伯克利推出世界最快的KVS数据库Anna:秒杀Redis和Cassandra
天下武功,唯快不破。
伯克利 RISE 实验室推出了最新的键值存储数据库 Anna,提供了惊人的存取速度、超强的伸缩性和史无前例的一致性保证。Jeff Dean 说,当一个系统增长到十倍规模时,就需要进行重新设计。那么,对于 RISE 实验室的研究员们来说,怎样才能设计出一个具备指数级增长规模的键值存储数据库呢?
题外话:
RISE 实验室的前身是赫赫有名的伯克利 AMP 实验室,该实验室曾开发出了一大批大获成功的分布式技术,这些技术对高性能计算产生了深远的影响,包括 Spark、Mesos、Tachyon 等。如今,原 AMP 实验室博士生,同时也是 Spark 和 Mesos 核心作者之一的 Matei 已经转身去了斯坦福,并于去年年底推出了以普及机器学习实践为目的的开源项目 DAWN(详见 AI 前线报道 ),而 RISE 实验室也在没多久后推出了志在取代 Spark 的新型分布式执行框架 Ray。
过去几年,RISE 实验室把研究重点放在如何设计一个无需协调的分布式系统上。他们提出了 CALM 基础理论(http://db.cs.berkeley.edu/papers/sigrec10-declimperative.pdf),设计出了新编程语言 Bloom(http://bloom-lang.net/),开发出了跨平台程序分析框架 Blazes(https://arxiv.org/pdf/1309.3324.pdf),发布了事务协议 HATs(http://www.vldb.org/pvldb/vol8/p185-bailis.pdf)。但在推出 Anna 之前,他们还未就这些理论、语言、框架或协议在多核环境下或云环境中能够提供怎样的性能有过任何测试或评估。
而 Anna 的推出正好印证了他们之前的研究成果。Anna 的论文显示,在单个 AWS 实例上,Anna 的速度是 Redis 的 10 倍。而在一个标准的交互式基准测试中,也以 10 倍的速度打败了 Cassandra。为了获得更多的比较结果,他们还拿 Anna 与其他主流的键值系统进行了性能对比:比 Masstree 快 700 倍,比英特尔的“无锁”TBB 哈希表快 800 倍。当然,Anna 并没有提供类似其他键值系统那样的线性一致性。不过,Anna 使用了本地缓存存放私有状态,仍然提供了极佳的无协调一致性,比“hogwild”风格的 C++ 哈希表要快上 126 倍。而且一旦到了云端,Anna 更是独领风骚,其他的系统无法真正提供线性伸缩,但 Anna 却可以。
Anna 的性能和伸缩性主要归功于它的完全无协调机制,节点工作进程有 90% 的工作负载是在处理请求,而其他大部分系统(如 Masstree 和英特尔的 TBB)只有不到 10% 的时间在处理请求,它们其余的 90% 时间花在了等待协调上。不仅如此,其他系统因为使用了共享内存,还会出现处理器缓存击穿问题。
Anna 不仅速度快,在一致性方面也达到了很高的水准。多年前,他们发布的事务协议 HATs 就已表明,无协调的分布式一致性和事务隔离性存在很大的提升空间,包括级联一致性和读提交事务级别。Anna 将 Bloom 的单格子组合设计模式移植到了 C++ 中,是第一个实现了上述所有级别一致性的系统。当然,也是因为设计上的简洁,才能达到如此快的速度。
RISE 的研究员们在设计 Anna 的过程中学到了很多,它们已经远远超出了一个键值数据库的范畴,可以被应用在任何一个分布式系统上。他们正基于 Anna 开发一个新的扩展系统,叫作 Bedrock。Bedrock 运行在云端,提供了无需人工干预、低成本的键值存储方案,而且是开源的。
Anna 架构简析
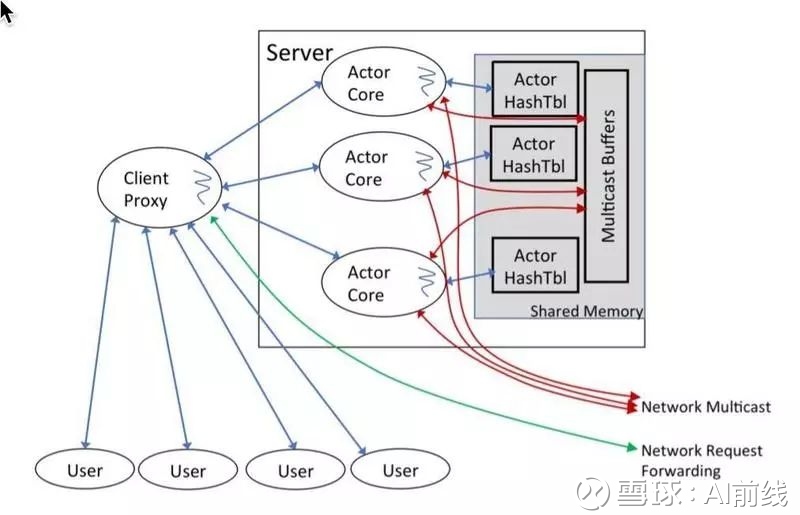
图 1:Anna 架构
上图是 Anna 单节点的架构图。Anna 服务器由一系列独立的线程组成,每个线程运行无协调的 actor。每个线程对应一个 CPU 核心,线程数量不超过 CPU 的总核数。客户端代理负责将远程请求分发给 actor,每个 actor 都有一个私有的哈希表,这些哈希表存放在共享内存中。线程间的变更通过内存广播进行交换,而服务器间的变更则通过 protobuf 进行交换。
这种线程和 CPU 核心一对一的模型避免了上下文切换开销。actor 之间不共享键值状态,通过一致性哈希对键空间进行分区,并使用多主复制机制在 actor 之间复制数据分区,而且复制系数是可配置的。actor 基于时间戳将键的更新通知给其他 actor 副本,每个 actor 有自己的私有状态,这个状态保存在一个叫作“格子”的数据结构中,确保在消息发生延迟、重排或重复时仍然能够保证一致性。
Anna 性能评测
下面就 Anna 的无协调 actor 模型在多核 CPU 上的并行能力、多服务器伸缩能力进行评测,并将它与其他流行的键值数据库进行对比。
无协调 actor 模型的伸缩性
在无协调 actor 模型中,每个 actor 对应一个线程,对任何一个共享状态都有自己的一份私有拷贝,并通过异步广播将更新通知给其他 actor。在多核服务器上,这种模型比传统的共享内存模型的性能要高出一个数量级。
为此,RISE 研究员设计了一个对比实验,将 Anna 与其他基于共享内存的 TBB、Masstree 和自己实现的一个键值存储系统(姑且把它叫作“Ideal”)进行了对比。他们在 AWS 的 m4.16xlarge 实例上运行实验,每个实例配备了 32 核的 CPU。实验中使用了 1 百万个键值对,键的大小为 8 字节,值的大小为 1KB。在实验过程中,他们基于 zipfian 分布和各种系数生成不同的压力负载,模拟不同层次的冲突。
在第一次实验中,他们对比了 Anna 与 TBB、Masstree 和 Ideal 在单台服务器上的吞吐量。他们逐渐增加线程数量,直到达到服务器 CPU 核数的上限,并观察它们的吞吐量。
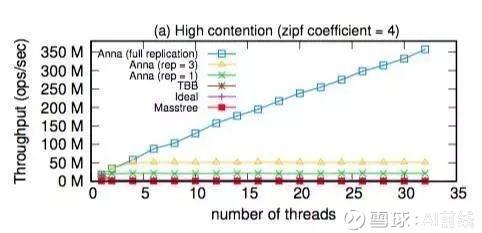
图 2
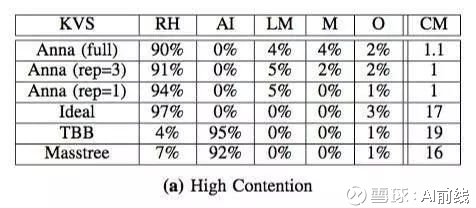
图 3
图 2 是在高并发情况下,线程数与吞吐量的变化关系,其中 zipf 系数为 4。图 3 是在高并发情况下,CPU 时间的使用情况。CPU 时间被分为 5 类:处理请求(RH)、原子指令(AI)、合并格子(LM)、广播(M)和其他。最右边一栏是 L1 缓存击穿数量(CM)。
从图中可以看出,在这样的负载压力下,TBB 和 Masstree 几乎失去了并行能力。因为大部分是更新操作,针对同一个键值的并行更新操作会被串行化,它们需要同步机制来防止多个线程同时更新同一个键值。因此,随着线程数量的增加,它们性能也只能趋于平缓。Ideal 虽然比 TBB 和 Masstree 的性能高出 6 倍,但相比 Anna,还是差了很多。尽管它没有使用同步机制,但在多个线程修改共享内存地址时,仍然存在缓存一致性方面的开销。
相反,在 Anna 中,更新操作是针对本地状态进行的,不需要进行同步,并定时通过广播进行变更交换。在高并发情况下,尽管它的性能仍然受限于其复制系数,但比基于共享内存的系统要好很多。Anna 有 90% 的 CPU 时间用于处理请求,花在其他方面的时间则很少。可见,Anna 的无协调 actor 模型解决了键值存储系统在多核环境里的伸缩性难题。
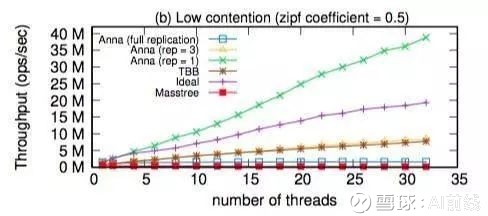
图 4
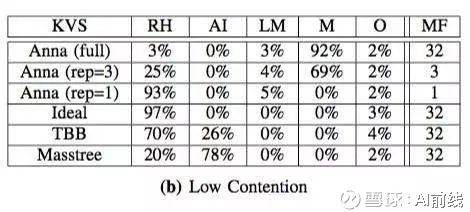
图 5
图 4 是在低并发情况下,线程数与吞吐量的变化关系,其中 zipf 系数为 0.5。图 5 是在低并发情况下,CPU 时间的使用情况,其中最右边一列表示内存占用(MF)。
当复制系数为 1 时,Anna 因为内存占用率极低而获得了更好的伸缩性。不过,随着复制系数的增加(增加到 3),吞吐量出现了明显下降(下降了四分之三)。这里有两个原因。首先,增加复制系数会占用更多的内存,而且在低并发的情况下,唯一键的更新操作大量增加,所以无法通过合并的方式进行变更交换。图 5 显示,当复制系数为 3 时,Anna 有 69% 的 CPU 时间用于处理广播变更。而在使用完整的复制系数时,Anna 也停止了伸缩,因为此时相当于每个线程只能处理一个请求。不过,尽管 TBB 和 Masstree 没有广播开销,但在内存占用和同步操作方面仍然存在大量开销。因此,从这个实验中可以得出这样的结论:对于一个支持多主复制的系统来说,在低并发量情况下使用高复制系数对性能是一种伤害。
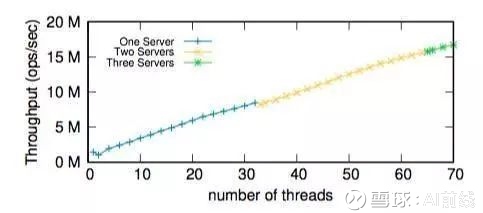
图 6
图 6 是在多个服务器上增加线程数时的吞吐量变化情况。Anna 的复制系数设置为 3,先是启动第一台服务器的 32 个线程,然后是第二台服务器的 32 个线程,最后是第三台服务器的所有剩余线程。从图中可以看出,Anna 的吞吐量随着线程数量的增加呈线性增长。在启动第 33 个线程时吞吐量有轻微下降,不过那是因为第 33 个线程是属于第二台服务器的。但从整体来看,吞吐量的增长是很稳定的。可见,借助 Anna 的无协调 actor 模型,是可以实现吞吐量线性增长的。
与其他系统的比较
为对比 Anna 与其他流行键值系统之间的性能差异,RISE 研究员设计了两次实验,第一次在单节点上与 Redis 进行对比,第二次在一个大型的分布式系统上与 Cassandra 进行对比。
Anna 具有多线程并行能力,而 Redis 使用的是单线程模型。所以,在第一次实验中,他们在同一台服务器上搭建了一个 Redis 集群,让 Anna 与这个集群进行比较。实验是在 AWS 的的 EC2 实例上运行的,其中 Redis 集群使用了尽可能多的线程。
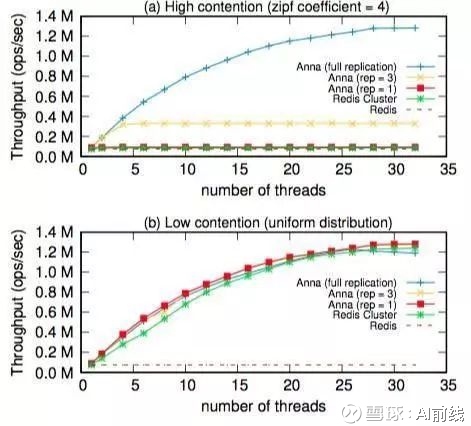
图 7
从图 7(a) 可以看出,在高并发情况下,Redis 集群的整体吞吐量几乎保持不变,而 Anna 可以在副本之间分散热键。Anna 的吞吐量随着复制系数的增加而增长,直到达到平缓。如果热键完全被复制,吞吐量还会随着线程的增加继续增长。从图 7(b) 可以看出,在低并发情况下,Anna 和 Redis 集群都获得了不错的并行能力,它们的吞吐量都随着线程数的增加而增长。
从这次实验可以看出,在高并发情况下,Anna 通过复制热键的方式在性能方面吊打 Redis 集群,而在低并发情况下,Anna 可以与 Redis 集群达到相似的性能。
在第二次实验中,RISE 研究员将 Cassandra 的一致性设置为最低级别(ONE),也就是说,只要一个节点确认就表示更新操作成功。他们在 AWS 的四个 EC2 可用区域(奥尔良、北弗吉尼亚、爱尔兰和东京)上运行该实验,并通过调整可用区域的节点数量来评测它们的伸缩性。它们的复制系数都被设置为 3。
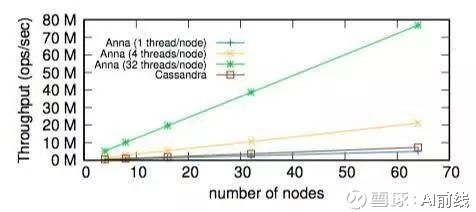
图 8
从图 8 可以看出,随着节点的增加,Anna 和 Cassandra 的性能都呈现出线性增长。不过,Anna 比 Cassandra 的性能高出一大截。事实上,在每个节点使用 4 个线程时,Anna 就可以打败 Cassandra,而当把所有的线程都用上,Anna 比 Cassandra 的性能高出 10 倍以上。
参考资料:
https://rise.cs.berkeley.edu/blog/anna-kvs/?twitter=@bigdata
论文原文:
http://db.cs.berkeley.edu/jmh/papers/anna_ieee18.pdf
作者:AI前线
链接:https://xueqiu.com/9217191040/103224951
来源:雪球
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
伯克利推出世界最快的KVS数据库Anna:秒杀Redis和Cassandra的更多相关文章
- 安娜Anna:世界最快的超级伸缩的KVS, 秒杀Redis
伯克利 这个大学在计算机学术界.工业界的地位举足轻重,其中的AMP实验室曾开发出了一大批大获成功. 对计算机行业产生深远影响的分布式计算技术,包括 Spark.Mesos.Tachyon 等.作为AM ...
- 构建高性能数据库缓存之redis主从复制
一.什么是redis主从复制? 主从复制,当用户往Master端写入数据时,通过Redis Sync机制将数据文件发送至Slave,Slave也会执行相同的操作确保数据一致:且实现Redis的主从复制 ...
- 数据库基础 非关系型数据库 MongoDB 和 redis
数据库基础 非关系型数据库 MongoDB 和 redis 1 NoSQL简介 访问量增加,频繁的读写 直接访问(硬盘)物理级别的数据,会很慢 ,关系型数据库的压力会很大 所以,需要内存级的读写操作, ...
- 【快学springboot】13.操作redis之String数据结构
前言 在之前的文章中,讲解了使用redis解决集群环境session共享的问题[快学springboot]11.整合redis实现session共享,这里已经引入了redis相关的依赖,并且通过spr ...
- php版redis插件,SSDB数据库,增强型的Redis管理api实例
php版redis插件,SSDB数据库,增强型的Redis管理api实例 SSDB是一套基于LevelDB存储引擎的非关系型数据库(NOSQL),可用于取代Redis,更适合海量数据的存储.另外,ro ...
- 写一些脚本的心得总结系列第4篇-------从数据库同步到redis
5.从数据库同步到redis的. redis把数据放内存里,读取都非常方便,也提供了远超memcache的丰富数据结构.下面我举2个例子,比如1)把数据从数据库写入到redis: <?php $ ...
- 构建高性能数据库缓存之redis(二)
一.概述 在构建高性能数据库缓存之redis(一)这篇文档中,阐述了Redis数据库(key/value)的特点.功能以及简单的配置过程,相信阅读过这篇文档的朋友,对Redis数据库会有一点的了解,此 ...
- SSDB 一个高性能的支持丰富数据结构的 NoSQL 数据库, 用于替代 Redis.
SSDB 一个高性能的支持丰富数据结构的 NoSQL 数据库, 用于替代 Redis. 特性 替代 Redis 数据库, Redis 的 100 倍容量 LevelDB 网络支持, 使用 C/C++ ...
- 华为云PB级数据库GaussDB(for Redis)揭秘第八期:用高斯 Redis 进行计数
摘要:高斯Redis,计数的最佳选择! 一.背景 当我们打开手机刷微博时,就要开始和各种各样的计数器打交道了.我们注册一个帐号后,微博就会给我们记录一组数据:关注数.粉丝数.动态数-:我们刷帖时,关注 ...
随机推荐
- 利用fiddler和mock调试本地微信网页
利用fiddler和mock调试本地微信网页 微信公众号网页是比较特殊的页面,普通页面直接打开即可访问,但对于需要请求微信相关接口的部分需要安全域名认证.这导致了使用mock数据进行开发的页面没办法走 ...
- 来了解并防范一下CSRF攻击提高网站安全
看一下我从网上找的原理图,结合举例描述,多看一遍你就知道怎么回事了. CSRF是什么呢?CSRF全名是Cross-site request forgery,是一种对网站的恶意利用,CSRF比XSS更具 ...
- 浏览器的 bfcache 特性
一.bfcache 基本概念 现代浏览器在根据历史记录进行前进/后退操作时,会启用缓存机制,名为"bfcache"(back-forward cache,往返缓存),它使页面导航非 ...
- POJ - 1426 暴力枚举+同余模定理 [kuangbin带你飞]专题一
完全想不到啊,同余模定理没学过啊,想起上学期期末考试我问好多同学'≡'这个符号什么意思,都说不知道,你们不是上了离散可的吗?不过看了别人的解法我现在会了,同余模定理介绍及运用点这里点击打开链接 简单说 ...
- SQL 分组统计 行转列 CASE WHEN 的使用
原文地址:http://blog.itpub.net/26451903/viewspace-733526 原文在分组统计部分 sql是有问题的 本文已将sql改正 已用红色标记 Cas ...
- nginx笔记5-双机热备原理
1动静分离演示: 将笔记3的Demo改造一下,如图所示: 改造完成后,其实就是在网页上显示一张图片 现在启动Tomcat运行起来,如图: 可以看到图片的请求是请求Tomcat下的图片. 现在,通过把静 ...
- 3D打印技术在医疗上的实际应用与实验室研究
2018-01-17 Chris 免费3D打印模型资源站 预计阅读时间:5-10分钟 关键字:3D打印髋关节.脊柱置换产品,3D打印技术辅助精准截骨,义齿,生物墨水(BioInk),干细胞 随着& ...
- Ambari部署HDP:HBase Master启动后自动消失
这是第一次出勤部署产品.遇到不可控问题,解决,写个心得.记录一下吧^^ 在排查问题的过程中,学到不少知识. (1)centos系统盘和数据盘分开,装操作系统的人没有将IT的空间分配出来,所以分区,自动 ...
- orcale和hive常用函数对照表(?代表未证实)
函数分类 oracle hive 说明 字符函数 upper('coolszy') upper(string A) ucase(string A) 将文本字符串转换成字母全部大写形式 lower('K ...
- 用Node.JS+MongoDB搭建个人博客(万众期待的router.js)(四)
万众期待的router.js,是我现在最想写的一个博客.因为他包含了整个个人博客的精髓.在这里,所有的请求配置,返回的参数等等所做的业务逻辑都在这个文件里实现. 我会详细说明这些代码的作用,所以这篇博 ...