网络爬虫BeautifulSoup库的使用
使用BeautifulSoup库提取HTML页面信息

#!/usr/bin/python3
import requests
from bs4 import BeautifulSoup url='http://python123.io/ws/demo.html'
r=requests.get(url)
if r.status_code==:
print('网络请求成功') demo=r.text
soup=BeautifulSoup(demo,'html.parser')
print(soup.prettify())
BeautifulSoup类的基本属性

#!/usr/bin/python3
import requests
from bs4 import BeautifulSoup url='http://python123.io/ws/demo.html'
r=requests.get(url)
if r.status_code==:
print('网络请求成功') demo=r.text
soup=BeautifulSoup(demo,'html.parser')
tag_title=soup.title
print(tag_title)
tag_a_attrs=soup.a.attrs
print(soup.p.string)
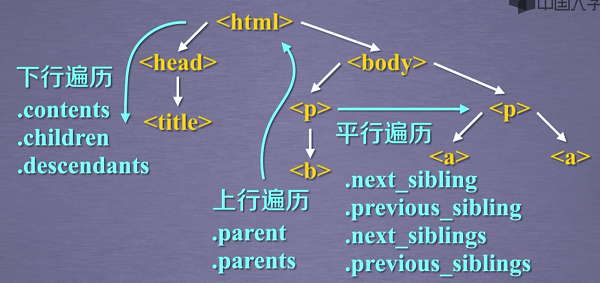
标签树的下行遍历
#!/usr/bin/python3
import requests
from bs4 import BeautifulSoup url='http://python123.io/ws/demo.html'
r=requests.get(url)
if r.status_code==200:
print('网络请求成功') demo=r.text
soup=BeautifulSoup(demo,'html.parser') print(soup.prettify())
print('我是分割线'.center(80,'-'))
#遍历子节点 for child in soup.body.children:
print(child)
#遍历子孙节点
for descendant in soup.body.descendants:
print(descendant)
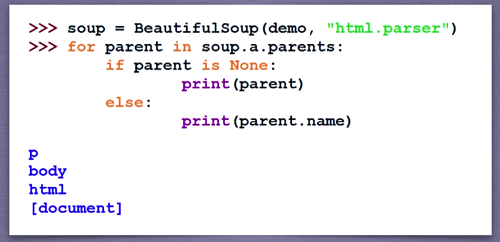
标签树的上行遍历

遍历title标签的上一级标签
print(soup.title.parent)
#a标签的下一标签
print(soup.a.next_sibling)
遍历a标签的所有前序节点以及后续节点
#遍历a标签的前序节点
for sibling in soup.a.next_siblings:
print(sibling)
#遍历a标签的前序节点
for sibling in soup.a.previous_siblings:
print(sibling)
soup标签的上一级标签为空,所以要进行判断
网络爬虫BeautifulSoup库的使用的更多相关文章
- Python爬虫-- BeautifulSoup库
BeautifulSoup库 beautifulsoup就是一个非常强大的工具,爬虫利器.一个灵活又方便的网页解析库,处理高效,支持多种解析器.利用它就不用编写正则表达式也能方便的实现网页信息的抓取 ...
- 2.03_01_Python网络爬虫urllib2库
一:urllib2库的基本使用 所谓网页抓取,就是把URL地址中指定的网络资源从网络流中抓取出来.在Python中有很多库可以用来抓取网页,我们先学习urllib2. urllib2 是 Python ...
- Python网络爬虫——BeautifulSoup4库的使用
使用requests库获取html页面并将其转换成字符串之后,需要进一步解析html页面格式,提取有用信息. BeautifulSoup4库,也被成为bs4库(后皆采用简写)用于解析和处理html和x ...
- [爬虫] BeautifulSoup库
Beautiful Soup库基础知识 Beautiful Soup库是解析xml和html的功能库.html.xml大都是一对一对的标签构成,所以Beautiful Soup库是解析.遍历.维护“标 ...
- python爬虫BeautifulSoup库class_
因为class是python的关键字,所以在写过滤的时候,应该是这样写: r = requests.get(web_url, headers=headers) # 向目标url地址发送get请求,返回 ...
- 网络爬虫--requests库中两个重要的对象
当我们使用resquests.get()时,返回的时response的对象,他包含服务器返回的所有信息,也包含请求的request的信息. 首先: response对象的属性有以下几个, r.stat ...
- 网络爬虫必备知识之urllib库
就库的范围,个人认为网络爬虫必备库知识包括urllib.requests.re.BeautifulSoup.concurrent.futures,接下来将结合爬虫示例分别对urllib库的使用方法进行 ...
- 网络爬虫必备知识之requests库
就库的范围,个人认为网络爬虫必备库知识包括urllib.requests.re.BeautifulSoup.concurrent.futures,接下来将结对requests库的使用方法进行总结 1. ...
- 网络爬虫必备知识之concurrent.futures库
就库的范围,个人认为网络爬虫必备库知识包括urllib.requests.re.BeautifulSoup.concurrent.futures,接下来将结对concurrent.futures库的使 ...
随机推荐
- CSharpGL(49)试水OpenGL软实现
CSharpGL(49)试水OpenGL软实现 CSharpGL迎来了第49篇.本篇内容是用C#编写一个OpenGL的软实现.暂且将其命名为SoftGL. 目前已经实现了由Vertex Shader和 ...
- Android中一个经典理解误区的剖析
今天,在Q群中有网友(@广州-包晴天)发出了网上的一个相对经典的问题,问题具体见下图. 本来是无意写此文的,但群里多个网友热情不好推却,于是,撰此文予以分析. 从这个问题的陈述中,我们发现,提问者明显 ...
- 通过 React Hooks 声明式地使用 setInterval
本文由云+社区发表 作者:Dan Abramov 接触 React Hooks 一定时间的你,也许会碰到一个神奇的问题: setInterval 用起来没你想的简单. Ryan Florence 在他 ...
- 第1章 发现端点(Discovery Endpoint) - IdentityModel 中文文档(v1.0.0)
OpenID Connect发现端点的客户端库作为httpclient的扩展方法提供.该GetDiscoveryDocumentAsync方法返回一个DiscoveryResponse对象,该对象具有 ...
- 【swoole】使用swoole简单实现TCP服务
上一篇写到了如何在windows系统上面利用docker快速搭建swoole开发环境,接下来体验下swoole的使用 使用swoole实现tcp服务 <?php $serv = new Swoo ...
- JS 实现的年月日三级联动
js文件 SYT="-请选择年份-"; SMT="-请选择月份-"; SDT="-请选择日期-"; BYN=50;//年份范围往前50年 A ...
- vue学习笔记4
父组件向子组件传值 组件实例定义方式,注意:一定要使用props属性来定义父组件传递过来的数据 <script> // 创建 Vue 实例,得到 ViewModel var vm = ne ...
- 如何优雅的使用 参数 is null而不导致全表扫描(破坏索引)
相信大家在很多实际业务中(特别是后台系统)会使用到各种筛选条件来筛选结果集 首先添加测试数据 ), Age INT) go CREATE INDEX idx_age ON TempList (Age) ...
- pgsql sql 统计整理
字符字段转整型查询: SELECT mon_id as staTime,SUM (CAST ( index_value AS INT )) AS totalCount FROM aidata.rep_ ...
- 客户端和服务端(C#) 时间戳的生成和转换
C# DateTime与时间戳的相互转换,包括JavaScript时间戳和Unix的时间戳. 1. 什么是时间戳 首先要清楚JavaScript与Unix的时间戳的区别: JavaScript时间戳: ...