Mongodb基础与入门
一:基本了解
1. 特点
基于分布式文件存储的NoSql数据库。能为WEB应用提供可扩展的高性能数据存储解决方案。
将数据存储为一个文档,数据结构由键值对组成。文档类似于JSON对象。字段值可以包含其他文档,数组以及文档数组。
2. 启动HTTP用户界面,需指定参数--rest $ ./mongod --dbpath=/data/db --rest 【Web界面访问端口比服务端口多1000】
3. 基本概念:文档,集合,数据库
数据库:database 数据表/集合:collection 数据记录行/文档:document
数据字段/域:field 索引:index 主键:primary key 自动将_id字段设为主键
不支持表链接
4. 一个mongodb可建立多个数据库。默认数据库为db(存储在data目录中),MongoDB的单个实例可以容纳多个独立的数据库,每一个都有自己的集合和权限,不同的数据库也放置在不同的文件中。
二:基础命令
1. 命令
显示所有数据库列表:show dbs
显示当前数据库集合或对象:db
连接到指定数据库:use 数据库名
数据库可通过名字标识。数据库名可以是满足以下条件的任意UTF-8字符串。
(1)不能是空字符串( " " )
(2)不能含有空格,点(.),$,/,\和\0 (空字符)
(3)全部为小写
(4)最多为64字节
特殊数据库:
(1)admin
权限上这是root数据库。若添加一个用户则此用户自动继承所有数据库的权限
(2)local
永远不会被复制的数据库。可以用来存储限于本地单台服务器的任意集合
(3)config
当Mongo用于分片设置时,在内部使用,用于保存分片的相关信息。
2. 文档
一组键值对(即BSON)。
不需要设置相同的字段,且相同的字段不需要相同的数据类型。
注意:
(1)键值对是有序的
(2)值不仅可以是字符串,还可以是其他几种数据类型
(3)区分类型和大小写
(4)不能有重复的键
(5)键一般为任意UTF-8字符串
键命名规范:
(1)不能含有空字符\0,???这个字符用来表示键的结尾。
(2).和$有特殊意义,只能在特定环境下使用
(3)???以下划线 "_" 开头的键是保留的
3. 集合
文档组,类似于表格。
存储在数据库中,没有固定的结构。可插入不同格式和类型的数据,但通常插入集合的数据会有一定的关联性
插入第一个文档时,集合就会被创建
集合命名规范:
(1)不能是空字符串
(2)不能含有空字符\0,???这个字符用来表示集合名的结尾。
(3)不能以 "system."开头,这是为系统保留的前缀
(4)不能含有保留字符。访问系统创建的集合需要在名字里出现 $
4. capped collections
有很高的性能以及队列过期的特性(过期按照插入的顺序)
是高性能自动的维护对象的插入顺序。适合类似记录日志功能
需显示创建并指定一个collection的大小(包含了数据的头信息),单位为字节。collection的数据存储空间值提前分配
注意:
可添加新的对象,但对象不会增加存储空间
可进行更新,如果新添的对象增加存储空间,更新失败
不允许进行删除。drop()删除collection所有的行【删除后须显示的重新创建这个collection】
在32bit机器中,最大存储为1e9( 1X109)个字节。
5. 元数据
数据库的信息是存储在集合中的。使用系统的命名空间:dbname.system.*
dbname.system.* 是包含多种系统信息的特殊集合。例: dbname.system.namespaces 列出所有名字的空间
dbname.system.indexes 列出所有索引
dbname.system.profile 包含数据库概要(profile)信息
dbname.system.uses 列出所有可访问数据库的用户
dbname.local.sources 包含复制对端(slave)的服务器信息和状态
注意:修改系统集合的对象限制
在{{system.indexes}}插入数据,可以创建索引。但除此之外该表信息是不可变的(特殊的drop index命令将自动更新相关信息)。
{{system.users}}是可修改的。 {{system.profile}}是可删除的。
6.常用数据类型
String:UTF-8 编码的字符串,存储数据常用的数据类型
Integer:存储数值
Boolean:存储布尔值
Double:存储(双精度)浮点值
Min/Max keys:将一个值与 BSON(二进制的 JSON)元素的最低值和最高值相对比。
Arrays:将数组或列表或多个值存储为一个键
Timestamp:时间戳,记录文档修改或添加时间
Object:用于内嵌文档
Null:创建空值
Symbol:采用特殊符号类型
Date:使用UNIX时间格式存储当前日期或时间,可自己指定
Object ID:创建文档的ID
Binary Data:存储二进制数据
Code:用于在文档中存储JavaScript代码
Regular expression:存储正则表达式
7. 连接[Mongodb Shell 连接]
连接语法:
mongodb://[username:password@] host1 [:port1] [, host2 [:port2]] [/[database] [?options] ]
PS:
mongodb:// 固定格式,必须指定
[username:password@] 如果设置,在连接数据库服务器之后,驱动都会尝试登陆这个数据库
host1 至少指定一个host[要连接的服务器的地址],如果连接复制集,请指定多个主机地址
portX 可选的指定端口,默认为27017
/database 如果指定username:password@,连接并验证登陆指定数据库。若不指定,默认打开admin数据库。
?options 如果不使用/database,则前面需要加上/。所有连接选项都是键值对name=value,键值对之间通过&或;(分号)隔开
例:
replicaSet = name
slaveOk = true | false
safe = true | false
w = n
wtimeoutMS = ms
fsync = true | false
journal = true | false
connectTimeoutMS = ms
socketTimeoutMS = ms
8. 操作
创建数据库语法格式:
use 数据库名 如果不存在则创建数据库,否则切换到指定数据库
删除数据库语法格式:
db.dropDatabase() 删除当前数据库,默认为test 可使用 db 命令查看当前数据库名
插入文档语法格式:[ 使用 insert() 或 save() 方法向集合中插入文档]
db.COLLECTION_NAME.insert(document)
db.col.save(document) 不指定_id字段,save() 类似于insert() 指定则会更新该_id的数据
更新文档语法格式:[使用 update() 和 save() 方法来更新集合中的文档。update() 用于更新已存在的文档,save() 通过传入的文档来替换已有的文档]
db.collection.update{
<query>,
<update>,
{
update:<boolean>
multi:<boolean>
writeConcern:<document>
}
}
参数说明:
query:update的查询条件,类似sql update查询内where后面的。
update:update的对象和一些更新的操作符(如$,$inc...)等,也可以理解为sql update查询内set后面的
upsert:如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。
multi:mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。
writeConcern:抛出异常的级别。
db.collection.save{
<document>,
{
writeConcern:<document>
}
}
参数说明:
document:文档数据
writeConcern:抛出异常的级别
删除文档语法格式:【在执行remove()函数前先执行find()命令来判断执行的条件是否正确,这是一个比较好的习惯。】
db.collection.remove{
<query>,
<justOne>
}
2.6版本之后:
db.collection.remove{
<query>,
{
justOne:<boolean>,
writeConcern:<document>
}
}
参数说明:
query:删除的文档的条件。
justOne:如果设为 true 或 1,则只删除一个文档。
writeConcern:抛出异常的级别。
删除全部:
db.col.remove( { } )
db.col.find( )
查询文档语法格式:【find() 以非结构化的方式显示所有文档,findOne() 只返回一个文档】
db.collection.find(query,projection)
参数说明:
query:使用查询操作符指定查询条件
projection:使用投影操作符指定返回的键。查询时返回文档中所有键值, 只需省略该参数即可(默认省略)
易读方式读取数据:db.col.find().pretty()
pretty():以格式化的方式显示所有文档
例:db.col.find().pretty() 以易读的方式读取数据
条件操作符:
1. where
等于
格式: {<key> : <value>}
例:db.col.find( {"by" : "兔兔"} ).pretty()
小于【 lt -- less than 】
格式: {<key> : {$lt : <value>} }
例:db.col.find( {"by" : {$lt : 50} } ).pretty()
小于等于【 lte -- less than equal】
格式: {<key> : {$lte : <value>} }
例:db.col.find( {"by" : {$lte : 50} } ).pretty()
大于【 gt -- greater than 】
格式: {<key> : {$gt : <value>} }
例:db.col.find( {"by" : {$gt : 50} } ).pretty()
大于等于【 gte -- greater than equal】
格式: {<key> : {$gte : <value>} }
例:db.col.find( {"by" : {$gte : 50} } ).pretty()
不等于【 ne -- not equal 】
格式: {<key> : {$ne : <value>} }
例:db.col.find( {"by" : {$ne : 50}} ).pretty()
2. and
find() 方法可以传入多个键(key),每个键(key)以逗号隔开
格式:
db.col.find( { key1 : value1 , key2 : value2 } ).pretty()
例:db.col.find( { likes : {$lt : 200, $gt : 100 } } ) 相当于: Select * from col where likes > 100 AND likes < 200 ;
3. or
格式:
db.col.find( { $or : [ { key1 : value1 }, { key2 : value2 } ] } ).pretty()
4. and 和 or
例:
db.col.find( { "by" : "兔兔" }, $or : [ { "by" : "开心的", {"title" : "睡觉"} } ] ).pretty()
5. $type操作符:基于BSON类型检索集合中匹配的数据类型并返回结果。
MongoDB中可以使用的类型:
例:
db.col.find( { "by" : { $type : 2 } } ) 获取 "col" 集合中 title 为 String 的数据
6. limit():读取指定数量的数据记录。接受一个数字参数,该参数指定从MongoDB中读取的记录条数
基本语法:
db.COLLECTION_NAME.find().limit(NUMBER)
例:
db.col.find({},{"title":1,_id:0}).limit(2)
补充:第一个 {} 放 where 条件,为空表示返回集合中所有文档。
第二个 {} 指定那些列显示和不显示 (0表示不显示 1表示显示)。
7. skip():跳过指定数量的数据,skip方法同样接受一个数字参数作为跳过的记录条数
基本语法:
db.COLLECTION_NAME.find().limit(NUMBER).skip(NUMBER)
例:
db.col.find({},{"title":1,_id:0}).limit(1).skip(1)
补充:skip 和 limit 结合就能实现分页
当查询时同时使用sort,skip,limit,无论位置先后 最后执行顺序 sort再skip再limit
8. sort():对数据进行排序。可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而-1是用于降序排列。
基本语法:
db.COLLECTION_NAME.find().sort({KEY:1})
例:
db.COLLECTION_NAME.find().sort({KEY:1})
9. ensureIndex():创建索引
基本语法:
db.COLLECTION_NAME.ensureIndex({KEY:1}) -- Key 值为你要创建的索引字段,1为指定按升序创建索引
例:
db.col.ensureIndex({"title":1}) --创建单个索引
db.col.ensureIndex({"title":1,"description":-1}) -- 创建多个索引
可选参数:
(1)background
boolean类型。
建索引过程会阻塞其它数据库操作,background可指定以后台方式创建索引,默认值为false
(2)unique
boolean类型。
建立的索引是否唯一。指定为true创建唯一索引。默认值为false
(3)name
string类型。
索引的名称。如果未指定,MongoDB的通过连接索引的字段名和排序顺序生成一个索引名称
(4)dropDups
boolean类型。
在建立唯一索引时是否删除重复记录,指定 true 创建唯一索引。默认值为 false
(5)sparse
boolean类型。
对文档中不存在的字段数据不启用索引。如果设置为true的话,在索引字段中不会查询出不包含对应字段的文档.。默认值为 false
(6)expireAfterSeconds
integer类型。
指定一个以秒为单位的数值,完成 TTL设定,设定集合的生存时间
(7)v
索引的版本号。默认的索引版本取决于mongod创建索引时运行的版本
(8)weights
document类型。
索引权重值,数值在 1 到 99,999 之间,表示该索引相对于其他索引字段的得分权重
(9)default_language
string类型。
对于文本索引,该参数决定了停用词及词干和词器的规则的列表。 默认为英语
(10)language_override
string类型。
对于文本索引,该参数指定了包含在文档中的字段名,语言覆盖默认的language,默认值为 language
例:
db.values.ensureIndex({open: 1, close: 1}, {background: true})
10. aggregate():处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。类似于sql语句中的 count(*)
基本语法:
db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)
聚合表达式:
(1)$sum 【计算总和】
例:
db.col.aggregate( [ { $group : { _id : "name" , num : { $sum : "likes" }} } ] ) --根据 name 分组 并求 likes 的和
(2)$avg【计算平均值】
例:
db.col.aggregate( [ { $group : { _id : "name" , num : { $avg : "likes" }} } ] ) --根据 name 分组 并求 likes 的平均值
(3)$min【获取集合中所有文档对应值得最小值】
例:
db.col.aggregate( [ { $group : { _id : "name" , num : { $min : "likes" }} } ] ) --根据 name 分组 并求 likes 的最小值
(4)$max【获取集合中所有文档对应值得最大值】
例:
db.col.aggregate( [ { $group : { _id : "name" , num : { $max : "likes" }} } ] ) --根据 name 分组 并求 likes 的最大值
(5)$push【在结果文档中插入值到一个数组中】
例:
db.col.aggregate( [ { $group : { _id : "name" , url : { $push : "$url" }} } ] ) --根据 name 分组 并插入值到数组中
(6)$addToSet【在结果文档中插入值到一个数组中,但不创建副本】
例:
db.col.aggregate( [ { $group : { _id : "name" , url : { $addToSet : "$url" }} } ] ) --根据 name 分组 并插入值到数组中但不创建副本
(7)$first【根据资源文档的排序获取第一个文档数据】
例:
db.col.aggregate( [ { $group : { _id : "name" , first_url : { $first : "$url" }} } ] ) --根据 name 分组 并获取第一个数据
(8)$last【根据资源文档的排序获取最后一个文档数据】
例:
db.col.aggregate( [ { $group : { _id : "name" , last_url : { $last : "$url" }} } ] ) --根据 name 分组 并获取最后一个数据
11. 管道
概念:在Unix和Linux中一般用于将当前命令的输出结果作为下一个命令的参数。
MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理。管道操作是可以重复的。
表达式:处理输入文档并输出。表达式是无状态的,只能用于计算当前聚合管道的文档,不能处理其它的文档。
聚合框架中常用操作:
$project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档
$match:用于过滤数据,只输出符合条件的文档。$match使用MongoDB的标准查询操作
$limit:用来限制MongoDB聚合管道返回的文档数
$skip:在聚合管道中跳过指定数量的文档,并返回余下的文档
$unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值
$group:将集合中的文档分组,可用于统计结果
$sort:将输入文档排序后输出
$gepNear:输出接近某一地理位置的有序文档
例:
db.article.aggregate(
{ $project : {
title : 1 ,
author : 1 ,
}}
); -- 默认情况下_id字段是被包含的
db.article.aggregate(
{ $project : {
title : 1 ,
author : 1 ,
}}
); -- 不包含_id字段
db.article.aggregate(
{ $skip : 5 }
); -- 跳过前五个文档
12. 复制(副本集)
概念:将数据同步在多个服务器的过程。
优点:提供了数据的冗余备份,并在多个服务器上存储数据副本,提高了数据的可用性, 并可以保证数据的安全性。还允许从硬件故障和服务中断中恢复数据。
原理:
mongodb的复制至少需要两个节点。其中一个是主节点,负责处理客户端请求,其余的都是从节点,负责复制主节点上的数据。
mongodb各个节点常见的搭配方式为:一主一从、一主多从。主节点记录在其上的所有操作oplog,从节点定期轮询主节点获取这些操作,然后对自己的数据
副本执行这些操作,从而保证从节点的数据与主节点一致。
结构图:
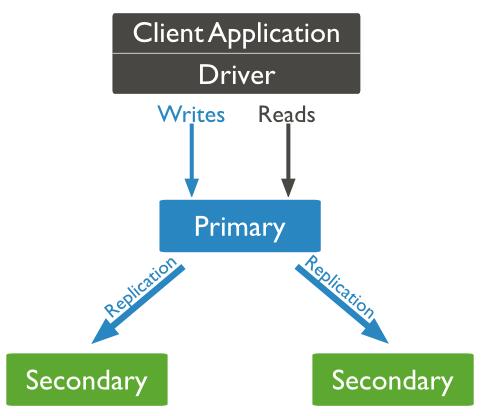
客户端总主节点读取数据,在客户端写入数据到主节点是, 主节点与从节点进行数据交互保障数据的一致性。
副本集特征:
(1)N个节点的集群
(2)任何节点可作为主节点
(3)所有写入操作都在主节点上
(4)自动故障转移
(5)自动恢复
例一:使用同一个MongoDB来做MongoDB主从的副本集设置及成员的添加
1. 关闭正在运行的MongoDB服务器
2. 通过指定 --replSet 选项来启动mongoDB。
【--replSet基本格式:
mongod --port "PORT" --dbpath "YOUR_DB_DATA_PATH" --replSet "REPLICA_SET_INSTANCE_NAME"
--rs.add基本格式:
rs.add(HOST_NAME : PORT)
】
mongod --port 27017 --dbpath "D:\set up\mongodb\data" --replSet rs0 --启动一个名为rs0的MongoDB实例,其端口号为27017。启动后打开命令提示框并连接上mongoDB服务
rs.initiate() -- 在客户端启动一个新的副本集
rs.conf() -- 查看副本集配置
rs.status -- 查看副本集状态
3. 添加成员
需要使用多条服务器来启动mongo服务。进入Mongo客户端,并使用rs.add()方法来添加副本集的成员。
rs.add(" mongod1.net : 27017 ") -- 将启动了的mongod1.net,端口号为27017的Mongo服务。 在客户端命令窗口使用rs.add() 命令将其添加到副本集中。
PS:
(1)在MongoDB中只能通过主节点将Mongo服务添加到副本集中, 判断当前运行的Mongo服务是否为主节点可以使用命令db.isMaster()
(2)MongoDB的副本集与我们常见的主从有所不同,主从在主机宕机后所有服务将停止,而副本集在主机宕机后,副本会接管主节点成为主节点,不会出现宕机的情况
13. 分片
概念:当MongoDB存储海量的数据时,我们可以通过在多台机器上分割数据,使得数据库系统能存储和处理更多的数据
为什么使用分片:
(1)复制所有的写入操作到主节点
(2)延迟的敏感数据会在主节点查询
(3)单个副本集限制在12个节点
(4)当请求量巨大时会出现内存不足
(5)本地磁盘不足
(6)垂直扩展价格昂贵
分片集群结构分布:
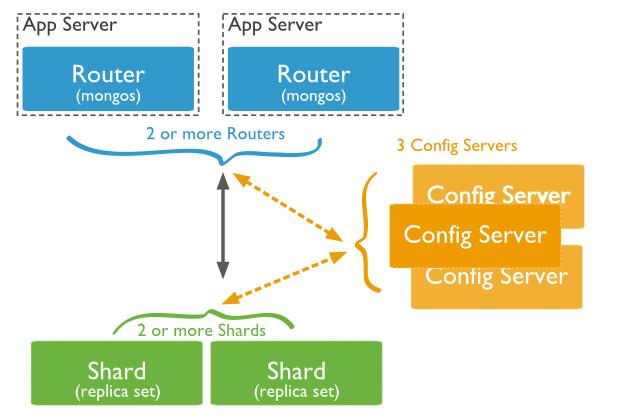
主要组件:
(1)Shard
用于存储实际的数据块,实际生产环境中一个shard server角色可由几台机器组个一个replica set承担,防止主机单点故障
(2)Config Server
mongod实例,存储了整个 ClusterMetadata,其中包括 chunk信息
(3)Query Routers
前端路由,客户端由此接入,且让整个集群看上去像单一数据库,前端应用可以透明使用
例:
分片结构端口分布如下:
Shard Server 1:27020
Shard Server 2:27021
Shard Server 3:27022
Shard Server 4:27023
Config Server :27100
Route Process:40000
步骤一:启动Shard Server
[root@100 /]# mkdir -p /www/mongoDB/shard/s0
[root@100 /]# mkdir -p /www/mongoDB/shard/s1
[root@100 /]# mkdir -p /www/mongoDB/shard/s2
[root@100 /]# mkdir -p /www/mongoDB/shard/s3
[root@100 /]# mkdir -p /www/mongoDB/shard/log
[root@100 /]# /usr/local/mongoDB/bin/mongod --port 27020 --dbpath=/www/mongoDB/shard/s0 --logpath=/www/mongoDB/shard/log/s0.log --logappend --fork
....
[root@100 /]# /usr/local/mongoDB/bin/mongod --port 27023 --dbpath=/www/mongoDB/shard/s3 --logpath=/www/mongoDB/shard/log/s3.log --logappend --fork
步骤二: 启动Config Server
[root@100 /]# mkdir -p /www/mongoDB/shard/config
[root@100 /]# /usr/local/mongoDB/bin/mongod --port 27100 --dbpath=/www/mongoDB/shard/config --logpath=/www/mongoDB/shard/log/config.log --logappend --fork
步骤三: 启动Route Process
/usr/local/mongoDB/bin/mongos --port 40000 --configdb localhost:27100 --fork --logpath=/www/mongoDB/shard/log/route.log --chunkSize 500
步骤四: 配置Sharding
[root@100 shard]# /usr/local/mongoDB/bin/mongo admin --port 40000
MongoDB shell version: 2.0.7
connecting to: 127.0.0.1:40000/admin
mongos> db.runCommand({ addshard:"localhost:27020" })
{ "shardAdded" : "shard0000", "ok" : 1 }
......
mongos> db.runCommand({ addshard:"localhost:27029" })
{ "shardAdded" : "shard0009", "ok" : 1 }
mongos> db.runCommand({ enablesharding:"test" }) #设置分片存储的数据库
{ "ok" : 1 }
mongos> db.runCommand({ shardcollection: "test.log", key: { id:1,time:1}})
{ "collectionsharded" : "test.log", "ok" : 1 }
步骤五: 程序代码内无需太大更改,直接按照连接普通的mongo数据库那样,将数据库连接接入接口40000
14. 数据备份与恢复
备份:【mongodump】
在Mongodb中我们使用mongodump命令来备份MongoDB数据。该命令可以导出所有数据到指定目录中,还可以通过参数指定导出的数据量级转存的服务器。
基本语法:
mongodump -h dbhost -d dbname -o dbdirectory
参数详解:
-h :MongDB所在服务器地址,例如:127.0.0.1,当然也可以指定端口号:127.0.0.1:27017
-d :需要备份的数据库实例,例如:test
-o :备份的数据存放位置,例如:c:\data\dump,当然该目录需要提前建立,在备份完成后,系统自动在dump目录下建立一个test目录,这个目录里面存放该数据库实例的备份数据
mongodump --host HOST_NAME --port PORT_NUMBER --备份所有MongoDB数据
mongodump --collection COLLECTION --db DB_NAME --备份指定数据库的集合
mongodump --dbpath DB_PATH --out BACKUP_DIRECTORY --
恢复:【mongorestore 】
基本语法:
mongorestore -h <hostname><:port> -d dbname <path>
参数详解:
--host <:port>, -h <:port>:MongoDB所在服务器地址,默认为: localhost:27017
--db , -d :需要恢复的数据库实例
--drop:恢复的时候,先删除当前数据,然后恢复备份的数据。就是说,恢复后,备份后添加修改的数据都会被删除,
<path>: mongorestore 最后的一个参数,设置备份数据所在位置,例如:c:\data\dump\test。你不能同时指定 <path> 和 --dir 选项,--dir也可以设置备份目录
--dir:指定备份的目录
15. 监控
【mongstat】
mongodb自带的状态检测工具,在命令行下使用。它会间隔固定时间获取mongodb的当前运行状态,并输出。
作用:了解MongoDB的运行情况,并查看MongoDB的性能。
例:
D:\set up\mongodb\bin>mongostat
输出结果:
【 mongotop】
mongodb下的一个内置工具。mongotop提供了一个方法,用来跟踪一个MongoDB的实例,查看哪些大量的时间花费在读取和写入数据。
也提供每个集合的水平的统计数据。默认情况下,mongotop返回值的每一秒。
例:
E:\mongodb-win32-x86_64-2.2.1\bin>mongotop <sleeptime> --locks
输出结果:
参数详解:
<sleeptime>:等待的时间长度,以秒为单位,mongotop等待调用之间。通过的默认mongotop返回数据的每一秒
--locks:报告每个数据库的锁的使用中
输出结果字段说明:
ns:包含数据库命名空间,后者结合了数据库名称和集合
db:包含数据库的名称。名为 . 的数据库针对全局锁定,而非特定数据库
total:mongod花费的时间工作在这个命名空间提供总额
read:提供了大量的时间,这mongod花费在执行读操作,在此命名空间
write:提供这个命名空间进行写操作,这mongod花了大量的时间
Mongodb基础与入门的更多相关文章
- MongoDB基础入门视频教程
MongoDB基础入门视频教程http://www.icoolxue.com/album/show/98
- 分布式文档存储数据库之MongoDB基础入门
一.MongoDB简介 MongoDB是用c++语言开发的一款易扩展,易伸缩,高性能,开源的,schema free 的基于文档的nosql数据库:所谓nosql是指不仅仅是sql的意思,它拥有部分s ...
- MongoDB基础知识 01
MongoDB基础知识 1. 文档 文档是MongoDB中的数据的基本单元,类似于关系型数据库管理系统的行. 文档是键值对的一个有序集.通常包含一个或者多个键值对. 例如: {”greeting& ...
- MongoDB【快速入门】
1.MongDB 简介 MongoDB(来自于英文单词"Humongous",中文含义为"庞大")是可以应用于各种规模的企业.各个行业以及各类应用程序的开源数据 ...
- 答好友困惑:Java零基础如何入门,不知道怎么学,迷茫ING
作者:程序员小跃 几个星期之前,我在知乎上看到一个提问,说是:对于完全没有经验零基础自身的数学底子也很弱学习Java应该怎么学习呢?想着类似的问题我也有过回答,并且反馈还是蛮好的,就参考之前的思路回答 ...
- mongodb基础用法
安装部分 mongodb配置方法 mongodb的安装目录 C:\MongoDB\Server\3.2\bin 创建以下目录 c:\mongo\log c:\mongo\db 创建mongodb的配置 ...
- mongodb基础系列——数据库查询数据返回前台JSP(一)
经过一段时间停顿,终于提笔来重新整理mongodb基础系列博客了. 同时也很抱歉,由于各种原因,没有及时整理出,今天做了一个demo,来演示,mongodb数据库查询的数据在JSP显示问题. 做了一个 ...
- MongoDB基础知识 02
MongoDB基础知识 02 6 数据类型 6.1 null : 表示空值或者不存在的字段 {"x":null} 6.2 布尔型 : 布尔类型只有两个值true和false {&q ...
- Linux基础知识入门
[Linux基础]Linux基础知识入门及常见命令. 前言:最近刚安装了Linux系统, 所以学了一些最基本的操作, 在这里把自己总结的笔记记录在这里. 1,V8:192.168.40.10V1: ...
随机推荐
- Guake!
快捷键及其定制: [全局快捷键] F12:显示/隐藏Guake的程序界面. [局部快捷键] Ctrl+Shift+T:新建标签页: Ctrl+Shift+W:关闭标签页: Ctrl+Shift+C:复 ...
- CCF系列之门禁系统(201412-1)
试题编号:201412-1试题名称:门禁系统时间限制: 2.0s内存限制: 256.0MB 问题描述 涛涛最近要负责图书馆的管理工作,需要记录下每天读者的到访情况.每位读者有一个编号,每条记录用读者的 ...
- spring 事务隔离级别配置
声明式的事务处理中,要配置一个切面,即一组方法,如 其中就用到了propagation,表示打算对这些方法怎么使用事务,是用还是不用,其中propagation有七种配置,REQUIRED.SUPPO ...
- 深入理解HashMap的扩容机制
什么时候扩容: 网上总结的会有很多,但大多都总结的不够完整或者不够准确.大多数可能值说了满足我下面条件一的情况. 扩容必须满足两个条件: 1. 存放新值的时候当前已有元素的个数必须大于等于阈值 2. ...
- Centos7-安装telnet服务
1,检查是否安装 telnet-server和xinetd rpm -qa telnet-server rpm -qa xinetd 2,如果没有安装过就安装 查找yum yum list |grep ...
- Oracle多行记录合并的几种方法
今天正好遇到需要做这个功能,顺手搜了一下网络,把几种方法都列出来,方便以后参考. 1 什么是合并多行字符串(连接字符串)呢,例如: SQL> desc test; Name Type Nulla ...
- tcpdump 使用
例子: 首先切换到root用户 tcpdump -w aaa.cap -i eth7 -nn -x 'port 9999' -c 1 以例子说明参数: -w:输出到文件aaa.cap ...
- 《共享库PATH与ld.so.conf简析》
这是摘抄<共享库PATH与ld.so.conf简析>1. 往/lib和/usr/lib里面加东西,是不用修改/etc/ld.so.conf的,但是完了之后要调一下ldconfig,不然这个 ...
- shell第四篇(上)
第四篇了解Shell 命令执行流程图 {网中人大哥推荐参考Learning the Bash Shell, 2nd Edition,第 178页:中文版229页} Shell 从标准输入或脚本中读取的 ...
- Struts2如何搭建?
如何搭建Struts2: 1.导入jar包 commons-fileupload-1.3.jar commons-io-2.0.1.jar commons-lang3-3.1.jar freema ...