Netty源码分析第6章(解码器)---->第4节: 分隔符解码器
Netty源码分析第六章: 解码器
第四节: 分隔符解码器
基于分隔符解码器DelimiterBasedFrameDecoder, 是按照指定分隔符进行解码的解码器, 通过分隔符, 可以将二进制流拆分成完整的数据包
同样继承了ByteToMessageDecoder并重写了decode方法
我们看其中的一个构造方法:
public DelimiterBasedFrameDecoder(int maxFrameLength, ByteBuf... delimiters) {
this(maxFrameLength, true, delimiters);
}
这里参数maxFrameLength代表最大长度, delimiters是个可变参数, 可以说可以支持多个分隔符进行解码
我们进入decode方法:
protected final void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
Object decoded = decode(ctx, in);
if (decoded != null) {
out.add(decoded);
}
}
这里同样调用了其重载的decode方法并将解析好的数据添加到集合list中, 其父类就可以遍历out, 并将内容传播
我们跟到重载decode方法中:
protected Object decode(ChannelHandlerContext ctx, ByteBuf buffer) throws Exception {
//行处理器(1)
if (lineBasedDecoder != null) {
return lineBasedDecoder.decode(ctx, buffer);
}
int minFrameLength = Integer.MAX_VALUE;
ByteBuf minDelim = null;
//找到最小长度的分隔符(2)
for (ByteBuf delim: delimiters) {
//每个分隔符分隔的数据包长度
int frameLength = indexOf(buffer, delim);
if (frameLength >= 0 && frameLength < minFrameLength) {
minFrameLength = frameLength;
minDelim = delim;
}
}
//解码(3)
//已经找到分隔符
if (minDelim != null) {
int minDelimLength = minDelim.capacity();
ByteBuf frame;
//当前分隔符否处于丢弃模式
if (discardingTooLongFrame) {
//首先设置为非丢弃模式
discardingTooLongFrame = false;
//丢弃
buffer.skipBytes(minFrameLength + minDelimLength);
int tooLongFrameLength = this.tooLongFrameLength;
this.tooLongFrameLength = 0;
if (!failFast) {
fail(tooLongFrameLength);
}
return null;
}
//处于非丢弃模式
//当前找到的数据包, 大于允许的数据包
if (minFrameLength > maxFrameLength) {
//当前数据包+最小分隔符长度 全部丢弃
buffer.skipBytes(minFrameLength + minDelimLength);
//传递异常事件
fail(minFrameLength);
return null;
}
//如果是正常的长度
//解析出来的数据包是否忽略分隔符
if (stripDelimiter) {
//如果不包含分隔符
//截取
frame = buffer.readRetainedSlice(minFrameLength);
//跳过分隔符
buffer.skipBytes(minDelimLength);
} else {
//截取包含分隔符的长度
frame = buffer.readRetainedSlice(minFrameLength + minDelimLength);
}
return frame;
} else {
//如果没有找到分隔符
//非丢弃模式
if (!discardingTooLongFrame) {
//可读字节大于允许的解析出来的长度
if (buffer.readableBytes() > maxFrameLength) {
//将这个长度记录下
tooLongFrameLength = buffer.readableBytes();
//跳过这段长度
buffer.skipBytes(buffer.readableBytes());
//标记当前处于丢弃状态
discardingTooLongFrame = true;
if (failFast) {
fail(tooLongFrameLength);
}
}
} else {
tooLongFrameLength += buffer.readableBytes();
buffer.skipBytes(buffer.readableBytes());
}
return null;
}
}
这里的方法也比较长, 这里也通过拆分进行剖析
(1). 行处理器
(2). 找到最小长度分隔符
(3). 解码
首先看第一步行处理器:
if (lineBasedDecoder != null) {
return lineBasedDecoder.decode(ctx, buffer);
}
这里首先判断成员变量lineBasedDecoder是否为空, 如果不为空则直接调用lineBasedDecoder的decode的方法进行解码, lineBasedDecoder实际上就是上一小节剖析的LineBasedFrameDecoder解码器
这个成员变量, 会在分隔符是\n和\r\n的时候进行初始化
我们看初始化该属性的构造方法:
public DelimiterBasedFrameDecoder(
int maxFrameLength, boolean stripDelimiter, boolean failFast, ByteBuf... delimiters) {
//代码省略
//如果是基于行的分隔
if (isLineBased(delimiters) && !isSubclass()) {
//初始化行处理器
lineBasedDecoder = new LineBasedFrameDecoder(maxFrameLength, stripDelimiter, failFast);
this.delimiters = null;
} else {
//代码省略
}
//代码省略
}
这里isLineBased(delimiters)会判断是否是基于行的分隔, 跟到isLineBased方法中:
private static boolean isLineBased(final ByteBuf[] delimiters) {
//分隔符长度不为2
if (delimiters.length != 2) {
return false;
}
//拿到第一个分隔符
ByteBuf a = delimiters[0];
//拿到第二个分隔符
ByteBuf b = delimiters[1];
if (a.capacity() < b.capacity()) {
a = delimiters[1];
b = delimiters[0];
}
//确保a是/r/n分隔符, 确保b是/n分隔符
return a.capacity() == 2 && b.capacity() == 1
&& a.getByte(0) == '\r' && a.getByte(1) == '\n'
&& b.getByte(0) == '\n';
}
首先判断长度等于2, 直接返回false
然后拿到第一个分隔符a和第二个分隔符b, 然后判断a的第一个分隔符是不是\r, a的第二个分隔符是不是\n, b的第一个分隔符是不是\n, 如果都为true, 则条件成立
我们回到decode方法中, 看步骤2, 找到最小长度的分隔符:
这里最小长度的分隔符, 意思就是从读指针开始, 找到最近的分隔符
for (ByteBuf delim: delimiters) {
//每个分隔符分隔的数据包长度
int frameLength = indexOf(buffer, delim);
if (frameLength >= 0 && frameLength < minFrameLength) {
minFrameLength = frameLength;
minDelim = delim;
}
}
这里会遍历所有的分隔符, 然后找到每个分隔符到读指针到数据包长度
然后通过if判断, 找到长度最小的数据包的长度, 然后保存当前数据包的的分隔符, 如下图:
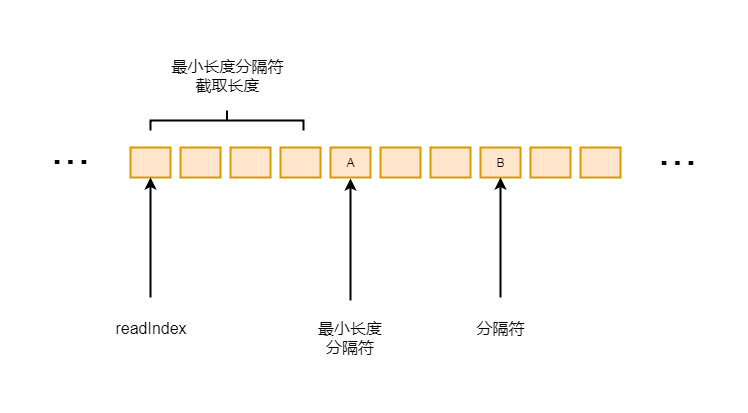
6-4-1
这里假设A和B同为分隔符, A分隔符到读指针的长度小于B分隔符到读指针的长度, 这里会找到最小的分隔符A, 分隔符的最小长度, 就readIndex到A的长度
我们继续看第3步, 解码:
if (minDelim != null) 表示已经找到最小长度分隔符, 我们继续看if块中的逻辑:
int minDelimLength = minDelim.capacity();
ByteBuf frame;
if (discardingTooLongFrame) {
discardingTooLongFrame = false;
buffer.skipBytes(minFrameLength + minDelimLength);
int tooLongFrameLength = this.tooLongFrameLength;
this.tooLongFrameLength = 0;
if (!failFast) {
fail(tooLongFrameLength);
}
return null;
}
if (minFrameLength > maxFrameLength) {
buffer.skipBytes(minFrameLength + minDelimLength);
fail(minFrameLength);
return null;
}
if (stripDelimiter) {
frame = buffer.readRetainedSlice(minFrameLength);
buffer.skipBytes(minDelimLength);
} else {
frame = buffer.readRetainedSlice(minFrameLength + minDelimLength);
}
return frame;
if (discardingTooLongFrame) 表示当前是否处于非丢弃模式, 如果是丢弃模式, 则进入if块
因为第一个不是丢弃模式, 所以这里先分析if块后面的逻辑
if (minFrameLength > maxFrameLength) 这里是判断当前找到的数据包长度大于最大长度, 这里的最大长度使我们创建解码器的时候设置的, 如果超过了最大长度, 就通过 buffer.skipBytes(minFrameLength + minDelimLength) 方式, 跳过数据包+分隔符的长度, 也就是将这部分数据进行完全丢弃
继续往下看, 如果长度不大最大允许长度, 则通过 if (stripDelimiter) 判断解析的出来的数据包是否包含分隔符, 如果不包含分隔符, 则截取数据包的长度之后, 跳过分隔符
我们再回头看 if (discardingTooLongFrame) 中的if块中的逻辑, 也就是丢弃模式:
首先将discardingTooLongFrame设置为false, 标记非丢弃模式
然后通过 buffer.skipBytes(minFrameLength + minDelimLength) 将数据包+分隔符长度的字节数跳过, 也就是进行丢弃, 之后再进行抛出异常
分析完成了找到分隔符之后的丢弃模式非丢弃模式的逻辑处理, 我们在分析没找到分隔符的逻辑处理, 也就是 if (minDelim != null) 中的else块:
if (!discardingTooLongFrame) {
if (buffer.readableBytes() > maxFrameLength) {
tooLongFrameLength = buffer.readableBytes();
buffer.skipBytes(buffer.readableBytes());
discardingTooLongFrame = true;
if (failFast) {
fail(tooLongFrameLength);
}
}
} else {
tooLongFrameLength += buffer.readableBytes();
buffer.skipBytes(buffer.readableBytes());
}
return null;
首先通过 if (!discardingTooLongFrame) 判断是否为非丢弃模式, 如果是, 则进入if块:
在if块中, 首先通过 if (buffer.readableBytes() > maxFrameLength) 判断当前可读字节数是否大于最大允许的长度, 如果大于最大允许的长度, 则将可读字节数设置到tooLongFrameLength的属性中, 代表丢弃的字节数
然后通过 buffer.skipBytes(buffer.readableBytes()) 将累计器中所有的可读字节进行丢弃
最后将discardingTooLongFrame设置为true, 也就是丢弃模式, 之后抛出异常
如果 if (!discardingTooLongFrame) 为false, 也就是当前处于丢弃模式, 则追加tooLongFrameLength也就是丢弃的字节数的长度, 并通过 buffer.skipBytes(buffer.readableBytes()) 将所有的字节继续进行丢弃
以上就是分隔符解码器的相关逻辑
第六章总结
本章介绍了抽象解码器ByteToMessageDecoder, 和其他几个实现了ByteToMessageDecoder类的解码器, 这个几个解码器逻辑都比较简单, 同学们可以根据其中的思想剖析其他的比较复杂的解码器, 或者根据其规则实现自己的自定义解码器
Netty源码分析第6章(解码器)---->第4节: 分隔符解码器的更多相关文章
- Netty源码分析第4章(pipeline)---->第4节: 传播inbound事件
Netty源码分析第四章: pipeline 第四节: 传播inbound事件 有关于inbound事件, 在概述中做过简单的介绍, 就是以自己为基准, 流向自己的事件, 比如最常见的channelR ...
- Netty源码分析第4章(pipeline)---->第5节: 传播outbound事件
Netty源码分析第五章: pipeline 第五节: 传播outBound事件 了解了inbound事件的传播过程, 对于学习outbound事件传输的流程, 也不会太困难 在我们业务代码中, 有可 ...
- Netty源码分析第4章(pipeline)---->第6节: 传播异常事件
Netty源码分析第四章: pipeline 第6节: 传播异常事件 讲完了inbound事件和outbound事件的传输流程, 这一小节剖析异常事件的传输流程 首先我们看一个最最简单的异常处理的场景 ...
- Netty源码分析第4章(pipeline)---->第7节: 前章节内容回顾
Netty源码分析第四章: pipeline 第七节: 前章节内容回顾 我们在第一章和第三章中, 遗留了很多有关事件传输的相关逻辑, 这里带大家一一回顾 首先看两个问题: 1.在客户端接入的时候, N ...
- Netty源码分析第5章(ByteBuf)---->第4节: PooledByteBufAllocator简述
Netty源码分析第五章: ByteBuf 第四节: PooledByteBufAllocator简述 上一小节简单介绍了ByteBufAllocator以及其子类UnPooledByteBufAll ...
- Netty源码分析第5章(ByteBuf)---->第5节: directArena分配缓冲区概述
Netty源码分析第五章: ByteBuf 第五节: directArena分配缓冲区概述 上一小节简单分析了PooledByteBufAllocator中, 线程局部缓存和arean的相关逻辑, 这 ...
- Netty源码分析第5章(ByteBuf)---->第6节: 命中缓存的分配
Netty源码分析第6章: ByteBuf 第六节: 命中缓存的分配 上一小节简单分析了directArena内存分配大概流程, 知道其先命中缓存, 如果命中不到, 则区分配一款连续内存, 这一小节带 ...
- Netty源码分析第5章(ByteBuf)---->第7节: page级别的内存分配
Netty源码分析第五章: ByteBuf 第六节: page级别的内存分配 前面小节我们剖析过命中缓存的内存分配逻辑, 前提是如果缓存中有数据, 那么缓存中没有数据, netty是如何开辟一块内存进 ...
- Netty源码分析第5章(ByteBuf)---->第10节: SocketChannel读取数据过程
Netty源码分析第五章: ByteBuf 第十节: SocketChannel读取数据过程 我们第三章分析过客户端接入的流程, 这一小节带大家剖析客户端发送数据, Server读取数据的流程: 首先 ...
- Netty源码分析第4章(pipeline)---->第1节: pipeline的创建
Netty源码分析第四章: pipeline 概述: pipeline, 顾名思义, 就是管道的意思, 在netty中, 事件在pipeline中传输, 用户可以中断事件, 添加自己的事件处理逻辑, ...
随机推荐
- Golang 临时对象池 sync.Pool
Go 1.3 的sync包中加入一个新特性:Pool.官方文档可以看这里http://golang.org/pkg/sync/#Pool 这个类设计的目的是用来保存和复用临时对象,以减少内存分配,降低 ...
- 使用Yarn+Webpack+Babel6搭建React.js环境
使用Yarn+Webpack+Babel6搭建React.js环境 Facebook开源的React.js已经改变了世人对前端UI的思考方式.这种基于组件方式的优势之一,就是使View更加的简单,因为 ...
- BZOJ3530:[SDOI2014]数数(AC自动机,数位DP)
Description 我们称一个正整数N是幸运数,当且仅当它的十进制表示中不包含数字串集合S中任意一个元素作为其子串.例如当S=(22,333,0233)时,233是幸运数,2333.20233.3 ...
- ZooKeeper学习之路 (九)利用ZooKeeper搭建Hadoop的HA集群
Hadoop HA 原理概述 为什么会有 hadoop HA 机制呢? HA:High Available,高可用 在Hadoop 2.0之前,在HDFS 集群中NameNode 存在单点故障 (SP ...
- 浅谈User Information List
[User Information List]用于查看一个site collection所有可以访问的用户信息.一个site collection只有一个User Information List表. ...
- block本质探寻三之block类型
一.oc代码 提示:看本文章之前,最好按顺序来看: //代码 void test1() { ; void(^block1)(void) = ^{ NSLog(@"block1----&quo ...
- iOS UITextField的代理<UITextFieldDelegate>的几点笔记
今天做项目的时候,有个需求,点击按钮,就在特定的编辑框输入按钮中的文字,一开始我还以C++的思想来写,先获取光标的位置,然后在判断是否在那个编辑框,进行输入.后来我旁边的同事看到了直接教我用代理方法, ...
- vue中使用codemirror
https://blog.csdn.net/oumaharuki/article/details/79268498 别人的记载,写的很不错,还有下载的方法 以下是自己使用过的,做出来的例子: 做出来 ...
- pci枚举初始化部分(1)
基于linux-4.20-rc3源码分析 1 .扫描所有PCI设备并检测,填充设备结构体 static struct pci_dev *pci_scan_device(struct pci_bus * ...
- PI接口开发之调java WS接口(转)
java提供的WSDL:http://XXX.XXX.XXX.XX/XXXXXXXcrm/ws/financialStatementsService?wsdl 登陆PI,下载Enterprise Se ...