Kafka集群环境搭建(2.9.2-0.8.2.2)
Kafka是一个分布式、可分区、可复制的消息系统。Kafka将消息以topic为单位进行归纳;Kafka发布消息的程序称为producer,也叫生产者;Kafka预订topics并消费消息的程序称为consumer,也叫消费者;当Kafka以集群的方式运行时,可以由一个服务或者多个服务组成,每个服务叫做一个broker,运行过程中producer通过网络将消息发送到Kafka集群,集群向消费者提供消息。
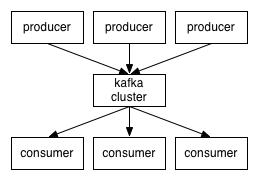
Kafka客户端和服务端基于TCP协议通信,并且提供了Java客户端API,实际上Kafka对多种语言都有支持
接下来访问Apache Kafka官网下载安装包,http://kafka.apache.org/ 网站的界面非常的简洁,下载和文档等分类一目了然
点击左边的download按钮,进入版本选择,这里选择0.8.2.2系列的基于Scala 2.9.2编写的kafka_2.9.2-0.8.2.2.tgz包,
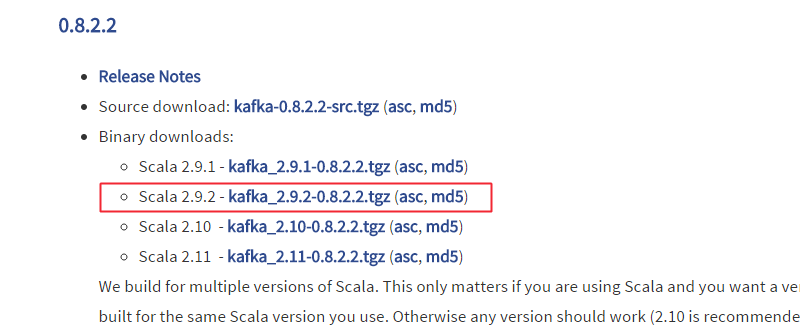
点击会进入下载页面,再次点击下载即可,下载完毕上传至服务器
和之前一样安装kafka集群之前,确保zookeeper服务已经正常运行,3台主机准备工作都以完成,并且通信正常,这些之前都详细说过,这三台主机分别为:linux1,linux2,linux3,接下来在linux1主机上执行释放:
$ tar -xvzf kafka_2.9.2-0.8.2.2.tgz
$ mv kafka_2.9.2-0.8.2.2 /usr/
$ cd /usr/kafka_2.9.2-0.8.2.2
这里相当于把kafka安装到了/usr目录下,接下来编辑配置文件,执行:
vim config/server.properties
修改broker.id=1,默认是0

这个值是集群中唯一的一个整数,每台机器各不相同,这里linux1设置为1其他机器后来再更改
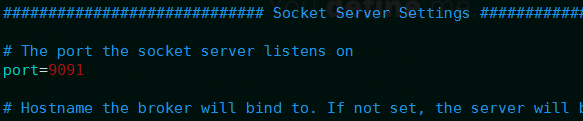
修改port=9091 默认为9092,就是为了方便后来的通信
这里设置log.dirs=/usr/kafka-logs默认为/tmp/kafka-logs,

这个目录可以根据自己习惯定义,意思就是设置Kafka日志存放的目录,这个目录后来我们需要手动建立
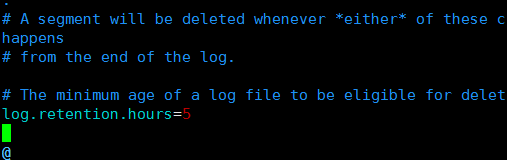
设置log.retention.hours=5 默认是168,代表清理日志的时间,根据实际情况配置即可
设置log.cleaner.enable=true,默认为false,这里一定要设置为true,否则Kafka不会自动清理日志
设置zookeeper.connect=linux1:2181,linux2:2181,linux3:2181/kafka,配置zookeeper集群的列表,这里就是这三台主机,然后指定了Kafka在zookeeper上创建的目录为/kafka,

最后一项配置,默认即可

表示连接zookeeper服务器的超时时间,以上设置都完毕,没问题保存配置并退出,然后将安装包通过网络发送至其他主机,就避免再次配置了
$ scp -r kafka_2.9.2-0.8.2.2 linux2:/usr/
$ scp -r kafka_2.9.2-0.8.2.2 linux3:/usr/
这样就发送到了linux2和linux3这两台主机,然后分别修改linux2和linux3中config/server.properties配置文件中broker.id分别为2和3,保存
然后集群中三台主机都执行:
mkdir /usr/kafka-logs
这样就创建了日志存放目录,到这里就算配置完毕了,
然后可以启动kafka服务,进入kafka_2.9.2-0.8.2.2目录,运行命令启动服务:
nohup bin/kafka-server-start.sh config/server.properties &
所有主机都要执行上面这条命令,到这里集群都已经启动了Kafka服务
接下来测试Kafka服务是否正常使用,在linux1上创建一个topic消息队列:
bin/kafka-topics.sh --create --replication-factor --partitions --topic dt_test --zookeeper linux1:,linux2:,linux3:/kafka
这里指定了2个副本,2个分区,topic名为dt_test,并且指定zookeeper分布,运行完这个稍等一下,如果卡住再次按回车即可回到命令行界面
然后在linux1上创建一个消费者consumer:
bin/kafka-console-consumer.sh --zookeeper linux1:,linux2:,linux3:/kafka --topic dt_test
这里用--topic指定了刚才刚刚创建的消息队列,现在命令行进入等待,等待生产者生产
现在在linux2上面创建一个生产者producer:
bin/kafka-console-producer.sh --broker-list linux2:,linux3: --topic dt_test
这里--broker-list指定建立生产者服务的节点,可以是本机也可以是指定多台机器,这里指定了linux2和linux3,--topic同样指定消息作业名,需要注意的是端口号这是是9091必须和前面配置文件中的设置一致,否则无法通信,我们前面把端口号改成9091这里必须是9091,如果端口号默认,那么这里一定是9092才可以;命令执行后同样会等待用户输入,我们输入Hello Kafka!

回车之后查看linux1的等待窗口:

可以看到这里将之前的输入消费输出了,这说明Kafka服务运行正常
以上就是Kafka集群搭建和测试的最基本的内容,另外运行bin/kafka-server-stop.sh脚本可以停止Kafka服务,重启Kafka时先停止再启动即可
Kafka集群环境搭建(2.9.2-0.8.2.2)的更多相关文章
- kafka 集群环境搭建 java
简单记录下kafka集群环境搭建过程, 用来做备忘录 安装 第一步: 点击官网下载地址 http://kafka.apache.org/downloads.html 下载最新安装包 第二步: 解压 t ...
- 数据源管理 | Kafka集群环境搭建,消息存储机制详解
本文源码:GitHub·点这里 || GitEE·点这里 一.Kafka集群环境 1.环境版本 版本:kafka2.11,zookeeper3.4 注意:这里zookeeper3.4也是基于集群模式部 ...
- 大数据 -- zookeeper和kafka集群环境搭建
一 运行环境 从阿里云申请三台云服务器,这里我使用了两个不同的阿里云账号去申请云服务器.我们配置三台主机名分别为zy1,zy2,zy3. 我们通过阿里云可以获取主机的公网ip地址,如下: 通过secu ...
- Kafka集群环境搭建
Kafka是一个分布式.可分区.可复制的消息系统.Kafka将消息以topic为单位进行归纳:Kafka发布消息的程序称为producer,也叫生产者:Kafka预订topics并消费消息的程序称为c ...
- kafka集群环境搭建(Linux)
一.准备工作 centos6.8和jvm需要准备64位的,如果为32位,服务启动的时候报java.lang.OutOfMemoryError: Map failed 的错误. 链接:http://pa ...
- 【Kafka】Kafka集群环境搭建
目录 一.初始环境准备 二.下载安装包并上传解压 三.修改配置文件 四.启动ZooKeeper 五.启动Kafka集群 一.初始环境准备 必须安装了JDK和ZooKeeper,并保证Zookeeper ...
- Ubuntu下kafka集群环境搭建及测试
kafka介绍: Kafka[1是一种高吞吐量[2] 的分布式发布订阅消息系统,有如下特性: 通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能 ...
- 大数据 -- Hadoop集群环境搭建
首先我们来认识一下HDFS, HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.它其实是将一个大文件分成若干块保存在不同服务器的多个节点中.通过联网 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二十一)NIFI1.7.1安装
一.nifi基本配置 1. 修改各节点主机名,修改/etc/hosts文件内容. 192.168.0.120 master 192.168.0.121 slave1 192.168.0.122 sla ...
随机推荐
- iOS 11开发教程(八)定制iOS11应用程序图标
iOS 11开发教程(八)定制iOS11应用程序图标 在图1.9中可以看到应用程序的图标是网状白色图像,它是iOS模拟器上的应用程序默认的图标.这个图标是可以进行改变的.以下就来实现在iOS模拟器上将 ...
- DataTable,List,Dictonary互转,筛选及相关写法
1.创建自定义DataTable /// 创建自定义DataTable(一) 根据列名字符串数组, /// </summary> /// <param name="sLi ...
- [BZOJ1758][WC2010]重建计划(点分治+单调队列)
点分治,对于每个分治中心,考虑求出经过它的符合长度条件的链的最大权值和. 从分治中心dfs下去取出所有链,为了防止两条链属于同一个子树,我们一个子树一个子树地处理. 用s1[i]记录目前分治中心伸下去 ...
- bzoj 2300 动态维护上凸壳(不支持删除)
新技能GET. 用set保存点,然后只需要找前趋和后继就可以动态维护了. /************************************************************** ...
- ZOJ 3623 Battle Ships DP
B - Battle Ships Time Limit:2000MS Memory Limit:65536KB 64bit IO Format:%lld & %llu Subm ...
- Java_模拟comet的实现
本文没有使用任何comet服务器, 只是利用tomcat模拟实现了一下comet, 不是真正的comet哦,因为不会有这样的应用场景, 只是模拟实现, 仅供参考. 一. 需求. 实现将服务端的时间推送 ...
- 华为S5300系列交换机V200R001SPH027升级补丁
S5300SI-V200R001SPH027.pat 附件: 链接:https://pan.baidu.com/s/1ulE0j5Rp4xMkAaOjNGKLMA 密码:d5ze
- HDU 2089 不要62(数位DP·记忆化搜索)
题意 中文 最基础的数位DP 这题好像也能够直接暴力来做 令dp[i][j]表示以 j 开头的 i 位数有多少个满足条件 那么非常easy有状态转移方程 dp[i][j] = sum{ dp[ ...
- Java学习笔记_22_Set接口的实现类
22.Set接口的实现类: Set接口存放的元素是无序的且不包括反复元素. 1>实现类HashSet: HashSet类依据元素的哈希码进行存放,取出时也能够依据哈希码高速找到.HashSet不 ...
- 网络编程_Python-网络模型.
http://xmdevops.blog.51cto.com/11144840/1861280