08_提升方法_AdaBoost算法
今天是2020年2月24日星期一。一个又一个意外因素串连起2020这不平凡的一年,多么希望时间能够倒退。曾经觉得电视上科比的画面多么熟悉,现在全成了陌生和追忆。
GitHub:https://github.com/wangzycloud/statistical-learning-method
提升方法
引入
提升方法是一种常用的统计学习方法,还是比较容易理解的。在分类问题中,通过改变训练样本的权重,学习多个分类器,并将这些分类器进行线性组合,从而提高分类的性能。其实说白了,就是一个人干不好的活,我让两个人干;两个人干不好,那就三个人四个人都来干。但是人多了不能像三个和尚那样没水喝,都不干活。包工头要采取一些措施,措施一:一个人干活的时候,哪里干的不好?就让第二个人补充在这个地方;两个人干活的时候,哪里干的不好?就让第三个人补充在这个地方。措施二:这三四个人在同一个地方干活,怎样确定这个活的结果干的好不好呢?有的人干活细致认真,自然对结果增益大;干活粗糙的,对结果增益不多,因此需要有一种组合策略进行判断。通过几个人共同努力,就解决了一个人干不好的事情。
接下来的内容,将按照书中顺序,先介绍提升方法的思路和代表性的提升算法AdaBoost;再从前向分步加法模型角度解释AdaBoost;最后看一个具体实例—提升树。
提升方法AdaBoost算法
提升方法基于这样一种思想:对于一个复杂的任务来说,将多个专家的判断进行适当的综合所得出的判断,要比其中任何一个专家单独的判断好。实际上,就是“三个臭皮匠顶个诸葛亮“的道理。书中上来提到了两个稍晦涩的概念“强可学习”、“弱可学习”,下文没有继续阐述这两个概念,这里简单的复述一下。在概率近似正确学习的框架中(不懂),一个概念,如果存在一个多项式的学习算法能够学习它,并且正确率很高,那么就称这个概念是强可学习的;一个概念,如果存在一个多项式的学习算法能够学习它,学习的正确率仅比随机猜测略好,那么就称这个概念是弱可学习的。这两个概念之间的相互关系,被证明是等价的,也就是说在一定的学习框架下,一个概念是强可学习的充分必要条件是这个概念是弱可学习的。(模型效果好==》强可学习;模型效果差==》弱可学习;两者有联系)
这样一来,在学习的过程中如果已经发现了“弱学习算法”,那么能否将它提升为“强学习算法”。我们知道,发现弱学习算法通常要比发现强学习算法容易得多,如何具体实施提升,是我们开发提升方法时所要解决的问题。
对于分类问题而言,给定一个训练数据样本集,求比较粗糙的分类规则(弱分类器)要比求精确的分类规则容易得多。提升方法就是从弱学习算法出发,反复学习,得到一系列弱分类器(又称为基本分类器),然后组合这些弱分类器,构成一个强分类器。并且大多数的提升方法都是改变训练数据的概率分布(训练数据的权值分布),针对不同的训练数据分布调用弱学习算法学习一系列弱分类器。可以理解为难分的数据加大权重,让下一个弱分类器重点学习该数据。
这样,对于提升方法来说,有两个问题需要解决:一是在每一轮如何改变训练数据的权值或概率分布;二是如何将弱分类器组合成一个强分类器。我们接下来要学习的AdaBoost算法,针对第一个问题,提高那些被前一轮分类器错误分类样本的权值,而降低那些被正确分类样本的权值。这样一来,那些没有得到正确分类的数据,由于其权重的加大而受到后一轮弱分类器的更多关注。于是,分类问题被一系列的弱分类器“分而治之”。针对第二个问题,AdaBoost采取加权多数表决的方法。具体的,加大分类误差率小的弱分类器的权值,使其在表决中起较大的作用;减小分类误差率大的弱分类器的权值,使其在表决中起到较小的作用。
AdaBoost算法
这里先简单的罗列AdaBoost算法过程,先赶完整体进度,后期编写代码时再整理细节。
假设给定一个二类分类的训练数据集



AdaBoost算法各个步骤的说明:
步骤(1)假设训练数据集具有均匀的权值分布,即每个训练样本在基本分类器的学习中作用相同,这一假设保证第一步能够在原始数据上学习基本分类器G1(x)。
步骤(2)AdaBoost反复学习基本分类器,在每一轮m=1,2,…,M顺次执行四步操作:
第a步,使用当前分布Dm加权的训练数据集,学习基本分类器Gm(x);
第b步,计算基本分类器Gm(x)在加权训练数据集上的分类误差率。实际上,第m个分类器的分类误差率,就是被分类器Gm(x)误分类样本的权值之和,这表明权重大的样本起的作用更大一些。如果将其误分类,则误差率大大增加,从而进一步影响Gm(x)的系数;
第c步,从公式8.8中,可以看出em≤1/2时,αm≥0,并且αm随着em的减小而增大,所以分类误差率越小的基本分类器在最终分类器中的作用越大;
第d步,更新训练数据的权值分布为下一轮做准备。可以看到,误分类样本在下一轮学习中起更大的作用,不改变所给的训练数据,而不断改变训练数据权值的分布,使得训练数据在基本分类器的学习中起不同的作用。
步骤(3)线性组合f(x)实现M个基本分类器的加权表决。系数αm表示了基本分类器Gm(x)的重要性,这里所有αm之和并不为1。f(x)的符号决定实例x的类,f(x)的绝对值表示分类的确信度。
AdaBoost的例子





AdaBoost算法的训练误差分析
该训练误差分析部分,用证明出来的定理形式,表明AdaBoost算法的最基本性质就是能在学习过程中不断减少训练误差。也就是“该算法能够降低在训练数据集的分类误差率”这件事用数学方式证明了。分别是AdaBoost训练误差上界定理8.1、二分类问题的AdaBoost训练误差上界定理8.2和推论8.1。



该定理说明,可以在每一轮选取适当的Gm使得Zm最小,从而使训练误差下降的最快。对于二分类问题,有定理8.2。

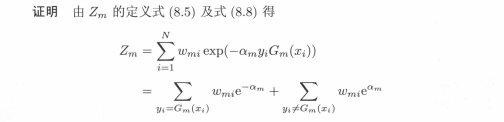


该推论表明,在此条件下,AdaBoost的训练误差是以指数速率下降的(看着像,不懂)。
AdaBoost算法的解释
本节内容从另外一个已经验证的模型来分析AdaBoost算法,并得到该算法的另外解释(我的理解是:AdaBoost算法是一般化的加法模型的特例,现在要从加法模型的角度分析)。可以认为AdaBoost算法是模型为加法模型、损失函数为指数函数、学习算法为前向分布算法时的二类分类学习方法。接下来的内容,先对加法模型及前向分布算法做简单介绍,通过对损失函数的分析,得到与AdaBoost算法等价的参数表示。
考虑加法模型,b(x)函数相当于基分类器:
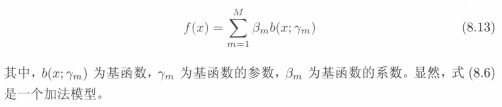
在给定训练数据及损失函数L(y,f(x))的条件下,学习加法模型f(x)成为经验风险极小化及损失函数极小化问题:
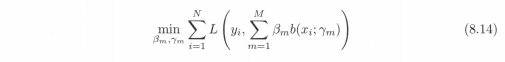
一般来说,加法模型f(x)中的M次基函数相加模型是一个复杂的优化问题,利用前向分布算法可以求解该优化问题。前向分布算法的思想是:因为学习的是加法模型,如果能够从前向后,每一步只学习一个基函数及其系数,逐步逼近优化目标8.14,那么就可以简化优化的复杂度。具体的,每一步只需优化以下损失函数(相当于每一步优化一个基函数,优化一个前进一个):
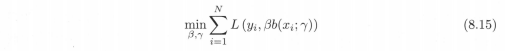
那么,前向分布算法如下:

本来公式8.14中的同时求解从m=1到M所有参数β、γ的优化问题,通过前向分布算法简化成了逐次求解各个β、γ的优化问题。
那么,前向分布算法与AdaBoost算法有什么联系呢?我们可以用定理的形式叙述之间的联系,也就是我们可以由前向分布算法推导出AdaBoost。定理如下:





以上内容直接截图了。本是作为笔记进行整理,数学推导插不上解释的嘴。要是以后文章被看到的多了,手推一下,再把内容整理上来。
提升树
我们知道,提升方法实际上是采用加法模型(即基函数的线性组合)与前向分步算法。本节提升树是以决策树作为基函数的提升方法,对分类问题决策树是二叉分类树,对回归问题决策树是二叉回归树。提升树被认为是统计学习中性能最好的方法之一。
在例8.1中看到的基本分类器x<v或x>v,可以看作是一个根节点直接连接两个叶节点的简单决策树,即所谓的决策树桩。提升树模型可以表示为决策树的加法模型:


即使数据中的输入与输出之间的关系很复杂,树的线性组合都可以很好地拟合训练数据。分类问题与回归问题的区别主要在于使用的损失函数不同,回归问题中一般使用平方误差损失函数,分类问题一般使用指数损失函数。对于二分类问题,提升树算法只需要将AdaBoost算法8.1中的基本分类器限制为二类分类即可。下面看一下用于回归问题的提升树:


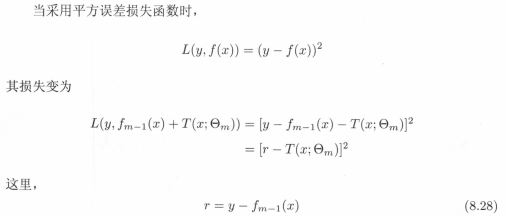
R是当前模型拟合数据的残差,所以对回归问题的提升树算法来说,只需要简单的拟合当前模型的残差即可。具体算法如下:

具体例子8.2:
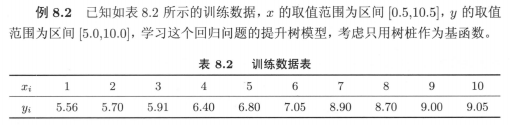





算法8.1代码已上传至github,先理解决策树章节的算法5.5,该提升树会非常好理解~
08_提升方法_AdaBoost算法的更多相关文章
- 机器学习理论提升方法AdaBoost算法第一卷
AdaBoost算法内容来自<统计学习与方法>李航,<机器学习>周志华,以及<机器学习实战>Peter HarringTon,相互学习,不足之处请大家多多指教! 提 ...
- 机器学习——提升方法AdaBoost算法,推导过程
0提升的基本方法 对于分类的问题,给定一个训练样本集,求比较粗糙的分类规则(弱分类器)要比求精确的分类的分类规则(强分类器)容易的多.提升的方法就是从弱分类器算法出发,反复学习,得到一系列弱分类器(又 ...
- 组合方法(ensemble method) 与adaboost提升方法
组合方法: 我们分类中用到非常多经典分类算法如:SVM.logistic 等,我们非常自然的想到一个方法.我们是否可以整合多个算法优势到解决某一个特定分类问题中去,答案是肯定的! 通过聚合多个分类器的 ...
- Boosting(提升方法)之GBDT
一.GBDT的通俗理解 提升方法采用的是加法模型和前向分步算法来解决分类和回归问题,而以决策树作为基函数的提升方法称为提升树(boosting tree).GBDT(Gradient Boosting ...
- Boosting(提升方法)之AdaBoost
集成学习(ensemble learning)通过构建并结合多个个体学习器来完成学习任务,也被称为基于委员会的学习. 集成学习构建多个个体学习器时分两种情况:一种情况是所有的个体学习器都是同一种类型的 ...
- 统计学习方法c++实现之七 提升方法--AdaBoost
提升方法--AdaBoost 前言 AdaBoost是最经典的提升方法,所谓的提升方法就是一系列弱分类器(分类效果只比随机预测好一点)经过组合提升最后的预测效果.而AdaBoost提升方法是在每次训练 ...
- 提升方法-AdaBoost
提升方法通过改变训练样本的权重,学习多个分类器(弱分类器/基分类器)并将这些分类器进行线性组合,提高分类的性能. AdaBoost算法的特点是不改变所给的训练数据,而不断改变训练数据权值的分布,使得训 ...
- 提升方法(boosting)详解
提升方法(boosting)详解 提升方法(boosting)是一种常用的统计学习方法,应用广泛且有效.在分类问题中,它通过改变训练样本的权重,学习多个分类器,并将这些分类器进行线性组合,提高分类的性 ...
- js 变量提升+方法提升
<!DOCTYPE html> <html> <head lang="en"> <meta charset="UTF-8&quo ...
随机推荐
- CCF ISBN
题目原文 问题描述(题目链接登陆账号有问题,要从这个链接登陆,然后点击“模拟考试”,进去找本题目) 试题编号: 201312-2 试题名称: ISBN号码 时间限制: 1.0s 内存限制: 256 ...
- docker 容器核心技术
容器的数据卷(volume)也是占用磁盘空间,可以通过以下命令删除失效的volume: [root@localhost]# sudo docker volume rm $(docker volume ...
- quartzJob
定时任务的时间修改.暂停.立即执行 定时任务的修改.暂停主要是调用quartz内置方法pauseJob().resumeJob().triggerJob()等方法 //暂停一个job JobKey j ...
- 【雕爷学编程】Arduino动手做(42)---PM2.5粉尘传感器
37款传感器与模块的提法,在网络上广泛流传,其实Arduino能够兼容的传感器模块肯定是不止37种的.鉴于本人手头积累了一些传感器和模块,依照实践(动手试试)出真知的理念,以学习和交流为目的,这里准备 ...
- 「雕爷学编程」Arduino动手做(25)——MQ2气敏检测模块
37款传感器与模块的提法,在网络上广泛流传,其实Arduino能够兼容的传感器模块肯定是不止37种的.鉴于本人手头积累了一些传感器和模块,依照实践出真知(一定要动手做)的理念,以学习和交流为目的,这里 ...
- flask之session
''' session使用: session创建: (1)导入session from flask import session (2)设置secret_key密钥 app.secret_key='s ...
- 团队作业-Beta冲刺 (第一天)
这个作业属于哪个课程 <课程的链接> 这个作业要求在哪里 <作业要求的链接> 团队名称 RTD <团队博客链接> 这个作业的目标 剩余任务预估,分配任务(开发,测试 ...
- 接上一篇:vue零基础入门记录
上一篇的vue项目已经搭建运行了起来,我用惯了idea这里也用的idea打开的项目.貌似其他软件写前端更好. 打开项目的项目路径是这样的 写惯了后台,第一眼看的时候感觉这个项目路径很乱,后面才知道我们 ...
- JUC整理笔记二之聊聊volatile
要想学好JUC,还得先了解 volatile 这个关键字.了解 volatile ,我们从一个例子开始吧. 本文不会很详细去说java内存模型,只是很简单地学习一下volatile 一个例子 pack ...
- var、let、const三者的区别
var定义的变量,没有块的概念,可以跨块访问, 不能跨函数访问. let定义的变量,只能在块作用域里访问,不能跨块访问,也不能跨函数访问. const用来定义常量,使用时必须初始化(即必须赋值),只能 ...