Netty核心概念(7)之Java线程池
1.前言
本章本来要讲解Netty的线程模型的,但是由于其是基于Java线程池设计而封装的,所以我们先详细学习一下Java中的线程池的设计。之前也说过Netty5被放弃的原因之一就是forkjoin结构比较复杂,forkjoin也是JDK提供的一个基本线程模型,这里就不进行介绍。本节涉及知识点很多,可能有误,请对照JDK源码进行学习。
本章涉及的概念有Callable,Future,ExecutorService等,所有的类都在java.util.concurrent包下。
2.相关概念
2.1 Callable
学过Java的人都知道,在Java中运行线程任务有两个方法,一个是继承Thread类,覆写run方法,另一个就是实现Runnable接口,实现run方法。但是这两种方法都有一个尴尬的地方,其没有返回值,而通常我们使用异步模型,需要知道异步的任务的执行结果,虽然方法有很多,但是最简单的还是重新制造一个带返回值的接口,这个接口就是Callable。此接口就一个call()方法,返回一个结果。此外Thread只接受Runnable类,所以该接口是专门给线程池模型使用的。
2.2 Future

Future顾名思义,这个类的实例是从未来而来。异步模型,在主线程中提交任务到线程池中运行,得到执行后的结果,问题是主线程如何获取这个结果呢?这个时候就要靠这个来自未来的实例了。提交任务给异步线程时,会立刻得到一个Future对象,这个对象可以获得任务执行完成后的结果。明白了这个设定,就能很好的理解接口方法了。
cancel():取消掉这个任务,true时意味着运行中中断程序。实际上实现是办不到的,这个要自己实现的call方法做相应的取消实现,所以其正在的含义是改变Thread的状态成中断状态,具体中断处理逻辑要自己写在call或者run方法中。false则只是取消任务,不能对开始了的任务进行操作。
isCancelled():这个任务是否被取消
isDone():这个任务是否被完成
get():获取任务的执行结果,没完成就阻塞获取线程,在设置的时间内没获取到抛出TimeoutException。
2.3 ExecutorService
Java设计了很多种类型的线程模型,开发者可能扩展更多,为了有个统一的标准,就有了这个接口。

shutdown():关闭模型中所有的线程
isShutdown():是否已经关闭
isTerminated():所有的任务是否在shutdown之后终结了。
awaitTermination():等待任务结束。
submit():提交一个任务
invokeAll():执行所有的任务
invokeAny():执行所有的任务,其中一个完成就返回结果。
ExecutorService继承自Executor,其还有一个方法就是execute执行一个runnable任务。从这些接口方法,我们也可以清楚的认识到该类是对线程模型的一个基本使用的定义,提供了一个运用标准。
2.4 Executors
该类是一个具体的服务层的类了,给出所有JDK实现的线程模型的实例,方便开发者调用。该类的所有方法都是静态方法,静态工厂模式。
给出的方法有很多,但实际上只有三种类型的模型而已:1.线程池ThreadPoolExecutor;2.工作窃取算法实现的ForkJoinPool;3.周期任务线程池ScheduledThreadPoolExecutor;下面对这些方法进行简要说明。这里先简单介绍一下ThreadPoolExecutor的相关参数含义,才能更好的理解Executors提供的不同线程池的含义,具体参数如下:
corePoolSize:核心线程池的大小,可以理解为线程池中最小的线程数量。
maximumPoolSize:最大的线程数量
keepAliveTime:线程池线程数量超过core的设置后,线程最大的空闲时间,超过这个值且数量仍大于core会被销毁。
unit:keepAliveTime的单位
workQueue:任务的存储队列
threadFactory:创建线程时的工厂方法
handler:执行阻塞时处理类,当线程数达到最大,任务存储队列也满了,新提交的任务会触发该方法。
现在我们来看看几种和ThreadPoolExecutor相关的方法:
1.newFixedThreadPool(nThreads):
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
从参数可以看出,FixedThreadPool是一个可重用固定线程数的线程池,由于固定了线程数量,所以keepAliveTime参数无实际作用。其任务在LinkedBlockingQueue中,这是一个无边界的队列,所以handler无作用。
2.newSingleThreadExecutor():
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
可以看出,SingleThreadExecutor和FixedThreadPool参数基本一样,就是线程数量为1,keepAliveTime和handler参数不起作用。
3.newCachedThreadPool():
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
CachedThreadPool是一个无限制的线程池,其线程空闲1分钟就会被回收,SynchronousQueue在之前的博客中也介绍过:这里。这是个无容量的阻塞队列,有点像接力棒。由于线程池大小没有限制,所以实际上handler对该类也没有作用。
4.newScheduledThreadPool(int corePoolSize):
return new ScheduledThreadPoolExecutor(corePoolSize); super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
定时任务线程池是继承自ThreadPoolExecutor的,其能做到定时执行,归功于DelayedWorkQueue。这个队列功能和DelayQueue类似:这里,设计实现上与PriorityBlockingQueue队列相似:这里。这个线程池也是无边界的。
5.newSingleThreadScheduledExecutor():
return new DelegatedScheduledExecutorService
(new ScheduledThreadPoolExecutor(1));
这个和newSingleThreadExecutor一样,就是单线程的周期任务。
6.newWorkStealingPool():
return new ForkJoinPool
(Runtime.getRuntime().availableProcessors(),
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
ForkJoin的核心思想就是:将一个大任务切割成若干个小任务同时进行,最后等所有任务完成,合并任务结果。工作窃取算法是其的一种优化,比如有个线程执行完了其任务,另一个线程还有N个任务,这样等待就比较耗时,所以空闲的线程会从忙碌的线程处理的任务链尾端拿任务进行执行。
其它的不是线程模型相关的内容,值得一提的就只有RunnableAdapter了。
static final class RunnableAdapter<T> implements Callable<T> {
final Runnable task;
final T result;
RunnableAdapter(Runnable task, T result) {
this.task = task;
this.result = result;
}
public T call() {
task.run();
return result;
}
}
实现简单易懂,不再描述。
3. 实现细节
上面讲了线程池的一些基本概念,这里将对其实现过程进行解析,理解更深刻。上面的概念有两个地方没有说明清楚,一个是Future为什么能达到这种效果。另一个就是callable接口为什么能返回结果,我们知道Thread只接收Runnable接口实例,该方法即没有入参,又没有返回值,这是怎么做到的?带着这两个疑问,我们对ThreadPoolExecutor进行详细的介绍。
3.1 FutureTask
这个类是解决上诉问题的关键。其实现了Future和Runnable两个接口,是线程池使用的具体任务对象,控制着任务的相关执行。
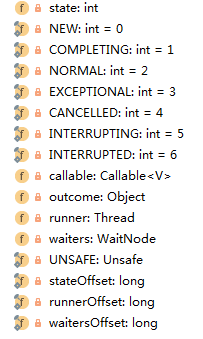
state:任务的状态。后面是其7种状态定义。
callable:需要执行的任务,如果是runnable会变成callable的适配器对象。
outcome:执行结果
runner:执行的线程
waiters:等待任务执行完成的线程
public boolean isCancelled() {
return state >= CANCELLED;
}
public boolean isDone() {
return state != NEW;
}
上面很清楚,状态就是由该类控制的。
public V get() throws InterruptedException, ExecutionException {
int s = state;
if (s <= COMPLETING)
s = awaitDone(false, 0L);
return report(s);
}
private int awaitDone(boolean timed, long nanos)
throws InterruptedException {
final long deadline = timed ? System.nanoTime() + nanos : 0L;
WaitNode q = null;
boolean queued = false;
for (;;) {
if (Thread.interrupted()) {
removeWaiter(q);
throw new InterruptedException();
}
int s = state;
if (s > COMPLETING) {
if (q != null)
q.thread = null;
return s;
}
else if (s == COMPLETING) // cannot time out yet
Thread.yield();
else if (q == null)
q = new WaitNode();
else if (!queued)
queued = UNSAFE.compareAndSwapObject(this, waitersOffset,
q.next = waiters, q);
else if (timed) {
nanos = deadline - System.nanoTime();
if (nanos <= 0L) {
removeWaiter(q);
return state;
}
LockSupport.parkNanos(this, nanos);
}
else
LockSupport.park(this);
}
}
这里就get方法的逻辑:1.判断线程是否中断,中断移除无效等待节点;2.如果完成了,返回;3.如果进行中,让出时间片;4.如果无等待者,将此线程设置成waiter;5.如果没添加到task的等待节点中,添加进去;6.如果有超时设置,超时了移除等待,否则等待。7.阻塞等待执行完成。
简要的说一下上述过程就是根据state判断是立刻返回还是阻塞等待,等待后将其设置成等待节点。最后我们需要关心的就是run方法了。
public void run() {
if (state != NEW ||
!UNSAFE.compareAndSwapObject(this, runnerOffset,
null, Thread.currentThread()))
return;
try {
Callable<V> c = callable;
if (c != null && state == NEW) {
V result;
boolean ran;
try {
result = c.call();
ran = true;
} catch (Throwable ex) {
result = null;
ran = false;
setException(ex);
}
if (ran)
set(result);
}
} finally {
// runner must be non-null until state is settled to
// prevent concurrent calls to run()
runner = null;
// state must be re-read after nulling runner to prevent
// leaked interrupts
int s = state;
if (s >= INTERRUPTING)
handlePossibleCancellationInterrupt(s);
}
}
判断状态,执行callable的call方法,获取返回值。这里可能会有个疑问,runnable接口是怎么返回结果的呢?答案是runnable方法不能返回结果,但是可以通过RunnableAdapter传入一个默认的结果,在runnable任务结束时就能获取这个结果了。上面的问题2实际上要说明的就是没有其他方法对一个既没有入参,又没有出参的方法进行返回,最好的方法就是对其包装一层,通过包装的局部变量返回执行结果。FutureTask就是这么做的,最后看下任务完成后执行的方法。
private void finishCompletion() {
// assert state > COMPLETING;
for (WaitNode q; (q = waiters) != null;) {
if (UNSAFE.compareAndSwapObject(this, waitersOffset, q, null)) {
for (;;) {
Thread t = q.thread;
if (t != null) {
q.thread = null;
LockSupport.unpark(t);
}
WaitNode next = q.next;
if (next == null)
break;
q.next = null; // unlink to help gc
q = next;
}
break;
}
}
done();
callable = null; // to reduce footprint
}
这里就能够看出,在get操作任务未完成时,get线程阻塞,并且将阻塞线程添加到任务的waiter队列中。任务实际完成后,会释放锁,这就达到通知线程任务完成的效果了。
3.2 AbstractExecutorService
线程池的任务定义,通知任务完成的实现原理等了解完了,现在再来看下线程池是如何实现的吧。该类为抽象父类,没有做核心的操作,关键的execute方法没有实现,实现了其它通用逻辑的方法。简略看下就可以明白了:
public <T> Future<T> submit(Callable<T> task) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task);
execute(ftask);
return ftask;
}
private <T> T doInvokeAny(Collection<? extends Callable<T>> tasks,
boolean timed, long nanos)
throws InterruptedException, ExecutionException, TimeoutException {
if (tasks == null)
throw new NullPointerException();
int ntasks = tasks.size();
if (ntasks == 0)
throw new IllegalArgumentException();
ArrayList<Future<T>> futures = new ArrayList<Future<T>>(ntasks);
ExecutorCompletionService<T> ecs =
new ExecutorCompletionService<T>(this);
// For efficiency, especially in executors with limited
// parallelism, check to see if previously submitted tasks are
// done before submitting more of them. This interleaving
// plus the exception mechanics account for messiness of main
// loop.
try {
// Record exceptions so that if we fail to obtain any
// result, we can throw the last exception we got.
ExecutionException ee = null;
final long deadline = timed ? System.nanoTime() + nanos : 0L;
Iterator<? extends Callable<T>> it = tasks.iterator();
// Start one task for sure; the rest incrementally
futures.add(ecs.submit(it.next()));
--ntasks;
int active = 1;
for (;;) {
Future<T> f = ecs.poll();
if (f == null) {
if (ntasks > 0) {
--ntasks;
futures.add(ecs.submit(it.next()));
++active;
}
else if (active == 0)
break;
else if (timed) {
f = ecs.poll(nanos, TimeUnit.NANOSECONDS);
if (f == null)
throw new TimeoutException();
nanos = deadline - System.nanoTime();
}
else
f = ecs.take();
}
if (f != null) {
--active;
try {
return f.get();
} catch (ExecutionException eex) {
ee = eex;
} catch (RuntimeException rex) {
ee = new ExecutionException(rex);
}
}
}
if (ee == null)
ee = new ExecutionException();
throw ee;
} finally {
for (int i = 0, size = futures.size(); i < size; i++)
futures.get(i).cancel(true);
}
}
这里就能看出提交的任务都被包装成FutureTask任务了。invokeAll方法就是包装所有的任务,遍历调用execute方法。invokeAny最终也是相似的操作。
3.3 ThreadPoolExecutor
抽象父类的作用不多,这里我们看ThreadPoolExecutor是如何管理线程池,进行调度的吧。ThreadPoolExecutor的策略如下:
1、当有一个新任务提交时,只要当前线程数少于corePoolSize,哪怕有空闲的线程,其也会创建一个新的线程给新任务使用。
2、corePoolSize<X<maxSize的时候,只有队列满了才会创建线程。
3、只有有任务到来时才会创建线程,哪怕是corePoolSize也不是立刻初始化。
4、创建线程失败,执行器也会继续下去,但是任务不会被执行
5、根据上面的说明,无界的队列会导致线程数达到corePoolSize就不再增长,因为队列永远不会满
6、有界队列可以防止资源耗尽,但是更难正确和控制。

workQueue:任务队列
mainLock:主要的锁
worker:工作者,运行中线程
termination:终止信号
其他的就不一一介绍了,都是之前提到过的参数。这里直接看最重要的execute方法实现。
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}
源码注释说明了这段操作,一共有3个步骤:
1.如果运行中的线程数小于corePoolSize的数量,创建一个新的线程,该任务作为其第一个任务。addWorker会检查池的状态和工作线程数量,不满足条件就会返回false。
2.如果一个任务成功的放入队列,再次检查状态,如果池停止了,就会拒绝该任务,且移除该任务,否则触发方法,请求分配worker。
3.如果不能放入队列,尝试创建一个线程,如果失败,就拒绝该任务。
可以说思路其实是很清晰的,但是实际上操作却不容易,具体细节就不说明了。接下来看下Worker是如何工作的:
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
while (task != null || (task = getTask()) != null) {
w.lock();
// If pool is stopping, ensure thread is interrupted;
// if not, ensure thread is not interrupted. This
// requires a recheck in second case to deal with
// shutdownNow race while clearing interrupt
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
beforeExecute(wt, task);
Throwable thrown = null;
try {
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
worker也是一个runnable方法,不同的是其继承了AbstractQueuedSynchronizer,该类是Java并发包的一个重点。创建worker对象的时候就初始化了线程设置,只等addWorker()方法调用start()。运行过程判断有没有任务,有任务锁住线程,然后运行任务。这里都有不同的扩展点给开发者进行业务扩展。完成任务后,在运行中的线程集合中,移除它。这里可能会疑惑,运行完后线程被移除了,怎么继续执行的任务。
首先,runWorker中task为null的时候会getTask,从任务队列中获取任务。
其次,execute方法判断了当前池的状态决定是否添加worker。
然后,最重要的是runWorker方法要结束必须是没有任务,那里有个while循环。
最后,该worker被移除,检测corePoolSize和线程池当前状态决定是否添加线程。
这里又可能会有疑惑了,不是说好的空闲超时才移除吗?这段逻辑其实就在getTask中,如果getTask在指定时间内都没有获取任务,不就意味着线程空闲了这么久吗,所以执行到最后直接移除就可以了。最后我们看下Java的线程池是如何关闭的,这对后面理解Netty的优雅停机有帮助。
public void shutdown() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
advanceRunState(SHUTDOWN);
interruptIdleWorkers();
onShutdown(); // hook for ScheduledThreadPoolExecutor
} finally {
mainLock.unlock();
}
tryTerminate();
}
先解决权限问题,再设置状态为shutdown,这样保证新任务不会再提交进线程池。接着对所有运行中的worker发起中断信号,最后尝试停机,唤醒awaitTermination的线程。所以说所谓的shutdown,并不保证任务执行完毕,只是阻止新任务进来,还需要任务自身配合中断信号。这个是必然的,因为没人知道你的任务干了什么,万一是个死循环,不直接销毁线程,如何能停止它?
最后我们聊聊AbstractQueuedSynchronizer,每一个worker都是该类实例,这个类究竟达成了一个怎样的目的?详细介绍看这篇文章:这里。下面是Worker中实现的相关代码:
protected boolean isHeldExclusively() {
return getState() != 0;
}
protected boolean tryAcquire(int unused) {
if (compareAndSetState(0, 1)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
protected boolean tryRelease(int unused) {
setExclusiveOwnerThread(null);
setState(0);
return true;
}
public void lock() { acquire(1); }
public boolean tryLock() { return tryAcquire(1); }
public void unlock() { release(1); }
public boolean isLocked() { return isHeldExclusively(); }
void interruptIfStarted() {
Thread t;
if (getState() >= 0 && (t = thread) != null && !t.isInterrupted()) {
try {
t.interrupt();
} catch (SecurityException ignore) {
}
}
}
根据文章中所介绍的:
- tryAcquire:独占式获取同步状态。获取时设置状态为1。
- isHeldExclusively: AQS是否被当前线程独占。不为0独占。
- tryRelease:独占式释放同步状态。设置状态为0,释放锁。
所以worker类实际上是一个排他锁,只允许一个线程操作。
4 后记
本章主要介绍了Java线程池的执行过程,Future的实现方式,整个过程可用下图表示:
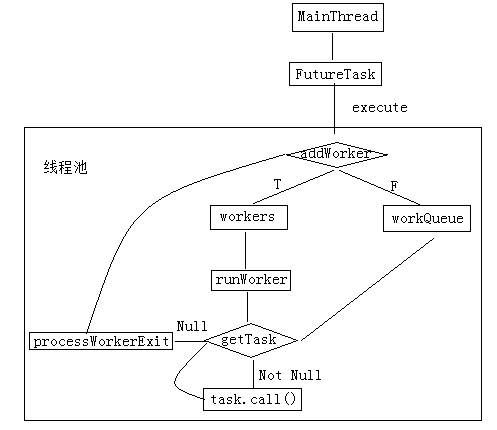
再提一下FutureTask,其call执行完就会解锁,get就能知道是否执行完毕了。大体的过程就是上图,实现细节就不在此讨论。
Netty核心概念(7)之Java线程池的更多相关文章
- Netty核心概念(8)之Netty线程模型
1.前言 第7节初步学习了一下Java原本的线程池是如何工作的,以及Future的为什么能够达到其效果,这些知识对于理解本章有很大的帮助,不了解的可以先看上一节. Netty为什么会高效?回答就是良好 ...
- Java线程池的使用方式,核心运行原理、以及注意事项
为什么需要线程池 java中为了提高并发度,可以使用多线程共同执行,但是如果有大量线程短时间之内被创建和销毁,会占用大量的系统时间,影响系统效率. 为了解决上面的问题,java中引入了线程池,可以使创 ...
- 并发编程系列:Java线程池的使用方式,核心运行原理、以及注意事项
并发编程系列: 高并发编程系列:4种常用Java线程锁的特点,性能比较.使用场景 线程池的缘由 java中为了提高并发度,可以使用多线程共同执行,但是如果有大量线程短时间之内被创建和销毁,会占用大量的 ...
- Java线程池中的核心线程是如何被重复利用的?
真的!讲得太清楚了!https://blog.csdn.net/MingHuang2017/article/details/79571529 真的是解惑了 本文所说的"核心线程". ...
- Java 线程池框架核心代码分析--转
原文地址:http://www.codeceo.com/article/java-thread-pool-kernal.html 前言 多线程编程中,为每个任务分配一个线程是不现实的,线程创建的开销和 ...
- Java 线程池框架核心代码分析
前言 多线程编程中,为每个任务分配一个线程是不现实的,线程创建的开销和资源消耗都是很高的.线程池应运而生,成为我们管理线程的利器.Java 通过Executor接口,提供了一种标准的方法将任务的提交过 ...
- java线程池技术(二): 核心ThreadPoolExecutor介绍
版权声明:本文出自汪磊的博客,转载请务必注明出处. Java线程池技术属于比较"古老"而又比较基础的技术了,本篇博客主要作用是个人技术梳理,没什么新玩意. 一.Java线程池技术的 ...
- Java线程池二:线程池原理
最近精读Netty源码,读到NioEventLoop部分的时候,发现对Java线程&线程池有些概念还有困惑, 所以深入总结一下 Java线程池一:线程基础 为什么需要使用线程池 Java线程映 ...
- 【java线程系列】java线程系列之java线程池详解
一线程池的概念及为何需要线程池: 我们知道当我们自己创建一个线程时如果该线程执行完任务后就进入死亡状态,这样如果我们需要在次使用一个线程时得重新创建一个线程,但是线程的创建是要付出一定的代价的,如果在 ...
随机推荐
- Excel获得焦点变色
1. 点击 Sheet 2. 右键菜单 查看代码 3. 复制如下代码 Private Sub Worksheet_SelectionChange(ByVal Target As Excel.Ran ...
- Windows 下安装mysql总结
1.配置环境变量 将安装目录添加到系统路径 我的电脑->属性->高级->环境变量->path 2.修改my.ini 位于解压安装目录下 在其中修改或添加配置: [mysqld] ...
- python面向对象-2深入类的属性
在交互式环境中输入: >>> class A: a=0 def __init__(self): self.a=10 self.b=100 >>> a=A() > ...
- 超全table功能Datatables使用的填坑之旅--2:post 动态传参: 解决: ajax 传参无值问题.
官网解释与方法:1 当向服务器发出一个ajax请求,Datatables将会把服务器请求到的数据构造成一个数据对象. 2 实际上他是参考jQuery的ajax.data属性来的,他能添加额外的参数传给 ...
- Java 注解概要
转载自:https://www.cnblogs.com/peida/archive/2013/04/24/3036689.html(Java注解就跟C#的特性是一样的) 要深入学习注解,我们就必须能定 ...
- 关于RabbitMQ一点
RabbitMQ是AMQP(高级消息队列协议)的标准实现,理论上可以保证消息发送的准确性 RabbitMQ是用Erlang语言编写的,而Erlang语言具有以下特点: 并发性--Erlang支持超大量 ...
- Informatica bulk和normal模式
转载:http://bestxiaok.iteye.com/blog/1107612 Bulk 方式进行目标数据的Load,是Informatica提供的一种高性能的Load数据方式.它利用数据库底层 ...
- 五、搭建kube-dns
1. 简介 kube-dns用来为kubernetes service分配子域名,在集群中可以通过名称访问service.通常kube-dns会为service赋予一个名为"servic ...
- 微信公众平台如何与Web App结合?
Web App简而言之就是为移动平台而优化的网页,它可以表现得和原生应用一样,并且克服了原生应用一些固有的缺点.一般而言Web App最大的入口是浏览器,但现在微信公众平台作为新兴的平台,结合其内置浏 ...
- 一般处理程序获取Layui上传的图片
asp.net利用一般处理程序获取用户上传的图片,上传图片利用的layui 前台页面 <%@ Page Language="C#" AutoEventWireup=" ...