蚂蚁代理免费代理ip爬取(端口图片显示+token检查)
分析
蚂蚁代理的列表页大致是这样的:
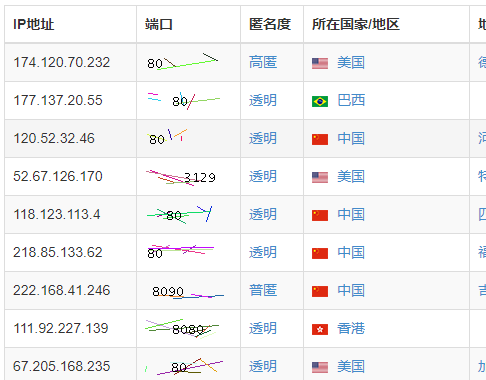
端口字段使用了图片显示,并且在图片上还有各种干扰线,保存一个图片到本地用画图打开观察一下:
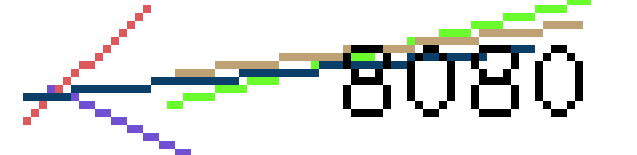
仔细观察蓝色的线其实是在黑色的数字下面的,其它的干扰线也是,所以这幅图是先绘制的干扰线又绘制的端口数字,于是就悲剧了,干扰线形同虚设,所以还是有办法识别的。
然后就是ip字段,看了下ip字段很老实没啥猫腻。
注意到这个列表有一个按端口号筛选的功能,很兴奋的试了一下以为可以绕过去,然后: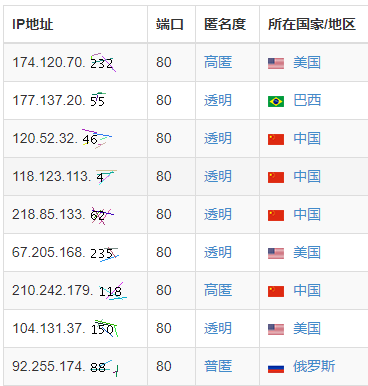
端口号是不用图片显示了,但是ip地址的最后一部分用图片显示,还是老老实实识别端口号吧。
另外就是对于端口号图片的url也是先存储在元素属性上然后又设置的,它默认返回的src是空的:

还有就是对于图片的访问需要有一个proxy_token的cookie,否则的话访问不了这张图片,这个算是做的比较好的了,其它的站点一般都是对图片访问没有限制。
这个proxy_token是在页面返回的时候设置的,同时设置了图片的src,可以在页面底部找到这段js:
$(function() {
document.cookie = "proxy_token=mcmoveng;path=/";
$("img.js-proxy-img").each(function(index, item) {
$(this).attr("src", $(this).attr("data-uri")).removeAttr("data-uri");;
});
});
在页面返回的时候提取出对应的proxy_token即可。
代码实现
识别端口号的话使用这个库:https://github.com/CC11001100/commons-simple-character-ocr
首先需要收集一些图片来生成标注图片,这里选了它的随机选择5位数端口的列表,这样得到的数字更多可以少下几张。
另外需要注意的是对图片去噪音使用的是SingleColorClean,这种过滤器会将图片上除了指定颜色(未指定的话默认是黑色)之外的颜色统统过滤掉,正好适合这里除了字体的黑色其它干扰线统统过滤掉,当然是有一定几率干扰线是黑色的过滤不掉的,几率大概是1/0XFFFFFF吧…haha
下载一些图片生成标注图片:
package org.cc11001100.t1; import cc11001100.ocr.OcrUtil;
import cc11001100.ocr.clean.SingleColorFilterClean;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document; import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.ByteArrayInputStream;
import java.io.File;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.util.regex.Matcher;
import java.util.regex.Pattern; /**
* @author CC11001100
*/
public class AntProxyGrab { private static OcrUtil ocrUtil; static {
ocrUtil = new OcrUtil().setImageClean(new SingleColorFilterClean());
} private static void grabImage(String saveBasePath) {
String url = "http://www.mayidaili.com/free/fiveport/";
for (int i = 0; i < 10; i++) {
String responseContent = getResponseContent(url + i);
String proxyToken = parseProxyToken(responseContent);
Document doc = Jsoup.parse(responseContent);
doc.select(".js-proxy-img").forEach(elt -> {
String imgLink = elt.attr("data-uri");
byte[] imgBytes = download(imgLink, proxyToken);
try {
BufferedImage img = ImageIO.read(new ByteArrayInputStream(imgBytes));
String savePath = saveBasePath + "/" + System.currentTimeMillis() + ".png";
ImageIO.write(img, "png", new File(savePath));
System.out.println("save img " + imgLink);
} catch (IOException e) {
e.printStackTrace();
}
});
}
} private static String parseProxyToken(String responseContent) {
Matcher matcher = Pattern.compile("proxy_token=(.+);path=/").matcher(responseContent);
if (matcher.find()) {
return matcher.group(1);
}
return "";
} private static String getResponseContent(String url) {
byte[] responseBytes = download(url);
return new String(responseBytes, StandardCharsets.UTF_8);
} private static byte[] download(String url) {
return download(url, "");
} private static byte[] download(String url, String proxyToken) {
for (int i = 0; i < 3; i++) {
try {
return Jsoup.connect(url).cookie("proxy_token", proxyToken).execute().bodyAsBytes();
} catch (IOException e) {
e.printStackTrace();
}
}
return new byte[0];
} public static void main(String[] args) {
String rawImageSaveDir = "E:/test/proxy/ant/raw/";
String distinctCharImgSaveDir = "E:/test/proxy/ant/char/";
grabImage(rawImageSaveDir);
ocrUtil.init(rawImageSaveDir, distinctCharImgSaveDir);
} }
现在去E:/test/proxy/ant/char/将图片名称改为其代表的意思:

上面的标注数据生成完grabImage方法就没用了,在此基础上修改一下爬取前十页的内容并返回:
package org.cc11001100.t1; import cc11001100.ocr.OcrUtil;
import cc11001100.ocr.clean.SingleColorClean;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document; import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.ByteArrayInputStream;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.List;
import java.util.Objects;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import java.util.stream.Collectors; /**
* @author CC11001100
*/
public class AntProxyGrab { private static OcrUtil ocrUtil; static {
ocrUtil = new OcrUtil().setImageClean(new SingleColorClean());
ocrUtil.loadDictionaryMap("E:/test/proxy/ant/char/");
} private static List<String> grabProxyIp() {
String url = "http://www.mayidaili.com/free/fiveport/";
List<String> resultList = new ArrayList<>();
for (int i = 0; i < 10; i++) {
String responseContent = getResponseContent(url + i);
String proxyToken = parseProxyToken(responseContent);
Document doc = Jsoup.parse(responseContent);
List<String> ipList = doc.select("tbody tr").stream().map(elt -> {
String ip = elt.select("td:eq(0)").text();
String imgLink = elt.select(".js-proxy-img").attr("data-uri");
byte[] imgBytes = download(imgLink, proxyToken);
try {
BufferedImage img = ImageIO.read(new ByteArrayInputStream(imgBytes));
String port = ocrUtil.ocr(img);
return ip + ":" + port;
} catch (IOException e) {
e.printStackTrace();
}
return null;
}).filter(Objects::nonNull).collect(Collectors.toList());
resultList.addAll(ipList);
}
return resultList;
} private static String parseProxyToken(String responseContent) {
Matcher matcher = Pattern.compile("proxy_token=(.+);path=/").matcher(responseContent);
if (matcher.find()) {
return matcher.group(1);
}
return "";
} private static String getResponseContent(String url) {
byte[] responseBytes = download(url);
return new String(responseBytes, StandardCharsets.UTF_8);
} private static byte[] download(String url) {
return download(url, "");
} private static byte[] download(String url, String proxyToken) {
for (int i = 0; i < 3; i++) {
try {
return Jsoup.connect(url).cookie("proxy_token", proxyToken).execute().bodyAsBytes();
} catch (IOException e) {
e.printStackTrace();
}
}
return new byte[0];
} public static void main(String[] args) {
grabProxyIp().forEach(System.out::println);
} }
蚂蚁代理免费代理ip爬取(端口图片显示+token检查)的更多相关文章
- requests 使用免费的代理ip爬取网站
import requests import queue import threading from lxml import etree #要爬取的URL url = "http://xxx ...
- Scrapy爬取美女图片第三集 代理ip(上) (原创)
首先说一声,让大家久等了.本来打算那天进行更新的,可是一细想,也只有我这样的单身狗还在做科研,大家可能没心思看更新的文章,所以就拖到了今天.不过忙了521,522这一天半,我把数据库也添加进来了,修复 ...
- Scrapy爬取美女图片第四集 突破反爬虫(上)
本周又和大家见面了,首先说一下我最近正在做和将要做的一些事情.(我的新书<Python爬虫开发与项目实战>出版了,大家可以看一下样章) 技术方面的事情:本次端午假期没有休息,正在使用fl ...
- 百度图片爬虫-python版-如何爬取百度图片?
上一篇我写了如何爬取百度网盘的爬虫,在这里还是重温一下,把链接附上: http://www.cnblogs.com/huangxie/p/5473273.html 这一篇我想写写如何爬取百度图片的爬虫 ...
- Python爬取谷歌街景图片
最近有个需求是要爬取街景图片,国内厂商百度高德和腾讯地图都没有开放接口,查询资料得知谷歌地图开放街景api 谷歌捷径申请key地址:https://developers.google.com/maps ...
- Python爬虫学习(6): 爬取MM图片
为了有趣我们今天就主要去爬取以下MM的图片,并将其按名保存在本地.要爬取的网站为: 大秀台模特网 1. 分析网站 进入官网后我们发现有很多分类: 而我们要爬取的模特中的女模内容,点进入之后其网址为:h ...
- Scrapy爬取美女图片 (原创)
有半个月没有更新了,最近确实有点忙.先是华为的比赛,接着实验室又有项目,然后又学习了一些新的知识,所以没有更新文章.为了表达我的歉意,我给大家来一波福利... 今天咱们说的是爬虫框架.之前我使用pyt ...
- Scrapy-多层爬取天堂图片网
1.根据图片分类对爬取的图片进行分类 开发者选项 --> 找到分类地址 爬取每个分类的地址通过回调函数传入下一层 name = 'sky'start_urls = ['http: ...
- python3爬取女神图片,破解盗链问题
title: python3爬取女神图片,破解盗链问题 date: 2018-04-22 08:26:00 tags: [python3,美女,图片抓取,爬虫, 盗链] comments: true ...
随机推荐
- 设置Nginx+php-fpm显示错误信息
Begin 最近在用PHP写后台程序,但是有错误不会显示简直坑爹,全都是200这样的错误代码而已= =... 于是 于是就搜索如何打开错误显示,然后就在博客里面记录一下 修改配置文件 /etc/php ...
- hdu1051 Wooden Sticks---贪心
题目链接: http://acm.hdu.edu.cn/showproblem.php?pid=1051 题目大意:给你n根木棍的长度和重量.根据要求求出制作该木棍的最短时间.建立第一个木棍需要1分钟 ...
- angularjs购物车练习
本文是一个简单的购物车练习,功能包括增加.减少某商品的数量,从而影响该商品的购买总价以及所有商品的购买总价:从购物车内移除一项商品:清空购物车. 页面效果如图: 若使用js或jQuery来实现这个页面 ...
- vscode设置出错, 无法自动补全
问题: 之前设置的没问题, vscode重装后, 发现vscode里面的设置还在, 但敲代码却无法识别虚拟环境中的包了, 因此相关的内容也无法自动补全. 解决: 后来发现, 实际上设置没有出错, 但重 ...
- 用js来实现那些数据结构06(队列)
其实队列跟栈有很多相似的地方,包括其中的一些方法和使用方式,只是队列使用了与栈完全不同的原则,栈是后进先出原则,而队列是先进先出(First In First Out). 一.队列 队列是一种特 ...
- 使用 C# (.NET Core) 实现模板方法模式 (Template Method Pattern)
本文的概念内容来自深入浅出设计模式一书. 项目需求 有一家咖啡店, 供应咖啡和茶, 它们的工序如下: 咖啡: 茶: 可以看到咖啡和茶的制作工序是差不多的, 都是有4步, 其中有两步它们两个是一样的, ...
- [LeetCode] Split Array into Consecutive Subsequences 将数组分割成连续子序列
You are given an integer array sorted in ascending order (may contain duplicates), you need to split ...
- [LeetCode] Construct Binary Tree from String 从字符串创建二叉树
You need to construct a binary tree from a string consisting of parenthesis and integers. The whole ...
- Vue2.0父子组件之间的双向数据绑定问题解决方案
对于vue 1.0项目代码,如果把vue换成vue 2.0,那么之后项目代码就完全奔溃不能运行,vue 2.0在父子组件数据绑定的变化(不再支持双向绑定)颠覆了1.0的约定,很遗憾. 解决方案只有两种 ...
- 51nod 1981 如何愉快地与STL玩耍
Description 驴蛋蛋在愉快地与STL玩耍 突然间小A跳了出来对驴蛋蛋说,看你与STL玩的很开心啊,那我给你一个大小为N的vector,这个vector上每个位置上是一个set, 每次我会在闭 ...