使用NNI的scikit-learn以及Tensorflow分析
一、NNI简介

NNI (Neural Network Intelligence) 是自动机器学习(AutoML)的工具包。 它通过多种调优的算法来搜索最好的神经网络结构和(或)超参,并支持单机、本地多机、云等不同的运行环境。
| Supported Frameworks | Tuning Algorithms | Training Services |
|---|---|---|
| PyTorch | TPE | Local Machine |
| TensorFlow | Random Search | Remote Servers |
| Keras | Anneal | OpenPAI |
| MXNet | Naive Evolution | Kubeflow |
| Caffe2 | SMAC | FrameworkController on K8S (AKS etc.) |
| CNTK | Batch | |
| KerasChainer | Grid Search | |
| Theano | Hyperband | |
| Network Morphism | ||
| ENAS | ||
| Metis Tuner |
使用场景
- 在本地 Trial 不同的自动机器学习算法来训练模型。
- 在分布式环境中加速自动机器学习(如:远程 GPU 工作站和云服务器)。
- 定制自动机器学习算法,或比较不同的自动机器学习算法。
- 在自己的机器学习平台中支持自动机器学习。
具体安装以及应用请参照官网。
二、使用NNI对scikit-learn进行调参
scikit-learn (sklearn) 是数据挖掘和分析的流行工具。 它支持多种机器学习模型,如线性回归,逻辑回归,决策树,支持向量机等。 提高 scikit-learn 的效率是非常有价值的课题。
NNI 支持多种调优算法,可以为 scikit-learn 搜索最佳的模型和超参,并支持本机、远程服务器组、云等各种环境。
- 样例概述
此样例使用了数字数据集,由 1797 张 8x8 的图片组成,每张图片都是一个手写数字。目标是将这些图片分到 10 个类别中。在此样例中,使用了 SVC 作为模型,并选择了一些参数,包括 "C", "keral", "degree", "gamma" 和 "coef0"。 关于这些参数的更多信息,可参考这里 。
- 如何在 NNI 中使用 sklearn
只需要如下几步,即可在 sklearn 代码中使用 NNI。
- 第一步,定义搜索空间
准备 search_space.json 文件来存储选择的搜索空间。 例如,不同的正则化值:
{
"C": {"_type":"uniform","_value":[0.1, 1]},
}
如果要选择不同的正则化参数、核函数等,可以将其放进一个search_space.json文件中。
{
"C": {"_type":"uniform","_value":[0.1, 1]},
"keral": {"_type":"choice","_value":["linear", "rbf", "poly", "sigmoid"]},
"degree": {"_type":"choice","_value":[1, 2, 3, 4]},
"gamma": {"_type":"uniform","_value":[0.01, 0.1]},
"coef0 ": {"_type":"uniform","_value":[0.01, 0.1]}
}
在 Python 代码中,可以将这些值作为一个 dict,读取到 Python 代码中。
- 第二步,代码修改
在代码最前面,要加上 import nni 来导入 NNI 包。
然后,要使用nni.get_next_parameter() 函数从 NNI 中获取参数。 然后在代码中使用这些参数。 例如,如果定义了如上的 search_space.json,就会获得像下面一样的 dict,就可以使用这些变量来编写 scikit-learn 的代码。
params = {
"C": 0.1,
"keral": "linear",
"degree": 1,
"gamma": 0.01,
"coef0 ": 0.01
}
完成训练后,可以得到模型分数,如:精度,召回率,均方差等等。 NNI 会将分数发送给 Tuner 算法,并据此生成下一组参数,所以需要将分数返回给 NNI。NNI 会开始下一个 Trial 任务。
因此只需要在训练结束后调用 nni.report_final_result(score),就可以将分数传给 NNI。 如果训练过程中有中间分数,也可以使用 nni.report_intemediate_result(score) 返回给 NNI。 注意, 可以不返回中间分数,但必须返回最终的分数。
def run(X_train, X_test, y_train, y_test, PARAMS):
'''Train model and predict result'''
model.fit(X_train, y_train)
score = model.score(X_test, y_test)
LOG.debug('score: %s' % score)
nni.report_final_result(score)
if __name__ == '__main__':
X_train, X_test, y_train, y_test = load_data()
try:
# get parameters from tuner
RECEIVED_PARAMS = nni.get_next_parameter()
LOG.debug(RECEIVED_PARAMS)
PARAMS = get_default_parameters()
PARAMS.update(RECEIVED_PARAMS)
LOG.debug(PARAMS)
model = get_model(PARAMS)
run(X_train, X_test, y_train, y_test, model)
except Exception as exception:
LOG.exception(exception)
raise
}
如上代码所示,在运行开始通过nni.get_next_parameter()调用参数,结束后在run()中通过nni.report_final_result(score)返回评估值,具体代码可参考样例。
- 第三步,准备 Tuner以及配置文件
准备 Tuner: NNI 支持多种流行的自动机器学习算法,包括:Random Search(随机搜索),Tree of Parzen Estimators (TPE),Evolution(进化算法)等等。 也可以实现自己的 Tuner(参考这里)。下面使用了 NNI 内置的 Tuner:
tuner:
builtinTunerName: TPE
classArgs:
optimize_mode: maximize
builtinTunerName 用来指定 NNI 中的 Tuner,classArgs 是传入到 Tuner的参数( 内置 Tuner在这里),optimization_mode 表明需要最大化还是最小化 Trial 的结果。
准备配置文件: 实现 Trial 的代码,并选择或实现自定义的 Tuner 后,就要准备 YAML 配置文件了。 其大致内容如下:
authorName: default
experimentName: example_sklearn-classification
# 并发运行数量
trialConcurrency: 1
# Experiment 运行时间
maxExecDuration: 1h
# 可为空,即数量不限
maxTrialNum: 100
#choice: local, remote
trainingServicePlatform: local
searchSpacePath: search_space.json
#choice: true, false
useAnnotation: false
tuner:
#choice: TPE, Random, Anneal, Evolution
builtinTunerName: TPE
classArgs:
#choice: maximize, minimize
optimize_mode: maximize
trial:
command: python3 main.py
codeDir: .
gpuNum: 0
因为这个 Trial 代码没有使用 NNI Annotation的方法,所以useAnnotation 为 false。 command 是运行 Trial 代码所需要的命令,codeDir 是 Trial 代码的相对位置。 命令会在此目录中执行。 同时,也需要提供每个 Trial 进程所需的 GPU 数量。
完成上述步骤后,可通过下列命令来启动 Experiment:
nnictl create --config ~/nni/examples/trials/sklearn/classification/config.yml
参考这里来了解 nnictl 命令行工具的更多用法。
- 查看 Experiment 结果
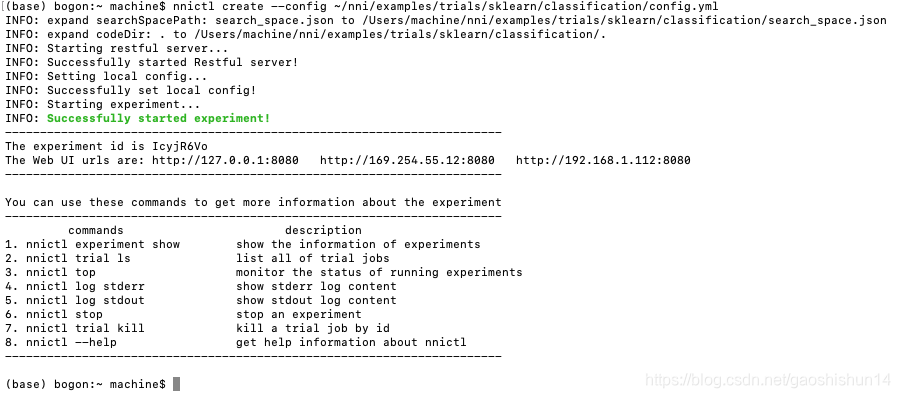
当出现Successfully started experiment!即表示实验成功,可通过Web UI的地址来查看实验结果,本次实验的实验结果如下图所示:
查看概要页面:
点击标签 "Overview"。
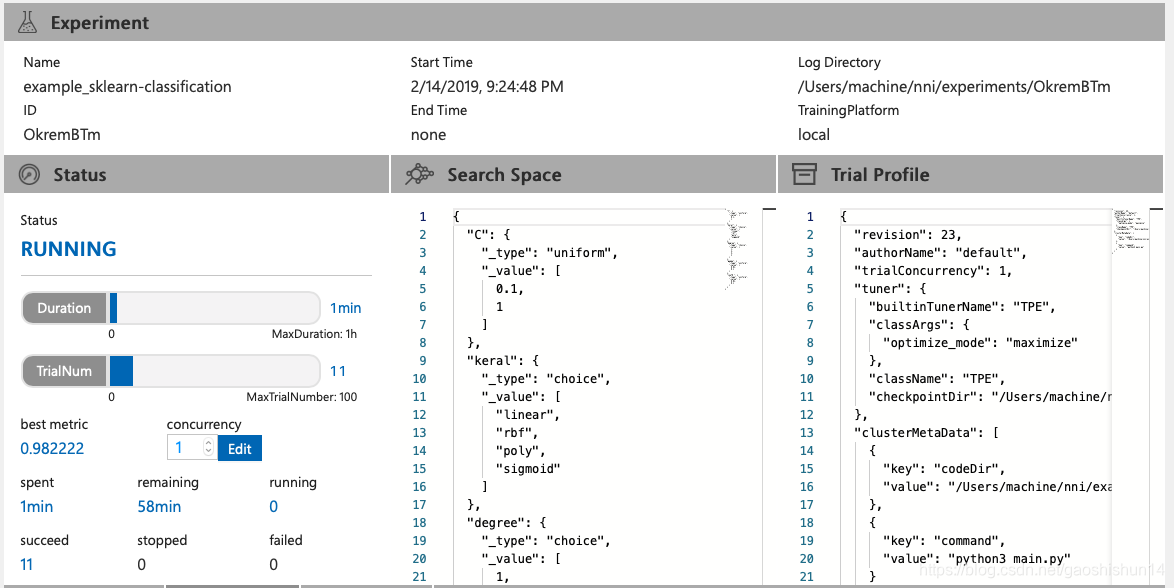
此图为Web UI的总体界面,通过此界面可以查看运行状态、搜索空间。可以在运行中或结束后,随时下载 Experiment 的结果。从上图中我们可以发现,我们最好的运行结果为0.98222,运行11次共花费2分钟。前 10 个 Trial 结果也会列在 Overview 页面中,如下所示:
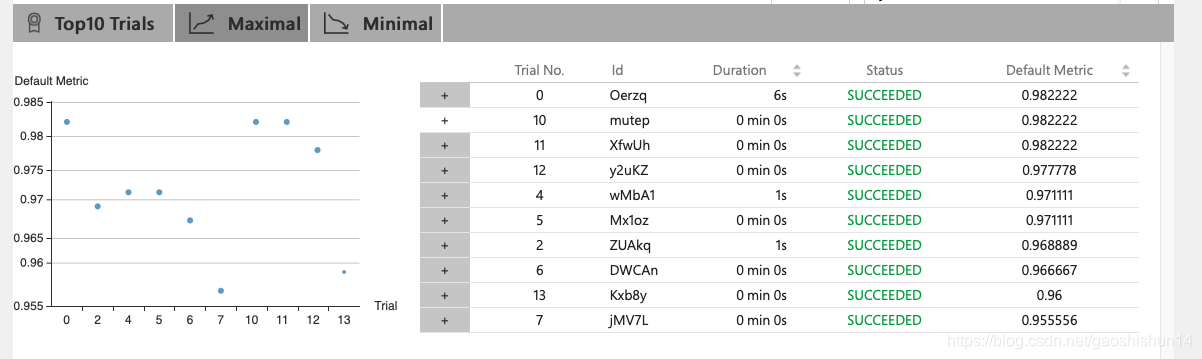
点击➕,还可以查看具体的参数值。
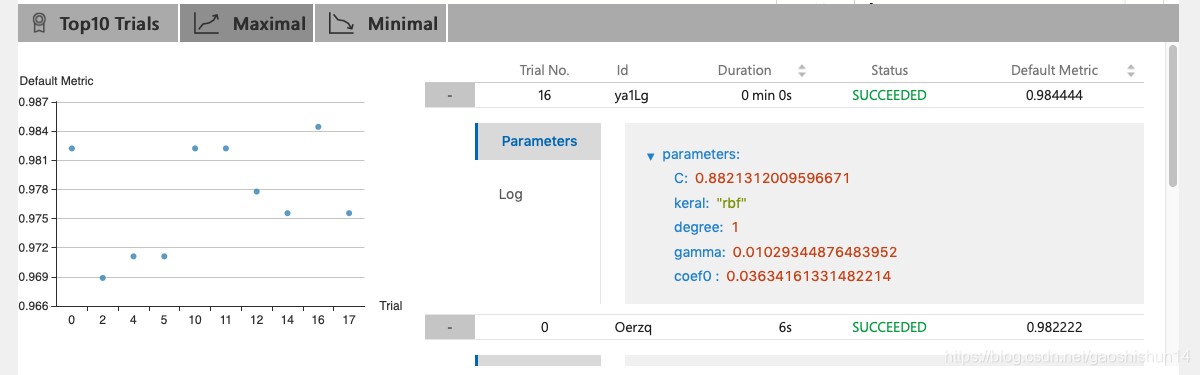
查看 Trial 详情页面:
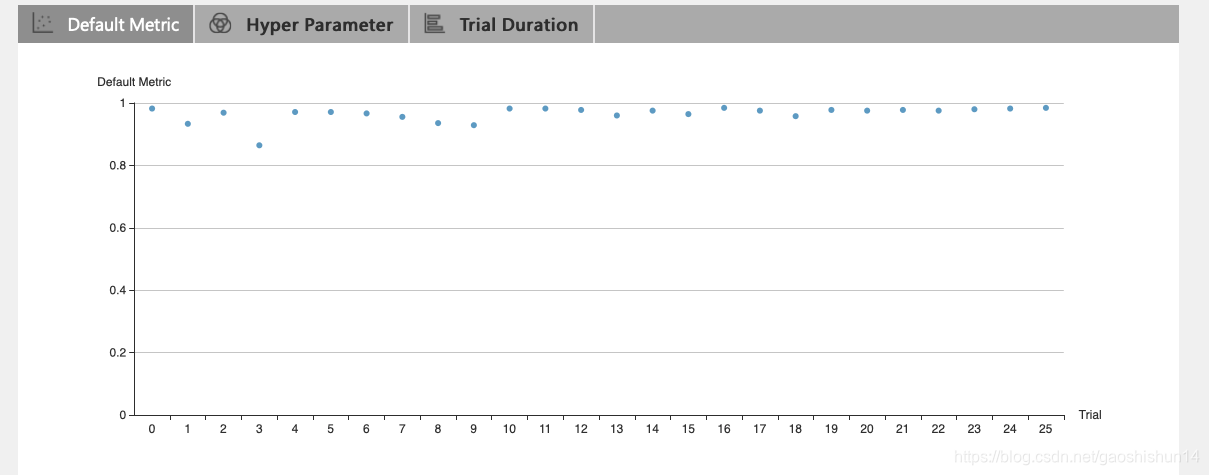
点击 "Default Metric" 来查看所有 Trial 的点图。
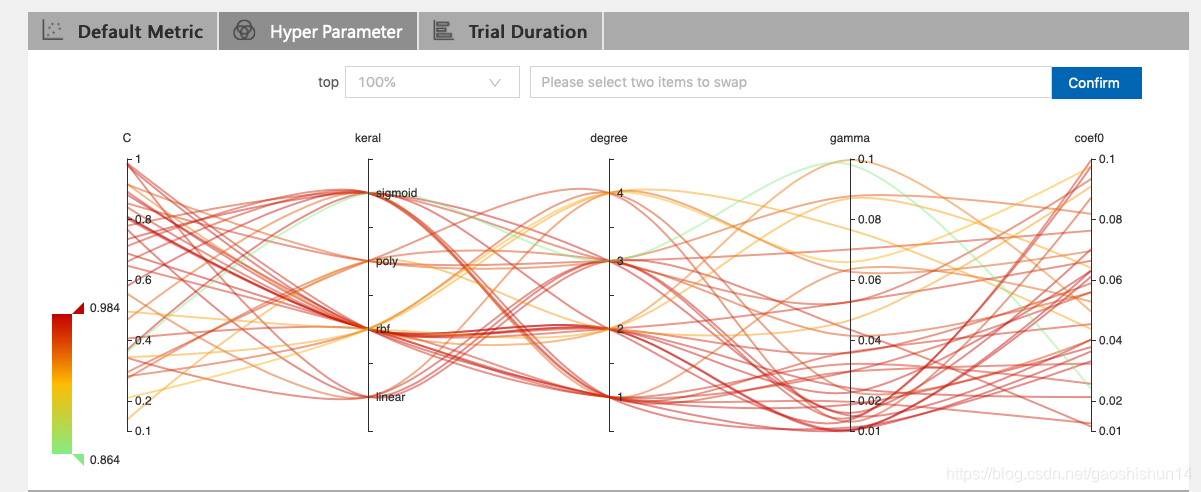
点击 "Hyper Parameter" 标签查看图像。
- 可选择百分比查看最好的 Trial。
- 选择两个轴来交换位置。
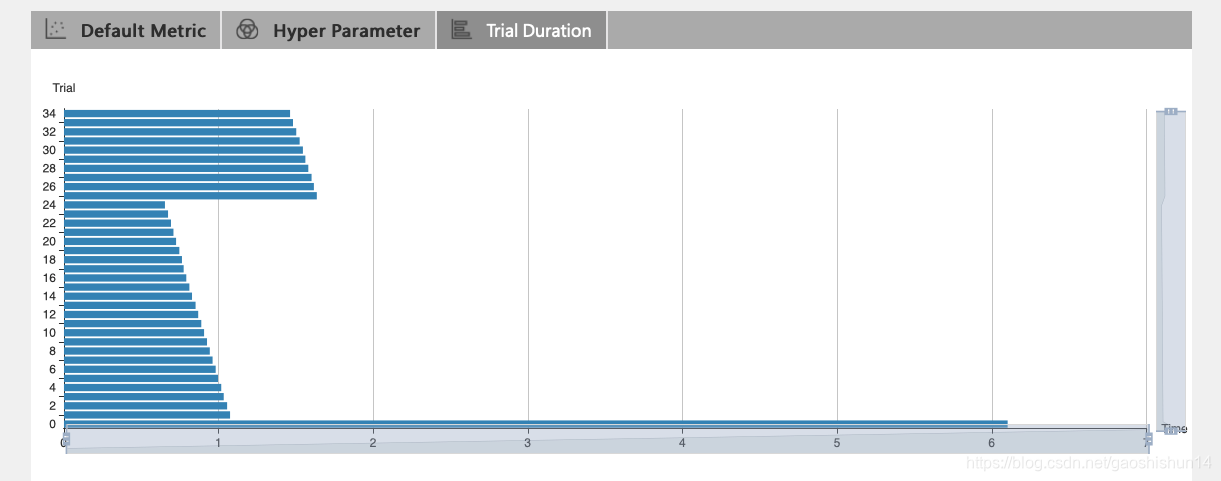
点击 "Trial Duration" 标签来查看柱状图,可观察到每次的运行时间。
三、使用NNI对TensorFlow进行调参
TensorFlow是一个基于数据流编程(dataflow programming)的符号数学系统,被广泛应用于各类机器学习(machine learning)算法的编程实现,它支持多种深度学习的架构。
- 样例概述
MINIST是深度学习的经典入门demo,它是由6万张训练图片和1万张测试图片构成的,每张图片都是28*28大小(如下图),而且都是黑白色构成(这里的黑色是一个0-1的浮点数,黑色越深表示数值越靠近1),这些图片是采集的不同的人手写从0到9的数字。TensorFlow将这个数据集和相关操作封装到了库中,而NNI可以为基于TensorFlow的深度学习算法搜索最佳的模型和超参。

- 如何在 NNI 中使用 TensorFlow
只需要如下几步,即可在 TensorFlow 代码中使用 NNI。因为具体步骤与上一个样例相同,在本例中仅给出相应代码。
- 第一步,定义搜索空间
search_space.json文件为:
{
"dropout_rate":{"_type":"uniform","_value":[0.5, 0.9]},
"conv_size":{"_type":"choice","_value":[2,3,5,7]},
"hidden_size":{"_type":"choice","_value":[124, 512, 1024]},
"batch_size": {"_type":"choice", "_value": [1, 4, 8, 16, 32]},
"learning_rate":{"_type":"choice","_value":[0.0001, 0.001, 0.01, 0.1]}
}
本例对于正则化、网络架构以及学习速率等超参进行调试。
- 第二步,代码修改
在代码最前面,加上 import nni 来导入 NNI 包。
然后,要使用nni.get_next_parameter() 函数从 NNI 中获取参数。
最后只需要在训练结束后调用 nni.report_final_result(score),就可以将分数传给 NNI。具体代码可参考样例
- 第三步,准备 Tuner以及配置文件
准备 Tuner: 本例使用 NNI 内置的 Tuner :Tree of Parzen Estimators (TPE)
tuner:
builtinTunerName: TPE
classArgs:
optimize_mode: maximize
准备配置文件: 实现 Trial 的代码,并选择或实现自定义的 Tuner 后,就要准备 YAML 配置文件了。 其大致内容如下:
authorName: default
experimentName: example_mnist
trialConcurrency: 1
maxExecDuration: 1h
maxTrialNum: 10
#choice: local, remote, pai
trainingServicePlatform: local
searchSpacePath: search_space.json
#choice: true, false
useAnnotation: false
tuner:
#choice: TPE, Random, Anneal, Evolution, BatchTuner
#SMAC (SMAC should be installed through nnictl)
builtinTunerName: TPE
classArgs:
#choice: maximize, minimize
optimize_mode: maximize
trial:
command: python3 mnist.py
codeDir: .
gpuNum: 0
因为这个 Trial 代码没有使用 NNI Annotation的方法,所以useAnnotation 为 false。 command 是运行 Trial 代码所需要的命令,codeDir 是 Trial 代码的相对位置。 命令会在此目录中执行。 同时,也需要提供每个 Trial 进程所需的 GPU 数量。
完成上述步骤后,可通过下列命令来启动 Experiment:
nnictl create --config ~/nni/examples/trials/minist/config.yml
参考这里来了解 nnictl 命令行工具的更多用法。
- 查看 Experiment 结果
本例将最大次数设置为20,实验结果如下图所示:
查看概要页面:
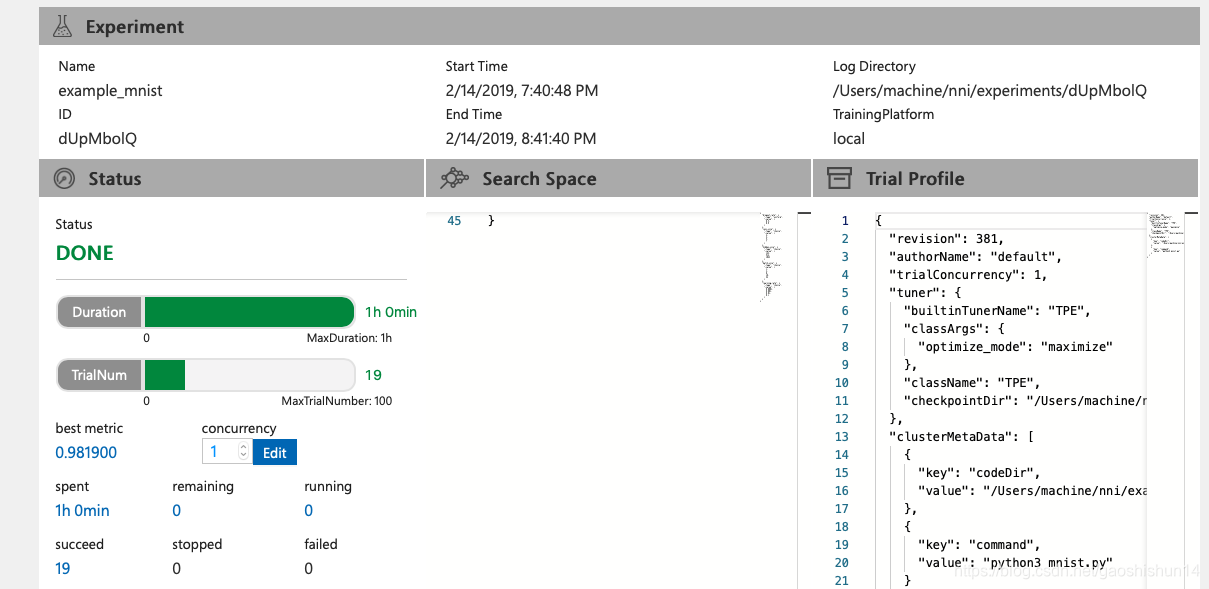
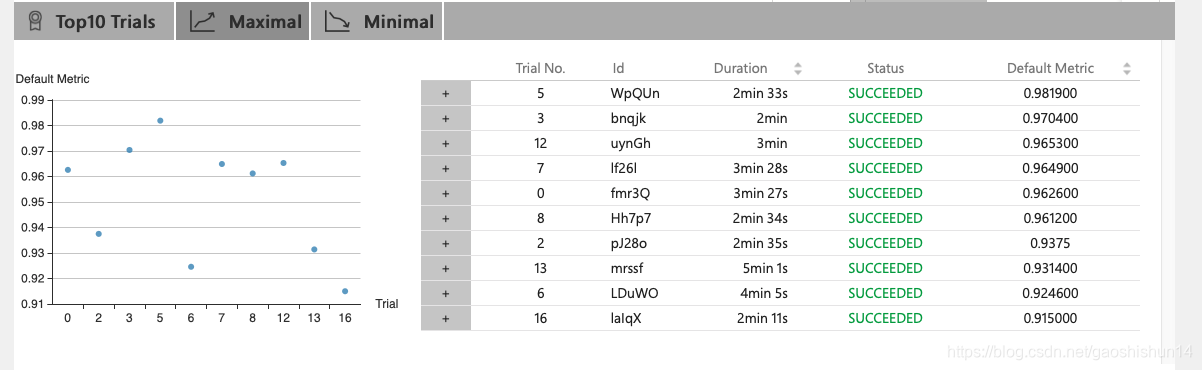
从上图中我们可以发现,我们最好的运行结果为0.981900,运行19次共花费60分钟。前 10 个 Trial 结果如下所示:
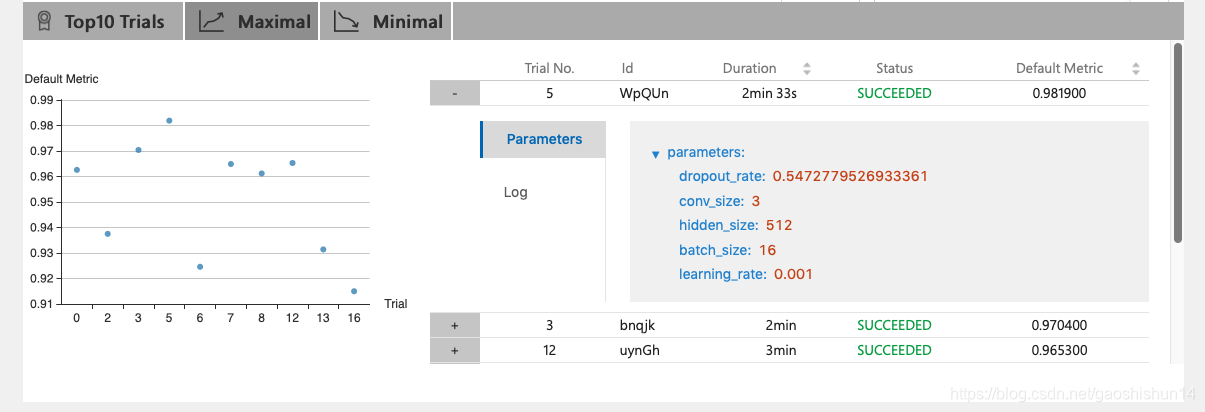
具体的参数值为:
查看 Trial 详情页面:
点击 "Default Metric" 来查看所有 Trial 的点图。
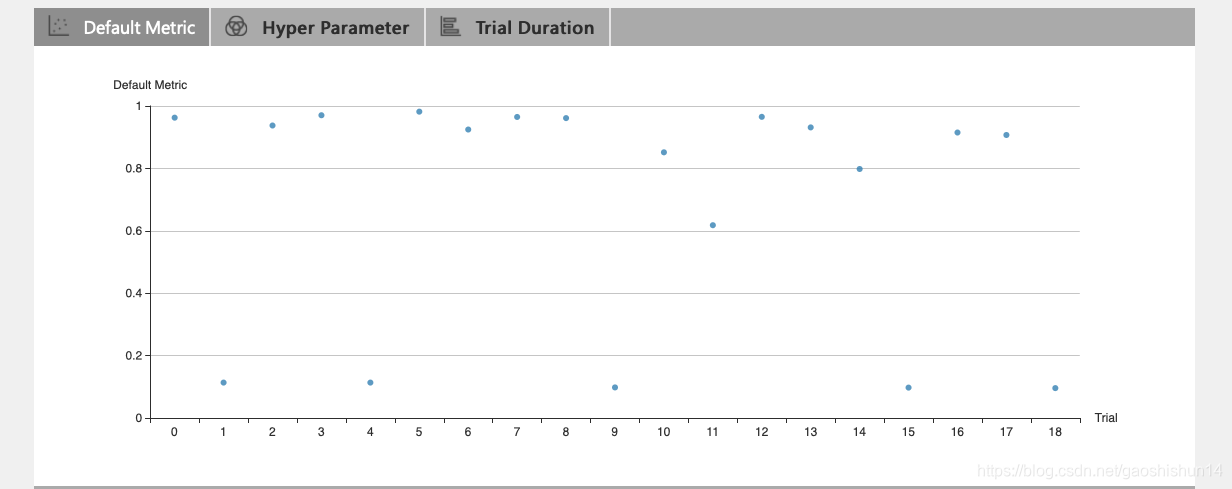
点击 "Hyper Parameter" 标签查看图像。
- 可选择百分比查看最好的 Trial。
- 选择两个轴来交换位置。
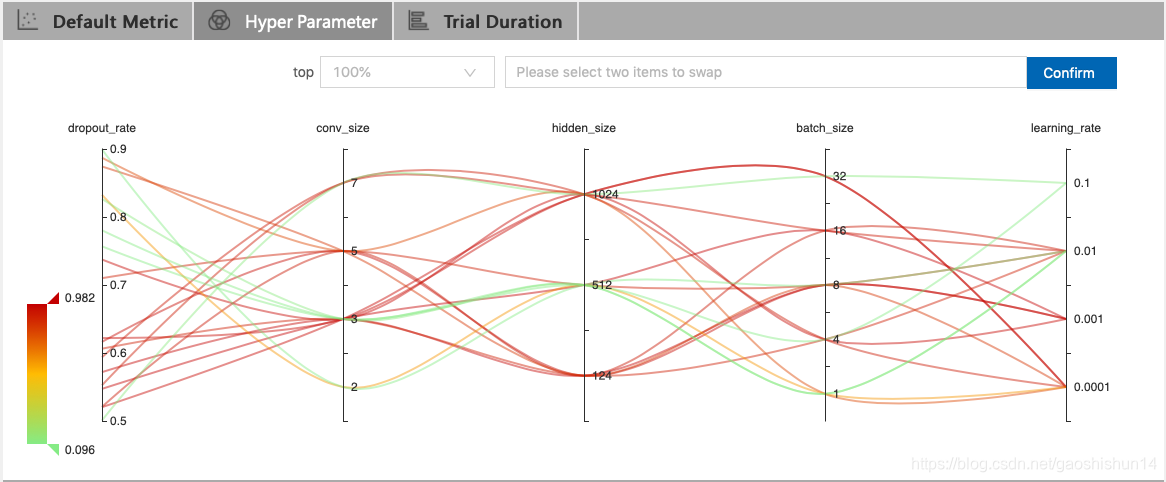
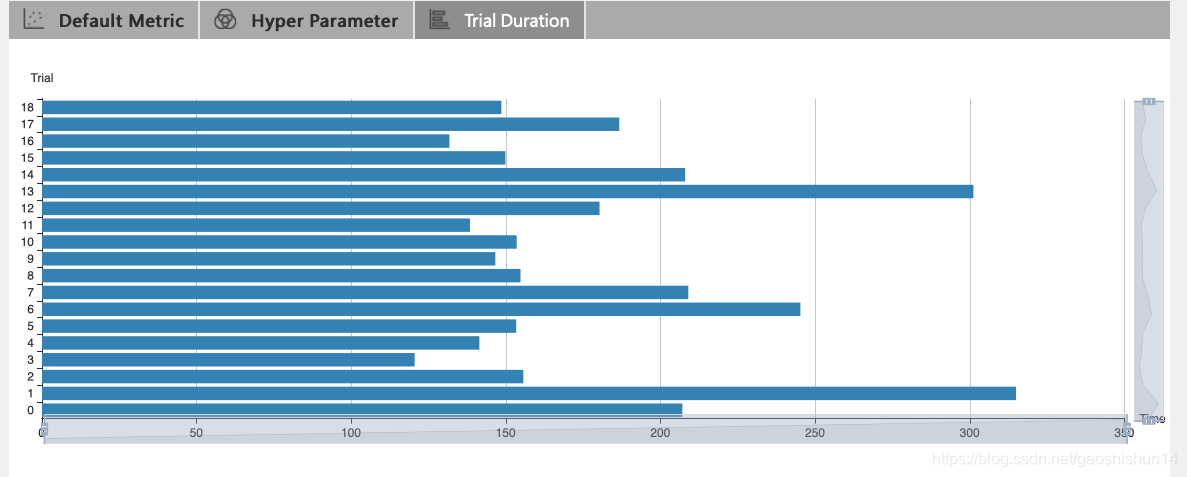
点击 "Trial Duration" 标签来查看柱状图,可观察到每次的运行时间。
四、总结
通过本文所应用的两个示例我们可以看到,NNI工具包可以帮助用户或者开发者自动进行数据分析,自动帮他们搜索模型,进行参数调试和性能分析。NNI极大的简便了 scikit-learn以及TensorFlow的调试工作。NNI仅仅需要定义搜索空间、简单的修改代码、编写配置文件就可以快速调试超参,并且其参数性能优越,而且提供了Web UI来查看调试过程中的相应信息。NNI可以为用户可以节省更多的时间,将精力放在探索更有深度的机器学习上。
使用NNI的scikit-learn以及Tensorflow分析的更多相关文章
- 集成算法(chapter 7 - Hands on machine learning with scikit learn and tensorflow)
Voting classifier 多种分类器分别训练,然后分别对输入(新数据)预测/分类,各个分类器的结果视为投票,投出最终结果: 训练: 投票: 为什么三个臭皮匠顶一个诸葛亮.通过大数定律直观地解 ...
- scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类 (python代码)
scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类数据集 fetch_20newsgroups #-*- coding: UTF-8 -*- import ...
- (原创)(三)机器学习笔记之Scikit Learn的线性回归模型初探
一.Scikit Learn中使用estimator三部曲 1. 构造estimator 2. 训练模型:fit 3. 利用模型进行预测:predict 二.模型评价 模型训练好后,度量模型拟合效果的 ...
- (原创)(四)机器学习笔记之Scikit Learn的Logistic回归初探
目录 5.3 使用LogisticRegressionCV进行正则化的 Logistic Regression 参数调优 一.Scikit Learn中有关logistics回归函数的介绍 1. 交叉 ...
- Scikit Learn: 在python中机器学习
转自:http://my.oschina.net/u/175377/blog/84420#OSC_h2_23 Scikit Learn: 在python中机器学习 Warning 警告:有些没能理解的 ...
- Scikit Learn
Scikit Learn Scikit-Learn简称sklearn,基于 Python 语言的,简单高效的数据挖掘和数据分析工具,建立在 NumPy,SciPy 和 matplotlib 上.
- Query意图分析:记一次完整的机器学习过程(scikit learn library学习笔记)
所谓学习问题,是指观察由n个样本组成的集合,并根据这些数据来预测未知数据的性质. 学习任务(一个二分类问题): 区分一个普通的互联网检索Query是否具有某个垂直领域的意图.假设现在有一个O2O领域的 ...
- Linear Regression with Scikit Learn
Before you read This is a demo or practice about how to use Simple-Linear-Regression in scikit-lear ...
- Spark技术在京东智能供应链预测的应用——按照业务进行划分,然后利用scikit learn进行单机训练并预测
3.3 Spark在预测核心层的应用 我们使用Spark SQL和Spark RDD相结合的方式来编写程序,对于一般的数据处理,我们使用Spark的方式与其他无异,但是对于模型训练.预测这些需要调用算 ...
随机推荐
- virtualbox+vagrant学习-2(command cli)-19-vagrant box命令
Status 格式: vagrant status [name|id] options只有 -h, --help 这将告诉你vagrant正在管理的机器的状态. 很容易就会忘记你的vagrant机器是 ...
- SSM框架之关于使用JSP作为视图展示问题解决方案
JSP作为视图层展示数据,已经有很长一段时间了,不管是在校学习还是企业工作,总会或多或少接触这个.特别是对于一些传统中小型或者一些几年前的企业而言,有很多使用JSP作为视图展示层. JSP本质是就是S ...
- VC++程序运行时间测试函数
0:介绍 我们在衡量一个函数运行时间,或者判断一个算法的时间效率,或者在程序中我们需要一个定时器,定时执行一个特定的操作,比如在多媒体中,比如在游戏中等,都会用到时间函数.还比如我们通过记录函数或者算 ...
- Elasticsearch之如何合理分配索引分片
大多数ElasticSearch用户在创建索引时通用会问的一个重要问题是:我需要创建多少个分片? 在本文中, 我将介绍在分片分配时的一些权衡以及不同设置带来的性能影响. 如果想搞清晰你的分片策略以及如 ...
- 名字&值
1)名字VS值 名字和内存(存储)位置相关联. 名字—(环境)———>位置——(状态)——>值 这两个映射都在随着程序的运行而改变. 2)环境VS状态 环境是指一个名字到存储位置映射,也可 ...
- 0CO_PC_01 成本对象控制: 计划/实际数据
用户提出要取生产订单的成本分析明细,分析目标和实际的差异. 查了一下,可以使用 BW标准数据源:0CO_PC_01 其中,值类型:10(实际).20(计划).30(目标) 货币类型:20(成本控制范围 ...
- php生成带自定义logo和带二维码跳转自定义地址的二维码
index.php<?phpheader('Content-type:text/html;charset=UTF-8');// 指定允许其他域名访问header('Access-Control- ...
- day 87 Vue学习六之axios、vuex、脚手架中组件传值
本节目录 一 axios的使用 二 vuex的使用 三 组件传值 四 xxx 五 xxx 六 xxx 七 xxx 八 xxx 一 axios的使用 Axios 是一个基于 promise 的 HT ...
- Linux-2.6_LCD驱动学习
内核自带的驱动LCD,drivers/video/Fbmem.c LCD驱动程序 假设app: open("/dev/fb0", ...) 主设备号: 29, 次设备号: 0--- ...
- iOS Swift WisdomKeyboardKing 键盘智能管家SDK
iOS Swift WisdomKeyboardKing 键盘智能管家SDK [1]前言: 今天给大家推荐个好用的开源框架:WisdomKeyboardKing,方面iOS日常开发,优点和功能请 ...