bm25
BM25算法,通常用来作搜索相关性平分。一句话概况其主要思想:对Query进行语素解析,生成语素qi;然后,对于每个搜索结果D,计算每个语素qi与D的相关性得分,最后,将qi相对于D的相关性得分进行加权求和,从而得到Query与D的相关性得分。
BM25算法的一般性公式如下:
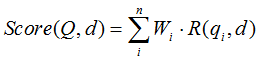
其中,Q表示Query,qi表示Q解析之后的一个语素(对中文而言,我们可以把对Query的分词作为语素分析,每个词看成语素qi。);d表示一个搜索结果文档;Wi表示语素qi的权重;R(qi,d)表示语素qi与文档d的相关性得分。
下面我们来看如何定义Wi。判断一个词与一个文档的相关性的权重,方法有多种,较常用的是IDF。这里以IDF为例,公式如下:
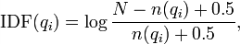
其中,N为索引中的全部文档数,n(qi)为包含了qi的文档数。
根据IDF的定义可以看出,对于给定的文档集合,包含了qi的文档数越多,qi的权重则越低。也就是说,当很多文档都包含了qi时,qi的区分度就不高,因此使用qi来判断相关性时的重要度就较低。
我们再来看语素qi与文档d的相关性得分R(qi,d)。首先来看BM25中相关性得分的一般形式:
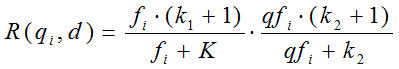
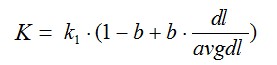
其中,k1,k2,b为调节因子,通常根据经验设置,一般k1=2,b=0.75;fi为qi在d中的出现频率,qfi为qi在Query中的出现频率。dl为文档d的长度,avgdl为所有文档的平均长度。由于绝大部分情况下,qi在Query中只会出现一次,即qfi=1,因此公式可以简化为:
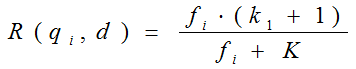
从K的定义中可以看到,参数b的作用是调整文档长度对相关性影响的大小。b越大,文档长度的对相关性得分的影响越大,反之越小。而文档的相对长度越长,K值将越大,则相关性得分会越小。这可以理解为,当文档较长时,包含qi的机会越大,因此,同等fi的情况下,长文档与qi的相关性应该比短文档与qi的相关性弱。
综上,BM25算法的相关性得分公式可总结为:
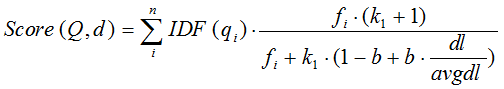
从BM25的公式可以看到,通过使用不同的语素分析方法、语素权重判定方法,以及语素与文档的相关性判定方法,我们可以衍生出不同的搜索相关性得分计算方法,这就为我们设计算法提供了较大的灵活性。
原文地址:http://ipie.blogbus.com/logs/104136815.html
bm25的更多相关文章
- BM25相关度打分公式
BM25算法是一种常见用来做相关度打分的公式,思路比较简单,主要就是计算一个query里面所有词和文档的相关度,然后在把分数做累加操作,而每个词的相关度分数主要还是受到tf/idf的影响.公式如下: ...
- 概率检索模型及BM25
概率排序原理 以往的向量空间模型是将query和文档使用向量表示然后计算其内容相似性来进行相关性估计的,而概率检索模型是一种直接对用户需求进行相关性的建模方法,一个query进来,将所有的文档分为两类 ...
- BM25和Lucene Default Similarity比较 (原文标题:BM25 vs Lucene Default Similarity)
原文链接: https://www.elastic.co/blog/found-bm-vs-lucene-default-similarity 原文 By Konrad Beiske 翻译 By 高家 ...
- 文本相似度 — TF-IDF和BM25算法
1,$TF-IDF$算法 $TF$是指归一化后的词频,$IDF$是指逆文档频率.给定一个文档集合$D$,有$d_1, d_2, d_3, ......, d_n \in D$.文档集合总共包含$m$个 ...
- 文本相似度-BM25算法
BM25 is a bag-of-words retrieval function that ranks a set of documents based on the query terms app ...
- 概率检索模型:BIM+BM25+BM25F
1. 概率排序原理 以往的向量空间模型是将query和文档使用向量表示然后计算其内容相似性来进行相关性估计的,而概率检索模型是一种直接对用户需求进行相关性的建模方法,一个query进来,将所有的文档分 ...
- BM25 调参调研
1. 搜索 ES 计算文本相似度用的 BM25,参数默认,不适合电商场景,可调整 BM25 参数使其适用于电商短文本场景 2. k1.b.tf.L.tfScore 的关系如下图红框内所示(注:这里的 ...
- Solr相似度算法二:Okapi BM25
地址:https://en.wikipedia.org/wiki/Okapi_BM25 In information retrieval, Okapi BM25 (BM stands for Be ...
- 相关度算法BM25
BM25算法,通常用来作搜索相关性平分.一句话概况其主要思想:对Query进行语素解析,生成语素qi:然后,对于每个搜索结果D,计算每个语素qi与D的相关性得分,最后,将qi相对于D的相关性得分进行加 ...
随机推荐
- poj 1459 Power Network【建立超级源点,超级汇点】
Power Network Time Limit: 2000MS Memory Limit: 32768K Total Submissions: 25514 Accepted: 13287 D ...
- jquery判断文本域长度
<div id="result">您还可以输入100字</div> <textarea name="content" id=&qu ...
- 用Windbg来看看CLR的JIT是什么时候发生的
博客搬到了fresky.github.io - Dawei XU,请各位看官挪步.最新的一篇是:用Windbg来看看CLR的JIT是什么时候发生的.
- 针对C#程序做性能测试的一些基本准则
博客搬到了fresky.github.io - Dawei XU,请各位看官挪步.最新的一篇是:针对C#程序做性能测试的一些基本准则.
- 安装、配置JDK的步骤
1.配置环境变量,打开我的电脑--属性--高级--环境变量,新建系统变量JAVA_HOME .变量值:jdk的目录,比如d:/java.选择“系统变量”中变量名为“Path”的环境变量双击该变量,把J ...
- bootstrap-table对前台页面表格的支持
1.bootstrap-table是在bootstrap的基础上面做了一些封装,所以在使用bootstrap-table之前要导入的js和css有 1)基本的还是jQuery <script t ...
- PowerShell运行cmd命令
1.使用.exe扩展名 2.使用 cmd /c "" 3.在 PowerShell v3 中有另一种选择来解决这个问题,只需在命令行的任意位置添加 –% 序列(两个短划线和一个百分 ...
- nginx模块编程之获取客户ip及端口号
ngx_request_t结构体中有一个connection定义,该定义指向一个ngx_connection_t的结构体: 结构体定义如下: struct ngx_connection_s { voi ...
- Android软键盘调用及隐藏,以及获得点击软键盘输入的字母信息
在Android提供的EditText中单击的时候,会自动的弹出软键盘,其实对于软键盘的控制我们可以通过InputMethodManager这个类来实现.我们需要控制软键盘的方式就是两种一个是像Edi ...
- java24 手写服务器最终版本
手写服务器最终版本; <?xml version="1.0" encoding="UTF-8"?> <web-app> <serv ...