正文内容 python3编码问题
来源:http://www.jb51.net/article/92006.htm
以下是全文:
这两天写了个监测网页的爬虫,作用是跟踪一个网页的变化,但运行了一晚出现了一个问题。。。。希望大家不吝赐教!
我用的是python3,错误在对html response的decode时抛出,代码原样为:
response = urllib.urlopen(dsturl)
content = response.read().decode('utf-8')
抛出错误为
File "./unxingCrawler_p3.py", line 50, in getNewPhones
content = response.read().decode()
UnicodeDecodeError: 'utf8' codec can't decode byte 0xb2 in position 24137: invalid start byte
之前运行都没问题,经过一晚上就出现了。。。。最不明白的是在它声明为utf-8编码的网页中为什么会出现utf-8无法解析的字符?
后来经过热心网友的提醒,才发现需要使用decode('utf-8', 'ignore')
为了彻底闹明白python的编码问题,特分享下文,希望对大家熟悉python的编码问题带来些帮助
1.从字节说起:
一个字节包括八个比特位,每个比特位表示0或1,一个字节即可表示从00000000到11111111共2^8=256个数字。一个ASCII编码使用一个字节(除去字节的最高位作为作奇偶校验位),ASCII编码实际使用一个字节中的7个比特位来表示字符,共可表示2^7=128个字符。比如ASCII编码中的01000001(即十进制的65)表示字符'A',01000001加上32之后的01100001(即十进制的97)表示字符'a'。现在打开Python,调用chr和ord函数,我们可以看到Python为我们对ASCII编码进行了转换。如图

第一个00000000表示空字符,因此ASCII编码实际上只包括了 字母、标点符号、特殊符号等共127个字符。因为ASCII是在美国出生的,对于由字母组成单词进而用单词表达的英文来说也是够了。但是中国人、日本人、 韩国人等其他语言的人不服了。中文是一个字一个字,ASCII编码用上了浑身解数256个字符都不够用。
因此后来出现了Unicode编码。Unicode编码通常由两个字节组成,共表示256*256个字符,即所谓的UCS-2。某些偏僻字还会用到四个字节,即所谓的UCS-4。也就是说Unicode标准也还在发展。但UCS-4出现的比较少,我们先记住: 最原始的ASCII编码使用一个字节编码,但由于语言差异字符众多,人们用上了两个字节,出现了统一的、囊括多国语言的Unicode编码。
在Unicode中,原本ASCII中的127个字符只需在前面补一个全零的字节即可,比如前文谈到的字符‘a':01100001,在Unicode中变成了00000000 01100001。不久,美国人不开心了,吃上了世界民族之林的大锅饭,原本只需一个字节就能传输的英文现在变成两个字节,非常浪费存储空间和传输速度。
人们再发挥聪明才智,于是出现了UTF-8编码。因为针对的是空间浪费问题,因此这种 UTF-8编码是可变长短的 ,从英文字母的一个字节,到中文的通常的三个字节,再到某些生僻字的六个字节。解决了空间问题,UTF-8编码还有一个神奇的附加功能,那就是兼容了老大哥的ASCII编码。一些老古董软件现在在UTF-8编码中可以继续工作。
注意除了英文字母相同,汉字在Unicode编码和UTF-8编码中通常是不同的。比如汉字的‘中'字在Unicode中是01001110 00101101,而在UTF-8编码中是11100100 10111000 10101101。
我们祖国母亲自然也有自己的一套标准。那就是GB2312和GBK。当然现在挺少看到。通常都是直接使用UTF-8。
2.Python3中的默认编码
Python3中默认是UTF-8,我们通过以下代码:
import sys sys.getdefaultencoding()
可查看Python3的默认编码。

3.Python3中的encode和decode
Python3中字符编码经常会使用到decode和encode函数。特别是在抓取网页中,这两个函数用的熟练非常有好处。encode的作用,使我们看到的直观的字符转换成计算机内的字节形式。decode刚好相反,把字节形式的字符转换成我们看的懂的、直观的、“人模人样”的形式。
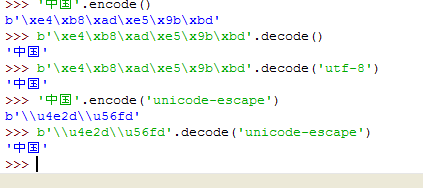
\x表示后面是十六进制, \xe4\xb8\xad即是二进制的 11100100 10111000 10101101。也就是说汉字‘中'encode成字节形式,是 11100100 10111000 10101101。同理,我们拿 11100100 10111000 10101101也就是 \xe4\xb8\xad来decode回来,就是汉字‘中'。完整的应该是 b'\xe4\xb8\xad',在Python3中, 以字节形式表示的字符串则必须加上 前缀b,也就是写成上文的b'xxxx'形式。
前文说的Python3的默认编码是UTF-8,所以我们可以看到,Python处理这些字符的时候是以UTF-8来处理的。因此从上图可以看到,就算我们通过encode('utf-8')特意把字符encode为UTF-8编码,出来的结果还是相同:b'\xe4\xb8\xad'。
明白了这一点,同时我们知道UTF-8兼容ASCII,我们可以猜想大学时经常背诵的‘A'对应ASCII中的65,在这里是不是也能正确的decode出来呢。十进制的65转换成十六进制是41,我们尝试下:
b'\x41'.decode()
结果如下。果然是字符‘A'

4.Python3中的编码转换
据说字符在计算机的内存中统一是以Unicode编码的。只有在字符要被写进文件、存进硬盘或者从服务器发送至客户端(例如网页前端的代码)时会变成utf-8。但其实我比较关心怎么把这些字符以Unicode的字节形式表现出来,露出它在内存中的庐山正面目的。这里有个照妖镜:
xxxx.encode/decode('unicode-escape')
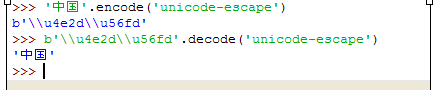
b'\\u4e2d'还是b'\u4e2d,一个斜杠貌似没影响。同时可以 发现在shell窗口中,直接输 '\u4e2d'和输入b '\u4e2d'.decode('unicode-escape')是相同的,都会打印出汉字‘中', 反而是 '\u4e2d'.decode('unicode-escape')会报错。说明 说明Python3不仅支持Unicode,而且一个‘\uxxxx'格式的 Unicode字符 可被辨识且被等价于str类型。

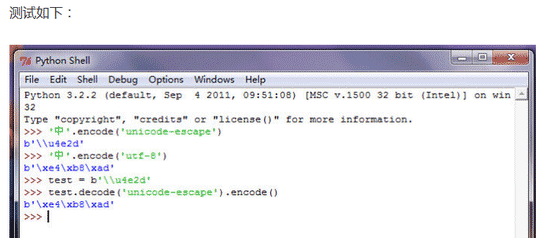
如果我们知道一个Unicode字节码,怎么变成UTF-8的字节码呢。懂了以上这些,现在我们就有思路了,先decode,再encode。代码如下:
xxx.decode('unicode-escape').encode()
最后的扩展
还记得刚刚那个ord吗。时代变迁,老大哥ASCII被人合并,但ord还是有用武之地。试试ord('中'),输出结果是20013。20013是什么呢,我们再试试hex(ord('中')),输出结果是'0x4e2d',也就是20013是我们在上文见面了无数次的x4e2d的十进制值。这里说下hex,是用来转换成十六进制的函数,学过单片机的人对hex肯定不会陌生。
最后的扩展,在网上看到的他人的问题。我们写下类似于'\u4e2d'的字符,Python3知道我们想表达什么。但是让Python读取某个文件的时候出现了'\u4e2d',是不是计算机就不认识它了呢?后来下文有人给出了答案。如下:
import codecs file = codecs.open( "a.txt", "r", "unicode-escape" ) u = file.read() print(u)
正文内容 python3编码问题的更多相关文章
- 转发:吐血总结,彻底明白 python3 编码原理
吐血总结,彻底明白 python3 编码原理 写的不错,转发学习一下,侵删.. 原文地址https://zhuanlan.zhihu.com/p/40834093 防止原文看不到了 这里粘贴复制一下: ...
- Python2 和 Python3 编码问题
基本存储单元 位(bit, b):二进制数中的一个数位,可以是0或者1,是计算机中数据的最小单位. 字节(Byte,B):计算机中数据的基本单位,每8位组成一个字节. 1B = 8b 各种信息在计算机 ...
- dede模版列表调用文章正文内容的方法
在制作织梦模板的时候,有的时候我们需要调用文章部分内容,用[field:description/]标签字数不够多(数据库设计字段是varchar(255)的),另外修改了文章内容但是摘要还需要手动修改 ...
- python3编码问题
继续收集python3编码问题相关资料 资料来源 鹏程的新浪博客(转载)http://blog.sina.com.cn/s/blog_6d7cf9e50102vo90.html 这篇鹏程老师写的关 ...
- python2和python3编码问题
欢迎加入python学习交流群 667279387 一.什么是编解码 1.什么是unicode 2.编码方式 二.python中的编解码 1.python2 (1).encode() 和 .decod ...
- python2和python3编码
python2编码 unicode:unicode 你好 u'\u4f60\u597d' | | | | encode('utf8')| |decode('utf8') encode('gbk')| ...
- 如何提取CSDN博客正文内容
document.getElementById("article_content").outerHTML; 在任意的一片博文运行以上代码都可以获得正文内容,但是对于代码.字体都没有 ...
- 帝国CMS批量提取正文内容到简介
最近接到一个帝国CMS模板改版项目,自带的数据可能是采集的,以前的简介字段内容只截取了60个字,新模板的简介60字符太少了,不美观,想让简介都截取200个字,怎么批量修改呢,文章太多了手动改肯定不行, ...
- scrapy 爬虫返回json格式内容unicode编码转换为中文的问题解决
最近在基于python3.6.5 的环境使用scrapy框架爬虫获取json数据,返回的数据是unicode格式的,在spider里面的parse接口中打印response.text出来如下: cla ...
随机推荐
- centos搭建gitlib
sudo yum install -y curl policycoreutils-python openssh-server sudo yum -y install postfixsudo syste ...
- 02 DML(DataManipulationLanguage)
1.插入记录 基本语法 : INSERT INTO tbl_name (col_name ,col_name1,..,col_nameN) VALUES (val1,val2, ...
- Web基础之Spring AOP与事务
Spring之AOP AOP 全程Aspect Oriented Programming,直译就是面向切面编程.和POP.OOP相似,它也是一种编程思想.OOP强调的是封装.继承.多态,也就是功能的模 ...
- Mac安装软件提示破损
安装提示破损 zhong终端输入 sudo spctl --master-disable 就可以顺利打开啦
- maven集成SSM项目,Tomcat部署运行——SSM整合框架搭建(二)之问题
问题一.当放开controller中的方法,出现如下问题 ### Error querying database. Cause: org.springframework.jdbc.CannotGetJ ...
- 095-PHP遍历关联数组,并修改数组元素值
<?php $arr=array('I'=>1,'II'=>2,'III'=>3,'IV'=>4,'V'=>5); //定义一个数组 echo '修改之前数组信息: ...
- GDI+3
关于这个的例子其实网上已经有这方面的资料了,但是为了文章的完整性,还是觉得有必要讲解.我们先来看一下效果: ( 图2 )接下来看看这是如何做到的. 思路:聊天窗体上有一个截图按钮,点击按钮后, ...
- junit基础学习之-引用spring容器的测试(7)
context 自动注入的文章链接:http://www.360doc.com/content/11/0815/09/2371584_140471325.shtml
- COGS1487 麻球繁衍
不会做%%http://blog.csdn.net/doom_bringer/article/details/50428503 #include<bits/stdc++.h> #defin ...
- 《Thinking in Java》位运算
按位操作符: 首先先记住一件事,方便理解:是否对应正负对应10. 1.与(&):11得1,10得0,00得0. 2.或(|):11得1,10得1,00得0. 3.异或(^):11得0,10得1 ...