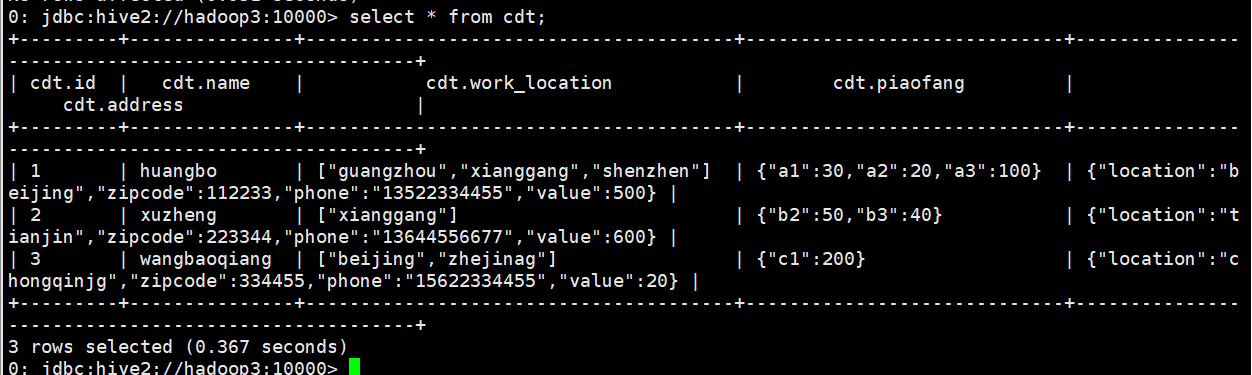
- select name from cdt;
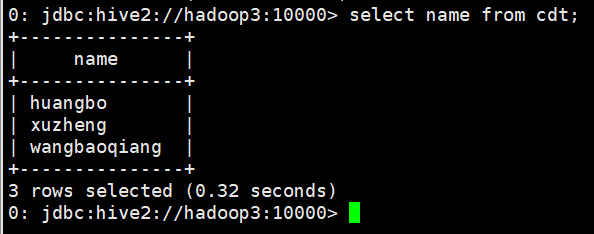
- select work_location from cdt;
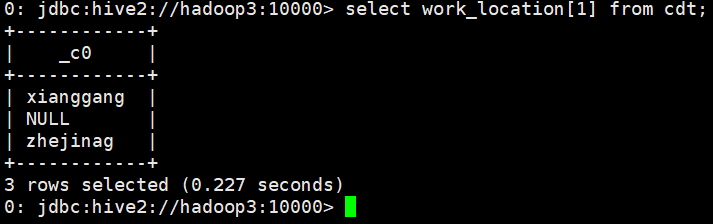
- select work_location[] from cdt;
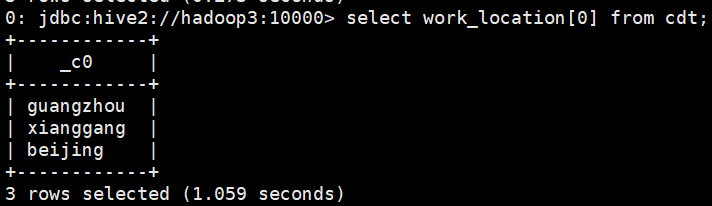
- select work_location[] from cdt;
2、map
建表语句、导入数据同1
查询语句
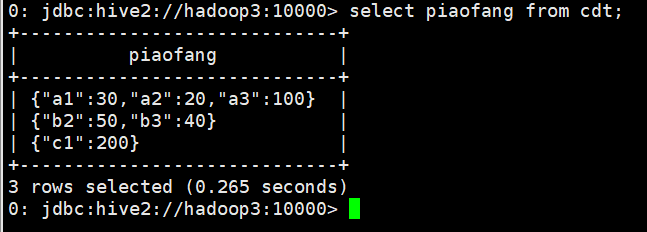
- select piaofang from cdt;
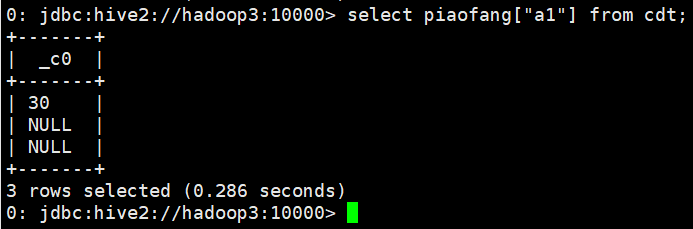
- select piaofang["a1"] from cdt;
3、struct
建表语句、导入数据同1
查询语句
- select address from cdt;
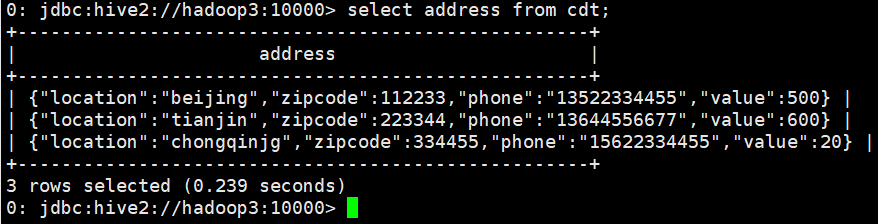
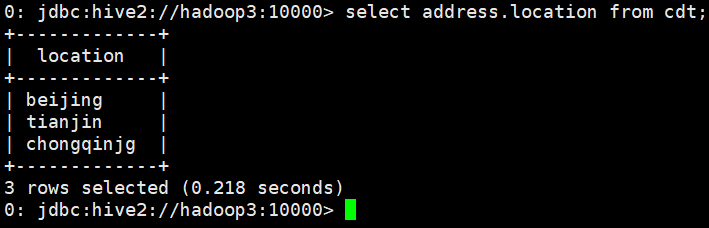
- select address.location from cdt;
4、uniontype
很少使用
参考资料:http://yugouai.iteye.com/blog/1849192
二、视图
1、Hive 的视图和关系型数据库的视图区别
和关系型数据库一样,Hive 也提供了视图的功能,不过请注意,Hive 的视图和关系型数据库的数据还是有很大的区别:
(1)只有逻辑视图,没有物化视图;
(2)视图只能查询,不能 Load/Insert/Update/Delete 数据;
(3)视图在创建时候,只是保存了一份元数据,当查询视图的时候,才开始执行视图对应的 那些子查询
2、Hive视图的创建语句
- create view view_cdt as select * from cdt;

3、Hive视图的查看语句
- show views;
- desc view_cdt;-- 查看某个具体视图的信息

4、Hive视图的使用语句
- select * from view_cdt;

5、Hive视图的删除语句
- drop view view_cdt;

三、函数
1、内置函数
具体可看http://www.cnblogs.com/qingyunzong/p/8744593.html
(1)查看内置函数
- show functions;

(2)显示函数的详细信息
- desc function substr;

(3)显示函数的扩展信息
- desc function extended substr;

2、自定义函数UDF
当 Hive 提供的内置函数无法满足业务处理需要时,此时就可以考虑使用用户自定义函数。
UDF(user-defined function)作用于单个数据行,产生一个数据行作为输出。(数学函数,字 符串函数)
UDAF(用户定义聚集函数 User- Defined Aggregation Funcation):接收多个输入数据行,并产 生一个输出数据行。(count,max)
UDTF(表格生成函数 User-Defined Table Functions):接收一行输入,输出多行(explode)
(1) 简单UDF示例
A. 导入hive需要的jar包,自定义一个java类继承UDF,重载 evaluate 方法
ToLowerCase.java
- import org.apache.hadoop.hive.ql.exec.UDF;
- public class ToLowerCase extends UDF{
- // 必须是 public,并且 evaluate 方法可以重载
- public String evaluate(String field) {
- String result = field.toLowerCase();
- return result;
- }
- }
B. 打成 jar 包上传到服务器
C. 将 jar 包添加到 hive 的 classpath
- add JAR /home/hadoop/udf.jar;

D. 创建临时函数与开发好的 class 关联起来
- 0: jdbc:hive2://hadoop3:10000> create temporary function tolowercase as 'com.study.hive.udf.ToLowerCase';

E. 至此,便可以在 hql 在使用自定义的函数
- 0: jdbc:hive2://hadoop3:10000> select tolowercase('HELLO');

(2) JSON数据解析UDF开发
现有原始 json 数据(rating.json)如下
{"movie":"1193","rate":"5","timeStamp":"978300760","uid":"1"}
{"movie":"661","rate":"3","timeStamp":"978302109","uid":"1"}
{"movie":"914","rate":"3","timeStamp":"978301968","uid":"1"}
{"movie":"3408","rate":"4","timeStamp":"978300275","uid":"1"}
{"movie":"2355","rate":"5","timeStamp":"978824291","uid":"1"}
{"movie":"1197","rate":"3","timeStamp":"978302268","uid":"1"}
{"movie":"1287","rate":"5","timeStamp":"978302039","uid":"1"}
{"movie":"2804","rate":"5","timeStamp":"978300719","uid":"1"}
{"movie":"594","rate":"4","timeStamp":"978302268","uid":"1"}
现在需要将数据导入到 hive 仓库中,并且最终要得到这么一个结果:

该怎么做、???(提示:可用内置 get_json_object 或者自定义函数完成)
A. get_json_object(string json_string, string path)
返回值: string
说明:解析json的字符串json_string,返回path指定的内容。如果输入的json字符串无效,那么返回NULL。 这个函数每次只能返回一个数据项。
- 0: jdbc:hive2://hadoop3:10000> select get_json_object('{"movie":"594","rate":"4","timeStamp":"978302268","uid":"1"}','$.movie');

创建json表并将数据导入进去
- 0: jdbc:hive2://hadoop3:10000> create table json(data string);
- No rows affected (0.983 seconds)
- 0: jdbc:hive2://hadoop3:10000> load data local inpath '/home/hadoop/json.txt' into table json;
- No rows affected (1.046 seconds)
- 0: jdbc:hive2://hadoop3:10000>

- 0: jdbc:hive2://hadoop3:10000> select
- . . . . . . . . . . . . . . .> get_json_object(data,'$.movie') as movie
- . . . . . . . . . . . . . . .> from json;

B. json_tuple(jsonStr, k1, k2, ...)
参数为一组键k1,k2……和JSON字符串,返回值的元组。该方法比 get_json_object 高效,因为可以在一次调用中输入多个键
- 0: jdbc:hive2://hadoop3:10000> select
- . . . . . . . . . . . . . . .> b.b_movie,
- . . . . . . . . . . . . . . .> b.b_rate,
- . . . . . . . . . . . . . . .> b.b_timeStamp,
- . . . . . . . . . . . . . . .> b.b_uid
- . . . . . . . . . . . . . . .> from json a
- . . . . . . . . . . . . . . .> lateral view json_tuple(a.data,'movie','rate','timeStamp','uid') b as b_movie,b_rate,b_timeStamp,b_uid;

(3) Transform实现
Hive 的 TRANSFORM 关键字提供了在 SQL 中调用自写脚本的功能。适合实现 Hive 中没有的 功能又不想写 UDF 的情况
具体以一个实例讲解。
Json 数据: {"movie":"1193","rate":"5","timeStamp":"978300760","uid":"1"}
需求:把 timestamp 的值转换成日期编号
1、先加载 rating.json 文件到 hive 的一个原始表 rate_json
- create table rate_json(line string) row format delimited;
- load data local inpath '/home/hadoop/rating.json' into table rate_json;
2、创建 rate 这张表用来存储解析 json 出来的字段:
- create table rate(movie int, rate int, unixtime int, userid int) row format delimited fields
- terminated by '\t';
解析 json,得到结果之后存入 rate 表:
- insert into table rate select
- get_json_object(line,'$.movie') as moive,
- get_json_object(line,'$.rate') as rate,
- get_json_object(line,'$.timeStamp') as unixtime,
- get_json_object(line,'$.uid') as userid
- from rate_json;
3、使用 transform+python 的方式去转换 unixtime 为 weekday
先编辑一个 python 脚本文件
- ########python######代码
- ## vi weekday_mapper.py
- #!/bin/python
- import sys
- import datetime
- for line in sys.stdin:
- line = line.strip()
- movie,rate,unixtime,userid = line.split('\t')
- weekday = datetime.datetime.fromtimestamp(float(unixtime)).isoweekday()
- print '\t'.join([movie, rate, str(weekday),userid])
保存文件 然后,将文件加入 hive 的 classpath:
- hive>add file /home/hadoop/weekday_mapper.py;
- hive> insert into table lastjsontable select transform(movie,rate,unixtime,userid)
- using 'python weekday_mapper.py' as(movie,rate,weekday,userid) from rate;
创建最后的用来存储调用 python 脚本解析出来的数据的表:lastjsontable
- create table lastjsontable(movie int, rate int, weekday int, userid int) row format delimited
- fields terminated by '\t';
最后查询看数据是否正确
- select distinct(weekday) from lastjsontable;
四、特殊分隔符处理
补充:hive 读取数据的机制:
1、 首先用 InputFormat<默认是:org.apache.hadoop.mapred.TextInputFormat >的一个具体实 现类读入文件数据,返回一条一条的记录(可以是行,或者是你逻辑中的“行”)
2、 然后利用 SerDe<默认:org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe>的一个具体 实现类,对上面返回的一条一条的记录进行字段切割
Hive 对文件中字段的分隔符默认情况下只支持单字节分隔符,如果数据文件中的分隔符是多 字符的,如下所示:
01||huangbo
02||xuzheng
03||wangbaoqiang
1、使用RegexSerDe正则表达式解析
创建表
- create table t_bi_reg(id string,name string)
- row format serde 'org.apache.hadoop.hive.serde2.RegexSerDe'
- with serdeproperties('input.regex'='(.*)\\|\\|(.*)','output.format.string'='%1$s %2$s')
- stored as textfile;

导入数据并查询
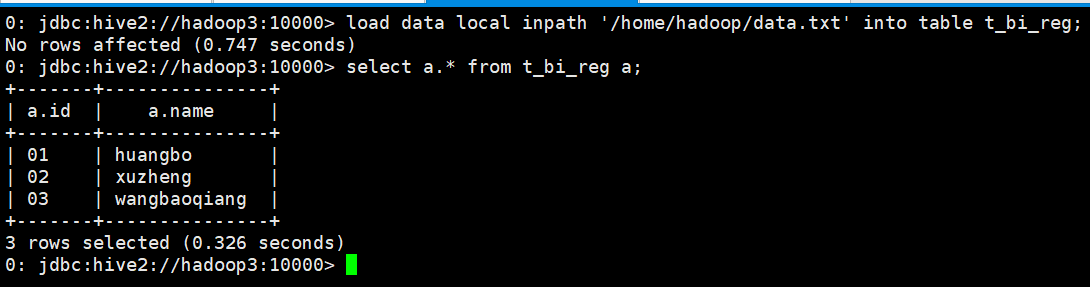
- 0: jdbc:hive2://hadoop3:10000> load data local inpath '/home/hadoop/data.txt' into table t_bi_reg;
- No rows affected (0.747 seconds)
- 0: jdbc:hive2://hadoop3:10000> select a.* from t_bi_reg a;
2、通过自定义InputFormat处理特殊分隔符
Hive学习之路 (十)Hive的高级操作的更多相关文章
- [转帖]Hive学习之路 (一)Hive初识
Hive学习之路 (一)Hive初识 https://www.cnblogs.com/qingyunzong/p/8707885.html 讨论QQ:1586558083 目录 Hive 简介 什么是 ...
- Git学习之路(6)- 分支操作
▓▓▓▓▓▓ 大致介绍 几乎所有的版本控制系统都会支持分支操作,分支可以让你在不影响开发主线的情况下,随心所欲的实现你的想法,但是在大多数的版本控制系统中,这个过程的效率是非常低的.就比如我在没有学习 ...
- Hive学习之路 (二十)Hive 执行过程实例分析
一.Hive 执行过程概述 1.概述 (1) Hive 将 HQL 转换成一组操作符(Operator),比如 GroupByOperator, JoinOperator 等 (2)操作符 Opera ...
- Hive学习之路 (十八)Hive的Shell操作
一.Hive的命令行 1.Hive支持的一些命令 Command Description quit Use quit or exit to leave the interactive shell. s ...
- hive学习笔记之十:用户自定义聚合函数(UDAF)
欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos 本篇概览 本文是<hive学习笔记>的第十 ...
- Hive学习之路 (一)Hive初识
Hive 简介 什么是Hive 1.Hive 由 Facebook 实现并开源 2.是基于 Hadoop 的一个数据仓库工具 3.可以将结构化的数据映射为一张数据库表 4.并提供 HQL(Hive S ...
- Hive学习之路 (二十一)Hive 优化策略
一.Hadoop 框架计算特性 1.数据量大不是问题,数据倾斜是个问题 2.jobs 数比较多的作业运行效率相对比较低,比如即使有几百行的表,如果多次关联多次 汇总,产生十几个 jobs,耗时很长.原 ...
- Hive学习之路 (二)Hive安装
Hive的下载 下载地址http://mirrors.hust.edu.cn/apache/ 选择合适的Hive版本进行下载,进到stable-2文件夹可以看到稳定的2.x的版本是2.3.3 Hive ...
- Hive学习之路 (十一)Hive的5个面试题
一.求单月访问次数和总访问次数 1.数据说明 数据字段说明 用户名,月份,访问次数 数据格式 A,, A,, B,, A,, B,, A,, A,, A,, B,, B,, A,, A,, B,, B ...
- Hive学习之路 (四)Hive的连接3种连接方式
一.CLI连接 进入到 bin 目录下,直接输入命令: [hadoop@hadoop3 ~]$ hive SLF4J: Class path contains multiple SLF4J bindi ...
随机推荐
- java编写带头结点的单链表
最近在牛客网上练习在线编程,希望自己坚持下去,每天都坚持下去练习,给自己一个沉淀,不多说了 我遇到了一个用java实现单链表的题目,就自己在做题中将单链表完善了一下,希望大家作为参考也熟悉一下,自己 ...
- Job控制台(elastic job lite console)
elastic job lite console: 设计理念 1.本控制台和Elastic Job并无直接关系,是通过读取Elastic Job的注册中心数据展现作业状态,或更新注册中心数据修改全局配 ...
- mac 下mongodb connect failed 连接错误
我是用brew install mongod 安装的 MongoDB shell version v3.4.2connecting to: mongodb://127.0.0.1:270172017- ...
- STL:vector<bool> 和bitset
今天某个地方要用到很多位标记于是想着可以用下bitset,不过发现居然是编译时确定空间的,不能动态分配.那就只能用vector来代替一下了,不过发现居然有vector<bool>这个特化模 ...
- python学习之老男孩python全栈第九期_day016作业
1. 请利用filter()过滤出1~100中平方根是整数的数,即结果应该是: [1, 4, 9, 16, 25, 36, 49, 64, 81, 100] import math def func( ...
- 使用vue+webpack打包时,去掉资源前缀
在build文件夹下找到webpack.prod.conf.js文件,搜索 filename: utils.assetsPath('css/[name].[contenthash].css'), 将[ ...
- php5.5过渡--变量
单纯的定义变量,如: $usernumber = $_POST['usernumber']; 会出现警告: Notice: Undefined index: usernumber in ... 规范问 ...
- js dictionary字典 遍历
var dic={A:"AA",B:"BB",C:"CC"} //不能length去for循环(length:undefined) dic[ ...
- android开启线程的误区
发现一些刚学android的人,和我当初一样,对android的线程会存在着一定误区. 在android中,开启新线程时,一些人会用以下方法: new Handler().post(r); 但是这样并 ...
- mac系统使用介绍
点击左上角苹果-->关于本机 Dock-->偏好设置 推荐按装mac系统:OS X V10.8(山狮) Finder-->应用程序(安装程序)<==>我的电脑 Safar ...