#Week5 Regularization
一、The Problem of Overfitting
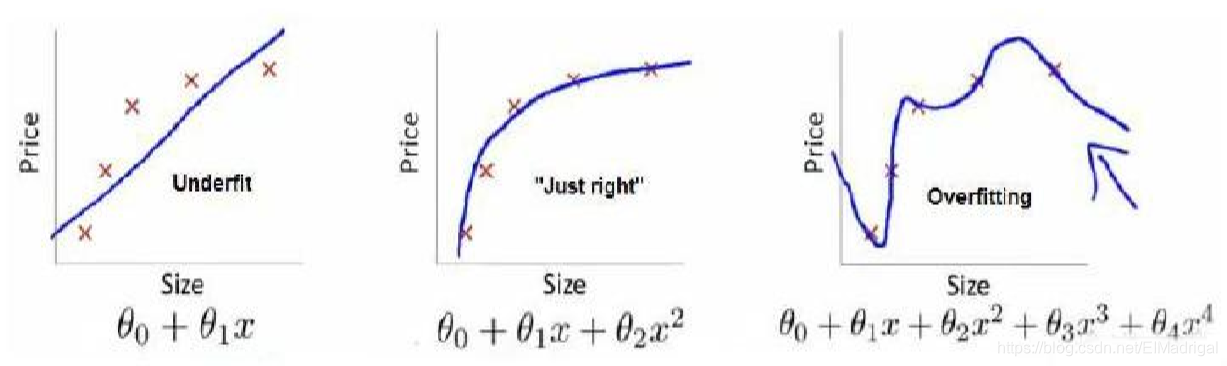
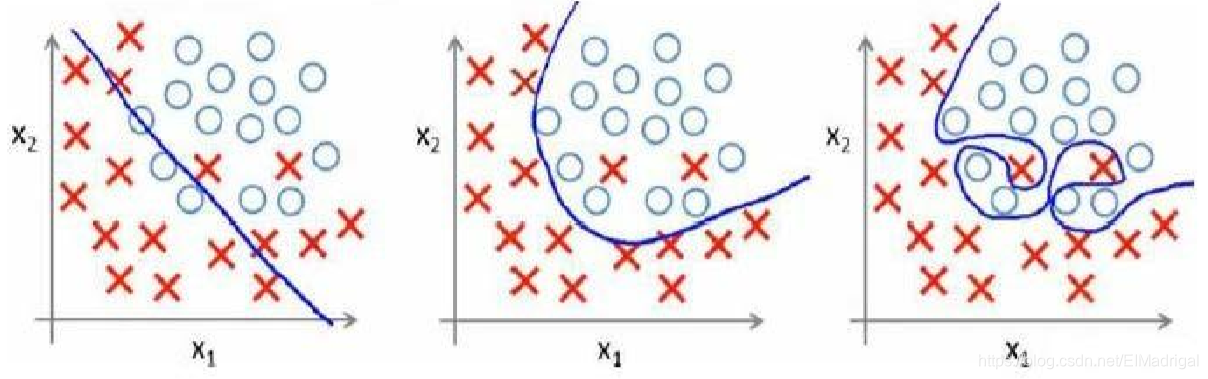
欠拟合(high bias):模型不能很好地适应训练集;
过拟合(high variance):模型过于强调拟合原始数据,测试时效果会比较差。
处理过拟合:
1、丢弃一些特征,包括人工丢弃和算法选择;
2、正则化:保留所有特征,但减小参数的值。
二、Cost Function
过拟合一般是由高次项引起,那么我们可以通过增加某些项的cost,来降低它们的权重。
在梯度下降过程中,要使损失函数变小,那么\(\theta\)就会变得很小,所以假设函数中的\(\theta\)就会变小,该项的权重就会降低。
如果不知道要惩罚哪些特征,可以一起惩罚(除了\(\theta_0\))。
将代价函数改为:
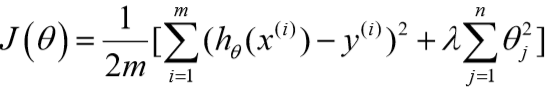
\(\lambda\)是正则化参数。
如果\(\lambda\)过大,那么所有的参数都会最小化,那么假设就会变为\(h_\theta(x)=\theta_0\),造成欠拟合。
三、Regularized Linear Regression
\(\theta_0\)没有正则化处理,所以梯度下降要分情况:
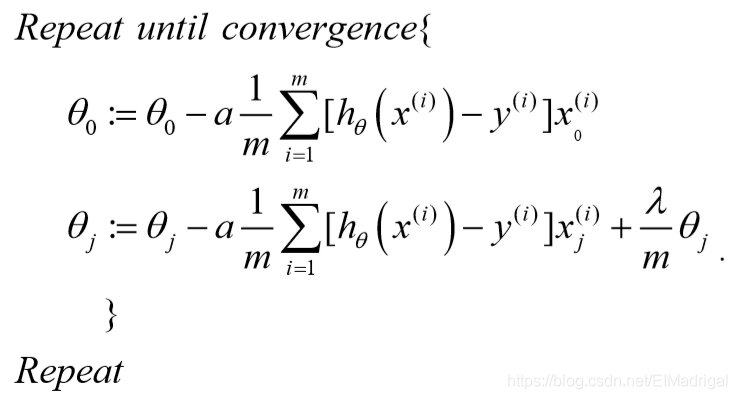
化简下:
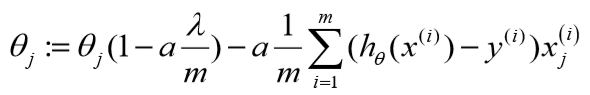
可以看到:
正则化后的参数更新比原来多减小了一个值。
再看线性回归的另外一个工具:常规方程。
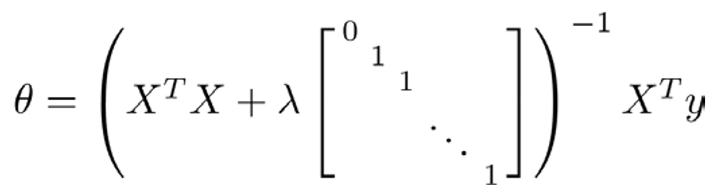
推导过程省略......
四、Regularized Logistic Regression
对于逻辑回归的代价函数,同样增加一个正则化表达式:
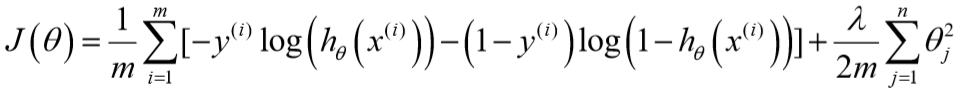
梯度下降算法与线性回归相同,不过\(h_\theta(x)\)不同。
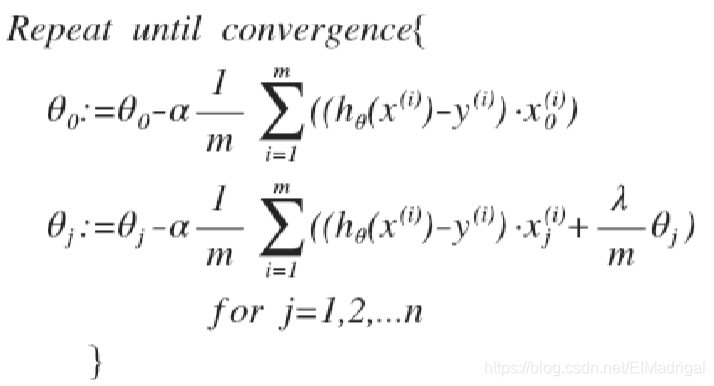
#Week5 Regularization的更多相关文章
- 数据预处理中归一化(Normalization)与损失函数中正则化(Regularization)解惑
背景:数据挖掘/机器学习中的术语较多,而且我的知识有限.之前一直疑惑正则这个概念.所以写了篇博文梳理下 摘要: 1.正则化(Regularization) 1.1 正则化的目的 1.2 正则化的L1范 ...
- 正则化方法:L1和L2 regularization、数据集扩增、dropout
正则化方法:防止过拟合,提高泛化能力 在训练数据不够多时,或者overtraining时,常常会导致overfitting(过拟合).其直观的表现如下图所示,随着训练过程的进行,模型复杂度增加,在tr ...
- Andrew Ng机器学习公开课笔记 -- Regularization and Model Selection
网易公开课,第10,11课 notes,http://cs229.stanford.edu/notes/cs229-notes5.pdf Model Selection 首先需要解决的问题是,模型 ...
- Stanford机器学习笔记-3.Bayesian statistics and Regularization
3. Bayesian statistics and Regularization Content 3. Bayesian statistics and Regularization. 3.1 Und ...
- Regularization on GBDT
之前一篇文章简单地讲了XGBoost的实现与普通GBDT实现的不同之处,本文尝试总结一下GBDT运用的正则化技巧. Early Stopping Early Stopping是机器学习迭代式训练模型中 ...
- 斯坦福第七课:正则化(Regularization)
7.1 过拟合的问题 7.2 代价函数 7.3 正则化线性回归 7.4 正则化的逻辑回归模型 7.1 过拟合的问题 如果我们有非常多的特征,我们通过学习得到的假设可能能够非常好地适应训练集( ...
- Stanford机器学习---第三讲. 逻辑回归和过拟合问题的解决 logistic Regression & Regularization
原文:http://blog.csdn.net/abcjennifer/article/details/7716281 本栏目(Machine learning)包括单参数的线性回归.多参数的线性回归 ...
- Machine Learning - 第3周(Logistic Regression、Regularization)
Logistic regression is a method for classifying data into discrete outcomes. For example, we might u ...
- (五)用正则化(Regularization)来解决过拟合
1 过拟合 过拟合就是训练模型的过程中,模型过度拟合训练数据,而不能很好的泛化到测试数据集上.出现over-fitting的原因是多方面的: 1) 训练数据过少,数据量与数据噪声是成反比的,少量数据导 ...
随机推荐
- 跟面试官侃半小时MySQL事务,说完原子性、一致性、持久性的实现
提到MySQL的事务,我相信对MySQL有了解的同学都能聊上几句,无论是面试求职,还是日常开发,MySQL的事务都跟我们息息相关. 而事务的ACID(即原子性Atomicity.一致性Consiste ...
- PowerShell入门简介
文章更新于:2020-03-03 一.PowerShell简介 说实话,我总感觉 PowerShell 是 cmd 的加强版,但是看官方介绍,功能甚是强大,用处有待我们发掘. 二.PowerShell ...
- 单线程IP扫描解析
扫描代码: private void Button_Click(object sender, RoutedEventArgs e) { a5.Items.Clear(); string str = t ...
- matplotlib BlendedGenericTransform(混合变换)和CompositeGenericTransform(复合变换)
2020-04-10 23:31:13 -- Edit by yangrayBlendedGenericTransform是Transform的子类,支持在x / y方向上使用不同的变换.(博主翻译为 ...
- alg-链表中有环
typedef struct ListNode { int val; ListNode *next; ListNode(int x) : val(x), next(nullptr) {} }ListN ...
- mysql 向上取整
SELECT CEILING(10.0) --->10 SELECT CEILING(10.1) --->11
- 【three.js第三课】鼠标事件,移动、旋转物体
1.下载three.js的源码包后,文件夹结构如下: 2.在[three.js第一课]的代码基础上,引入OrbitControls.js文件,此文件主要用于 对鼠标的操作. 该文件位置:在文件结构中 ...
- 【论文研读】强化学习入门之DQN
最近在学习斯坦福2017年秋季学期的<强化学习>课程,感兴趣的同学可以follow一下,Sergey大神的,有英文字幕,语速有点快,适合有一些基础的入门生. 今天主要总结上午看的有关DQN ...
- 深度学习之文本分类模型-前馈神经网络(Feed-Forward Neural Networks)
目录 DAN(Deep Average Network) Fasttext fasttext文本分类 fasttext的n-gram模型 Doc2vec DAN(Deep Average Networ ...
- Python生成一维码
参考页面 https://pypi.org/project/python-barcode/ 利用python-barcode的库 一.安装python-barcode库 #安装前提条件库 pip in ...