对tf.nn.softmax的理解
Softmax的含义:Softmax简单的说就是把一个N*1的向量归一化为(0,1)之间的值,由于其中采用指数运算,使得向量中数值较大的量特征更加明显。
如图所示,在等号左边部分就是全连接层做的事。
- W是全连接层的参数,我们也称为权值;W是全连接层的参数,是个T*N的矩阵,这个N和X的N对应,T表示类别数,比如你进行手写数字识别,就是10个分类,那么T就是10。
- X是全连接层的输入,也就是特征。从图上可以看出特征X是N1的向量,他就是由全连接层前面多个卷积、激活和池化层处理后得到的;
举一个例子,假设全连接层前面连接的是一个卷积层,这个卷积层的输出是64个特征,每个特征的大小是7X7,那么在将这些特征输入给全连接层之前会将这些特征通过tf.reshape转化为成N1的向量(这个时候N就是64X7X7=3136)。
我们所说的训练一个网络,对于全连接层而言就是寻找最合适的W矩阵。因此全连接层就是执行WX得到一个T1的向量(也就是图中的logits[T1]),这个向量里面的每个数都没有大小限制的,也就是从负无穷大到正无穷大。然后如果你是多分类问题,一般会在全连接层后面接一个softmax层,这个softmax的输入是T1的向量,输出也是T1的向量(也就是图中的prob[T*1],这个向量的每个值表示这个样本属于每个类的概率),只不过输出的向量的每个值的大小范围为0到1。
现在你知道softmax的输出向量是什么意思了,就是概率,该样本属于各个类的概率!
那么softmax执行了什么操作可以得到0到1的概率呢?先来看看softmax的公式(以前自己看这些内容时候对公式也很反感,不过静下心来看就好了):
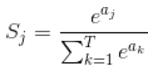
公式非常简单,前面说过softmax的输入是WX,假设模型的输入样本是I,讨论一个3分类问题(类别用1,2,3表示),样本I的真实类别是2,那么这个样本I经过网络所有层到达softmax层之前就得到了WX,也就是说WX是一个31的向量,那么上面公式中的aj就表示这个31的向量中的第j个值(最后会得到S1,S2,S3);而分母中的ak则表示31的向量中的3个值,所以会有个求和符号(这里求和是k从1到T,T和上面图中的T是对应相等的,也就是类别数的意思,j的范围也是1到T)。因为e^x恒大于0,所以分子永远是正数,分母又是多个正数的和,所以分母也肯定是正数,因此Sj是正数,而且范围是(0,1)。如果现在不是在训练模型,而是在测试模型,那么当一个样本经过softmax层并输出一个T*1的向量时,就会取这个向量中值最大的那个数的index作为这个样本的预测标签。
因此我们训练全连接层的W的目标就是使得其输出的WX在经过softmax层计算后其对应于真实标签的预测概率要最高。
举个例子:假设你的WX=[1,2,3],那么经过softmax层后就会得到[0.09,0.24,0.67],这三个数字表示这个样本属于第1,2,3类的概率分别是0.09,0.24,0.67。取概率最大的0.67,所以这里得到的预测值就是第三类。
弄懂了softmax,就要来说说softmax loss了。
那softmax loss是什么意思呢?如下:
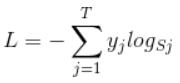
首先L是损失。Sj是softmax的输出向量S的第j个值,前面已经介绍过了,表示的是这个样本属于第j个类别的概率。yj前面有个求和符号,j的范围也是1到类别数T,因此y是一个1*T的向量,里面的T个值,而且只有1个值是1,其他T-1个值都是0。那么哪个位置的值是1呢?答案是真实标签对应的位置的那个值是1,其他都是0。所以这个公式其实有一个更简单的形式:
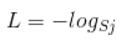
当然此时要限定j是指向当前样本的真实标签。
来举个例子吧。假设一个5分类问题,然后一个样本I的标签y=[0,0,0,1,0],也就是说样本I的真实标签是4,假设模型预测的结果概率(softmax的输出)p=[0.1,0.15,0.05,0.6,0.1],可以看出这个预测是对的,那么对应的损失L=-log(0.6),也就是当这个样本经过这样的网络参数产生这样的预测p时,它的损失是-log(0.6)。那么假设p=[0.15,0.2,0.4,0.1,0.15],这个预测结果就很离谱了,因为真实标签是4,而你觉得这个样本是4的概率只有0.1(远不如其他概率高,如果是在测试阶段,那么模型就会预测该样本属于类别3),对应损失L=-log(0.1)。那么假设p=[0.05,0.15,0.4,0.3,0.1],这个预测结果虽然也错了,但是没有前面那个那么离谱,对应的损失L=-log(0.3)。我们知道log函数在输入小于1的时候是个负数,而且log函数是递增函数,所以-log(0.6) < -log(0.3) < -log(0.1)。简单讲就是你预测错比预测对的损失要大,预测错得离谱比预测错得轻微的损失要大。
理清了softmax loss,就可以来看看cross entropy了。
corss entropy是交叉熵的意思,它的公式如下:
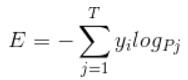
是不是觉得和softmax loss的公式很像。当cross entropy的输入P是softmax的输出时,cross entropy等于softmax loss。Pj是输入的概率向量P的第j个值,所以如果你的概率是通过softmax公式得到的,那么cross entropy就是softmax loss。
对tf.nn.softmax的理解的更多相关文章
- 深度学习原理与框架-Tensorflow基本操作-mnist数据集的逻辑回归 1.tf.matmul(点乘操作) 2.tf.equal(对应位置是否相等) 3.tf.cast(将布尔类型转换为数值类型) 4.tf.argmax(返回最大值的索引) 5.tf.nn.softmax(计算softmax概率值) 6.tf.train.GradientDescentOptimizer(损失值梯度下降器)
1. tf.matmul(X, w) # 进行点乘操作 参数说明:X,w都表示输入的数据, 2.tf.equal(x, y) # 比较两个数据对应位置的数是否相等,返回值为True,或者False 参 ...
- tf.nn.softmax(logits,name=None)
tf.nn.softmax( logits, axis=None, name=None, dim=None #dim在后来改掉了 ) 通过Softmax回归,将logistic的预测二分类的概率的问题 ...
- tf.nn.softmax & tf.nn.reduce_sum & tf.nn.softmax_cross_entropy_with_logits
tf.nn.softmax softmax是神经网络的最后一层将实数空间映射到概率空间的常用方法,公式如下: \[ softmax(x)_i=\frac{exp(x_i)}{\sum_jexp(x_j ...
- tf.nn.softmax 分类
tf.nn.softmax(logits,axis=None,name=None,dim=None) 参数: logits:一个非空的Tensor.必须是下列类型之一:half, float32,fl ...
- TensorFlow 的softmax实例理解
对于理论,简单的去看一下百度上的说明,这里直接上实例,帮助理解. # softmax函数,将向量映射到0-1的范围内,P=exp(ax)/(sum(exp(a1x)+exp(a2x)+...)) in ...
- 深度学习原理与框架-图像补全(原理与代码) 1.tf.nn.moments(求平均值和标准差) 2.tf.control_dependencies(先执行内部操作) 3.tf.cond(判别执行前或后函数) 4.tf.nn.atrous_conv2d 5.tf.nn.conv2d_transpose(反卷积) 7.tf.train.get_checkpoint_state(判断sess是否存在
1. tf.nn.moments(x, axes=[0, 1, 2]) # 对前三个维度求平均值和标准差,结果为最后一个维度,即对每个feature_map求平均值和标准差 参数说明:x为输入的fe ...
- 深度学习原理与框架-CNN在文本分类的应用 1.tf.nn.embedding_lookup(根据索引数据从数据中取出数据) 2.saver.restore(加载sess参数)
1. tf.nn.embedding_lookup(W, X) W的维度为[len(vocabulary_list), 128], X的维度为[?, 8],组合后的维度为[?, 8, 128] 代码说 ...
- 深度学习原理与框架-Tensorflow卷积神经网络-cifar10图片分类(代码) 1.tf.nn.lrn(局部响应归一化操作) 2.random.sample(在列表中随机选值) 3.tf.one_hot(对标签进行one_hot编码)
1.tf.nn.lrn(pool_h1, 4, bias=1.0, alpha=0.001/9.0, beta=0.75) # 局部响应归一化,使用相同位置的前后的filter进行响应归一化操作 参数 ...
- 第三节,TensorFlow 使用CNN实现手写数字识别(卷积函数tf.nn.convd介绍)
上一节,我们已经讲解了使用全连接网络实现手写数字识别,其正确率大概能达到98%,这一节我们使用卷积神经网络来实现手写数字识别, 其准确率可以超过99%,程序主要包括以下几块内容 [1]: 导入数据,即 ...
随机推荐
- idea常见需求
1.给class加注释模板 /** *@ClassName ${NAME} *@Description TODO *@Author xxx *@Date ${DATE} ${TIME} *@Versi ...
- 关于使用gitlab协同开发提交代码步骤
记录使用gitlab协同开发时从自己的分支向master分支提交代码的步骤: 环境:安装了git和TortoiseGit(git的可视化工具) 1.首先切换到自己的分支(如果不在自己的分支) 2.gi ...
- com.mysql.jdbc.exceptions.jdbc4.MySQLDataException: '2.34435678977654336E17' in column '3' is outside valid range for the datatype INTEGER.
### Error querying database. Cause: java.lang.reflect.UndeclaredThrowableException### The error may ...
- python socket实例
1.客户端向服务端发送 #coding:utf-8 '''客户端''' import socket khd=socket.socket() #声明socket类型,同时生产socket连接对象 khd ...
- Rime输入法一些设定
有鉴于谷歌搜狗拼音等不太好用,但是博主一直页没找到合心的输入法,直到遇见Rime,中州韵就是我想要的输入法.记录一下自己用的时候的修改,以备查询.注意:缩进不要弄丢,所有更改完都需要重新部署才能生效. ...
- hexo NexT主题首页title链接的优化
在默认设置下,文章链接都会改变,不利于搜索引擎收录,也不利于分享 更改index.swig文件 文件路径是your-hexo-sitethemesnextlayout,将下面代码 1 {% block ...
- Centos7上查看ext4文件系统的实际创建时间
前提:今日查看nginx日志时发现有报错,说是一些js,css文件找不到,于是想到去实际路径下查看文件是否确实不存在.结果出现下图中报错: 经过别人提醒查看文件的时间,于是看了一下登上服务器是9:52 ...
- Proto3:C++ API概览
包名 说明 google::protobuf Protocol Buffer运行时库核心组件. google::protobuf::io I/O操作辅助类. google::protobuf::uti ...
- 2、【Spark】Spark环境搭建(集群方式)
Spark集群方式搭建结构如图所示,按照主从方式.
- Python3——2019年全国大学生计算二级考试
Python语言程序设计二级重点(2019年版) 第一章 程序设计基本方法 IPO程序编写方法 :输入(input),输出(output),处理(process): Python程序的特点: (1)语 ...