容器技术之Docker-swarm
前文我聊到了docker machine的简单使用和基本原理的说明,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/13160915.html;今天我们来聊一聊docker集群管理工具docker swarm;docker swarm是docker 官方的集群管理工具,它可以让跨主机节点来创建,管理docker 集群;它的主要作用就是可以把多个节点主机的docker环境整合成一个大的docker资源池;docker swarm面向的就是这个大的docker 资源池在上面管理容器;在前面我们都只是在单台主机上的创建,管理容器,但是在生产环境中通常一台物理机上的容器实在是不能够满足当前业务的需求,所以docker swarm提供了一种集群解决方案,方便在多个节点上创建,管理容器;接下来我们来看看docker swarm集群的搭建过程吧;
docker swarm 在我们安装好docker时就已经安装好了,我们可以使用docker info来查看
- [root@node1 ~]# docker info
- Client:
- Debug Mode: false
- Server:
- Containers: 0
- Running: 0
- Paused: 0
- Stopped: 0
- Images: 0
- Server Version: 19.03.11
- Storage Driver: overlay2
- Backing Filesystem: xfs
- Supports d_type: true
- Native Overlay Diff: true
- Logging Driver: json-file
- Cgroup Driver: cgroupfs
- Plugins:
- Volume: local
- Network: bridge host ipvlan macvlan null overlay
- Log: awslogs fluentd gcplogs gelf journald json-file local logentries splunk syslog
- Swarm: inactive
- Runtimes: runc
- Default Runtime: runc
- Init Binary: docker-init
- containerd version: 7ad184331fa3e55e52b890ea95e65ba581ae3429
- runc version: dc9208a3303feef5b3839f4323d9beb36df0a9dd
- init version: fec3683
- Security Options:
- seccomp
- Profile: default
- Kernel Version: 3.10.0-693.el7.x86_64
- Operating System: CentOS Linux 7 (Core)
- OSType: linux
- Architecture: x86_64
- CPUs: 4
- Total Memory: 3.686GiB
- Name: docker-node01
- ID: 4HXP:YJ5W:4SM5:NAPM:NXPZ:QFIU:ARVJ:BYDG:KVWU:5AAJ:77GC:X7GQ
- Docker Root Dir: /var/lib/docker
- Debug Mode: false
- Registry: https://index.docker.io/v1/
- Labels:
- provider=generic
- Experimental: false
- Insecure Registries:
- 127.0.0.0/8
- Live Restore Enabled: false
- [root@node1 ~]#
提示:从上面的信息可以看到,swarm是出于非活跃状态,这是因为我们还没有初始化集群,所以对应的swarm是处于inactive状态;
初始化集群
- [root@docker-node01 ~]# docker swarm init --advertise-addr 192.168.0.41
- Swarm initialized: current node (ynz304mbltxx10v3i15ldkmj1) is now a manager.
- To add a worker to this swarm, run the following command:
- docker swarm join --token SWMTKN-1-6difxlq3wc8emlwxzuw95gp8rmvbz2oq62kux3as0e4rbyqhk3-2m9x12n102ca4qlyjpseobzik 192.168.0.41:2377
- To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
- [root@docker-node01 ~]#
提示:从上面反馈的信息可以看到,集群初始化成功,并且告诉我们当前节点为管理节点,如果想要其他节点加入到该集群,可以使用在对应节点上运行docker swarm join --token SWMTKN-1-6difxlq3wc8emlwxzuw95gp8rmvbz2oq62kux3as0e4rbyqhk3-2m9x12n102ca4qlyjpseobzik 192.168.0.41:2377 这个命令,就把对应节点当作work节点加入到该集群,如果想要以管理节点身份加入到集群,我们需要在当前终端运行docker swarm join-token manager命令
- [root@docker-node01 ~]# docker swarm join-token manager
- To add a manager to this swarm, run the following command:
- docker swarm join --token SWMTKN-1-6difxlq3wc8emlwxzuw95gp8rmvbz2oq62kux3as0e4rbyqhk3-dqjeh8hp6cp99bksjc03b8yu3 192.168.0.41:2377
- [root@docker-node01 ~]#
提示:我们执行docker swarm join-token manager命令,它返回了一个命令,并告诉我们添加一个管理节点,在对应节点上执行docker swarm join --token SWMTKN-1-6difxlq3wc8emlwxzuw95gp8rmvbz2oq62kux3as0e4rbyqhk3-dqjeh8hp6cp99bksjc03b8yu3 192.168.0.41:2377命令即可;
到此docker swarm集群就初始化完毕,接下来我们把其他节点加入到该集群
把docker-node02以work节点身份加入集群
- [root@node2 ~]# docker swarm join --token SWMTKN-1-6difxlq3wc8emlwxzuw95gp8rmvbz2oq62kux3as0e4rbyqhk3-2m9x12n102ca4qlyjpseobzik 192.168.0.41:2377
- This node joined a swarm as a worker.
- [root@node2 ~]#
提示:没有报错就表示加入集群成功;我们可以使用docker info来查看当前的docker 环境详细信息
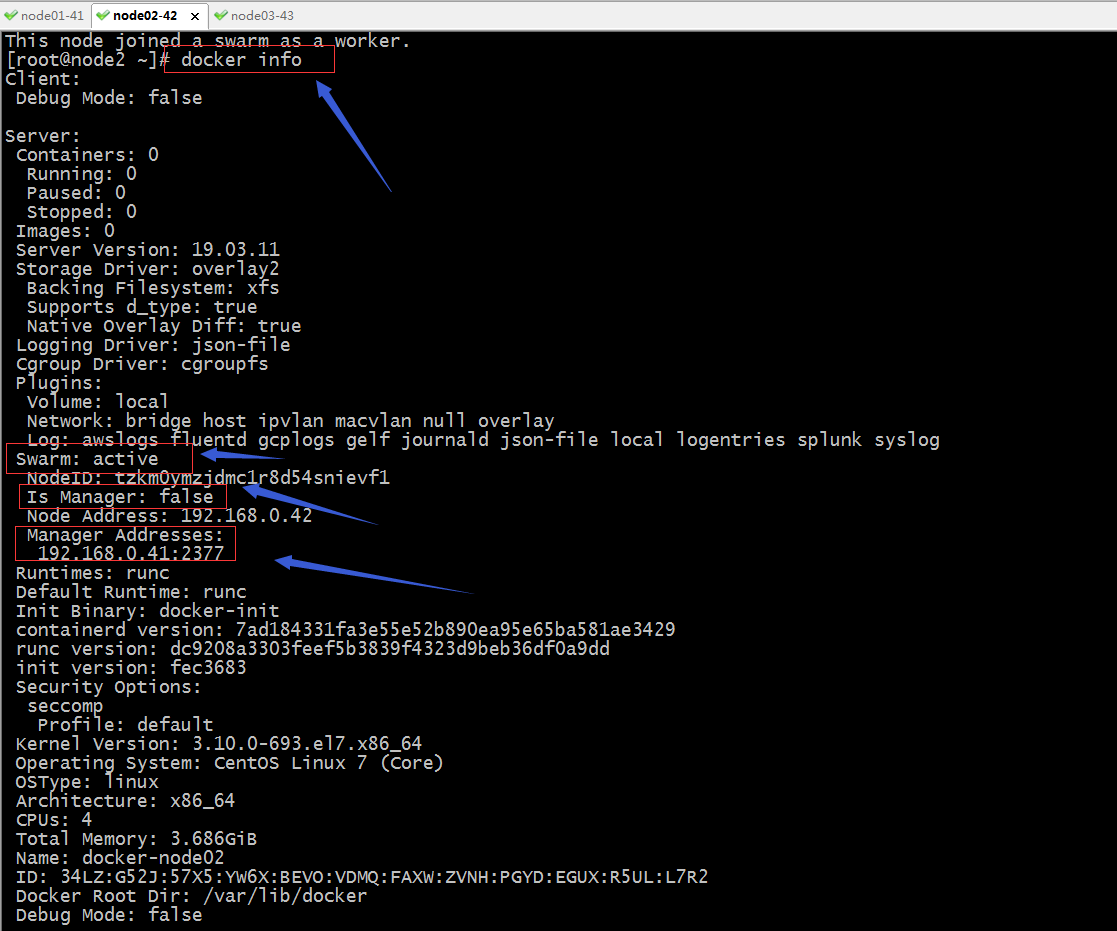
提示:从上面的信息可以看到,在docker-node02这台主机上docker swarm 已经激活,并且可以看到管理节点的地址;除了以上方式可以确定docker-node02以及加入到集群;我们还可以在管理节点上运行docker node ls 查看集群节点信息;
查看集群节点信息

提示:在管理节点上运行docker node ls 就可以看到当前集群里有多少节点已经成功加入进来;
把docker-node03以管理节点身份加入到集群

提示:可以看到docker-node03已经是集群的管理节点,所以可以在docker-node03这个节点执行docker node ls 命令;到此docker swarm集群就搭建好了;接下来我们来说一说docker swarm集群的常用管理
有关节点相关管理命令
docker node ls :列出当前节点上的所有节点
- [root@docker-node01 ~]# docker node ls
- ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
- ynz304mbltxx10v3i15ldkmj1 * docker-node01 Ready Active Leader 19.03.11
- tzkm0ymzjdmc1r8d54snievf1 docker-node02 Ready Active 19.03.11
- aeo8j7zit9qkoeeft3j0q1h0z docker-node03 Ready Active Reachable 19.03.11
- [root@docker-node01 ~]#
提示:该命令只能在管理节点上执行;
docker node inspect :查看指定节点的详细信息;
- [root@docker-node01 ~]# docker node inspect docker-node01
- [
- {
- "ID": "ynz304mbltxx10v3i15ldkmj1",
- "Version": {
- "Index": 9
- },
- "CreatedAt": "2020-06-20T05:57:17.57684293Z",
- "UpdatedAt": "2020-06-20T05:57:18.18575648Z",
- "Spec": {
- "Labels": {},
- "Role": "manager",
- "Availability": "active"
- },
- "Description": {
- "Hostname": "docker-node01",
- "Platform": {
- "Architecture": "x86_64",
- "OS": "linux"
- },
- "Resources": {
- "NanoCPUs": 4000000000,
- "MemoryBytes": 3958075392
- },
- "Engine": {
- "EngineVersion": "19.03.11",
- "Labels": {
- "provider": "generic"
- },
- "Plugins": [
- {
- "Type": "Log",
- "Name": "awslogs"
- },
- {
- "Type": "Log",
- "Name": "fluentd"
- },
- {
- "Type": "Log",
- "Name": "gcplogs"
- },
- {
- "Type": "Log",
- "Name": "gelf"
- },
- {
- "Type": "Log",
- "Name": "journald"
- },
- {
- "Type": "Log",
- "Name": "json-file"
- },
- {
- "Type": "Log",
- "Name": "local"
- },
- {
- "Type": "Log",
- "Name": "logentries"
- },
- {
- "Type": "Log",
- "Name": "splunk"
- },
- {
- "Type": "Log",
- "Name": "syslog"
- },
- {
- "Type": "Network",
- "Name": "bridge"
- },
- {
- "Type": "Network",
- "Name": "host"
- },
- {
- "Type": "Network",
- "Name": "ipvlan"
- },
- {
- "Type": "Network",
- "Name": "macvlan"
- },
- {
- "Type": "Network",
- "Name": "null"
- },
- {
- "Type": "Network",
- "Name": "overlay"
- },
- {
- "Type": "Volume",
- "Name": "local"
- }
- ]
- },
- "TLSInfo": {
- "TrustRoot": "-----BEGIN CERTIFICATE-----\nMIIBaTCCARCgAwIBAgIUeBd/eSZ7WaiyLby9o1yWpjps3gwwCgYIKoZIzj0EAwIw\nEzERMA8GA1UEAxMIc3dhcm0tY2EwHhcNMjAwNjIwMDU1MjAwWhcNNDAwNjE1MDU1\nMjAwWjATMREwDwYDVQQDEwhzd2FybS1jYTBZMBMGByqGSM49AgEGCCqGSM49AwEH\nA0IABMsYxnGoPbM4gqb23E1TvOeQcLcY56XysLuF8tYKm56GuKpeD/SqXrUCYqKZ\nHV+WSqcM0fD1g+mgZwlUwFzNxhajQjBAMA4GA1UdDwEB/wQEAwIBBjAPBgNVHRMB\nAf8EBTADAQH/MB0GA1UdDgQWBBTV64kbvS83eRHyI6hdJeEIv3GmrTAKBggqhkjO\nPQQDAgNHADBEAiBBB4hLn0ijybJWH5j5rtMdAoj8l/6M3PXERnRSlhbcawIgLoby\newMHCnm8IIrUGe7s4CZ07iHG477punuPMKDgqJ0=\n-----END CERTIFICATE-----\n",
- "CertIssuerSubject": "MBMxETAPBgNVBAMTCHN3YXJtLWNh",
- "CertIssuerPublicKey": "MFkwEwYHKoZIzj0CAQYIKoZIzj0DAQcDQgAEyxjGcag9sziCpvbcTVO855BwtxjnpfKwu4Xy1gqbnoa4ql4P9KpetQJiopkdX5ZKpwzR8PWD6aBnCVTAXM3GFg=="
- }
- },
- "Status": {
- "State": "ready",
- "Addr": "192.168.0.41"
- },
- "ManagerStatus": {
- "Leader": true,
- "Reachability": "reachable",
- "Addr": "192.168.0.41:2377"
- }
- }
- ]
- [root@docker-node01 ~]#
docker node ps :列出指定节点上运行容器的清单
- [root@docker-node01 ~]# docker node ps
- ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
- [root@docker-node01 ~]# docker node ps docker-node01
- ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
- [root@docker-node01 ~]#
提示:类似docker ps 命令,我上面没有运行容器,所以看不到对应信息;默认不指定节点名称表示查看当前节点上的运行容器清单;
docker node rm :删除指定节点
- [root@docker-node01 ~]# docker node ls
- ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
- ynz304mbltxx10v3i15ldkmj1 * docker-node01 Ready Active Leader 19.03.11
- tzkm0ymzjdmc1r8d54snievf1 docker-node02 Ready Active 19.03.11
- aeo8j7zit9qkoeeft3j0q1h0z docker-node03 Ready Active Reachable 19.03.11
- [root@docker-node01 ~]# docker node rm docker-node03
- Error response from daemon: rpc error: code = FailedPrecondition desc = node aeo8j7zit9qkoeeft3j0q1h0z is a cluster manager and is a member of the raft cluster. It must be demoted to worker before removal
- [root@docker-node01 ~]# docker node rm docker-node02
- Error response from daemon: rpc error: code = FailedPrecondition desc = node tzkm0ymzjdmc1r8d54snievf1 is not down and can't be removed
- [root@docker-node01 ~]#
提示:删除节点前必须满足,被删除的节点不是管理节点,其次就是要删除的节点必须是down状态;
docker swarm leave:离开当前集群
- [root@docker-node03 ~]# docker ps
- CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
- e7958ffa16cd nginx "/docker-entrypoint.…" 28 seconds ago Up 26 seconds 80/tcp n1
- [root@docker-node03 ~]# docker swarm leave
- Error response from daemon: You are attempting to leave the swarm on a node that is participating as a manager. Removing this node leaves 1 managers out of 2. Without a Raft quorum your swarm will be inaccessible. The only way to restore a swarm that has lost consensus is to reinitialize it with `--force-new-cluster`. Use `--force` to suppress this message.
- [root@docker-node03 ~]# docker swarm leave -f
- Node left the swarm.
- [root@docker-node03 ~]#
提示:管理节点默认是不允许离开集群的,如果强制使用-f选项离开集群,会导致在其他管理节点无法正常管理集群;
- [root@docker-node01 ~]# docker node ls
- Error response from daemon: rpc error: code = Unknown desc = The swarm does not have a leader. It's possible that too few managers are online. Make sure more than half of the managers are online.
- [root@docker-node01 ~]#
提示:我们在docker-node01上现在就不能使用docker node ls 来查看集群节点列表了;解决办法重新初始化集群;
- [root@docker-node01 ~]# docker node ls
- Error response from daemon: rpc error: code = Unknown desc = The swarm does not have a leader. It's possible that too few managers are online. Make sure more than half of the managers are online.
- [root@docker-node01 ~]# docker swarm init --advertise-addr 192.168.0.41
- Error response from daemon: This node is already part of a swarm. Use "docker swarm leave" to leave this swarm and join another one.
- [root@docker-node01 ~]# docker swarm init --force-new-cluster
- Swarm initialized: current node (ynz304mbltxx10v3i15ldkmj1) is now a manager.
- To add a worker to this swarm, run the following command:
- docker swarm join --token SWMTKN-1-6difxlq3wc8emlwxzuw95gp8rmvbz2oq62kux3as0e4rbyqhk3-2m9x12n102ca4qlyjpseobzik 192.168.0.41:2377
- To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
- [root@docker-node01 ~]# docker node ls
- ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
- ynz304mbltxx10v3i15ldkmj1 * docker-node01 Ready Active Leader 19.03.11
- tzkm0ymzjdmc1r8d54snievf1 docker-node02 Unknown Active 19.03.11
- aeo8j7zit9qkoeeft3j0q1h0z docker-node03 Down Active 19.03.11
- rm3j7cjvmoa35yy8ckuzoay46 docker-node03 Unknown Active 19.03.11
- [root@docker-node01 ~]#
提示:重新初始化集群不能使用docker swarm init --advertise-addr 192.168.0.41这种方式初始化,必须使用docker swarm init --force-new-cluster,该命令表示使用从当前状态强制创建一个集群;现在我们就可以使用docker node rm 把down状态的节点从集群删除;
删除down状态的节点
- [root@docker-node01 ~]# docker node ls
- ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
- ynz304mbltxx10v3i15ldkmj1 * docker-node01 Ready Active Leader 19.03.11
- tzkm0ymzjdmc1r8d54snievf1 docker-node02 Ready Active 19.03.11
- aeo8j7zit9qkoeeft3j0q1h0z docker-node03 Down Active 19.03.11
- rm3j7cjvmoa35yy8ckuzoay46 docker-node03 Down Active 19.03.11
- [root@docker-node01 ~]# docker node rm aeo8j7zit9qkoeeft3j0q1h0z rm3j7cjvmoa35yy8ckuzoay46
- aeo8j7zit9qkoeeft3j0q1h0z
- rm3j7cjvmoa35yy8ckuzoay46
- [root@docker-node01 ~]# docker node ls
- ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
- ynz304mbltxx10v3i15ldkmj1 * docker-node01 Ready Active Leader 19.03.11
- tzkm0ymzjdmc1r8d54snievf1 docker-node02 Ready Active 19.03.11
- [root@docker-node01 ~]#
docker node promote:把指定节点提升为管理节点
- [root@docker-node01 ~]# docker node ls
- ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
- ynz304mbltxx10v3i15ldkmj1 * docker-node01 Ready Active Leader 19.03.11
- tzkm0ymzjdmc1r8d54snievf1 docker-node02 Ready Active 19.03.11
- [root@docker-node01 ~]# docker node promote docker-node02
- Node docker-node02 promoted to a manager in the swarm.
- [root@docker-node01 ~]# docker node ls
- ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
- ynz304mbltxx10v3i15ldkmj1 * docker-node01 Ready Active Leader 19.03.11
- tzkm0ymzjdmc1r8d54snievf1 docker-node02 Ready Active Reachable 19.03.11
- [root@docker-node01 ~]#
docker node demote:把指定节点降级为work节点
- [root@docker-node01 ~]# docker node ls
- ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
- ynz304mbltxx10v3i15ldkmj1 * docker-node01 Ready Active Leader 19.03.11
- tzkm0ymzjdmc1r8d54snievf1 docker-node02 Ready Active Reachable 19.03.11
- [root@docker-node01 ~]# docker node demote docker-node02
- Manager docker-node02 demoted in the swarm.
- [root@docker-node01 ~]# docker node ls
- ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
- ynz304mbltxx10v3i15ldkmj1 * docker-node01 Ready Active Leader 19.03.11
- tzkm0ymzjdmc1r8d54snievf1 docker-node02 Ready Active 19.03.11
- [root@docker-node01 ~]#
docker node update:更新指定节点
- [root@docker-node01 ~]# docker node ls
- ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
- ynz304mbltxx10v3i15ldkmj1 * docker-node01 Ready Active Leader 19.03.11
- tzkm0ymzjdmc1r8d54snievf1 docker-node02 Ready Active 19.03.11
- [root@docker-node01 ~]# docker node update docker-node01 --availability drain
- docker-node01
- [root@docker-node01 ~]# docker node ls
- ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
- ynz304mbltxx10v3i15ldkmj1 * docker-node01 Ready Drain Leader 19.03.11
- tzkm0ymzjdmc1r8d54snievf1 docker-node02 Ready Active 19.03.11
- [root@docker-node01 ~]#
提示:以上命令把docker-node01的availability属性更改为drain,这样更改后docker-node01的资源就不会被调度到用来运行容器;
为docker swarm集群添加图形界面
- [root@docker-node01 docker]# docker run --name v1 -d -p 8888:8080 -e HOST=192.168.0.41 -e PORT=8080 -v /var/run/docker.sock:/var/run/docker.sock docker-registry.io/test/visualizer
- Unable to find image 'docker-registry.io/test/visualizer:latest' locally
- latest: Pulling from test/visualizer
- cd784148e348: Pull complete
- f6268ae5d1d7: Pull complete
- 97eb9028b14b: Pull complete
- 9975a7a2a3d1: Pull complete
- ba903e5e6801: Pull complete
- 7f034edb1086: Pull complete
- cd5dbf77b483: Pull complete
- 5e7311667ddb: Pull complete
- 687c1072bfcb: Pull complete
- aa18e5d3472c: Pull complete
- a3da1957bd6b: Pull complete
- e42dbf1c67c4: Pull complete
- 5a18b01011d2: Pull complete
- Digest: sha256:54d65cbcbff52ee7d789cd285fbe68f07a46e3419c8fcded437af4c616915c85
- Status: Downloaded newer image for docker-registry.io/test/visualizer:latest
- 3c15b186ff51848130393944e09a427bd40d2504c54614f93e28477a4961f8b6
- [root@docker-node01 docker]# docker ps
- CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
- 3c15b186ff51 docker-registry.io/test/visualizer "npm start" 6 seconds ago Up 5 seconds (health: starting) 0.0.0.0:8888->8080/tcp v1
- [root@docker-node01 docker]#
提示:我上面的命令是从私有仓库中下载的镜像,原因是互联网下载太慢了,所以我提前下载好,放在私有仓库中;有关私有仓库的搭建使用,请参考https://www.cnblogs.com/qiuhom-1874/p/13061984.html或者https://www.cnblogs.com/qiuhom-1874/p/13058338.html;在管理节点上运行visualizer容器后,我们就可以直接访问该管理节点地址的8888端口,就可以看到当前容器的情况;如下图
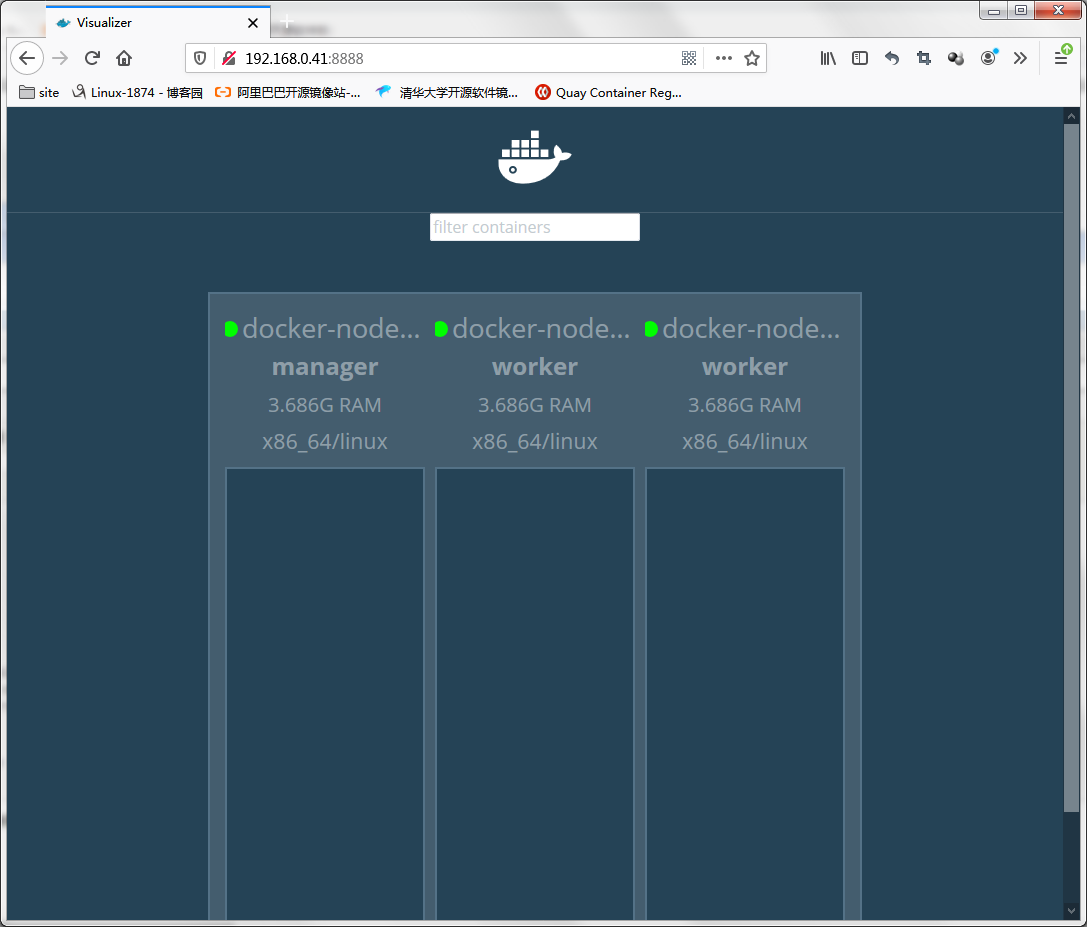
提示:从上面的信息可以看到当前集群有一个管理节点和两个work节点;现目前集群里没有运行任何容器;
在docker swarm运行服务
- [root@docker-node01 ~]# docker service create --name myweb docker-registry.io/test/nginx:latest
- i0j6wvvtfe1360ibj04jxulmd
- overall progress: 1 out of 1 tasks
- 1/1: running [==================================================>]
- verify: Service converged
- [root@docker-node01 ~]# docker service ls
- ID NAME MODE REPLICAS IMAGE PORTS
- i0j6wvvtfe13 myweb replicated 1/1 docker-registry.io/test/nginx:latest
- [root@docker-node01 ~]# docker service ps myweb
- ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
- 99y8towew77e myweb.1 docker-registry.io/test/nginx:latest docker-node03 Running Running 1 minutes ago
- [root@docker-node01 ~]#
提示:docker service create 表示在当前swarm集群环境中创建一个服务;以上命令表示在swarm集群上创建一个名为myweb的服务,用docker-registry.io/test/nginx:latest镜像;默认情况下只启动一个副本;
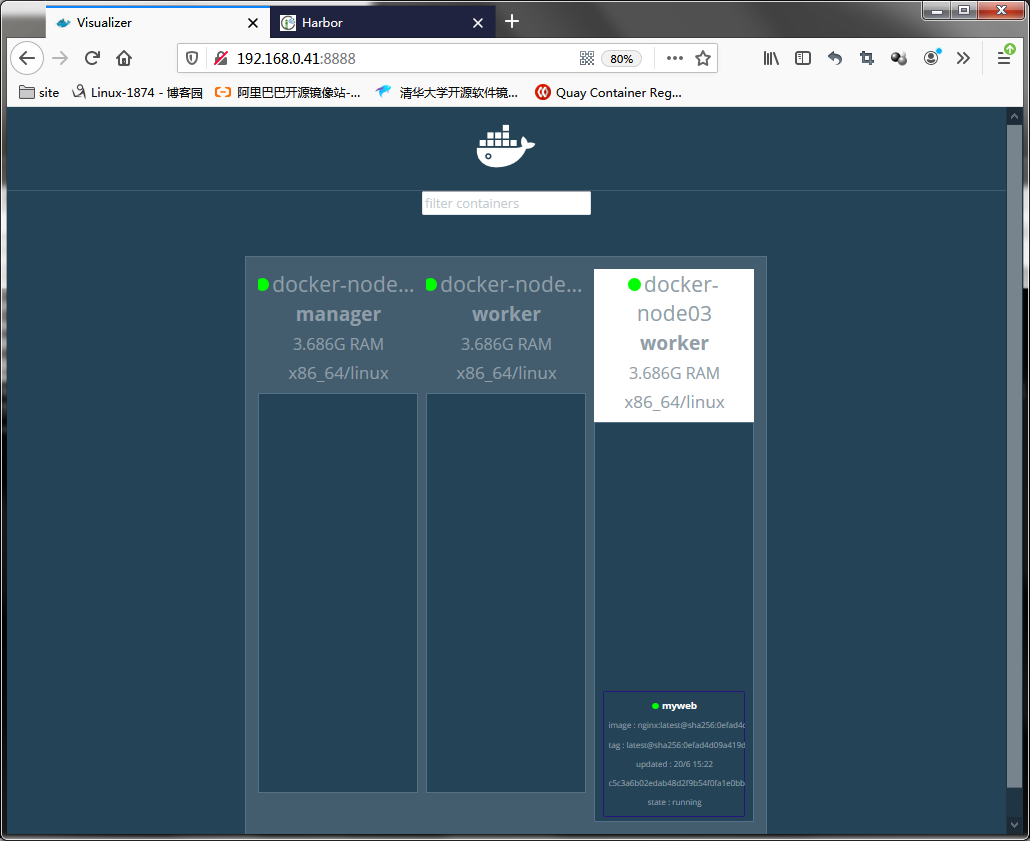
提示:可以看到当前集群中运行了一个myweb的容器,并且运行在docker-node03这台主机上;
在swarm 集群上创建多个副本服务
- [root@docker-node01 ~]# docker service create --replicas 3 --name web docker-registry.io/test/nginx:latest
- mbiap412jyugfpi4a38mb5i1k
- overall progress: 3 out of 3 tasks
- 1/3: running [==================================================>]
- 2/3: running [==================================================>]
- 3/3: running [==================================================>]
- verify: Service converged
- [root@docker-node01 ~]# docker service ls
- ID NAME MODE REPLICAS IMAGE PORTS
- i0j6wvvtfe13 myweb replicated 1/1 docker-registry.io/test/nginx:latest
- mbiap412jyug web replicated 3/3 docker-registry.io/test/nginx:latest
- [root@docker-node01 ~]#docker service ps web
- ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
- 1rt0e7u4senz web.1 docker-registry.io/test/nginx:latest docker-node02 Running Running 28 seconds ago
- 31ll0zu7udld web.2 docker-registry.io/test/nginx:latest docker-node02 Running Running 28 seconds ago
- l9jtbswl2x22 web.3 docker-registry.io/test/nginx:latest docker-node03 Running Running 32 seconds ago
- [root@docker-node01 ~]#
提示:--replicas选项用来指定期望运行的副本数量,该选项会在集群上创建我们指定数量的副本,即便我们集群中有节点宕机,它始终会创建我们指定数量的容器在集群上运行着;
测试:把docker-node03关机,看看我们运行的服务是否会迁移到节点2上呢?
docker-node03关机前
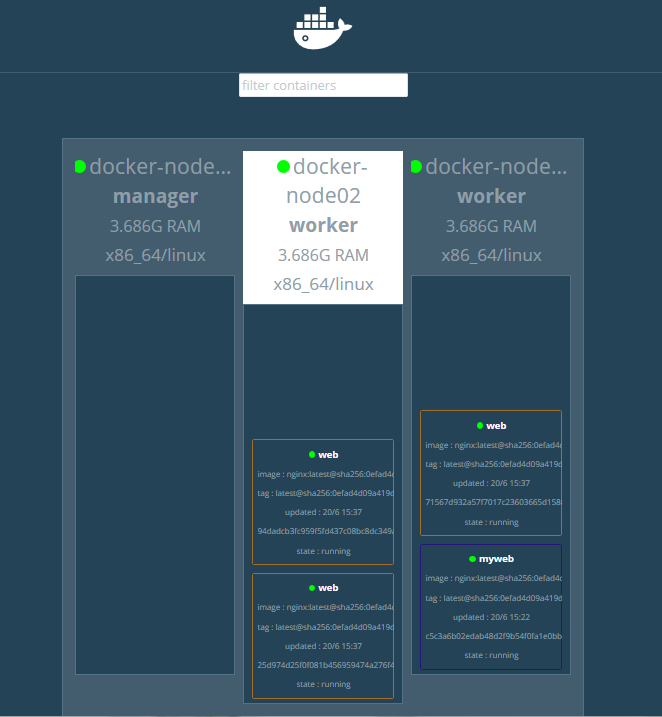
docker-node03关机后
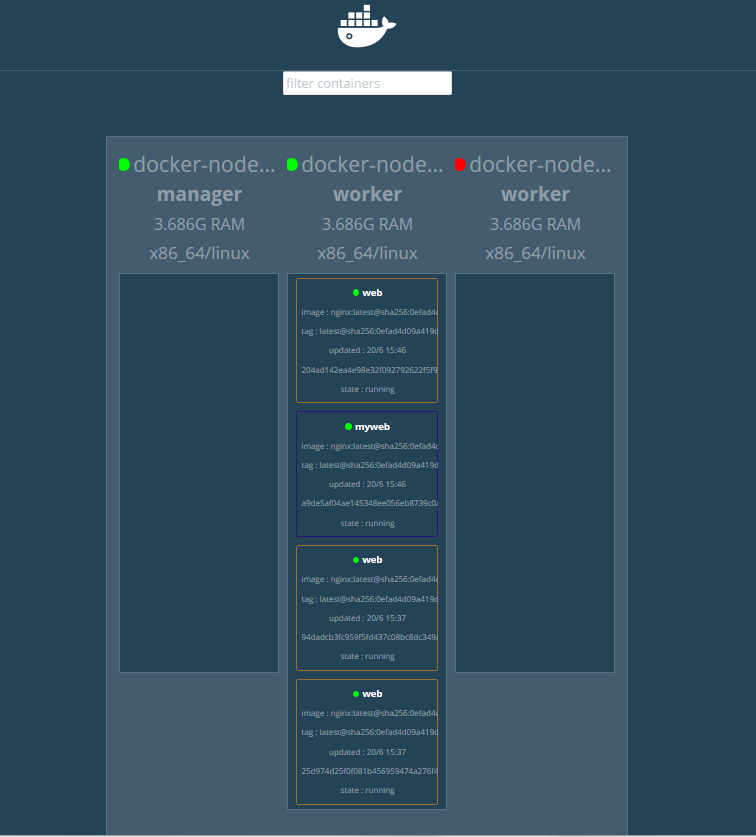
提示:从上面的截图可以看到,当节点3宕机后,节点3上跑的所有容器,会全部迁移到节点2上来;这就是创建容器时用--replicas选项的作用;总结一点,创建服务使用副本模式,该服务所在节点故障,它会把对应节点上的服务迁移到其他节点上;这里需要提醒一点的是,只要集群上的服务副本满足我们指定的replicas的数量,即便故障的节点恢复了,它是不会把服务迁移回来的;
- [root@docker-node01 ~]# docker service ps web
- ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
- 1rt0e7u4senz web.1 docker-registry.io/test/nginx:latest docker-node02 Running Running 15 minutes ago
- 31ll0zu7udld web.2 docker-registry.io/test/nginx:latest docker-node02 Running Running 15 minutes ago
- t3gjvsgtpuql web.3 docker-registry.io/test/nginx:latest docker-node02 Running Running 6 minutes ago
- l9jtbswl2x22 \_ web.3 docker-registry.io/test/nginx:latest docker-node03 Shutdown Shutdown 23 seconds ago
- [root@docker-node01 ~]#
提示:我们在管理节点查看服务列表,可以看到它迁移服务就是把对应节点上的副本停掉,然后在其他节点创建一个新的副本;
服务伸缩
- [root@docker-node01 ~]# docker service ls
- ID NAME MODE REPLICAS IMAGE PORTS
- i0j6wvvtfe13 myweb replicated 1/1 docker-registry.io/test/nginx:latest
- mbiap412jyug web replicated 3/3 docker-registry.io/test/nginx:latest
- [root@docker-node01 ~]# docker service scale myweb=3 web=5
- myweb scaled to 3
- web scaled to 5
- overall progress: 3 out of 3 tasks
- 1/3: running [==================================================>]
- 2/3: running [==================================================>]
- 3/3: running [==================================================>]
- verify: Service converged
- overall progress: 5 out of 5 tasks
- 1/5: running [==================================================>]
- 2/5: running [==================================================>]
- 3/5: running [==================================================>]
- 4/5: running [==================================================>]
- 5/5: running [==================================================>]
- verify: Service converged
- [root@docker-node01 ~]# docker service ls
- ID NAME MODE REPLICAS IMAGE PORTS
- i0j6wvvtfe13 myweb replicated 3/3 docker-registry.io/test/nginx:latest
- mbiap412jyug web replicated 5/5 docker-registry.io/test/nginx:latest
- [root@docker-node01 ~]# docker service ps myweb web
- ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
- j7w490h2lons myweb.1 docker-registry.io/test/nginx:latest docker-node02 Running Running 12 minutes ago
- 1rt0e7u4senz web.1 docker-registry.io/test/nginx:latest docker-node02 Running Running 21 minutes ago
- 99y8towew77e myweb.1 docker-registry.io/test/nginx:latest docker-node03 Shutdown Shutdown 5 minutes ago
- en5rk0jf09wu myweb.2 docker-registry.io/test/nginx:latest docker-node03 Running Running 31 seconds ago
- 31ll0zu7udld web.2 docker-registry.io/test/nginx:latest docker-node02 Running Running 21 minutes ago
- h1hze7h819ca myweb.3 docker-registry.io/test/nginx:latest docker-node03 Running Running 30 seconds ago
- t3gjvsgtpuql web.3 docker-registry.io/test/nginx:latest docker-node02 Running Running 12 minutes ago
- l9jtbswl2x22 \_ web.3 docker-registry.io/test/nginx:latest docker-node03 Shutdown Shutdown 5 minutes ago
- od3ti2ixpsgc web.4 docker-registry.io/test/nginx:latest docker-node03 Running Running 31 seconds ago
- n1vur8wbmkgz web.5 docker-registry.io/test/nginx:latest docker-node03 Running Running 31 seconds ago
- [root@docker-node01 ~]#
提示:docker service scale 命令用来指定服务的副本数量,从而实现动态伸缩;
服务暴露
- [root@docker-node01 ~]# docker service ls
- ID NAME MODE REPLICAS IMAGE PORTS
- i0j6wvvtfe13 myweb replicated 3/3 docker-registry.io/test/nginx:latest
- mbiap412jyug web replicated 5/5 docker-registry.io/test/nginx:latest
- [root@docker-node01 ~]# docker service update --publish-add 80:80 myweb
- myweb
- overall progress: 3 out of 3 tasks
- 1/3: running [==================================================>]
- 2/3: running [==================================================>]
- 3/3: running [==================================================>]
- verify: Service converged
- [root@docker-node01 ~]#
提示:docker swarm集群中的服务暴露和docker里面的端口暴露原理是一样的,都是通过iptables 规则表或LVS规则实现的;
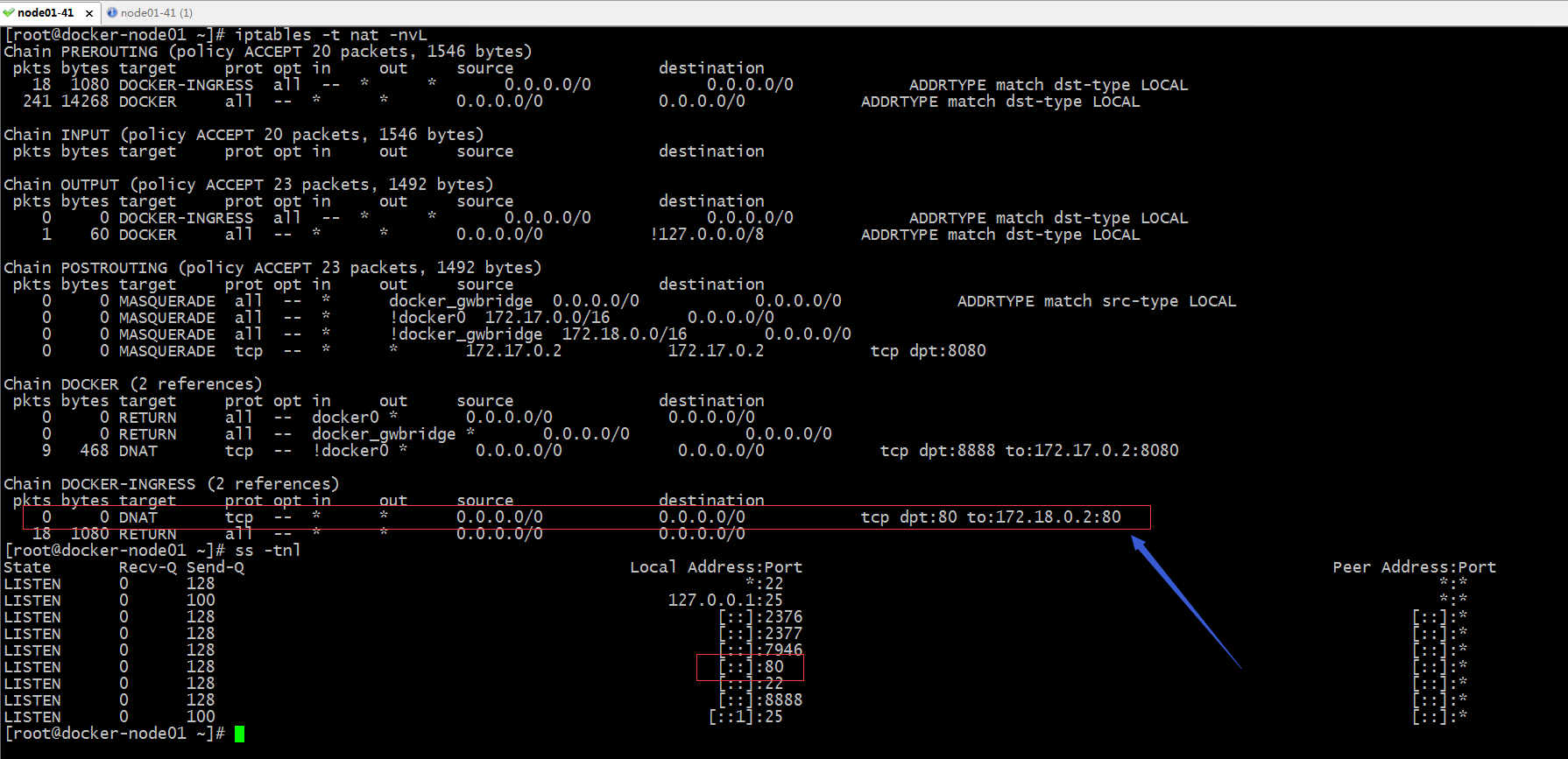
提示:我们可以在管理节点上看到对应80端口已经处于监听状态,并且在iptables规则表中多了一项访问本机80端口都DNAT到172.18.0.2的80上了;其实不光是在管理节点,在work节点上相应的iptables规则也都发生了变化;如下

提示:从上面的规则来看,我们访问节点地址的80端口,都会DNAT到172.18.0.2的80;
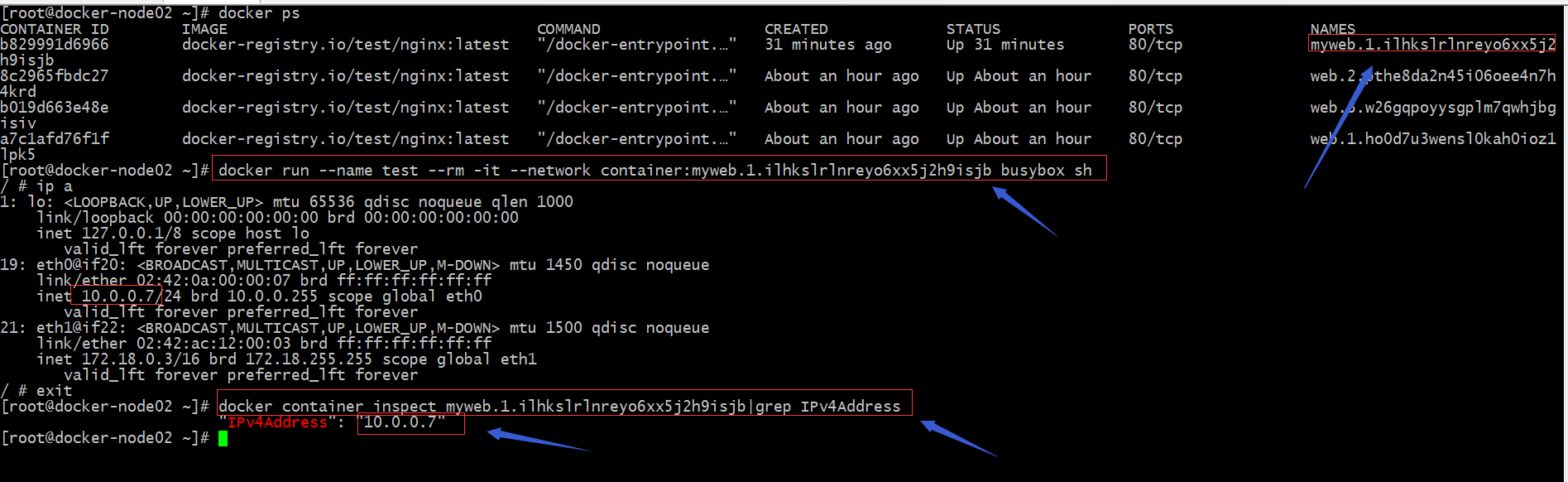
提示:从上面是显示结果看,我们不难得知在docker-node02运行myweb容器的内部地址是10.0.0.7,那为什么我们访问172.18.0.2是能够访问到容器内部的服务呢?原因是10.0.0.7是ingress网络,生效范围是swarm集群里的容器,类型是overlay叠加网络;简单讲ingress网络就是一个虚拟网络,真正通信的网络是靠docker_gwbridge网络,而docker_gwbridge网络是一个桥接网络,生效范围是local,所以我们访问节点地址的80,会通过iptables规则转发到docker_gwbridge网络上,docker_gwbridge会通过内核转发,把docker_gwbridge上的流量转发给ingress网络,从而实现访问到真正提供服务的容器;而在管理节点上能够访问到容器服务的原因是通过访问本机的80,通过iptables规则把流量转发给docker_gwbridge,docker_gwbridge通过内核把流量转发给ingress网络,因为ingress生效范围是整个swarm,这意味着管理节点和work节点共享一个swarm的网络空间,所以访问管理节点的80端口,实际上通过iptables规则和内核的转发,最终流量会发送到work节点上的某一台容器上,从而访问到服务;
测试:访问管理节点的80服务看看是否能够访问到nginx提供的页面呢?
- [root@docker-node02 ~]# docker ps
- CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
- b829991d6966 docker-registry.io/test/nginx:latest "/docker-entrypoint.…" About an hour ago Up About an hour 80/tcp myweb.1.ilhkslrlnreyo6xx5j2h9isjb
- 8c2965fbdc27 docker-registry.io/test/nginx:latest "/docker-entrypoint.…" 2 hours ago Up 2 hours 80/tcp web.2.pthe8da2n45i06oee4n7h4krd
- b019d663e48e docker-registry.io/test/nginx:latest "/docker-entrypoint.…" 2 hours ago Up 2 hours 80/tcp web.3.w26gqpoyysgplm7qwhjbgisiv
- a7c1afd76f1f docker-registry.io/test/nginx:latest "/docker-entrypoint.…" 2 hours ago Up 2 hours 80/tcp web.1.ho0d7u3wensl0kah0ioz1lpk5
- [root@docker-node02 ~]# docker exec -it myweb.1.ilhkslrlnreyo6xx5j2h9isjb bash
- root@b829991d6966:/# cd /usr/share/nginx/html/
- root@b829991d6966:/usr/share/nginx/html# ls
- 50x.html index.html
- root@b829991d6966:/usr/share/nginx/html# echo "this is docker-node02 index page" >index.html
- root@b829991d6966:/usr/share/nginx/html# cat index.html
- this is docker-node02 index page
- root@b829991d6966:/usr/share/nginx/html#
提示:以上是在docker-node02节点上对运行的nginx容器的主页进行了修改,接下我们访问管理节点的80端口,看看是否能够访问得到work节点上的容器,它们会有什么效果?是轮询?还是一直访问一个容器?
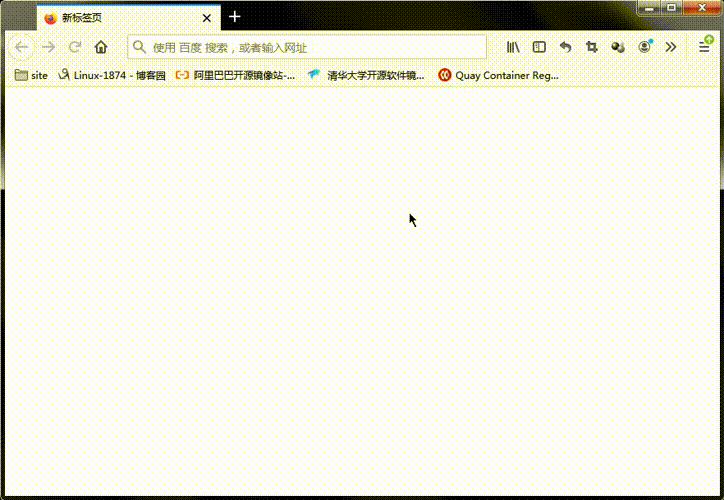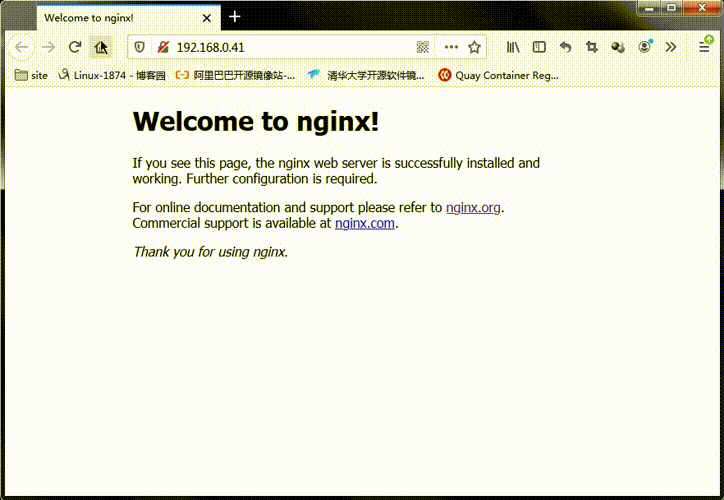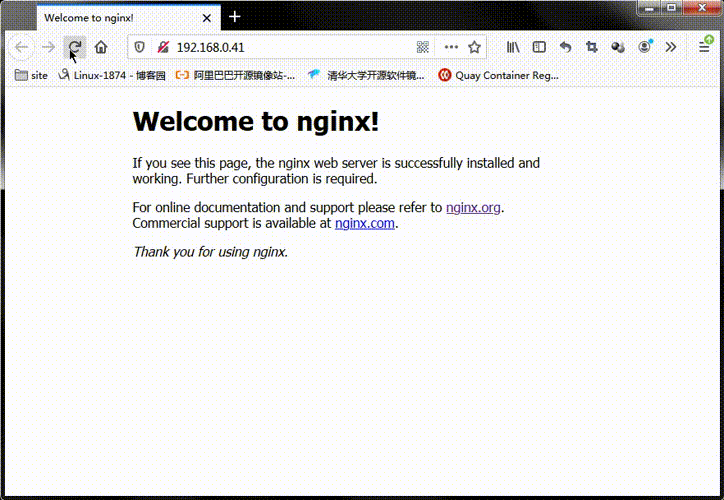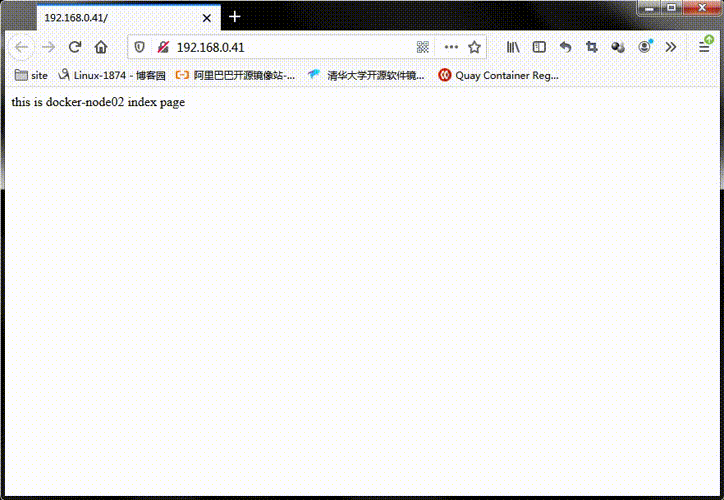
提示:可以看到我们访问管理节点的80端口,会轮询的访问到work节点上的容器;用浏览器测试可能存在缓存的问题,我们可以用curl命令测试比较准确;如下
- [root@docker-node03 ~]# docker ps
- CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
- f43fdb9ec7fc docker-registry.io/test/nginx:latest "/docker-entrypoint.…" 2 hours ago Up 2 hours 80/tcp myweb.3.pgdjutofb5thlk02aj7387oj0
- 4470785f3d00 docker-registry.io/test/nginx:latest "/docker-entrypoint.…" 2 hours ago Up 2 hours 80/tcp myweb.2.uwxbe182qzq00qgfc7odcmx87
- 7493dcac95ba docker-registry.io/test/nginx:latest "/docker-entrypoint.…" 2 hours ago Up 2 hours 80/tcp web.4.rix50fhlmg6m9txw9urk66gvw
- 118880d300f4 docker-registry.io/test/nginx:latest "/docker-entrypoint.…" 2 hours ago Up 2 hours 80/tcp web.5.vo7c7vjgpf92b0ryelb7eque0
- [root@docker-node03 ~]# docker exec -it myweb.2.uwxbe182qzq00qgfc7odcmx87 bash
- root@4470785f3d00:/# cd /usr/share/nginx/html/
- root@4470785f3d00:/usr/share/nginx/html# echo "this is myweb.2 index page" > index.html
- root@4470785f3d00:/usr/share/nginx/html# cat index.html
- this is myweb.2 index page
- root@4470785f3d00:/usr/share/nginx/html# exit
- exit
- [root@docker-node03 ~]# docker exec -it myweb.3.pgdjutofb5thlk02aj7387oj0 bash
- root@f43fdb9ec7fc:/# cd /usr/share/nginx/html/
- root@f43fdb9ec7fc:/usr/share/nginx/html# echo "this is myweb.3 index page" >index.html
- root@f43fdb9ec7fc:/usr/share/nginx/html# cat index.html
- this is myweb.3 index page
- root@f43fdb9ec7fc:/usr/share/nginx/html# exit
- exit
- [root@docker-node03 ~]#
提示:为了访问方便看得出效果,我们把myweb.2和myweb.3的主页都更改了内容
- [root@docker-node01 ~]# for i in {1..10} ; do curl 192.168.0.41; done
- this is myweb.3 index page
- this is docker-node02 index page
- this is myweb.2 index page
- this is myweb.3 index page
- this is docker-node02 index page
- this is myweb.2 index page
- this is myweb.3 index page
- this is docker-node02 index page
- this is myweb.2 index page
- this is myweb.3 index page
- [root@docker-node01 ~]#
提示:通过上面的测试,我们在使用--publish-add 暴露服务时,就相当于在管理节点创建了一个load balance;
容器技术之Docker-swarm的更多相关文章
- linux容器技术和Docker
linux容器技术和Docker 概述 Docker在一定程度上是LXC的增强版,早期的Docker使用LXC作为容器引擎,所以也可以说Docker是LXC的二次封装发行版,目前docker使用的容器 ...
- 容器技术|Docker三剑客之docker-compose
三剑客简介 docker-machine docker技术是基于Linux内核的cgroup技术实现的,那么问题来了,在非Linux平台上是否就不能使用docker技术了呢?答案是可以的,不过显然需要 ...
- 容器技术|Docker三剑客之docker-machine
docker-machine是什么? ocker-machine就是docker公司官方提出的,用于在各种平台上快速创建具有docker服务的虚拟机的技术,甚至可以通过指定driver来定制虚拟机的实 ...
- 容器技术与docker
名词介绍 IaaS:基础设施即服务,要搭建上层数据应用,先得通过互联网获得基础性设施服务 PaaS:平台即服务,搭建平台,集成应用产品,整合起来提供服务 SaaS:软件即服务,通过网络提供程序应用类服 ...
- 使用容器编排工具docker swarm安装clickhouse多机集群
1.首先需要安装docker最新版,docker 目前自带swarm容器编排工具 2.选中一台机器作为master,执行命令sudo docker swarm init [options] 3,再需 ...
- 容器技术之Docker基础入门
前文我们了解了下LXC的基础用法以及图形管理工具LXC WEB Panel的简单使用,有兴趣的朋友可以参考https://www.cnblogs.com/qiuhom-1874/p/12904188. ...
- 容器技术之Docker镜像
前文我们聊了下docker的基础使用方法,大概介绍了下docker的架构,管理镜像.运行容器.管理容器的一些相关命令说明:回顾请参考https://www.cnblogs.com/qiuhom-187 ...
- Docker容器技术-优化Docker镜像
一.优化Docker镜像 1.降低部署时间 一个大的Docker应用是如何影响在新Docker宿主机上的部署时间. (1)编写Dockerfile创建一个大Docker镜像 [root@bogon ~ ...
- 容器技术之Docker网络
上一篇博客我们主要聊了下docker镜像相关的说明以及怎样基于现有镜像制作镜像.分发镜像到docker仓库中的相关测试:回顾请参考https://www.cnblogs.com/qiuhom-1874 ...
- 容器技术之Docker数据卷
前一篇随笔中我们了解了docker的网络相关说明,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/12952616.html:今天我们来聊一聊docker的数据管 ...
随机推荐
- 上位机开发之三菱FX3U以太网通信实践
上次跟大家介绍了一下上位机与三菱Q系列PLC通信的案例,大家可以通过点击这篇文章:上位机开发之三菱Q系列PLC通信实践(←戳这里) 今天以三菱FX3U PLC为例,跟大家介绍一下,如何实现上位机与其之 ...
- Jenkins在Pod中实现Docker in Docker并用kubectl进行部署
Jenkins在Pod中实现Docker in Docker并用kubectl进行部署 准备工作 安装Jenkins Jenkins的kubernetes-plugin使用方法 说明 Jenkins的 ...
- Java 第十一届 蓝桥杯 省模拟赛 梅花桩
小明每天都要练功,练功中的重要一项是梅花桩. 小明练功的梅花桩排列成 n 行 m 列,相邻两行的距离为 1,相邻两列的距离也为 1. 小明站在第 1 行第 1 列上,他要走到第 n 行第 m 列上.小 ...
- Java实现 蓝桥杯VIP 算法训练 P1101
有一份提货单,其数据项目有:商品名(MC).单价(DJ).数量(SL).定义一个结构体prut,其成员是上面的三项数据.在主函数中定义一个prut类型的结构体数组,输入每个元素的值,计算并输出提货单的 ...
- Java实现 蓝桥杯VIP 算法训练 蜜蜂飞舞
时间限制:1.0s 内存限制:512.0MB 问题描述 "两只小蜜蜂呀,飞在花丛中呀--" 话说这天天上飞舞着两只蜜蜂,它们在跳一种奇怪的舞蹈.用一个空间直角坐标系来描述这个世界, ...
- Java中Collections类详细用法
1.sort(Collection)方法的使用(含义:对集合进行排序). 例:对已知集合c进行排序? public class Practice { public static void main(S ...
- java实现第六届蓝桥杯三羊献瑞
三羊献瑞 题目描述 观察下面的加法算式: 祥 瑞 生 辉 三 羊 献 瑞 三 羊 生 瑞 气 (如果有对齐问题,可以参看[图1.jpg]) 其中,相同的汉字代表相同的数字,不同的汉字代表不同的数字. ...
- 关于晶体问题TCXO_14.7456MHZ
如何判断热点的晶体好不好,首先,看偏移,偏移为0的晶体一般就是温补晶体,当然偏移是500或者几百固定的也是温补,但是不是我们首选的温补晶体 因为偏移为0非常省事,这是系统默认的偏移0,因此设置好频率就 ...
- HDFS ha 格式化报错:a shared edits dir must not be specified if HA is not enabled.
错误内容: Formatting using clusterid: CID-19921335-620f-4e72-a056-899702613a6b2019-01-12 07:28:46,986 IN ...
- Python + MySQL 批量查询百度收录
做SEO的同学,经常会遇到几百或几千个站点,然后对于收录情况去做分析的情况 那么多余常用的一些工具在面对几千个站点需要去做收录分析的时候,那么就显得不是很合适. 在此特意分享给大家一个批量查询百度收录 ...