4L-线性表之数组
关注公众号 MageByte,设置星标点「在看」是我们创造好文的动力。后台回复 “加群” 进入技术交流群获更多技术成长。
数组对于每一门编程语言来说都是重要的数据结构之一,当然不同语言对数组的实现及处理也不尽相同。Java 语言中提供的数组是用来存储固定大小的同类型元素。
你一定会说数组这么简单,有啥说的。嘿嘿嘿,里面包含的玄机可不一定每个人都知道。

今天的疑惑来了…..
数组几乎都是从 0 开始编号的,有没有想过 为啥数组从 0 开始编号,而不是从 1 开始呢? 使用 1 不是更符合人类的思维么?
数组简介
数组是一种线性表数据结构,用一组连续的内存空间来存储一组具有相同类型的数据。
里面出现了几个重要关键字,线性表、连续内存空间和相同类型数据,这里解释下每个关键词的含义。
线性表
就是数据排成像线一样的结构,就像我们的高铁 G1024 号,每节车厢首尾相连,数据最多只有「前」和「后」两个方向。除了数组,链表,队列,栈都是线性结构。
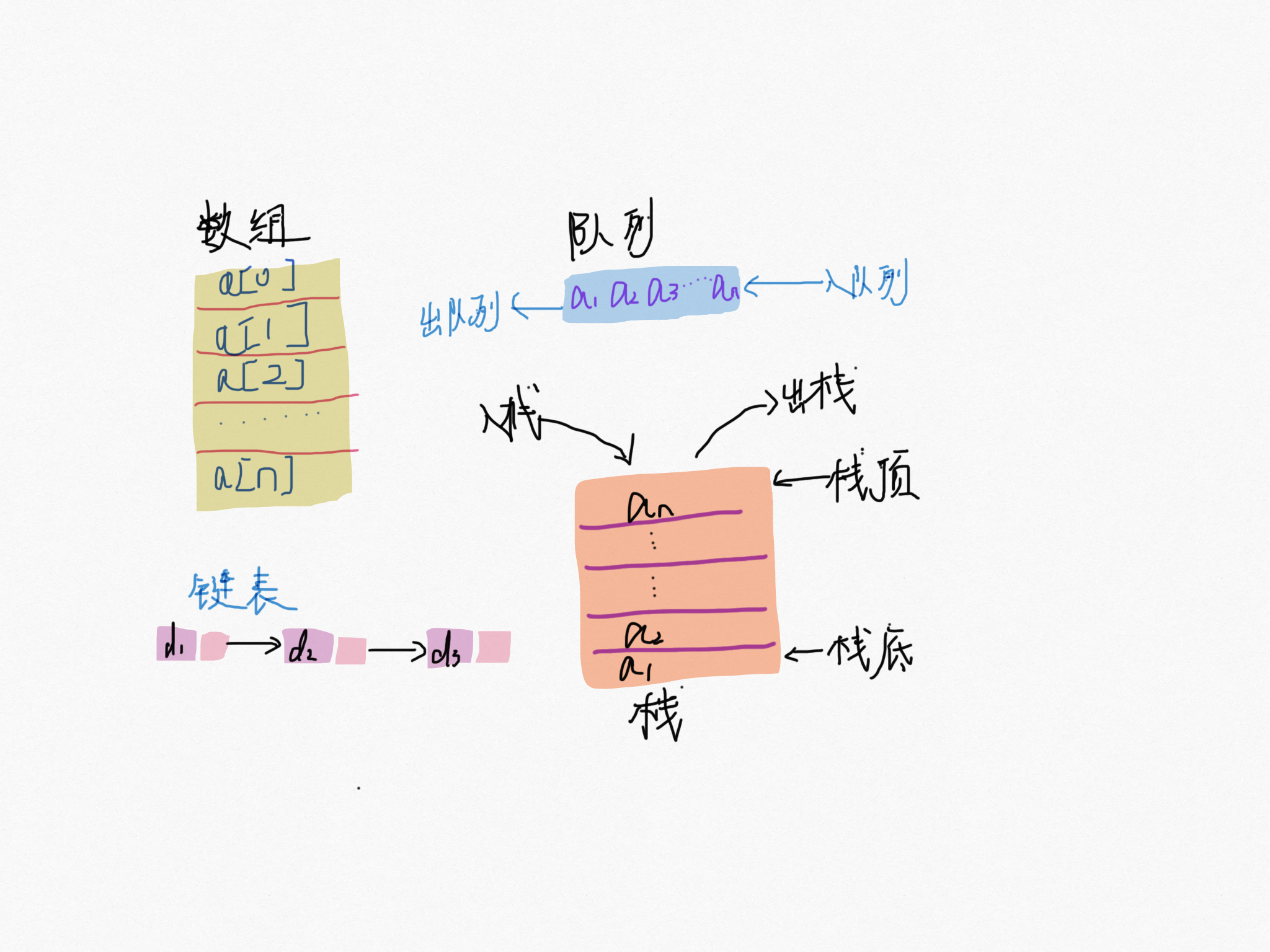
非线性表
比如二叉树、堆、图等。之所以叫非线性,是因为,在非线性表中,数据之间并不是简单的前后关系。
连续的内存空间
正式由于它具有连续的内存空间和相同的数据类型的数据。就有一个牛逼特性:「随机访问」。很多人面试的时候一定被问数组与链表有什么区别?多数会回答 “链表适合插入、删除,时间复杂度 O(1);数组适合查找,查找时间复杂度为 O(1)”。
这个回答并不严谨。适合查找,但是查找的时间复杂度并不是 O(1),即便是已经排序好的数据,你用二分法查找时间复杂度也是 O(logn)。正确的应该是,数组支持随机访问,根据下表随机访问的时间复杂度为 O(1)。
随机访问
我们都知道数组是根据下表访问数据的,它是如何实现随机访问呢?
用一个长度 4 的 int 类型的数组 int[] a = new int[4] 举例,首先计算机给数组 a 分配了一块连续内存空间 1000~1015。int 类型占 4 个字节,所以一共占有 4*4字节。内存块的首地址 base_address = 1000。当程序随机访问数组中的第 i 个元素,计算机通过以下寻址公式计算出内存地址。
targetAddress = base_address + i * data_type_size
- targetAddress:访问目标的内存地址。
- base_address:数组内存块的首地址。
- i 表示要访问的下标, data_type_size:数据类型的字节大小,比如 int 类型占 4 个字节。
首地址就像高铁 G1024 编号,每节车厢就是数组的的下标位置,每节车厢的座位就像一个个字节长度。
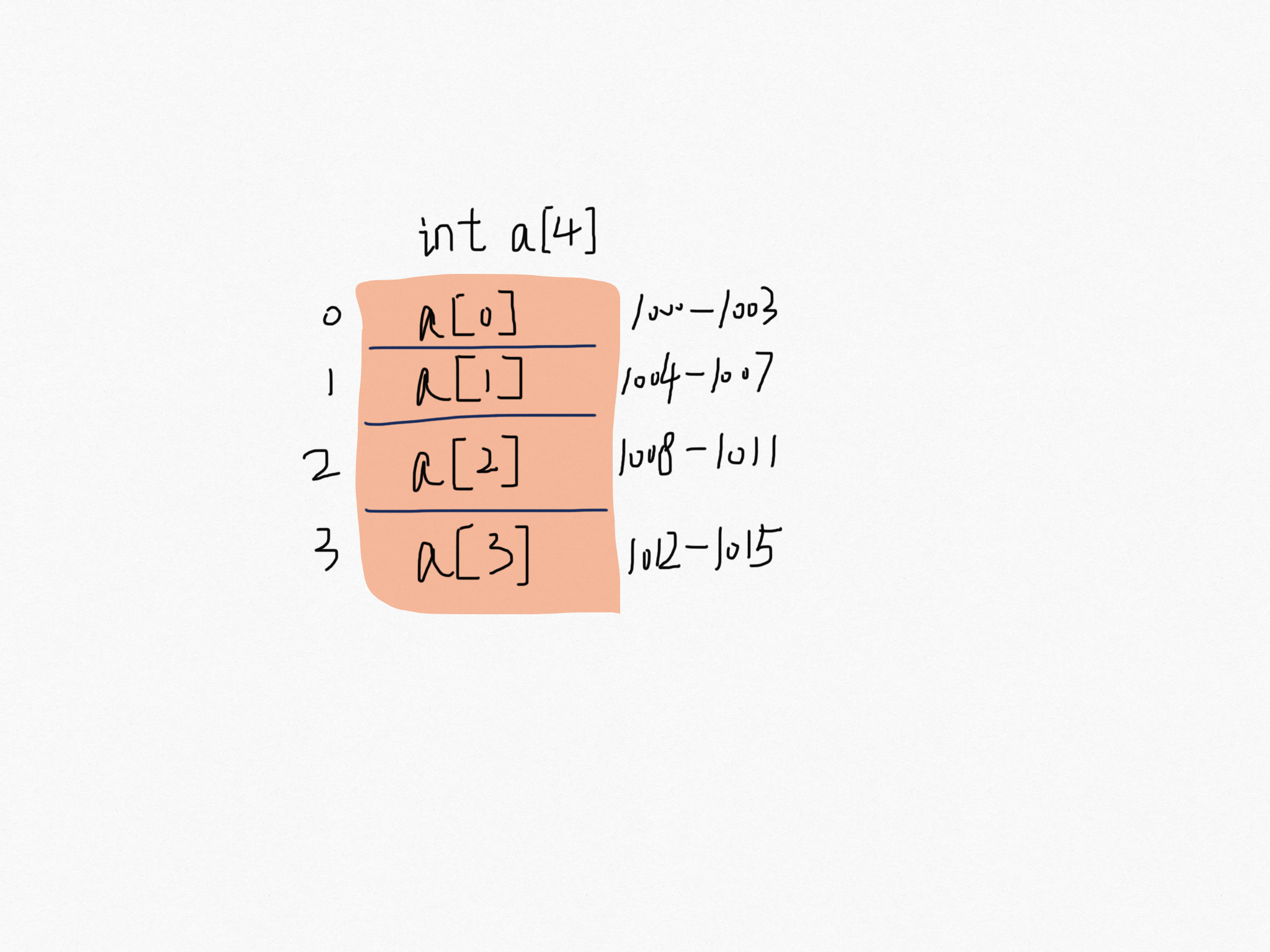
敲黑板了:同学们,数组寻址公式就是这儿回事。这个公式也是最后解释为何 下标从 0 开始的铺垫。
为何下标从 0 开始?
“下标”最确切的定义应该是“偏移(offset)”。前面也讲到,如果用 base_address 来表示数组的首地址,a[0] 就是偏移为 0 的位置,也就是首地址,a[i] 就表示偏移 i 个 data_type_size 的位置,所以计算 a[i] 的内存地址只需要用这个公式:
targetAddress[i] = base_address + i * data_type_size
现在问题来了,假如数组下标从 1 开始,计算 a[i] 的内存地址公式就需要改成:
targetAddress[i] = base_address + (i - 1) * data_type_size
重点来了,对比两个公式,从 1 开始每次随机访问数组元素都多了一次减法运算,相当于多执行了一次减法指令。
数组作为非常基础的数据结构,通过下标随机访问数组元素又是其非常基础的编程操作,效率的优化就要尽可能做到极致。所以为了减少一次减法操作,数组选择了从 0 开始编号,而不是从 1 开始。
当然这不能说是绝对,也可能是历史原因,C 语言设计是从 0 开始,后面的高级语言都效仿,也方便程序猿很快的适应,减少学习成本。
低效的插入和删除
有利有弊,这个限制也导致数组的删除、插入这种操作变得低效,为了保证内存连续性,就需要做数据移动工作。
那有没有什么改进方式呢?
插入操作
数组长度为 n,将一个元素插入到数组的第 k 个位置。为了满足连续性我们需要把 k 这个位置腾出来,给新插入的数据占坑,然后把 k 到 n 这部分的数据都往后移动一位。这个插入的时间复杂度是多少呢?我们来分析下,顺便学习下时间与空间复杂度分析。
当在数组的末尾插入元素,那就不需要移动数据,所以「最好时间复杂度」为 O(1)。当插入的位置在数组的开头,那所有的数据都需要依次往后移动一位,所有最坏时间复杂度 O(n)。而我们在每个位置插入元素概率是一样的,所以平均时间复杂度 就是 $$\frac {(1+2+3+…+n)} {n} = O(n)$$。
优化思路-鸠占鹊巢
如果数组中的顺序是有序,我们就需要移动 k 之后的数据,假如数组中存放的数据无序,只是作为一个存放数据的集合,要将某个元素插入到数组 k 位置,我们可以把原来在 k 位置的元素放到数组的最后,把新插入的元素放入 k 这个位置,时间复杂度就降低到了 O(1)。
删除操作
同理,假设我们要删除 第 k 个位置的数据,如果 k = n-1,那么最好时间复杂度就是 O(1)。若果 k = 0,最坏时间复杂度 O(n)。平均时间复杂度也是 O(n)。
优化思路-标记-批量执行
实际上,在某些场合并不需要非要追求数据的连续性。可以将多次的删除操作批量执行。
比如数组 number[6]中存储了 6 个 int 类型的元素:1、2、3、4、5、6。依次删除 1、2、3。三个元素。防止每次删除都需要移动数据,我们只要标记数据已经被删除,当达到删除阈值,比如是 3,才执行移动数据的操作,这个时候才执行移动操作,大大减少了数据搬移。
你会发现,这不就是 JVM 标记清除垃圾回收算法的核心思想吗?没错,数据结构和算法的魅力就在于此,很多时候我们并不是要去死记硬背某个数据结构或者算法,而是要学习它背后的思想和处理技巧,这些东西才是最有价值的。如果你细心留意,不管是在软件开发还是架构设计中,总能找到某些算法和数据结构的影子。
知识拓展&总结
数组用一块连续的内存空间,来存储相同类型的一组数据,最大的特点就是支持随机访问,但插入、删除操作也因此变得比较低效,平均情况时间复杂度为 O(n)。在平时的业务开发中,我们可以直接使用编程语言提供的容器类,但是,如果是特别底层的开发,直接使用数组可能会更合适。
问题来了
基于数组删除操作我们提出一个优化思路:标记-批量清除思想,在 Java 的 JVM 中,垃圾回收的标记清除算法是什么么?欢迎加群分享你的想法或者后台回复 「标记清除」获取答案。
欢迎加群与我们讨论分享,我们第一时间反馈。
推荐阅读

4L-线性表之数组的更多相关文章
- JavaScript 数据结构与算法之美 - 线性表(数组、栈、队列、链表)
前言 基础知识就像是一座大楼的地基,它决定了我们的技术高度. 我们应该多掌握一些可移值的技术或者再过十几年应该都不会过时的技术,数据结构与算法就是其中之一. 栈.队列.链表.堆 是数据结构与算法中的基 ...
- C语言实现顺序表的基本操作(从键盘输入 生成线性表,读txt文件生成线性表和数组生成线性表----三种写法)
经过三天的时间终于把顺序表的操作实现搞定了.(主要是在测试部分停留了太长时间) 1. 线性表顺序存储的概念:指的是在内存中用一段地址连续的存储单元依次存储线性表中的元素. 2. 采用的实现方式:一段地 ...
- c++线性表和数组的区别
在传统C语言程序中,描述顺序表的存储表示有两种方式:静态方式.动态方式 顺序表的静态存储表示: #define maxSize 100 typedefintT; typedefstruct{ T da ...
- 线性表(存储结构数组)--Java 实现
/*线性表的数组实现 *特点:插入删除慢需要平均移动一半的数据,查找较快 *注意:有重复和无重复的数据对应的操作会有些不同 *注意数组一旦创建其大小就固定了 *Java集合长度可变是由于创建新的数组将 ...
- Java探索之旅(10)——数组线性表ArrayList和字符串生成器StringBuffer/StringBuilder
1.数组线性表ArrayList 数组一旦定义则不可改变大小.ArrayList可以不限定个数的存储对象.添加,插入,删除,查找比较数组更加容易.可以直接使用引用类型变量名输出,相当于toString ...
- Java数据结构之线性表
从这里开始将要进行Java数据结构的相关讲解,Are you ready?Let's go~~ java中的数据结构模型可以分为一下几部分: 1.线性结构 2.树形结构 3.图形或者网状结构 接下来的 ...
- C 数据结构1——线性表分析(顺序存储、链式存储)
之前是由于学校工作室招新,跟着大伙工作室招新训练营学习数据结构,那个时候,纯碎是小白(至少比现在白很多)那个时候,学习数据结构,真的是一脸茫然,虽然写出来了,但真的不知道在干嘛.调试过程中,各种bug ...
- 线性表的顺序存储结构——java
线性表的顺序存储结构:是指用一组地址连续的存储单元一次存放线性表的元素.为了使用顺序结构实现线性表,程序通常会采用数组来保存线性中的元素,是一种随机存储的数据结构,适合随机访问.java中ArrayL ...
- 规则集Set与线性表List性能分析
前言 本章节将通过实验,测试规则集与线性表的性能.那么如何进行实验呢?针对不同的集合都进行指定数量元素的添加和删除操作,计算耗费时间进行分析. 那么,前两个章节呢,我们分别讲述了什么时候使用Set以及 ...
- 【Java数据结构学习笔记之一】线性表的存储结构及其代码实现
应用程序后在那个的数据大致有四种基本的逻辑结构: 集合:数据元素之间只有"同属于一个集合"的关系 线性结构:数据元素之间存在一个对一个的关系 树形结构:数据元素之间存在一个对多个关 ...
随机推荐
- CSS 之动态变换背景颜色
先上效果图 HTML代码: 123456789 <div class="header"> <h1>GCCHRN'S BLOG</h1> < ...
- 二十一世纪计算 | John Hopcroft:AI革命
编者按:信息革命的浪潮浩浩汤汤,越来越多的人将注意力转向人工智能,想探索它对人类生产生活所产生的可能影响.人工智能的下一步发展将主要来自深度学习,在这个领域中,更多令人兴奋的话题在等待我们探讨:神经网 ...
- CPU网卡亲和绑定
#!/bin/bash # # Copyright (c) , Intel Corporation # # Redistribution and use in source and binary fo ...
- 吐槽苹果开放接口のappleid登陆
这里吐槽一下苹果的开发文档,一切源于前段时间,公司的产品app(某知名资讯app)要接入苹果登陆(ios13发布以来,apple就流氓要求新上线的app,如果有第三方登陆的话,必须要接入appleid ...
- swoole(6)Task异步任务
一:什么是task进程? task进程是独立与worker进程的一组进程 ,他主要处理耗时较长的业务逻辑,并且不影响worker进程处理客户端的请求.worker进程通过task()函数把数据投递到 ...
- HTML与CSS 开发常用语义化命名
一.布局❤️ header 头部/页眉:index 首页/索引:logo 标志:nav/sub_nav 导航/子导航:banner 横幅广告:main/content 主体/内容:container/ ...
- 【jQuery学习日记】jQuery实现滚动动画
需要实现的效果 样式分析: 2个主要部分,头部的标题和导航部分,和主要的功能实现区域: 1.头部 <div id="header"> <h1>动漫视频< ...
- C/C++ 手动开O2
手动O2比赛不能用,平时玩玩就好 #pragma GCC optimize (2) #pragma G++ optimize (2)
- python之迭代器 生成器 枚举 常用内置函数 递归
迭代器 迭代器对象:有__next__()方法的对象是迭代器对象,迭代器对象依赖__next__()方法进行依次取值 with open('text.txt','rb',) as f: res = f ...
- ARC中__bridge, __bridge__transfer, __bridge_retained 关系
总结于 IOS Tuturial 中 ARC两章,详细在dropbox pdf 文档. Toll-Free Bridging 当你在 Objective-C 和 Core Foundation 对象之 ...