Java并发基础类AbstractQueuedSynchronizer的实现原理简介
1.引子
Lock接口的主要实现类ReentrantLock 内部主要是利用一个Sync类型的成员变量sync来委托Lock锁接口的实现,而Sync继承于AbstractQueuedSynchronizer,且大多数java.util.concurrent包下的并发工具类都是利用AbstractQueuedSynchronizer同步器来委托实现的,它是用来构建锁或者其他同步组件的基础框架。要想弄明白并发的原理,必须先搞清楚AbstractQueuedSynchronizer的实现机制。
可以看出 AbstractQueuedSynchronizer的直接父类是AbstractOwnableSynchronizer。

AbstractOwnableSynchronizer的类定义
public abstract class AbstractOwnableSynchronizer
implements java.io.Serializable { private static final long serialVersionUID = 3737899427754241961L; protected AbstractOwnableSynchronizer() {
} private transient Thread exclusiveOwnerThread; protected final void setExclusiveOwnerThread(Thread thread) {
exclusiveOwnerThread = thread;
} protected final Thread getExclusiveOwnerThread() {
return exclusiveOwnerThread;
}
}
这个类中只有Thread类型exclusiveOwnerThread成员变量的一对setter/getter方法,用来设置/获取独占线程,正如其名中的“Ownable",此类就是"一个线程可能专有的同步器。"这一对setter/getter对于独占锁类型的并发工具特别有用。而ReentrantLock是一个可重入排他锁(排他锁又称独占锁),因此ReentrantLock这类中常用到这两个方法。
2.同步器的基本用法
AbstractQueuedSynchronizer的类部分注释如下:
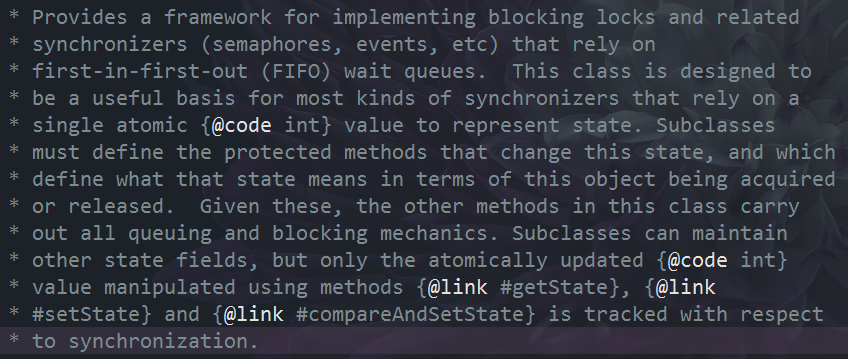
英文直译的意思是:此类提供用于实现阻塞锁及相关功能的框架依靠先进先出(FIFO)等待队列的同步器(semaphores, events, 等)。 为大多数依赖单个int类型原子值表示状态的同步器提供了实现基础。 子类必须定义更改此状态的受保护方法,并定义该状态对于获取或释放此对象而言意味着什么。 鉴于这些,此类中的其他方法将执行所有排队和阻塞机制。 子类可以维护其他状态字段,但是在同步方面仅跟踪使用方法{@link #getState},{@ link #setState}和{@ link#compareAndSetState}操作的原子更新的{@code int}值。
* Provides a framework for implementing blocking locks and related
* synchronizers (semaphores, events, etc) that rely on
* first-in-first-out (FIFO) wait queues. This class is designed to
* be a useful basis for most kinds of synchronizers that rely on a
* single atomic {@code int} value to represent state. Subclasses
* must define the protected methods that change this state, and which
* define what that state means in terms of this object being acquired
* or released. Given these, the other methods in this class carry
* out all queuing and blocking mechanics. Subclasses can maintain
* other state fields, but only the atomically updated {@code int}
* value manipulated using methods {@link #getState}, {@link
* #setState} and {@link #compareAndSetState} is tracked with respect
* to synchronization.
*
* <p>Subclasses should be defined as non-public internal helper
* classes that are used to implement the synchronization properties
* of their enclosing class. Class
* {@code AbstractQueuedSynchronizer} does not implement any
* synchronization interface. Instead it defines methods such as
* {@link #acquireInterruptibly} that can be invoked as
* appropriate by concrete locks and related synchronizers to
* implement their public methods.
*
* <p>This class supports either or both a default <em>exclusive</em>
* mode and a <em>shared</em> mode. When acquired in exclusive mode,
* attempted acquires by other threads cannot succeed. Shared mode
* acquires by multiple threads may (but need not) succeed. This class
* does not "understand" these differences except in the
* mechanical sense that when a shared mode acquire succeeds, the next
* waiting thread (if one exists) must also determine whether it can
* acquire as well. Threads waiting in the different modes share the
* same FIFO queue. Usually, implementation subclasses support only
* one of these modes, but both can come into play for example in a
* {@link ReadWriteLock}. Subclasses that support only exclusive or
* only shared modes need not define the methods supporting the unused mode.
*
* <p>This class defines a nested {@link ConditionObject} class that
* can be used as a {@link Condition} implementation by subclasses
* supporting exclusive mode for which method {@link
* #isHeldExclusively} reports whether synchronization is exclusively
* held with respect to the current thread, method {@link #release}
* invoked with the current {@link #getState} value fully releases
* this object, and {@link #acquire}, given this saved state value,
* eventually restores this object to its previous acquired state. No
* {@code AbstractQueuedSynchronizer} method otherwise creates such a
* condition, so if this constraint cannot be met, do not use it. The
* behavior of {@link ConditionObject} depends of course on the
* semantics of its synchronizer implementation.
*
* <p>This class provides inspection, instrumentation, and monitoring
* methods for the internal queue, as well as similar methods for
* condition objects. These can be exported as desired into classes
* using an {@code AbstractQueuedSynchronizer} for their
* synchronization mechanics.
*
* <p>Serialization of this class stores only the underlying atomic
* integer maintaining state, so deserialized objects have empty
* thread queues. Typical subclasses requiring serializability will
* define a {@code readObject} method that restores this to a known
* initial state upon deserialization.
主要英文类注释
用通俗的话来说:同步器的主要使用方式是继承,子类通过继承同步器并实现它的抽象方法来管理同步状态,在抽象方法的实现过程中免不了要对同步状态进行更改,这时就需要使用同步器提供的3个方法(getState()、setState(int newState)和compareAndSetState(int expect,int update))来进行操作,因为它们能够保证状态的改变是安全的。子类推荐被定义为自定义同步组件的静态内部类,同步器自身没有实现任何同步接口,它仅仅是定义了若干同步状态获取和释放的方法来供自定义同步组件使用,同步器既可以支持独占式地获取同步状态,也可以支持共享式地获取同步状态,这样就可以方便实现不同类型的同步组件。
使用技巧:
同步器的设计是基于模板方法模式的,也就是说,使用者需要继承同步器并重写指定的方法,随后将同步器组合在自定义同步组件的实现中,并调用同步器提供的模板方法,而这些模板方法将会调用使用者重写的方法。而重写同步器指定的方法时,需要使用同步器提供的如下3个方法来访问或修改同步状态
·getState():获取当前同步状态。
·setState(int newState):设置当前同步状态。
·compareAndSetState(int expect,int update):使用CAS设置当前状态,该方法能够保证状态设置的原子性。
可以看出,可父类同步器重写的主要方法有tryAcquire(arg)、 tryRelease(int) 、isHeldExcluseively() 、 tryAcquireShared(int) 、 tryReleaseShared(int)这五个,父类同步器AQS中的这5个方法不是抽象方法,是一个实例方法,但方法体中只有一行代码“throw new UnsupportedOperationException()”,如果不被重写则会实际调用父类的方法,将会直接报出异常。一般情况下,前两个方法是在排他锁中需要重写的方法(通常第3个方法”isHeldExcluseively()“也会被重写,将判断当前同步器是否在独占模式下被线程占用),而后两个方法是在共享锁中需要被重写,但基本上不可能同时重写这5个方法,因为一个锁不可能既是排他锁又是共享锁。
同步器可重写的方法:
| 方法名 | 描述 |
| boolean tryAcquire(int) | 独占式获取同步状态,实现此方法需要查询当前状态并判断同步状是否符合预期,然后再进行CAS设置同步状态 |
| boolean tryRelease(int) | 独占式释放同步状态,等待获取同步状态的线程将有机会获取同步状态 |
| boolean isHeldExclusively() | 当前同步器是否在独占模式下被线程占用,一般此方法表示是否被当前线程所独占 |
| int tryAcquireShared(int) | 共享式获取同步状态,反加大于等于0(等于0表示下个等待节点可能获取锁失败,大于0表示后面的等待节点获取锁很可能成功),表示获取成功,反之,获取失败。 |
| boolean tryReleaseShared(int) | 共享式释放同步状态 |
同步器AQS中的模板方法:
这些模板方法的方法体内将会调用以上5个可被重写的方法,
而自定义同步组件在实现一些同步功能时一般会使用委托的方式调用AQS的这些模板方法,而不会直接去调用上面AQS的那5个可重写的方法。当然也有例外,如ReentrantLock的tryLock()方法直接调用”boolean tryAcquire(int)“
| 方法 | 说明 |
| void acquire(int) | 独占式获取同步状态,如果当前线程获取同步状态成功,则由该方法返回,否则,将会进人同步队列等待,该方法将会调用重写的tryAcquire(int)方法 |
| void acquirelnterruptibly(int) | 与acquire(int arg)相同,但是该方法响应中断,当前线程未获取到同步状态而进入同步队列中,如果当前线程被中断,则该方法会抛出InterruptedException并返回 |
| boolean tryAcquireNanos(int ,long) | 在acquireTnterruptibly(int arg)基础上增加了超时限制,如果当前线程在超时时间内没有获取到同步状态,那么将会返回false,如果获取到了返回true |
| boolean release(int) |
独占式的释放同步状态,该方法会在释放同步状态之后,将同步队列中第一个节点包含的线程唤醒 |
| void acquireShared(int) | 共享式的获取同步状态,如果当前线程未获取到同步状态,将会进入同步队列等待,与独占式获取的主要区别是在同一时刻可以有多个线程获取到同步状态 |
| void acquireSharedInterruptibly(int) | 与acquireShared(int )相同,该方法响应中断 |
| boolean tryAcquireSharedNanos(int,long) | 在acquireSharedInterruptibly(int)基础上增加了超时限制 |
| boolean releaseShared(int) | 共享式的释放同步状态 |
| getQueuedThreads() | 获取等待在同步队列上的线程集合 |
AbstractQueuedSynchronizer类注释中的排他锁示例
class Mutex implements Lock, java.io.Serializable {
/**
* 如果state是0,表明锁没有被其他线程抢占,可以获取锁
* 如果state是1,表明锁被某个线程抢占了
*/
private static class Sync extends AbstractQueuedSynchronizer {
//锁的状态,即是否被某个抢占了
protected boolean isHeldExclusively() {
return getState() == 1;
}
//如果state是0,尝试抢锁
public boolean tryAcquire(int acquires) {
assert acquires == 1; // Otherwise unused
/*
*cas原子操作地修改state的值,修改成功,表示抢锁成功
* 则将当前线程设置为独占所有者线程
*/
if (compareAndSetState(0, 1)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
// 将state重置为0
protected boolean tryRelease(int releases) {
assert releases == 1; // Otherwise unused
//如果state为0,表明没有线程获取到锁,那么就不存在释放锁这各说法,所以管程状态错误
if (getState() == 0) throw new IllegalMonitorStateException();
//独占锁的释放,就是独占线程释放锁,所以独占所有者线程设为空
setExclusiveOwnerThread(null);
/*
*释放锁,表明之前锁已经被获取了,当前只会一个线程能够调用setState(),
* 所以可以不用compareAndSetState(int,int)方法来进行原子操作的更新,可以直接调用setState()方法
*/
setState(0);
return true;
}
Condition newCondition() {
return new ConditionObject();
}
private void readObject(ObjectInputStream s)
throws IOException, ClassNotFoundException {
s.defaultReadObject();
setState(0); // reset to unlocked state
}
}
// The sync object does all the hard work. We just forward to it.
private final Sync sync = new Sync();
//lock接口的实现全部委托给sync
public void lock() {
sync.acquire(1);
}
public boolean tryLock() {
return sync.tryAcquire(1);
}
public void unlock() {
sync.release(1);
}
public Condition newCondition() {
return sync.newCondition();
}
public boolean isLocked() {
return sync.isHeldExclusively();
}
public boolean hasQueuedThreads() {
return sync.hasQueuedThreads();
}
public void lockInterruptibly() throws InterruptedException {
sync.acquireInterruptibly(1);
}
public boolean tryLock(long timeout, TimeUnit unit)
throws InterruptedException {
return sync.tryAcquireNanos(1, unit.toNanos(timeout));
}
}
Mutex排他锁
上面的示例中:独占锁Mutex是一个自定义同步组件,它在同一时刻只允许一个线程占有锁。Mutex中定义了一个静态内部类,该内部类继承了同步器并实现了独占式获取和释放同步状态。在tryAcquire(int acquires)方法中,如果经过CAS设置成功(同步状态设置为1),则代表获取了同步状态,而在tryRelease(int releases)方法中只是将同步状态重置为0。用户使用Mutex时并不会直接和内部同步器的实现打交道,而是调用Mutex提供的方法,在Mutex的实现中,以获取锁的lock()方法为例,只需要在方法实现中调用同步器的模板方法acquire(int args)即可,当前线程调用该方法获取同步状态失败后会被加入到同步队列中等待
AbstractQueuedSynchronizer类注释中的共享锁示例:
这是一个类似于CountDownLatch的闩锁类,只不过它只需要触发一个信号即可。 因为闩锁是非排他性的,所以它使用共享的获取和释放方法。
class BooleanLatch {
private static class Sync extends AbstractQueuedSynchronizer {
boolean isSignalled() {
return getState() != 0;
}
protected int tryAcquireShared(int ignore) {
return isSignalled() ? 1 : -1;
}
protected boolean tryReleaseShared(int ignore) {
setState(1);
return true;
}
}
private final Sync sync = new Sync();
public boolean isSignalled() {
return sync.isSignalled();
}
public void signal() {
sync.releaseShared(1);
}
public void await() throws InterruptedException {
sync.acquireSharedInterruptibly(1);
}
}
BooleanLatch共享锁
3.AQS中的同步队列
主要的成员变量
private transient volatile Node head;
private transient volatile Node tail;
private volatile int state;
AbstractQueuedSynchronizer使用了一个int类型的名为state的成员变量表示同步状态,通过Node类型(Node是AbstractQueuedSynchronizer的静态内部类)的head 、tail头尾节点所确定的FIFO(双向链表型)队列来完成资源获取线程的排队工作。
而节点是构成同步队列(等待队列)的基础,同步器拥有首节点(head)和尾节点(tail),没有成功获取同步状态的线程将会成为节点加入该队列的尾部
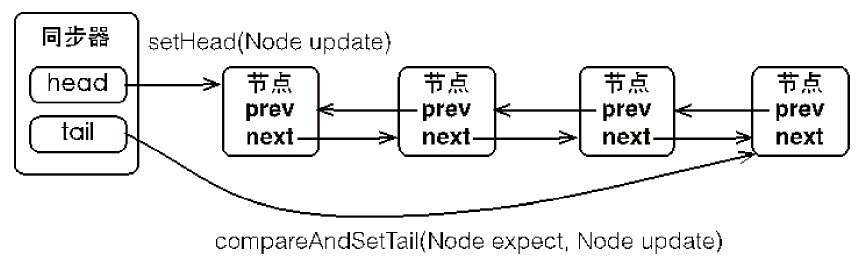 |
| 同步队列结构图 |
从上图可看出,同步器包含了两个节点类型的引用,一个指向头节点,而另一个指向尾节点。当一个线程成功地获取了同步状态(或者锁),其他线程将无法获取到同步状态,此节点需要添加到同步队列中,为保证线程安全,使用“compareAndSetTail(Node expect,Node update)"方法原子更新地在尾部插入等待节点(需要自旋循环直至更新成功)
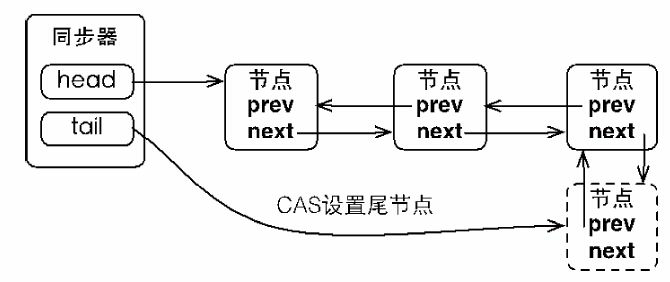 |
| 等待节点在尾部点入队 |
同步队列遵循FIFO,首节点是获取同步状态成功的节点,首节点的线程在释放同步状态时,将会唤醒后继节点,而后继节点将会在获取同步状态成功时将自己设置为首节点 。获取同步状态成功的线程才能设置首节点,且只有一个线程能获取到同步状态,不存在线程安全问题,所以不用CAS来设置节点
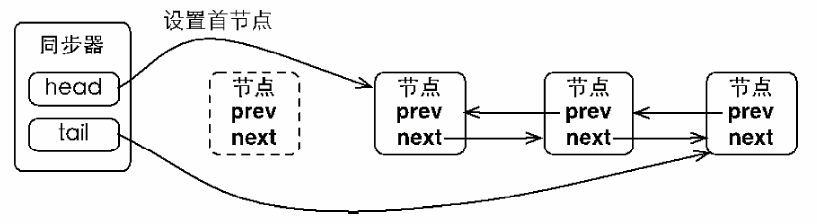 |
| 设置首节点 |
4.静态内部类Node的组成
Node节点是同步器AQS的一个关键内部类,一个Node实例表示一个双向链表型队列的一个节点 。
Node类的全部定义代码
static final class Node {
static final Node SHARED = new Node();
static final Node EXCLUSIVE = null;
static final int CANCELLED = 1;
static final int SIGNAL = -1;
static final int CONDITION = -2;
static final int PROPAGATE = -3;
volatile int waitStatus;
volatile Node prev;
volatile Node next;
volatile Thread thread;
Node nextWaiter;
final boolean isShared() {
return nextWaiter == SHARED;
}
final Node predecessor() throws NullPointerException {
Node p = prev;
if (p == null)
throw new NullPointerException();
else
return p;
}
Node() { // Used to establish initial head or SHARED marker
}
Node(Thread thread, Node mode) { // Used by addWaiter
this.nextWaiter = mode;
this.thread = thread;
}
Node(Thread thread, int waitStatus) { // Used by Condition
this.waitStatus = waitStatus;
this.thread = thread;
}
}
4.1 Node的成员变量
volatile int waitStatus;
volatile Node prev;
volatile Node next;
volatile Thread thread;
Node nextWaiter;
前几个属性都是用volatile关键字修饰,保存了内存的可见性,而nextWaiter属性在同步队列中一经初始化便不再变化,在条件队列中用锁保证可见性(在同步锁的lock与unlock之间的代码块中设置获取),因此可不用volatile修饰。
waitStatus属性表示当前节点的等待状态,具体含义见4.2。
thread属性表示当前节点入队等待的线程,即获取同步状态的线程。
prev 、next属性分别表示当前节点的前后驱节点。
nextWaiter属性在描述AQS同步队列的head、 tail两个成员变量中不起太大作用,只是表示共享型或独占型节点,nextWaiter属性主要在描述Condition条件队列的firstWaiter和lastWaiter两个成员变量中起重要作用,表示下一个等待条件的节点。
4.2 Node的静态常量
static final Node SHARED = new Node();
static final Node EXCLUSIVE = null;
static final int CANCELLED = 1;
static final int SIGNAL = -1;
static final int CONDITION = -2;
static final int PROPAGATE = -3;
静态常量SHARED和EXCLUSIVE分别代表在同步队列中当前节点的下一个等待节点的类型常数(共享型还是独占型)。
而静态常量CANCELLED、SIGNAL、CONDITION、PROPAGATE分别表示不同的等待状态,可以作为Node的waitStatus属性值。等待状态waitStatus各个取值的含义:
①CANCELLED,即值为1,同步队列中等待的线程等待超时或被中断,需要从同步队列中取消等待,节点进入此状态后不再变化。
②SIGNAL,即值为-1,后继节点的线程处于等待状, 而当前节点的线程如果释放了同步状态或者被取消,将通知后继节点,后继节点的线程将会运行
③CONDITION,即值为-2,节点在等待队列中,节点线程等待在Condition上,当其他线程对Condition调用了singal()方法后,该节点将会从等待队列中转移到同步队列中,加入到对同步状态的获取中
④PROPAGTE,即值为-3,表示下一次共享式同步状获取将会无条件地传播下去
⑤0,表示初始状态。 AQS在状态判断时,用waitStatus>0表示取消状态,waitStatus<=0表示有效状态。
4.2 Node的构造方法
Node() { // Used to establish initial head or SHARED marker
}
Node()方法没有方法体,使用属性的默认值,那么属性prev为null,前驱节点为空,表示为头节点;waitNode也为空,作为共享标记。
Node(Thread thread, Node mode) { // Used by addWaiter
this.nextWaiter = mode;
this.thread = thread;
}
Node(Thread thread, int waitStatus) { // Used by Condition
this.waitStatus = waitStatus;
this.thread = thread;
}
Node(Thread , Node)、 Node(Thread , int )节点分别作为等待队列、设置条件时使用。
5.独占锁的同步状态的获取与释放
5.1 获取同步状态
通过调用同步器的acquire(int arg)方法可以获取同步状态,该方法对中断不敏感,也就是由于线程获取同步状态失败后进入同步队列中,后续对线程进行中断操作时,线程不会从同步队列中移出
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
基本过程是:获取同步状态,构造等待节点、加入等待队列、自旋式地获取同步状态。
基本逻辑:先通过tryAcquire(int)方法(此方法由使用者自己来重写父类AQS定义相应规则)尝试获取同步状态,如果获取失败则将调用addWaiter()方法构建一个包含当前线程的排他型等待节点加入队列,然后再调用acquireQueued(Node,int)循环自旋CAS地获取同步状态。如果获取不到则阻塞节点中的线程,而被阻塞线程的唤醒主要依靠前驱节点的出队或阻塞线程被中断来实现.
现在来看到这几个方法的实现细节:
添加新的等待节点的方法addWaiter(Node)
主要通过调用compareAndSetTail(Node ,Node )方法来保证正确安全地设置尾节点,避免了非线程安全状态下添加新节点时节点先后顺序紊乱的情况。如果一次CAS设置尾节点失败,则直接进入enq(final Node)方法通过“死循环”形式地CAS操作,直到将节点设置成为尾节点成功后方法才能返回结束。
private Node addWaiter(Node mode) {
Node node = new Node(Thread.currentThread(), mode);
// Try the fast path of enq; backup to full enq on failure
Node pred = tail; //记录旧尾节点
if (pred != null) {
//pred不为null表明队列中至少有一个节点
node.prev = pred;//新添加的节点node作为队列最新的尾节点,那么node的前驱节点则是以前的旧尾节点
if (compareAndSetTail(pred, node)) {
/**
* cas设置新的尾节点成功,将从方法返回
* 旧尾节点的后继节点则是新添加的node节点
*/
pred.next = node;
return node;
}
}
//cas设置新的尾节点失败,进入enq方法,通过CAS进行死循环般地设置新的尾节点
enq(node);
return node;
}
private Node enq(final Node node) {
for (;;) {
Node t = tail;//尾节点为null,表明队列中一个节点都没有,是一个空队列
if (t == null) { // Must initialize
if (compareAndSetHead(new Node()))//CAS设置地设置头节点
tail = head;//此时队列中只有一个节点,头尾节点是同一个节点
} else {
node.prev = t;//新添加的节点node作为队列最新的尾节点,那么node的前驱节点则是以前的旧尾节点
if (compareAndSetTail(t, node)) {//CAS更新失败则继续循环CAS设置尾节点
/**
* cas设置新的尾节点成功,将从方法返回
* 旧尾节点的后继节点则是新添加的node节点
*/
t.next = node;
return t;
}
}
}
}
从等待队列中获取同步状态的方法acquireQueued(Node,int)
每个线程都尝试获取同步状态,当条件满足,获取到了同步状态,就可以从这个自旋过程中退出,否则依旧留在这个自旋过程中,方法就不能返回。
当前线程在“死循环”中尝试获取同步状态,而只有前驱节点是头节点才能够尝试获取同步状态,其原因主要体现在两方面:①首先队列这种数据结构要保证FIFO先进先出的基本原则。②其次头节点是当前获取到同步状态的节点,只有在头节点释放同步状态,才能通知后继节点可进入同步状态。
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;//获取同步状态的标志flag
try {
boolean interrupted = false;//线程中断标志的flag
for (;;) {
final Node p = node.predecessor(); //p为node的前驱节点
if (p == head && tryAcquire(arg)) {//p的前驱节点是头节点,且尝试获取同步状成功
/**
* setHead的方法体代码
* head = node;
* node.thread = null;
* node.prev = null;
*/
setHead(node);//将node设为新的头节点
p.next = null; //旧的头节点不会再使用了,将其相关属性解引用,便于垃圾回收
failed = false;
return interrupted;
}
/**
* shouldParkAfterFailedAcquire()方法用来检测在同步状态获取失败的情况下,线程是否需要阻塞.
* 如果shouldParkAfterFailedAcquire返回true,将会调用parkAndCheckInterrupt()进行线程阻塞,并进行中断状态检测,
* parkAndCheckInterrupt()返回是否中断的状态
*/
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed) //如果同步状态获取失败则取消同步状态的获取
cancelAcquire(node);
}
}
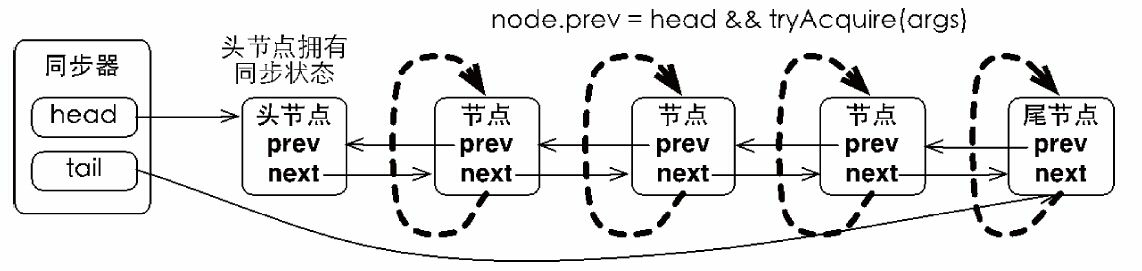
| 自旋地获取同步状态图 |
上图中可看出:由于非首节点线程前驱节点出队或者被中断而从等待状态返回,随后检查自己的前驱是否是头节点,如果是则尝试获取同步状态。可以看到节点和节点之间在循环检查的过程中基本不相互通信,而是简单地判断自己的前驱是否为头节点,这样就使得节点的释放规则符合FIFO,并且也便于对过早通知的处理(过早通知是指前驱节点不是头节点的线程由于中断而被唤醒)
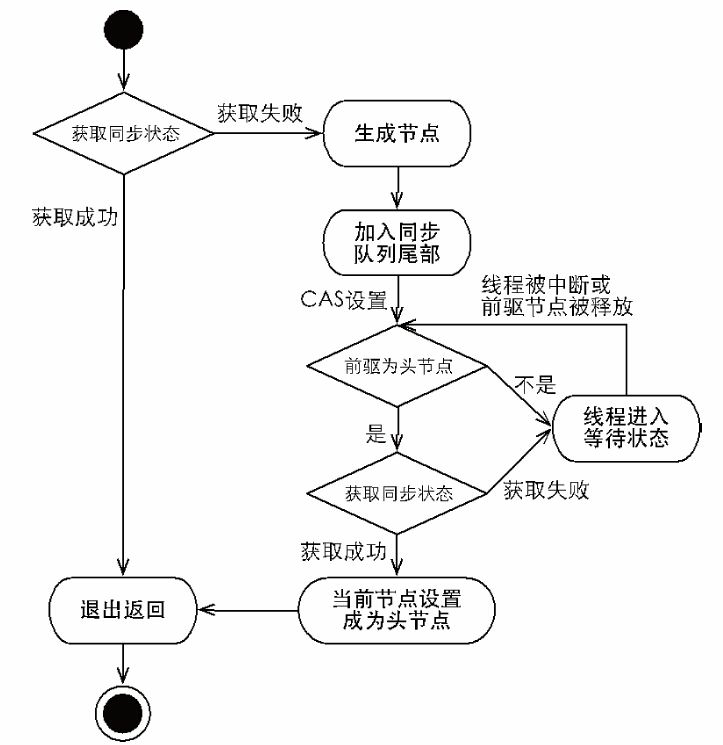 |
| 独占式同步状态获取流程 |
acquireQueued()方法体内部调用过的几个值得注意的方法
1)shouldParkAfterFailedAcquire(Node,Node)用来检测在同步状态获取失败的情况下,线程是否需要阻塞。为什么要判断node是否需要阻塞,因为有可能前面的节点是无效的。
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
int ws = pred.waitStatus;
if (ws == Node.SIGNAL)
/*
* This node has already set status asking a release
* to signal it, so it can safely park.
* 前驱节点刚好是SIGNAL,前驱节点就马上可能获取到同步状态了,
* 自己可以去休眠睡一会了。如果前驱状态不是SIGNAL,node还要参加同步状态的争夺,它还不能睡觉。
*/
return true;
if (ws > 0) { //ws==CANCELLED
/*
* Predecessor was cancelled. Skip over predecessors and
* indicate retry.
* 前驱节点被取消了,必须向前遍历找到一个有效状态的节点作为node的前驱节点。
* 中间这些无效的节点也从同步队列中移除掉了。
*/
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node;
} else {
/*
* waitStatus must be 0 or PROPAGATE. Indicate that we
* need a signal, but don't park yet. Caller will need to
* retry to make sure it cannot acquire before parking.
* 如果前驱正常,那就把前驱的状态设置成SIGNAL。CAS可能失败,pred可能刚释放锁
*/
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
}
return false;
2)而 parkAndCheckInterrupt()方法就很简单,休眠当前线程并检测当前线程是否被中断了。
private final boolean parkAndCheckInterrupt() {
LockSupport.park(this);
return Thread.interrupted();
}
3)cancelAcquire(Node)从同步队列中移除无效(取消状态)的节点
主要逻辑是:找到离node最近(node之前)的有效节点pred,同时将node与pred之间的无效节点移除,将node的state无条件设为CANCELLED,将node从队列中移除,更新pred与node.next的相互链接关系。
private void cancelAcquire(Node node) {
// Ignore if node doesn't exist
if (node == null)
return;
node.thread = null;
// Skip cancelled predecessors
//pred表示在队列中node前面的最近的有效节点
Node pred = node.prev;
////向前遍历找到离node最近的有效节点
while (pred.waitStatus > 0)
node.prev = pred = pred.prev;
//保存pred的原始后继节点,在CAS更新pre的后继节点将会用到predNext
Node predNext = pred.next; //
// Can use unconditional write instead of CAS here.
// After this atomic step, other Nodes can skip past us.
// Before, we are free of interference from other threads.
/*
*无条件设置为取消状态,在此后其他线程见到此节点的状态,将会路过此节点。
* 在此之前其他线程不受影响
*/
node.waitStatus = Node.CANCELLED;
// If we are the tail, remove ourselves.
//如果是node尾节点,则尝试将与node最近的有效节点pred设置为新的尾节点
if (node == tail && compareAndSetTail(node, pred)) {
/**
* 上面的CAS成功,pred就是最新的尾节点,尾节点的后继节点为null
* 因此CAS将pred的后继节点设为null,而之前的 “while (pred.waitStatus > 0)”循环已经将其前驱节点更新了。
*
*/
compareAndSetNext(pred, predNext, null);
} else {
// If successor needs signal, try to set pred's next-link
// so it will get one. Otherwise wake it up to propagate.
int ws;
if (pred != head &&
((ws = pred.waitStatus) == Node.SIGNAL ||
(ws <= 0 && compareAndSetWaitStatus(pred, ws, Node.SIGNAL))) &&
pred.thread != null) {
//当pred是中间节点,且(pred状态是SIGNAL或cas成功设为SIGNAL),
Node next = node.next;
if (next != null && next.waitStatus <= 0)
compareAndSetNext(pred, predNext, next);//将node的后继节点设pred的后继节点
} else {
//否则唤醒node的后继节点,其后继节点进行锁争夺
unparkSuccessor(node);
}
node.next = node; // help GC
}
}
5.2 可中断地获取同步状态
acquireInterruptibly(int)与上面的acquire(int)方法相比,增加了对线程中断的支持。
先检查当前线程若是中断的则直接抛出异常,方法得以返回,否则将尝试获取同步状态,若尝试获取失败则进入doAcquireInterruptibly(int)方法自旋(也是响应中断的)地获取同步状态
public final void acquireInterruptibly(int arg)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
if (!tryAcquire(arg))
doAcquireInterruptibly(arg);
}
doAcquireInterruptibly(int)与 acquireQueued(Node,int)相比,只有在检查到中断状态后的处理方式有所不同,acquireQueued方法用布尔变量interrupted标记为true,而doAcquireInterruptibly方法
则直接抛出异常。
private void doAcquireInterruptibly(int arg)
throws InterruptedException {
final Node node = addWaiter(Node.EXCLUSIVE);
boolean failed = true;
try {
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return;
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
/**
*与 acquireQueued(Node,int)相比,只有此处不同,acquireQueued方法在此处用布尔变量interrupted标记为true,
* 而本方法则直接抛出异常
*/
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
5.3 超时获取同步状态
tryAcquireNanos(int ,long)与acquireInterruptibly(int)相比,增加了对超时的支持
此方法会先检查当前线程是中断的则直接抛出异常,方法得以返回。否则将尝试获取同步状态,若尝试获取失败则进入doAcquireNanos(int,long)方法自旋限时(也是响应中断的)地获取同步状态,在限制时间内未获取到
同步状态方法仍将返回
public final boolean tryAcquireNanos(int arg, long nanosTimeout)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
return tryAcquire(arg) ||
doAcquireNanos(arg, nanosTimeout);
}
doAcquireNanos(int,long)方法与doAcquireInterruptibly(int)的主要区别是,doAcquireNanos做了超时时间的倒数准备,另外在超时剩余时间少于1000纳秒时不进行线程的阻塞,它直接进行死循环的快速自旋。
private boolean doAcquireNanos(int arg, long nanosTimeout)
throws InterruptedException {
if (nanosTimeout <= 0L)//nanosTimeout为负数,超时时间无效,直接返回false
return false;
final long deadline = System.nanoTime() + nanosTimeout;
final Node node = addWaiter(Node.EXCLUSIVE);
boolean failed = true;
try {
for (; ; ) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return true;
}
nanosTimeout = deadline - System.nanoTime();
if (nanosTimeout <= 0L)//超时间已到,方法返回false
return false;
if (shouldParkAfterFailedAcquire(p, node) &&
nanosTimeout > spinForTimeoutThreshold)
/*
*spinForTimeoutThreshold是常数为1000,当超时时间剩余不足1000纳秒时,
* 直接进入死循环的快速自旋,而不使用LockSupport.parkNanos方法进行线程阻塞。
* 主要原因是:在极短时间条件下,LockSupport.parkNanos无法做精细时间控制
*/
LockSupport.parkNanos(this, nanosTimeout);
if (Thread.interrupted())
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
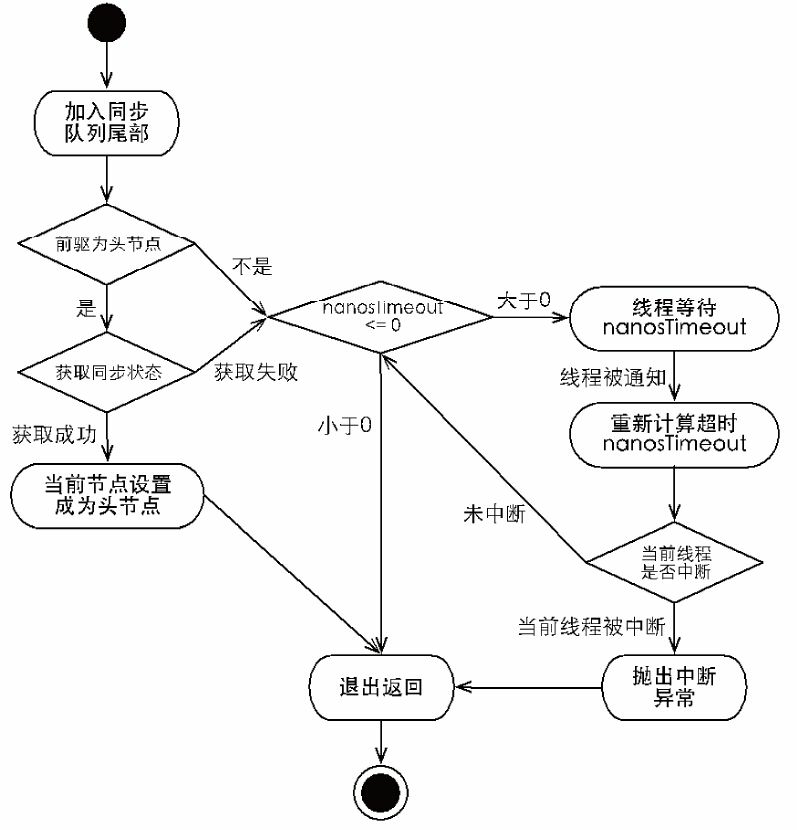 |
| 独占式超时同步状态获取流程 |
5.4 释放同步状态
释放同步状态release(int)方法:
先尝试释放同步状态,然后再唤醒头节点的后继节点线程
public final boolean release(int arg) {
if (tryRelease(arg)) {//尝试释放同步状态(同步组件需要重写tryRelease)
Node h = head;
if (h != null && h.waitStatus != 0)//waitStatus为零,是初始状态,获得同步状态节点的waitStatus不能为零。
unparkSuccessor(h);//唤醒后继节点
return true;
}
return false;
}
唤醒后继节点的方法unparkSuccessor(Node node):
主要逻辑是:将node节点的waitStatus设为初始值0 ,并唤醒可用的后继节点
private void unparkSuccessor(Node node) {
int ws = node.waitStatus;
/*
*waitStatus若为负数,表示可能需要一个信号,这里尝试将它清空,设为初始值0。若是正数只能是CANCELLED,这个状态不能再改变
*/
if (ws < 0)
compareAndSetWaitStatus(node, ws, 0);
/*
* 一般是直接将后继节点直接唤醒,但后继节点可能为null也可能是CANCELLED状态(此状态不再变化,需要从同步队列中取消等待),
* 因此在等待队列中从后向前遍历,找到离node最近的非CANCELLED后继节点
*/
Node s = node.next;
//waitStatus大于0,只能取Node.CANCELLED这个常量,常量值为1
if (s == null || s.waitStatus > 0) {//表达式的含义是:node后继节点为null或CANCELLED状态
s = null;
for (Node t = tail; t != null && t != node; t = t.prev)
if (t.waitStatus <= 0)//只要waitStatus不取值Node.CANCELLED,waitStatus就小于0
s = t;
}
if (s != null)
LockSupport.unpark(s.thread);//底层调用Unsafe的unpark(Thread)方法,这是一个用C++实现的本地方法,将线程唤醒
}
5.5 小结
在获取同步状态时,同步器维护一个同步队列,获取状态失败的线程都会被加入到队列中并在队列中进行自旋;移出队列(或停止自旋)的条件是前驱节点为头节点且成功获取了同步状态。
在释放同步状态时,同步器调用tryRelease(int arg)方法释放同步状态,然后唤醒头节点的后继节点
6.共享锁的同步状态的获取与释放
共享式获取与独占式获取最主要的区别在于同一时刻能否有多个线程同时获取到同步状态。以数据库为例,如果一个会话在某对些记录进行查询,那么这一刻对于这些记录的更新(增删改)操作均被阻塞,而其他的多个会话的查询操作也能够同时进行。写操作要求对资源的独占式访问,而读操作可以是共享式访问。这就是数据库读写分离的理论来源。
6.1 获取同步状态
在acquireShared(int )方法中,同步器调用tryAcquireShared(int )方法尝试获取同步状态,tryAcquireShared(int )方法返回值为int类型,当返回值大于等于0时,表示能够获取到同步状态。若返回值小于0,则进入doAcquireShared(int )方法自旋式获取同步状态,如果当前节点的前驱为头节点时,则尝试获取同步状态,如果返回值大于等于0,表示该次获取同步状态成功并从自旋过程中退出.
acquireShared(int )方法与大体上与"acquireQueued(int)"类似(当然尝试获取同步状态的方法由"tryAcquire(int)"换成了"tryAcquire(int)"),主要区别在于"acquireQueued(int)"不仅要设置新的头节点,还要根据获取同步状成功后的返回值来设置后继节点的waitState传播状态
public final void acquireShared(int arg) {
if (tryAcquireShared(arg) < 0)
doAcquireShared(arg);
}
private void doAcquireShared(int arg) {
final Node node = addWaiter(Node.SHARED);
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();
if (p == head) {
int r = tryAcquireShared(arg);
if (r >= 0) {
/**
* 与acquireQueued(int)的获取区主要在此,
* 不仅要设置新的头节点,还要根据获取同步状成功后的返回值来设置后继节点的waitState传播状态
*/
setHeadAndPropagate(node, r);
p.next = null; // help GC
if (interrupted)
selfInterrupt();
failed = false;
return;
}
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
其中的setHeadAndPropagate()方法,不只更新头节点,另外当还有剩余量时,还将唤醒下一个线程(包括设置传播量)
private void setHeadAndPropagate(Node node, int propagate) {
Node h = head; // Record old head for check below
setHead(node);
////如果还有剩余量,继续唤醒下一个邻居线程
if (propagate > 0 || h == null || h.waitStatus < 0 ||
(h = head) == null || h.waitStatus < 0) {
Node s = node.next;
if (s == null || s.isShared())
doReleaseShared();
}
}
另外共享式响应中断获取同步状态、共享式超时获取同步状态与独占式响应中断获取同步状态、独占式超时获取同步状态,它们之间的区别可以类比,这里不再赘述。
6.2 释放同步状态
releaseShared()方法在释放同步状态之后,将会唤醒后续处于等待状态的节点。对于能够支持多个线程同时访问的并发组件(比如Semaphore),它和独占式主要区别在于tryReleaseShared(int )方法必须确保同步状态线程安全释放,一般是通过循环和CAS来保证的,因为释放同步状态的操作会同时来自多个线程
public final boolean releaseShared(int arg) {
if (tryReleaseShared(arg)) {
doReleaseShared();
return true;
}
return false;
}
doReleaseShared()方法释放多个线程的同步状态
private void doReleaseShared() {
for (;;) {
Node h = head;
if (h != null && h != tail) {
int ws = h.waitStatus;
if (ws == Node.SIGNAL) {//SIGNAL表示后继节点的线程处于等待状态,当前节点释放后,后继节点则可运行
if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0))//尝试将waitState重置为初始状态0
continue; // CAS更新失败,将自旋调用compareAndSetWaitStatus更新为0
unparkSuccessor(h);//CAS成功将waitState设置为0,调用此方法来唤醒后继节点
}
//不需要信号SIGNAL,且waitState为0,则将尝试将waitState设置为Node.PROPAGATE(共享锁的特有状态)
else if (ws == 0 && !compareAndSetWaitStatus(h, 0, Node.PROPAGATE))
continue; // CAS更新失败,将自旋调用compareAndSetWaitStatus更新为Node.PROPAGATE
}
// 共享锁可同时被多个线程获取,也可能被多个线程同时释放,当其他某些线程将头节点被改变了(h与head不等),此自旋的循环将继续进行下去
if (h == head)
break;
}
}
6.3 设计简单的共享锁组件
此组件在同一时刻,只允许至多两个线程同时访问,超过两个线程的访问将被阻塞,我们将这个组件名为TwinsLock。
首先,确定访问模式。TwinsLock能够在同一时刻支持多个线程的访问,这显然是共享式访问,因此,需要使用同步器提供的acquireShared(int args)方法等和Shared相关的方法,这就要求TwinsLock必须重写tryAcquireShared(int args)方法和tryReleaseShared(int args)方法,这样才能保证同步器的共享式同步状态的获取与释放方法得以执行。
其次,定义资源数。TwinsLock在同一时刻允许至多两个线程的同时访问,表明同步资源数为2,这样可以设置初始状态status为2,当一个线程进行获取,status减1,该线程释放,则status加1,状态的合法范围为0、1和2,其中0表示当前已经有两个线程获取了同步资源,此时再有其他线程对同步状态进行获取,该线程只能被阻塞。在同步状态变更时,需要使用compareAndSet(int expect,int update)方法做原子性保障。
package aaxis.com.test1; import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.AbstractQueuedSynchronizer;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock; public class TwinsLock implements Lock { private final Sync sync = new Sync(2); private static final class Sync extends AbstractQueuedSynchronizer {
Sync(int count) {
if (count <= 0) {
throw new IllegalArgumentException("count must large than zero.");
}
setState(count);
} public int tryAcquireShared(int reduceCount) {
for (; ; ) {
int current = getState();
int newCount = current - reduceCount;
if (newCount < 0 || compareAndSetState(current,
newCount)) {
return newCount;
}
}
} public boolean tryReleaseShared(int returnCount) {
for (; ; ) {
int current = getState();
int newCount = current + returnCount;
if (compareAndSetState(current, newCount)) {
return true;
}
}
}
} public void lock() {
sync.acquireShared(1);
} @Override
public void lockInterruptibly() throws InterruptedException { } @Override
public boolean tryLock() {
return false;
} @Override
public boolean tryLock(long time, TimeUnit unit) throws InterruptedException {
return false;
} public void unlock() {
sync.releaseShared(1);
} @Override
public Condition newCondition() {
return null;
}
public static void main(String[] args) {
final Lock lock = new TwinsLock();
class Worker extends Thread {
public void run() {
while (true) {
lock.lock();
try {
Thread.sleep(1000);
System.out.println(Thread.currentThread().getName());
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}
}
// 启动10个线程
for (int i = 0; i < 10; i++) {
Worker w = new Worker();
w.setDaemon(true);
w.start();
}
// 每隔1秒换行
for (int i = 0; i < 10; i++) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
System.out.println();
}
}
}
}
TwinsLock
在上述示例中,TwinsLock实现了Lock接口,提供了面向使用者的接口,使用者调用lock()方法获取锁,随后调用unlock()方法释放锁,而同一时刻只能有两个线程同时获取到锁。TwinsLock同时包含了一个自定义同步器Sync,而该同步器面向线程访问和同步状态控制。以共享式获取同步状态为例:同步器会先计算出获取后的同步状态,然后通过CAS确保状态的正确设置,当tryAcquireShared(int reduceCount)方法返回值大于等于0时,当前线程才获取同步状态,对于上层的TwinsLock而言,则表示当前线程获得了锁。
在主方法测试中,定义了工作者线程Worker,该线程在执行过程中获取锁,当获取锁之后使当前线程睡眠1秒(并不释放锁),随后打印当前线程名称,最后再次睡眠1秒并释放锁。
测试结果显示:线程名称成对输出,也就是在同一时刻只有两个线程能够获取到锁。若将Sync(int)的构造参数修改成3,那么将每次打印3个线程名称。
参考:《Java并发编程的艺术》方腾飞
Java并发基础类AbstractQueuedSynchronizer的实现原理简介的更多相关文章
- Java 并发系列之二:java 并发机制的底层实现原理
1. 处理器实现原子操作 2. volatile /** 补充: 主要作用:内存可见性,是变量在多个线程中可见,修饰变量,解决一写多读的问题. 轻量级的synchronized,不会造成阻塞.性能比s ...
- java 并发多线程显式锁概念简介 什么是显式锁 多线程下篇(一)
目前对于同步,仅仅介绍了一个关键字synchronized,可以用于保证线程同步的原子性.可见性.有序性 对于synchronized关键字,对于静态方法默认是以该类的class对象作为锁,对于实例方 ...
- 《Java并发编程的艺术》Java并发机制的底层实现原理(二)
Java并发机制的底层实现原理 1.volatile volatile相当于轻量级的synchronized,在并发编程中保证数据的可见性,使用 valotile 修饰的变量,其内存模型会增加一个 L ...
- 【java并发编程艺术学习】(三)第二章 java并发机制的底层实现原理 学习记录(一) volatile
章节介绍 这一章节主要学习java并发机制的底层实现原理.主要学习volatile.synchronized和原子操作的实现原理.Java中的大部分容器和框架都依赖于此. Java代码 ==经过编译= ...
- Java并发机制的底层实现原理之volatile应用,初学者误看!
volatile的介绍: Java代码在编译后会变成Java字节码,字节码被类加载器加载到JVM里,JVM执行字节码,最终需要转化为汇编指令在CPU上执行,Java中所使用的并发机制依赖于JVM的实现 ...
- Java 并发机制底层实现 —— volatile 原理、synchronize 锁优化机制
本书部分摘自<Java 并发编程的艺术> 概述 相信大家都很熟悉如何使用 Java 编写处理并发的代码,也知道 Java 代码在编译后变成 Class 字节码,字节码被类加载器加载到 JV ...
- Java并发框架AbstractQueuedSynchronizer(AQS)
1.前言 本文介绍一下Java并发框架AQS,这是大神Doug Lea在JDK5的时候设计的一个抽象类,主要用于并发方面,功能强大.在新增的并发包中,很多工具类都能看到这个的影子,比如:CountDo ...
- Java并发编程笔记之ConcurrentHashMap原理探究
在多线程环境下,使用HashMap进行put操作时存在丢失数据的情况,为了避免这种bug的隐患,强烈建议使用ConcurrentHashMap代替HashMap. HashTable是一个线程安全的类 ...
- java 并发(五)---AbstractQueuedSynchronizer(4)
问题 : rwl 的底层实现是什么,应用场景是什么 读写锁 ReentrantReadWriteLock 首先我们来了解一下 ReentrantReadWriteLock 的作用是什么?和 Reent ...
随机推荐
- pygame库的学习
第一天:我学习了如何设置窗口和加载图片,以及加载音乐.这个库真的很有意思啊,打算py课设就拿这个写了. 代码: import pygamefrom sys import exit pygame.ini ...
- sessionManager配置
在sessionManager配置的时候,有两个属性, 在这个类中,cacheManager是要注入到sessionDao中的,但要求sessionDao实现CacheManagerAware接口 C ...
- mysql 命令行导入导出.sql文件
window下 1.导出整个数据库mysqldump -u 用户名 -p 数据库名 > 导出的文件名mysqldump -u dbuser -p dbname > dbname.sql 2 ...
- Typescript 实战 --- (9)ES6与CommonJS的模块系统
1.ES6模块系统 1-1.export 导出 (1).单独导出 // a.ts export let a = 1; (2).批量导出 // a.ts let b = 2; let c = 3; ex ...
- 使用 HTML5 视频事件
转自:http://msdn.microsoft.com/zh-cn/library/hh924822(v=vs.85).aspx 为什么要使用事件? HTML5 视频对象提供了很多事件,这些事件可以 ...
- ACM-寻宝
题目描述:寻宝 有这么一块神奇的矩形土地,为什么神奇呢?因为上面藏有很多的宝藏.该土地由N*M个小正方形土地格子组成,每个小正方形土地格子上,如果标有“E”,则表示该格可以通过:如果标有“X”,则表示 ...
- 使用Vue+JFinal框架搭建前后端分离系统
前后端分离作为Web开发的一种方式,现在应用越来越广泛.前端一般比较流行Vue.js框架,后端框架比较多,网上有很多Vue+SpringMVC前后端分离的demo,但是Vue+JFinal框架貌似没有 ...
- Day 30:HTML和CSS在Java项目中常用语法
framSet例子,其中的页面链接地址视情况而定,应为我还不知怎么弄当前文件下呢,例子主要在说明该标签如何使用 <!DOCTYPE html PUBLIC "-//W3C//DTD X ...
- 《ES6标准入门》(阮一峰)--3.变量的解构赋值
1.数组的解构赋值 基本用法 ES6 允许按照一定模式,从数组和对象中提取值,对变量进行赋值,这被称为解构(Destructuring). 以前,为变量赋值,只能直接指定值. let a = 1; l ...
- RadioGroup的使用
前言: 使用RadioGroup就可以在选择情况多的时候,简化代码 RadioGroup 使用互斥选择时,会使用RadioGroup标签下面RadioButton,如下面的代码:(这样写下来,男和女的 ...