入门大数据---Elasticsearch搭建与应用
项目版本

构建需要:
junit4.10
log4j1.2.17
spring-context3.2.0.RELEASE
spring-core3.2.0.RELEASE
spring-beans3.2.0.RELEASE
spring-web3.2.0.RELEASE
spring-expression3.2.0.RELEASE
jstl1.2
运行需要:
JRE1.7
Tomcat8.x
Linux部署Elastisearch同开发版本一致。
一、功能简介
ElasticSearchByWeb是一个基于ElasticSearch技术开发的搜索项目。
提供了索引库的建立,数据的录入,搜索查询,web展示。
索引库效果图:


搜索效果图:
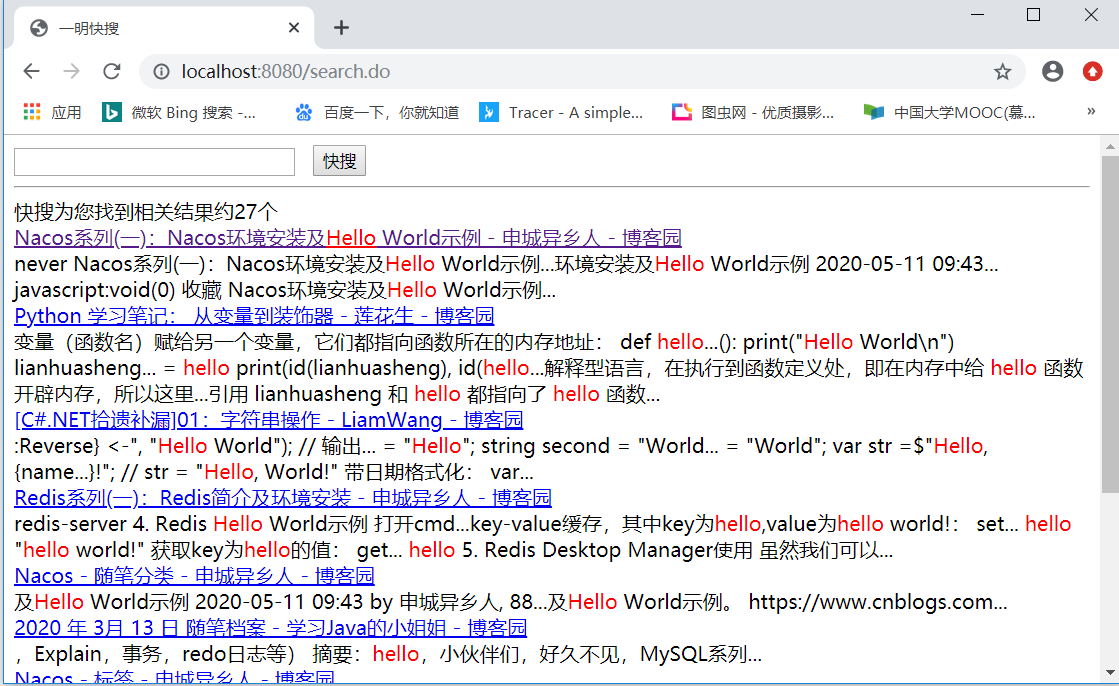
二、项目结构
├─.idea
│ ├─artifacts
│ ├─codeStyles
│ └─libraries
├─src
│ ├─main
│ │ ├─java
│ │ │ └─vip
│ │ │ └─shuai7boy
│ │ │ ├─controller (Spring MVC展示)
│ │ │ ├─model(用到的字段类)
│ │ │ ├─server(创建索引库,添加数据,搜索)
│ │ │ └─util(包括了分页工具类)
│ │ └─resources
│ └─test
│ └─java
└─web
└─WEB-INF(项目配置)
三、Elasticsearch服务搭建
要想使用代码操作ES,必须先把ES服务器搭建起来。
这里准备了三台服务器node1,node2,node3练手。
上传文件
先将Elasticsearch2.2.1下载好的文件上传到node1下面的/opt/elasticsearch目录下。
创建用户
创建一个新的Linux用户,名称随意,我这里取名ryj(ES为了安全,不能直接使用root用户运行)。
切换到新创建的用户,解压文件。
su ryj
tar xxx.tar.gz
修改配置
进入到/config 修改elasticsearch.yml
cluster.name: ryj-es #设置集群名称
node.name: node1 #设置节点名称(一会分发到其它服务器记得修改)
network.host: 192.168.40.200 #设置服务器地址(一会分发到其它服务器记得修改)
http.port: 9200 #放开端口
#下面是防止脑裂部分
discovery.zen.ping.multicast.enabled: false
discovery.zen.ping.unicast.hosts: ["192.168.40.200:9300", "192.168.40.201:9300","192.168.40.202:9300"]
discovery.zen.ping_timeout: 120s
client.transport.ping_timeout: 60s
修改完后保存。
添加插件
在项目下创建plugins目录
将head插件放入plugins目录(提供词库浏览的web ui)
将ik插件放入plugins目录(提供中文分词)
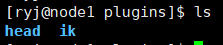
修改完后分发到另外两台服务器
scp -r xxx ryj@node2:`pwd`
scp -r xxx ryj@node3:`pwd`
启动
在启动之前要确保都要切换到上面新创建的Linux用户下。
./bin/elasticsearch
浏览
测试每个节点是否启动成功使用9200端口,例如: http://node1:9200/
浏览分词库在上面的基础上加
_plugin/head/,例如:http://node1:9200/_plugin/head/上面的都正常无误后,接下来就是运行项目构建索引库操作了。
进入vip.shuai7boy.serve.IndexServer 下运行createIndex构建索引库。
进入vip.shuai7boy.serve.IndexServer 下运行addHtmlToES添加数据。
启动Tomcat进行搜索。
入门大数据---Elasticsearch搭建与应用的更多相关文章
- 入门大数据---Elasticsearch是什么?
Elasticsearch是谁不重要,重要的是咱们都知道百度,谷歌这样的搜索巨头吧.它们的核心技术都利用了Elasticsearch,所以我们有必要对Elasticsearch了解下! 1.Elast ...
- 入门大数据---HDFS-HA搭建
一.简述 上一篇了解了Zookeeper和HDFS的一些概念,今天就带大家从头到尾搭建一下,其中遇到的一些坑也顺便记录下. 1.1 搭建的拓扑图如下: 1.2 部署环境:Centos3.1,java1 ...
- 入门大数据---Storm搭建与应用
1.Storm在Linux环境配置 主机名 tuge1 tuge2 tuge3 部署环境 Zookeeper/Nimbus Zookeeper/Supervisor Zookeeper/Supervi ...
- 入门大数据---Hbase搭建
环境介绍 tuge1 tuge2 tuge3 tuge4 NameNode NameNode DataNode DataNode ZooKeeper ZooKeeper ZooKeeper ZooKe ...
- 入门大数据---Kylin搭建与应用
由于Kylin官网已经是中文的了,而且写的很详细,这里就不再重述. 学习右转即可. 这里说个遇到的问题,当在Kylin使用SQL关键字时,要加上双引号,并且里面的内容要大写,这个和MySql有点区别需 ...
- 大数据平台搭建(hadoop+spark)
大数据平台搭建(hadoop+spark) 一.基本信息 1. 服务器基本信息 主机名 ip地址 安装服务 spark-master 172.16.200.81 jdk.hadoop.spark.sc ...
- 入门大数据---Flink学习总括
第一节 初识 Flink 在数据激增的时代,催生出了一批计算框架.最早期比较流行的有MapReduce,然后有Spark,直到现在越来越多的公司采用Flink处理.Flink相对前两个框架真正做到了高 ...
- 大数据平台搭建-zookeeper集群的搭建
本系列文章主要阐述大数据计算平台相关框架的搭建,包括如下内容: 基础环境安装 zookeeper集群的搭建 kafka集群的搭建 hadoop/hbase集群的搭建 spark集群的搭建 flink集 ...
- 大数据平台搭建-kafka集群的搭建
本系列文章主要阐述大数据计算平台相关框架的搭建,包括如下内容: 基础环境安装 zookeeper集群的搭建 kafka集群的搭建 hadoop/hbase集群的搭建 spark集群的搭建 flink集 ...
随机推荐
- 资源在windows编程中的应用----菜单
资源在Windows编程中的应用 资源 加速键.位图.光标.对话框.菜单.字符串.工具条 1.菜单的创建 菜单由以下组成部分: (1)窗口主菜单条 (2)下拉式菜单框 (3)菜单项热键标识 (4)菜单 ...
- HashMap1.7和1.8,红黑树原理!
jdk 1.7 概述 HashMap基于Map接口实现,元素以键值对的方式存储,并允许使用null键和null值,但只能有一个键作为null,因为key不允许重复,另外HashMap不能保证放入元素的 ...
- Java实现 蓝桥杯 算法训练 天数计算
试题 算法训练 天数计算 问题描述 编写函数求某年某月某日(**** ** **)是这一年的第几天 .提示:要考虑闰年,闰年的2月是29天(闰年的条件:是4的倍数但不是100的倍数,或者是400的倍数 ...
- Java实现 蓝桥杯VIP 算法训练 明明的随机数
问题描述 明明想在学校中请一些同学一起做一项问卷调查,为了实验的客观性,他先用计算机生成了N个1到1000之间的随机整数(N≤100),对于其中重复的数字,只保留一个,把其余相同的数去掉,不同的数对应 ...
- Java实现蓝桥杯模拟存储转换
问题描述 在计算机存储中,15.125GB是多少MB? 答案提交 这是一道结果填空的题,你只需要算出结果后提交即可.本题的结果为一个整数,在提交答案时只填写这个整数,填写多余的内容将无法得分. pac ...
- Java实现 蓝桥杯VIP 算法训练 蜜蜂飞舞
时间限制:1.0s 内存限制:512.0MB 问题描述 "两只小蜜蜂呀,飞在花丛中呀--" 话说这天天上飞舞着两只蜜蜂,它们在跳一种奇怪的舞蹈.用一个空间直角坐标系来描述这个世界, ...
- Java实现 LeetCode 167 两数之和 II - 输入有序数组
167. 两数之和 II - 输入有序数组 给定一个已按照升序排列 的有序数组,找到两个数使得它们相加之和等于目标数. 函数应该返回这两个下标值 index1 和 index2,其中 index1 必 ...
- Java实现 洛谷 P1008 三连击
public class Main { public static void main(String[] args){ for(int i = 123; i <= 329; i++){ int[ ...
- java实现最大公约数
编写一函数gcd,求两个正整数的最大公约数. 样例输入: 5 15 样例输出: 5 样例输入: 7 2 样例输出: 1 package adv92; import java.util.Scanner; ...
- Java实现 蓝桥杯 历届试题 最大子阵
问题描述 给定一个n*m的矩阵A,求A中的一个非空子矩阵,使这个子矩阵中的元素和最大. 其中,A的子矩阵指在A中行和列均连续的一块. 输入格式 输入的第一行包含两个整数n, m,分别表示矩阵A的行数和 ...