大数据系列之数据仓库Hive原理
Hive系列博文,持续更新~~~
大数据系列之数据仓库Hive原理
大数据系列之数据仓库Hive安装
大数据系列之数据仓库Hive中分区Partition如何使用
大数据系列之数据仓库Hive命令使用及JDBC连接
Hive的工作原理简单来说就是一个查询引擎
先来一张Hive的架构图:
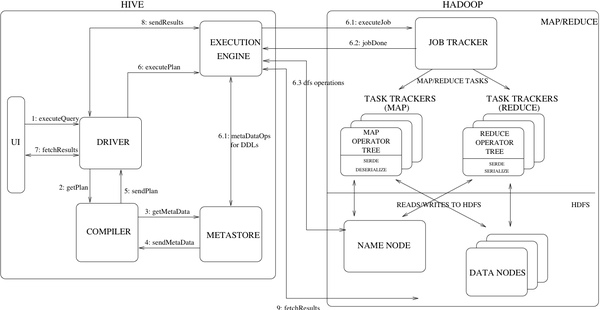
Hive的工作原理如下:
接收到一个sql,后面做的事情包括:
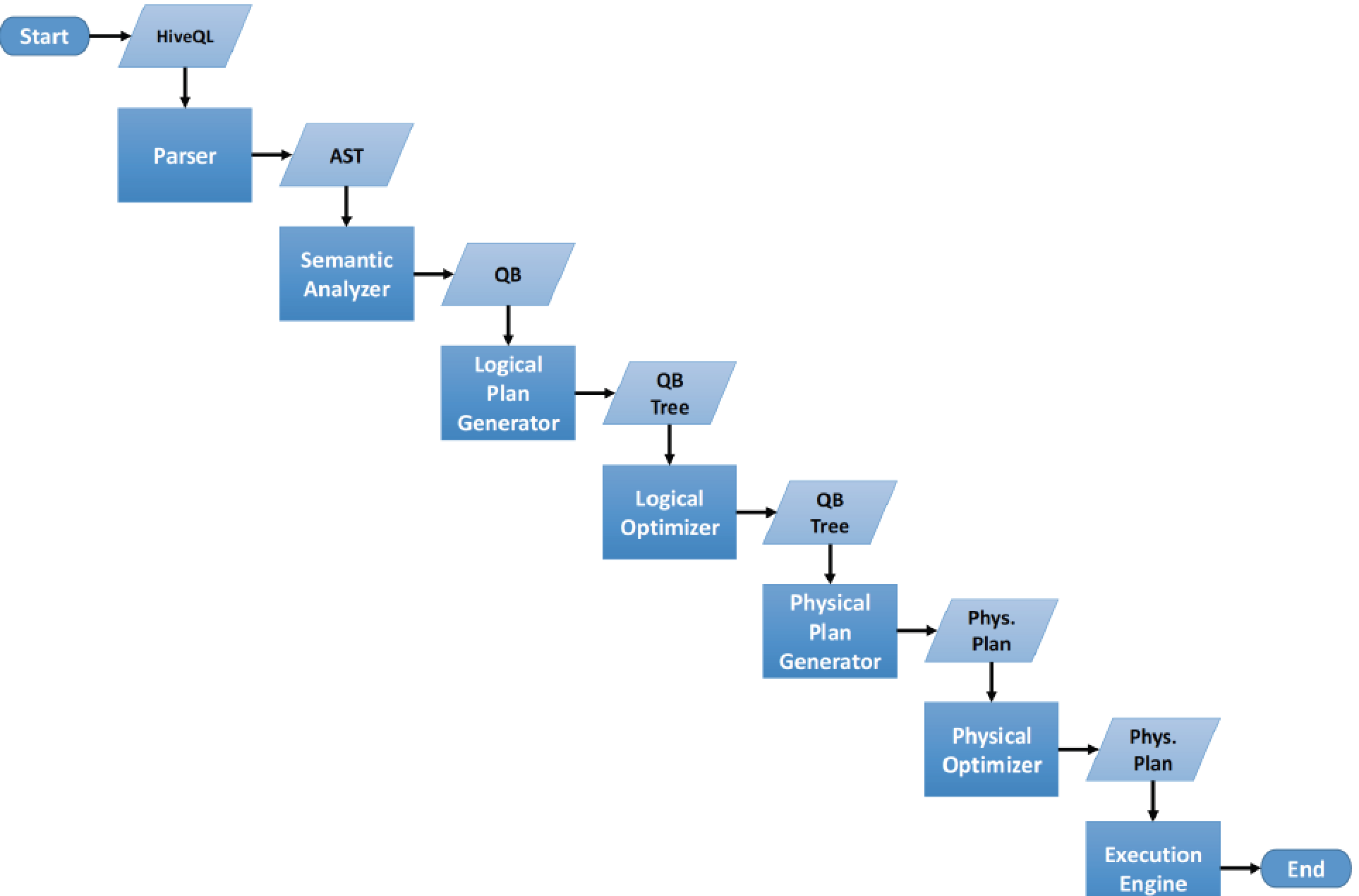
1.词法分析/语法分析
使用antlr将SQL语句解析成抽象语法树-AST
2.语义分析
从Megastore获取模式信息,验证SQL语句中队表名,列名,以及数据类型的检查和隐式转换,以及Hive提供的函数和用户自定义的函数(UDF/UAF)
3.逻辑计划生产
生成逻辑计划-算子树
4.逻辑计划优化
对算子树进行优化,包括列剪枝,分区剪枝,谓词下推等
5.物理计划生成
将逻辑计划生产包含由MapReduce任务组成的DAG的物理计划
6.物理计划执行
将DAG发送到Hadoop集群进行执行
7.将查询结果返回
流程如下图:
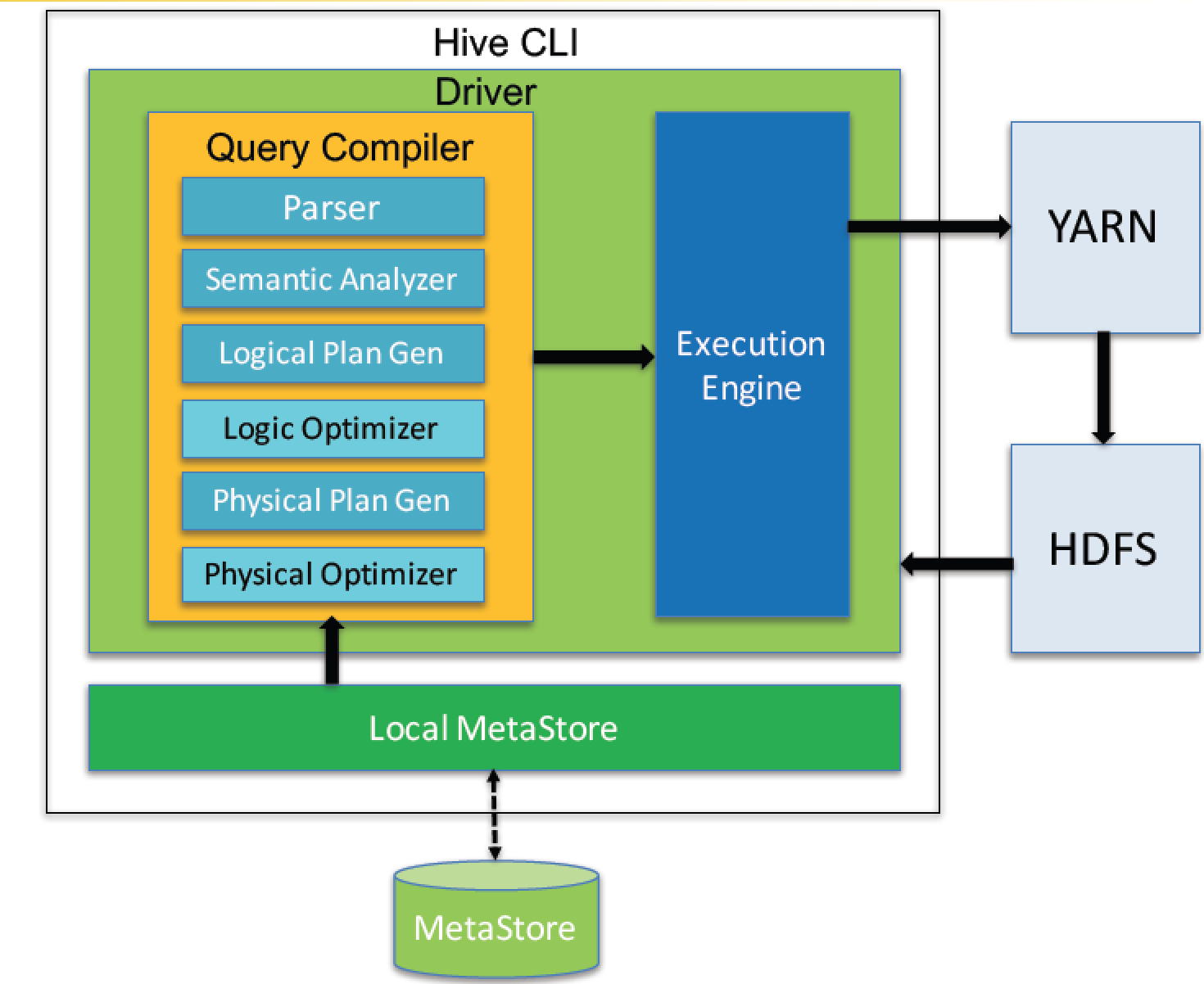
Query Compiler
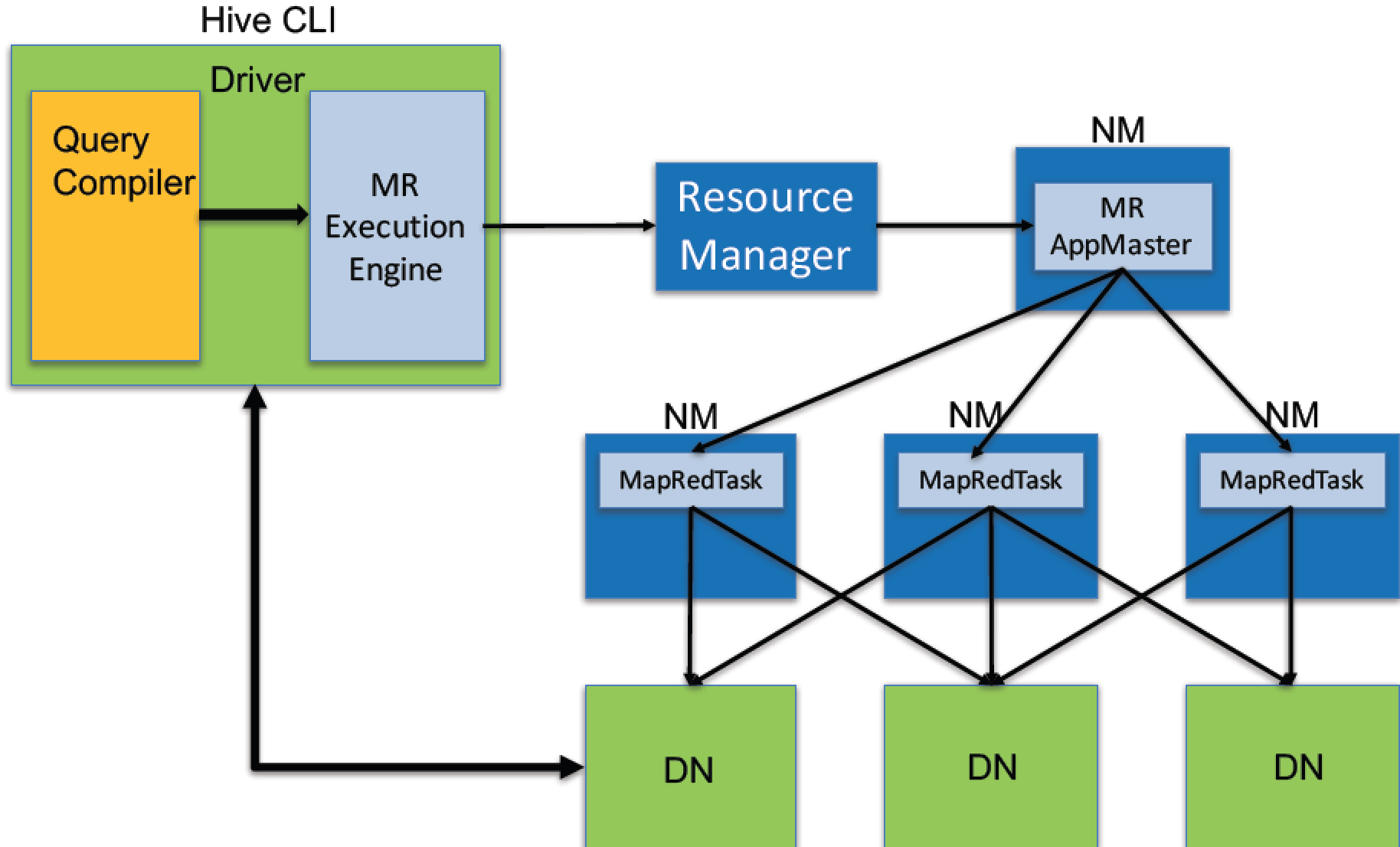
新版本的Hive也支持使用Tez或Spark作为执行引擎。

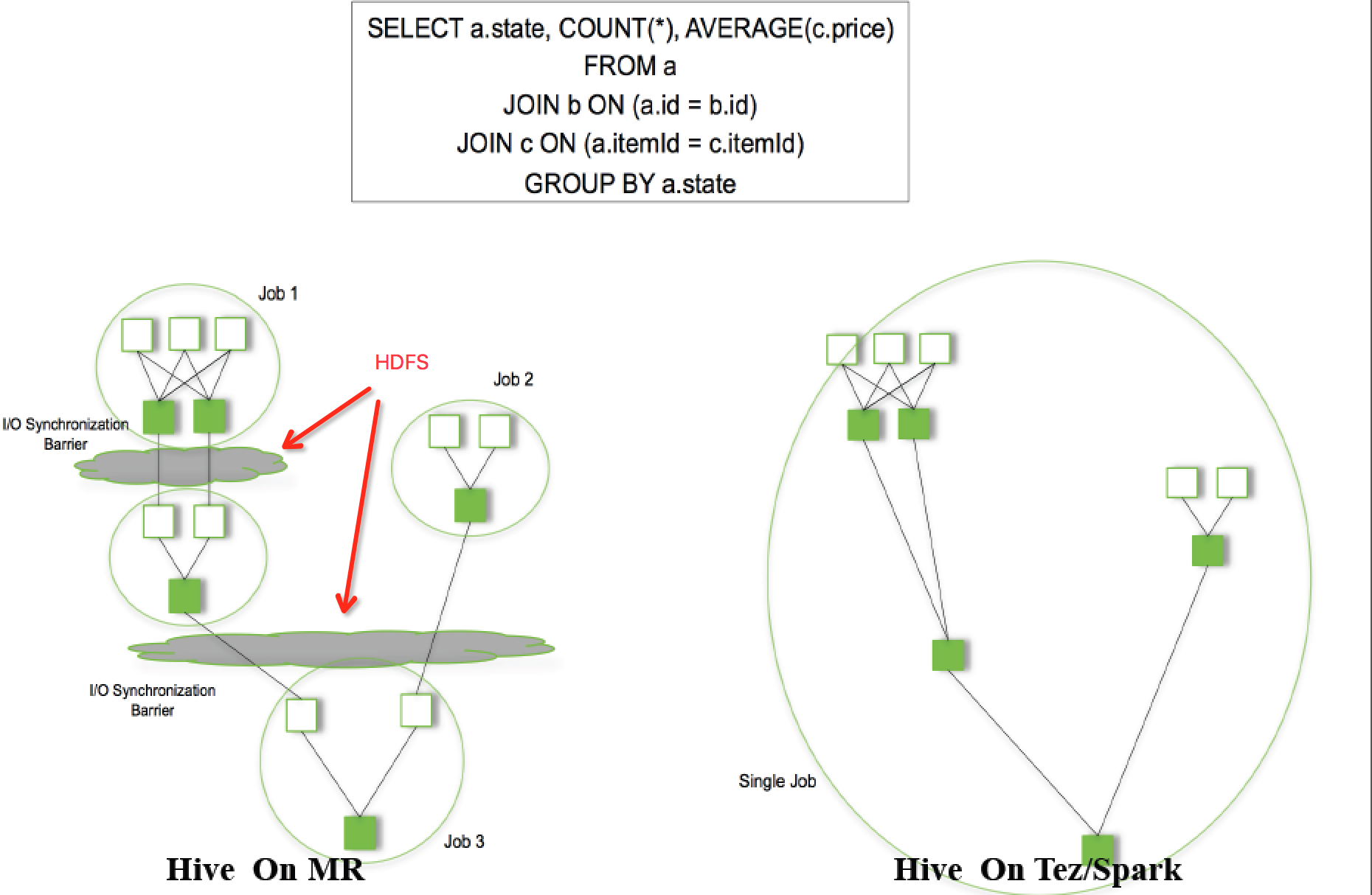
物理计划可以通过hive的Explain命令输出
例如:
: jdbc:hive2://master:10000/dbmfz> explain select count(*) from record_dimension;
+------------------------------------------------------------------------------------------------------+--+
| Explain |
+------------------------------------------------------------------------------------------------------+--+
| STAGE DEPENDENCIES: |
| Stage- is a root stage |
| Stage- depends on stages: Stage- |
| |
| STAGE PLANS: |
| Stage: Stage- |
| Map Reduce |
| Map Operator Tree: |
| TableScan |
| alias: record_dimension |
| Statistics: Num rows: Data size: Basic stats: COMPLETE Column stats: COMPLETE |
| Select Operator |
| Statistics: Num rows: Data size: Basic stats: COMPLETE Column stats: COMPLETE |
| Group By Operator |
| aggregations: count() |
| mode: hash |
| outputColumnNames: _col0 |
| Statistics: Num rows: Data size: Basic stats: COMPLETE Column stats: COMPLETE |
| Reduce Output Operator |
| sort order: |
| Statistics: Num rows: Data size: Basic stats: COMPLETE Column stats: COMPLETE |
| value expressions: _col0 (type: bigint) |
| Reduce Operator Tree: |
| Group By Operator |
| aggregations: count(VALUE._col0) |
| mode: mergepartial |
| outputColumnNames: _col0 |
| Statistics: Num rows: Data size: Basic stats: COMPLETE Column stats: COMPLETE |
| File Output Operator |
| compressed: false |
| Statistics: Num rows: Data size: Basic stats: COMPLETE Column stats: COMPLETE |
| table: |
| input format: org.apache.hadoop.mapred.SequenceFileInputFormat |
| output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat |
| serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe |
| |
| Stage: Stage- |
| Fetch Operator |
| limit: - |
| Processor Tree: |
| ListSink |
| |
+------------------------------------------------------------------------------------------------------+--+
rows selected (0.844 seconds)
除了DML,Hive也提供DDL来创建表的schema。
Hive数据存储支持HDFS的一些文件格式,比如CSV,Sequence File,Avro,RC File,ORC,Parquet。也支持访问HBase。
Hive提供一个CLI工具,类似Oracle的sqlplus,可以交互式执行sql,提供JDBC驱动作为Java的API。
转载请注明出处:
作者:mengfanzhu
原文链接:http://www.cnblogs.com/cnmenglang/p/6684615.html
大数据系列之数据仓库Hive原理的更多相关文章
- 大数据系列之数据仓库Hive安装
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- 大数据系列之数据仓库Hive命令使用及JDBC连接
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- 大数据系列之数据仓库Hive中分区Partition如何使用
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- 【大数据系列】apache hive 官方文档翻译
GettingStarted 开始 Created by Confluence Administrator, last modified by Lefty Leverenz on Jun 15, 20 ...
- 大数据系列(3)——Hadoop集群完全分布式坏境搭建
前言 上一篇我们讲解了Hadoop单节点的安装,并且已经通过VMware安装了一台CentOS 6.8的Linux系统,咱们本篇的目标就是要配置一个真正的完全分布式的Hadoop集群,闲言少叙,进入本 ...
- 大数据系列之并行计算引擎Spark介绍
相关博文:大数据系列之并行计算引擎Spark部署及应用 Spark: Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎. Spark是UC Berkeley AMP lab ( ...
- 大数据系列之分布式计算批处理引擎MapReduce实践
关于MR的工作原理不做过多叙述,本文将对MapReduce的实例WordCount(单词计数程序)做实践,从而理解MapReduce的工作机制. WordCount: 1.应用场景,在大量文件中存储了 ...
- 大数据系列(5)——Hadoop集群MYSQL的安装
前言 有一段时间没写文章了,最近事情挺多的,现在咱们回归正题,经过前面四篇文章的介绍,已经通过VMware安装了Hadoop的集群环境,相关的两款软件VSFTP和SecureCRT也已经正常安装了. ...
- 大数据系列(4)——Hadoop集群VSFTP和SecureCRT安装配置
前言 经过前三篇文章的介绍,已经通过VMware安装了Hadoop的集群环境,当然,我相信安装的过程肯定遇到或多或少的问题,这些都需要自己解决,解决的过程就是学习的过程,本篇的来介绍几个Hadoop环 ...
随机推荐
- Day22-中间件
1.中间件,在其它程序中,有的叫管道,有的叫http handler.下面是原生的中间件 2.自己也可以写中间件 2.1 写中间件,新建文件夹Middle,新建m1.py 2.2 在setting里注 ...
- 【刷题】BZOJ 3626 [LNOI2014]LCA
Description 给出一个n个节点的有根树(编号为0到n-1,根节点为0).一个点的深度定义为这个节点到根的距离+1. 设dep[i]表示点i的深度,LCA(i,j)表示i与j的最近公共祖先. ...
- MySql数据库迁移图文展示
MySql数据库的数据从一台服务器迁移到另外一台服务器需要将数据库导出,再从另外一台服务器导入.方法有很多,MySql配套的相关工具都有这个功能.phpMyAdmin就可以做,但是这个加载起来慢,推荐 ...
- Linux内核分析第八周——进程的切换和系统的一般执行过程
Linux内核分析第八周--进程的切换和系统的一般执行过程 李雪琦+原创作品转载请注明出处 + <Linux内核分析>MOOC课程http://mooc.study.163.com/cou ...
- JAVA中properties基本用法
转载 源地址不详 java中的properties文件是一种配置文件,主要用于表达配置信息,文件类型为*.properties,格式为文本文件,文件的内容是格式是"键=值"的格式, ...
- NATS_08:NATS客户端Go语言手动编写
NATS客户端 一个NATS客户端是基于NATS服务端来说既可以是一个生产数据的也可以是消费数据的.生产数据的叫生产者英文为 publishers,消费数据的叫消费者英文为 subscriber ...
- Java基础-面向接口编程-JDBC详解
Java基础-面向接口编程-JDBC详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.JDBC概念和数据库驱动程序 JDBC(Java Data Base Connectiv ...
- 防止jquery ajax 重复提交
var requestSent = false; jQuery("#buttonID").click(function() { if(!requestSent) { request ...
- 数据结构编程实验——chapter10-应用经典二叉树编程
二叉树不仅结构简单.节省内存,更重要是是这种结构有利于对数据的二分处理.之前我们提过,在二叉树的基础上能够派生很多经典的数据结构,也是下面我们将进行讨论的知识点: (1) 提高数据查找效率的二叉排 ...
- 6 Easy Steps to Learn Naive Bayes Algorithm (with code in Python)
6 Easy Steps to Learn Naive Bayes Algorithm (with code in Python) Introduction Here’s a situation yo ...