windows下在idea用maven导入spark2.3.1源码并编译并运行示例
一、前提
1.配置好maven:intellij idea maven配置及maven项目创建
2.下载好spark源码:
二、导入源码:
1.将下载的源码包spark-2.3.1.tgz解压(E:\spark-2.3.1.tgz\spark-2.3.1.tar)至E:\spark-2.3.1-src
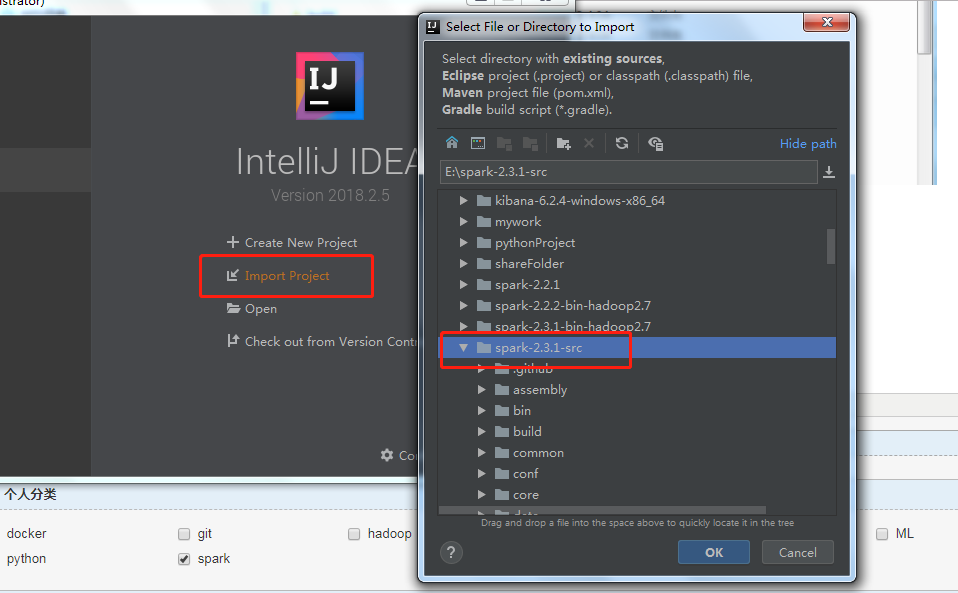
2.在ideal导入源码:
a.选择解压的源代码文件夹
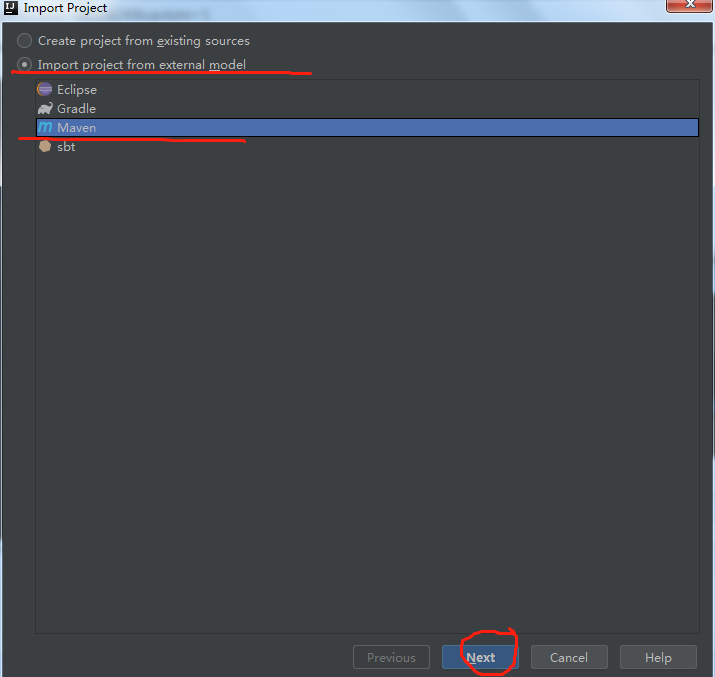
b.使用maven导入工程
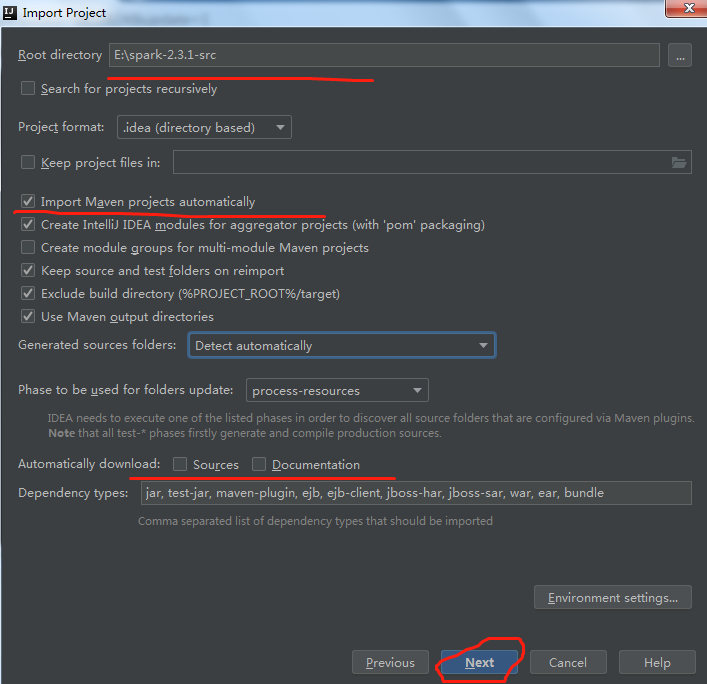
c.选择对应组件的版本
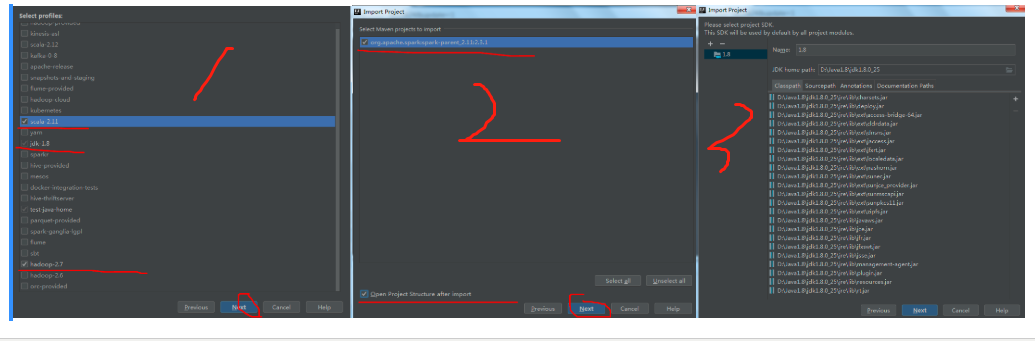
然后点击下一步:
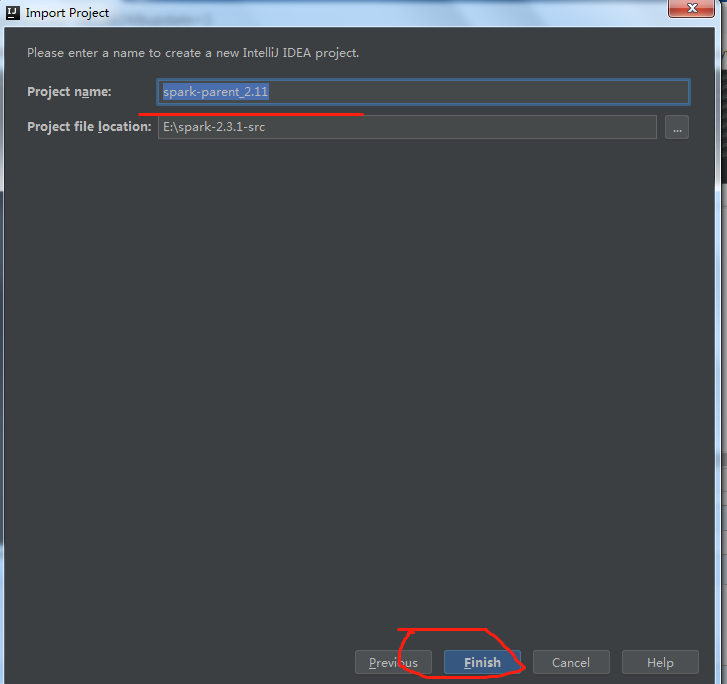 点击finish后,等待maven下载相关的依赖包,之后工程界面如下:
点击finish后,等待maven下载相关的依赖包,之后工程界面如下:
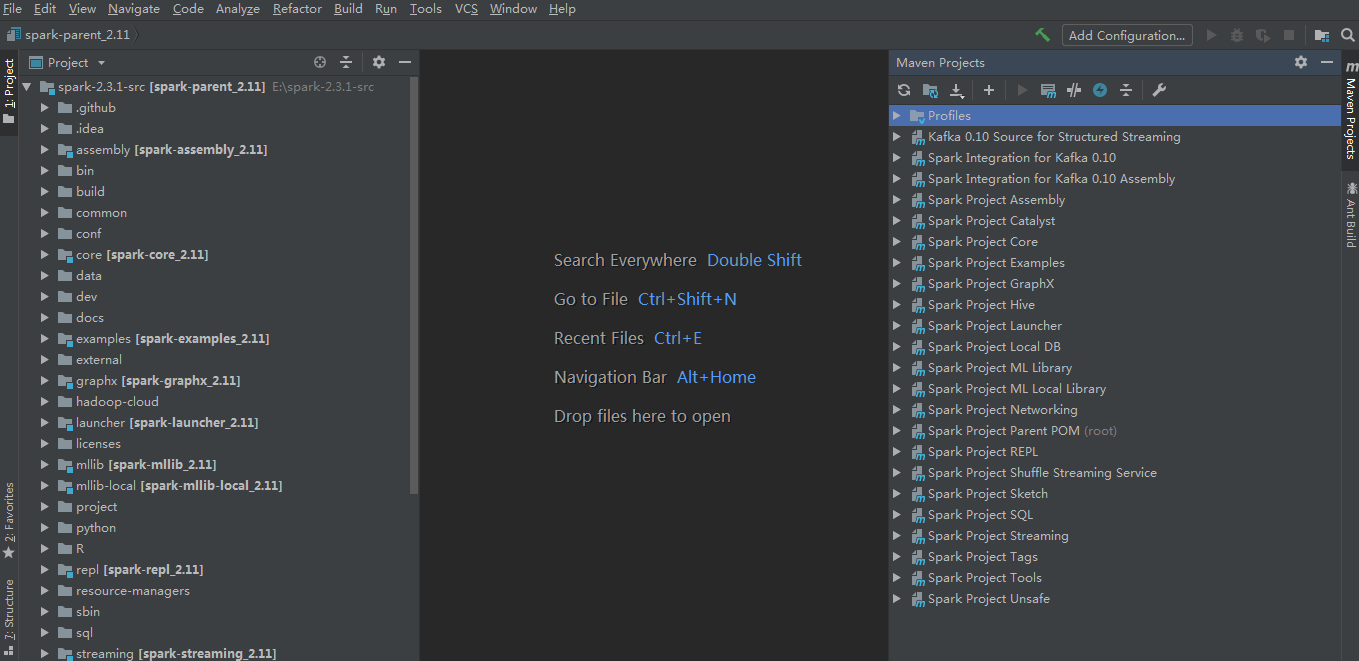
修改E:\spark-2.3.1-src\pom.xml文件,以避免这俩变量未定义,导致最终在E:\spark-2.3.1-src\assembly\target\scala-2.11\没有jar包

开始使用maven对spark源码进行编译打包成jar:
编译结果如下:
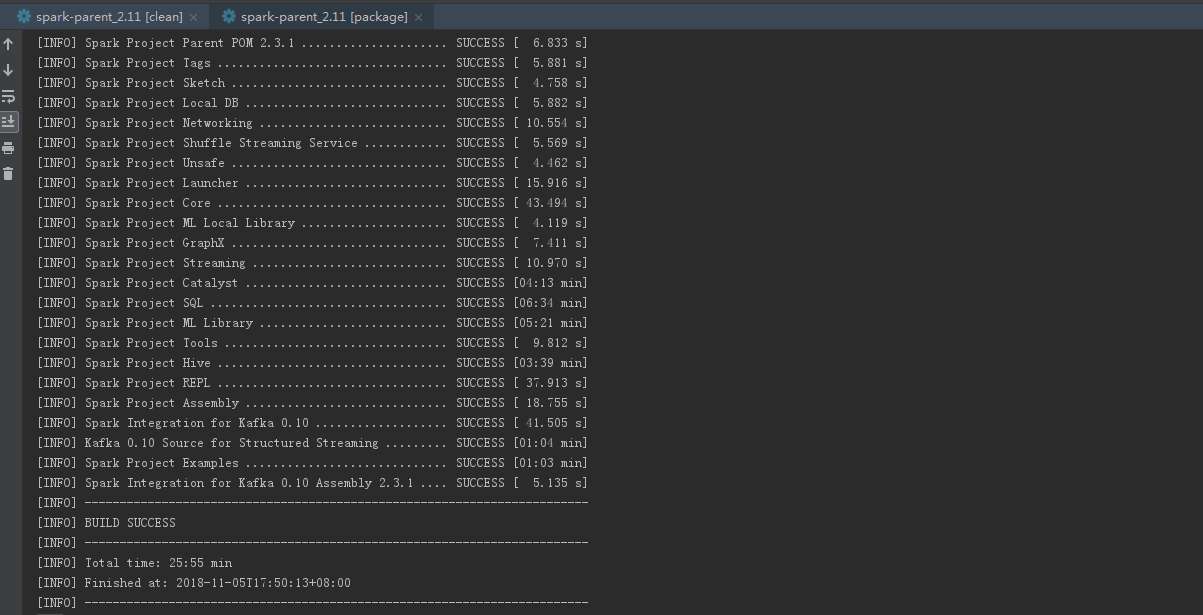
会在每个模块的target目录生成对应的jar,并在assembly\target\scala-2.11\jar下生成spark需要的全部jar包

解决办法如下,在E:\spark-2.3.1-src\sql\catalyst\target目录下会出现antlr4相关的类:


三.运行spark自带示例(前提:需要配置spark在windows下的运行环境,参见win7下配置spark)
1.SparkPi
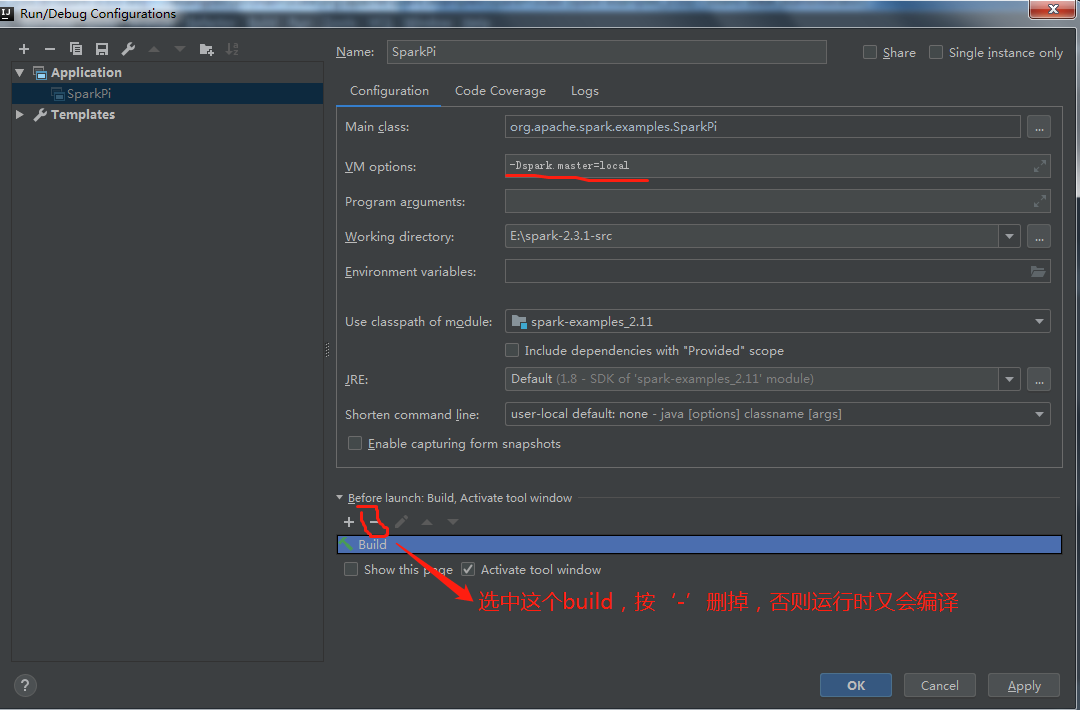
报错如下:
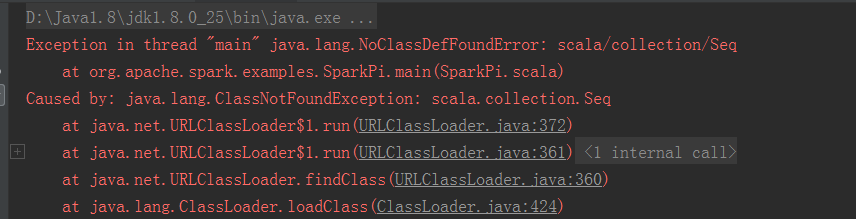
刚才生成的spark相关的依赖包没找到,解决办法如下:


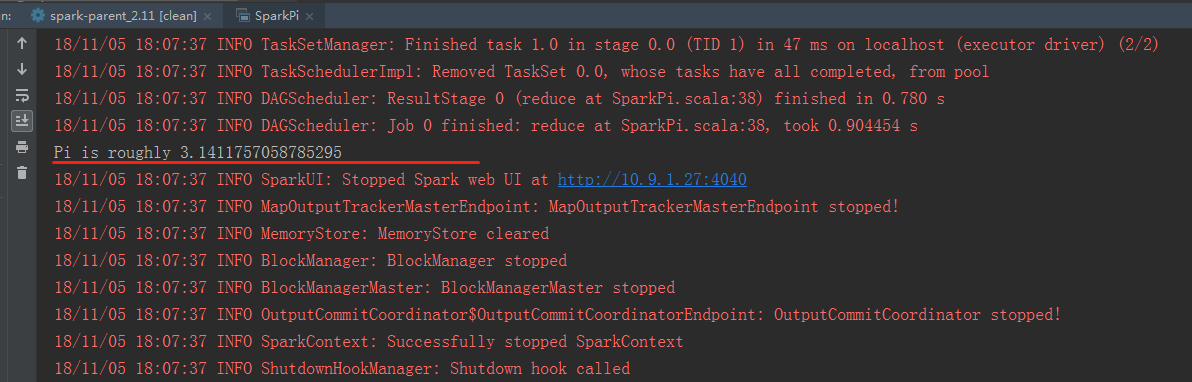
再次运行,结果如下:
2.通过org.apache.spark.deploy.SparkSubmit提交任务并运行(前提是像运行SparkPi一样,把assembly\target\jars的依赖加进该模块,方法同上):
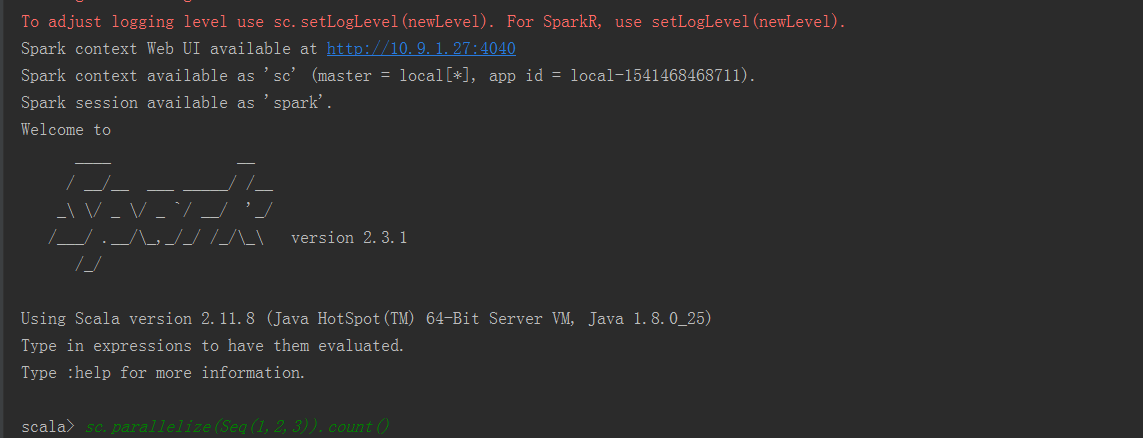
2.1 org.apache.spark.repl.Main
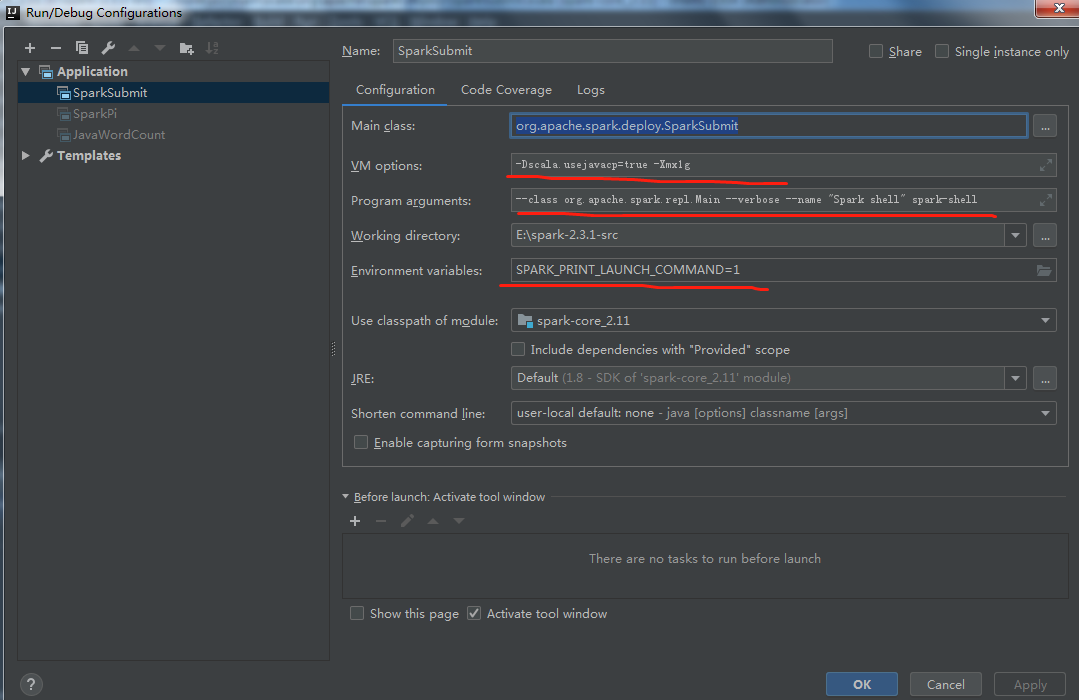
结果:
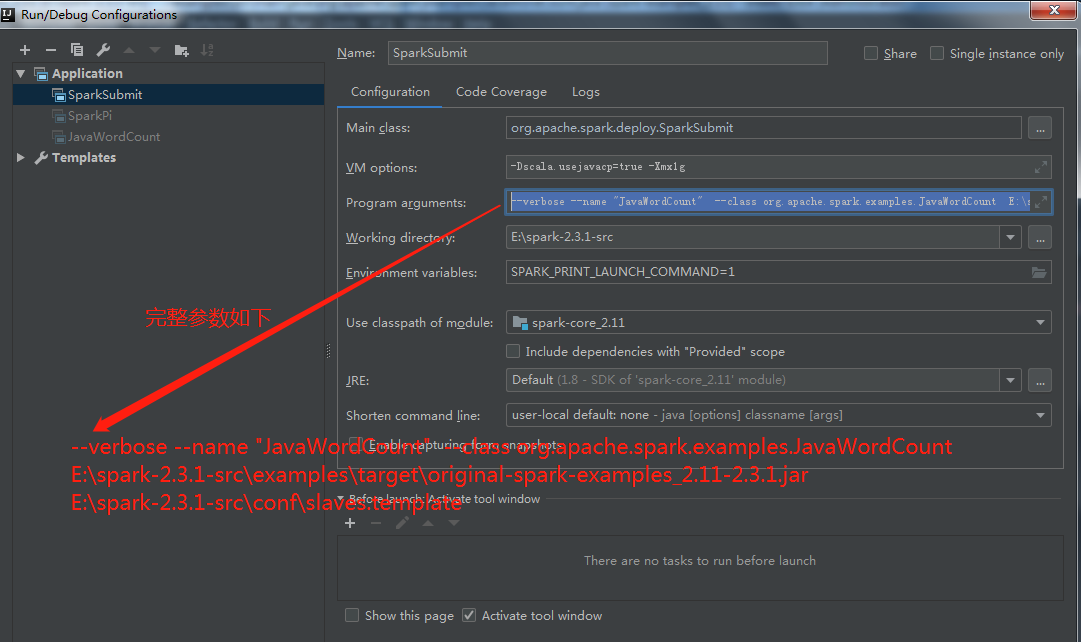
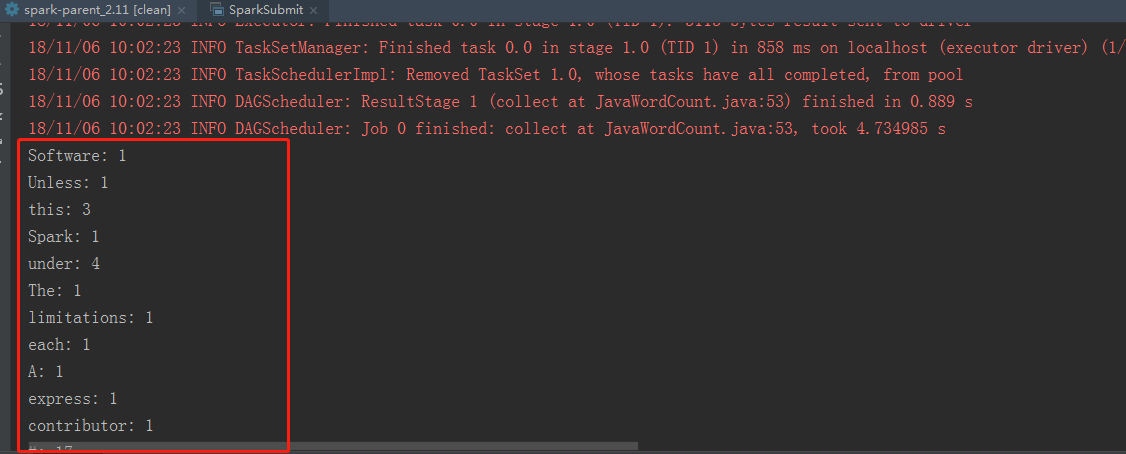
2.2 自定义spark代码类运行(以自带的org.apache.spark.examples.JavaWordCount为例)

windows下在idea用maven导入spark2.3.1源码并编译并运行示例的更多相关文章
- 导入spark2.3.3源码至intellij idea
检查环境配置 maven环境 2.检查scala插件 没有的话可以到https://plugins.jetbrains.com/plugin/1347-scala/versions 下载与idea对应 ...
- spark最新源码下载并导入到开发环境下助推高质量代码(Scala IDEA for Eclipse和IntelliJ IDEA皆适用)(以spark2.2.0源码包为例)(图文详解)
不多说,直接上干货! 前言 其实啊,无论你是初学者还是具备了有一定spark编程经验,都需要对spark源码足够重视起来. 本人,肺腑之己见,想要成为大数据的大牛和顶尖专家,多结合源码和操练编程. ...
- Windows上IDEA搭建最新Spark2.4.3源码调试的开发环境
相信很多同学都想通过阅读一些框架的源码,来提高自己的代码能力,但往往在第一步,搭建环境的时候就碰了壁. 本篇就来介绍下如何在Windows下,将最新版的Spark2.4.3编译,并导入到IDEA编译器 ...
- 如何在IDEA里给大数据项目导入该项目的相关源码(博主推荐)(类似eclipse里同一个workspace下单个子项目存在)(图文详解)
不多说,直接上干货! 如果在一个界面里,可以是单个项目 注意:本文是以gradle项目的方式来做的! 如何在IDEA里正确导入从Github上下载的Gradle项目(含相关源码)(博主推荐)(图文详解 ...
- 使用 IntelliJ IDEA 导入 Spark 最新源码及编译 Spark 源代码(博主强烈推荐)
前言 其实啊,无论你是初学者还是具备了有一定spark编程经验,都需要对spark源码足够重视起来. 本人,肺腑之己见,想要成为大数据的大牛和顶尖专家,多结合源码和操练编程. 准备工作 1.sca ...
- 使用 IntelliJ IDEA 导入 Spark 最新源码及编译 Spark 源代码
前言 其实啊,无论你是初学者还是具备了有一定spark编程经验,都需要对spark源码足够重视起来. 本人,肺腑之己见,想要成为大数据的大牛和顶尖专家,多结合源码和操练编程. 准备工作 1.sca ...
- Spark2.0.0源码编译
Hive默认使用MapReduce作为执行引擎,即Hive on mr,Hive还可以使用Tez和Spark作为其执行引擎,分别为Hive on Tez和Hive on Spark.由于MapRedu ...
- 一步步实现windows版ijkplayer系列文章之七——终结篇(附源码)
一步步实现windows版ijkplayer系列文章之一--Windows10平台编译ffmpeg 4.0.2,生成ffplay 一步步实现windows版ijkplayer系列文章之二--Ijkpl ...
- 一步步实现windows版ijkplayer系列文章之二——Ijkplayer播放器源码分析之音视频输出——视频篇
一步步实现windows版ijkplayer系列文章之一--Windows10平台编译ffmpeg 4.0.2,生成ffplay 一步步实现windows版ijkplayer系列文章之二--Ijkpl ...
随机推荐
- Java8新特性 -- Lambda基础语法
Lambda 表达式的基础语法: Java8引入了一个新的操作符 “->” 该操作符称为箭头操作符或Lambda操作符, 该操作符将Lambda表达式拆分为两部分: 左侧: Lambda表达式 ...
- 什么是AOP-面向交叉业务编程
一.AOP(Aspect-oriented programming,面向切面编程): 什么是AOP? 定义:将程序中的交叉业务逻辑提取出来,称之为切面.将这些切面动态织入到目标对象,然后生成一个代理对 ...
- CentOS 7.4 yum安装LAMP环境
配置防火墙,开启80.3306端口.CentOS 7.0默认使用的是firewall作为防火墙,这里改为iptables防火墙. #停止firewall服务 systemctl stop firewa ...
- Ansible--01
一.ansible是什么: 类似puppet之类的运维自动化工具 二.为什么选择ansible: 1. ansible是python语言开发的,python语言进入门槛低,方便基于pytnon对ans ...
- (十)T检验-第一部分
介绍T分布.T检验.Z检验与T检验.P值.相依样本以及配对样本的非独立T检验. T分布 在到目前为止举的所有例子中,我们都假设我们知道总体参数 μ 和 σ,但很多时候,我们并不知道,我们通常只有样本, ...
- Odoo的@api.装饰器
转载请注明原文地址:https://www.cnblogs.com/cnodoo/p/9281437.html Odoo自带的api装饰器主要有:model,multi,one,constrains, ...
- Entity Framework Code First 遭遇主键自动生成问题
4.0后就没有去跟踪后面的版本了.现在直接开始用5.0没想到在做User的GURD时就遭遇insert不进数据问题. ISet<User>.Add(user);_context.SaveC ...
- 学习笔记——OS——引论
学习笔记--OS--引论 操作系统的定义 操作系统是一组管理计算机硬件资源的软件集合: 用户和计算机硬件之间的接口 控制和管理硬件资源 实现对计算机资源的抽象 计算机系统硬件 冯诺依曼体系结构和哈佛结 ...
- 理解C++类的继承方式(小白)
基类里的 public(大人) protect(青年) private(小孩) 在通过继承时 继承方式public(我是大人咯) protect(我是青少年) private(我系小孩纸啦) &qu ...
- 20155238 2016-2017-2 《Java程序设计》第二周学习总结
教材学习内容总结 java基本类型:整数,字节,浮点数,字符 //"单行批注" */"单行批注" 变量 "驼峰式命命法" int age0f ...