细说 PEP 468: Preserving Keyword Argument Order
细说 PEP 468: Preserving Keyword Argument Order
Python 3.6.0 版本对字典做了优化,新的字典速度更快,占用内存更少,非常神奇。从网上找了资料来看,大部分都指向了 [Python-Dev] More compact dictionaries with faster iteration 这篇文章,里面概括性地介绍了旧字典和新字典的差别,以及优化的地方,很有创意。
然而我非常好奇这样的结构是怎么用C语言实现的,所以去看了源码。我分别找到 3.5.9 和 3.6.0 版本的 Python 字典源代码,对比了一下,发现 Python 里字典的实现到处都是神操作,令人振奋。于是,一个想法产生了,不如就从源码角度,细说一下 PEP 468 对字典的改进,也算是对 [Python-Dev] More compact dictionaries with faster iteration 的补充。
如果上来就对比 3.5.9 和 3.6.0 的代码差异,是没有办法把事情说清楚的,所以我还得多啰嗦一些,把字典数据结构先完整地分析一下,然后就可以愉快地对比差异了 : )
如无特殊说明,默认参考Python 3.6.0版本。
新特性
在 Python 的新特性变更记录页面,可以看到 Python 从 3.6 版本开始,支持有序字典,而且内存占用更少。
Python 3.6.0 beta 1
Release date: 2016-09-12
Core and Builtins
dict 数据结构简述
我本来想拿 Python 3.5.9 的结构来对比一下,不过后来想了想,没有必要。二者差异不大,不需要把对比搞得很麻烦,我直接介绍 Python 3.6.0 的字典结构,然后直接对比源码细节,就已经够清楚了。再参考 [Python-Dev] More compact dictionaries with faster iteration ,就更清晰了。
结构
涉及到字典对象的结构主要有3个:
PyDictObject(./Include/dictobject.h)PyDictKeysObject(./Objects/dict-common.h) 就是头文件里面的struct _dictkeysobjectPyDictKeyEntry(./Objects/dict-common.h)
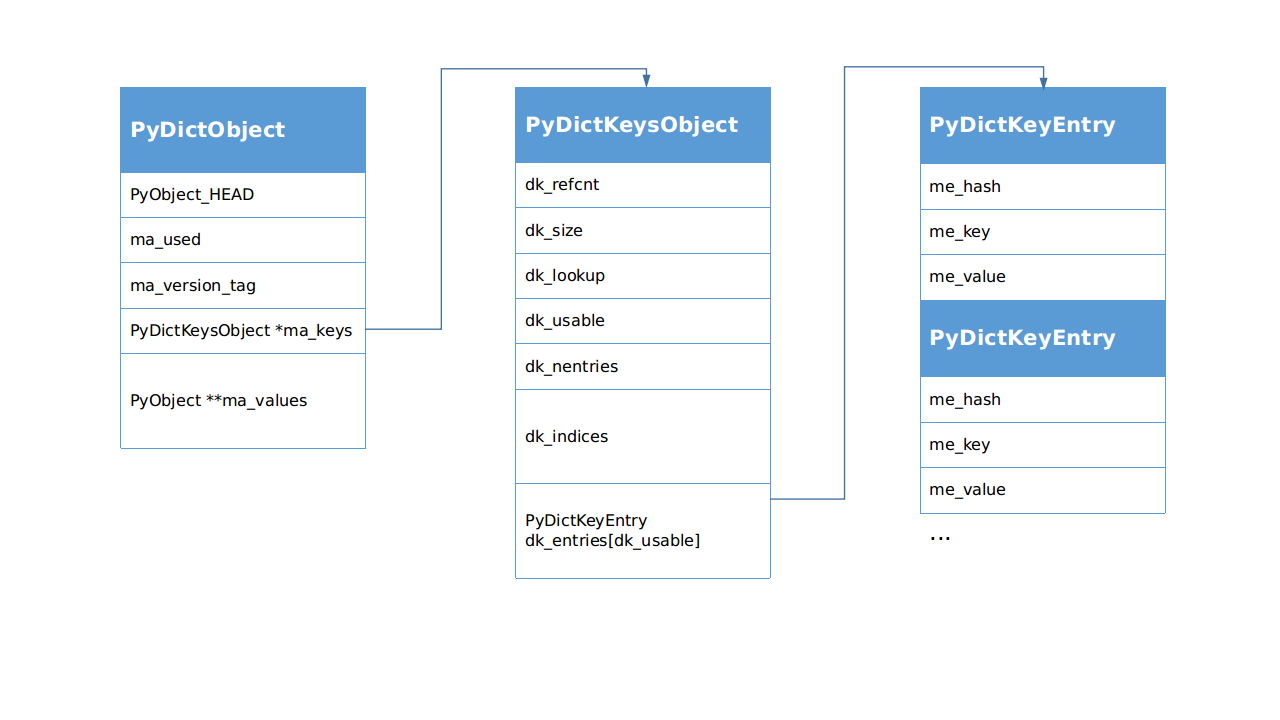
下面依次说明一下各个数据的定义:
PyDictObject字典对象,Python里面所有字典,不管是我们自己用
dict()创建的还是类的__dict__属性,都是它。PyObject_HEADPython里所有东西都是对象,而且这些对象都是无类型的,那么想想这两个问题:在C语言里,类型是固定的,而且没有运行时类型检查,那么怎么样实现动态调用呢?动态调用以后怎么识别类型呢?
没错,就是"看脸",假如每个对象都有一个这样的
PyObject_HEAD,其中包含类型信息,那么就可以用指针动态调用,然后根据其中的类型信息动态识别类型了。打个比方,假如你的对象很多很多,TA们的身高体重长相各自都是固定的,你今天约这个,明天约那个,“类型”变了怎么办?不碍事呀,用手机“动态调用”,听声音或者见面“识别类型”,一个道理嘛,哈哈哈哈哈哈哈……再多说一句,一定要做好“类型检查”,如果让你的对象发现你心里想的是别人,那就翻车了!这时候程序就出错崩溃了!
ma_used当前字典里的
item数量。ma_version_tag有一个64位无符号全局变量
pydict_global_version,字典的创建和每次更改,都会给这个全局变量+1,然后赋值(不是引用)给ma_version_tag。所以在不同的时刻,只需要看ma_version_tag变没变,就知道字典变没变,不需要检查字典的内容。这个特性可以优化程序。参考 PEP 509 -- Add a private version to dictPyDictKeysObject *ma_keys字典的键对象指针,虽然这个对象叫
KeysObject,但是里面也有value,在"combined"模式下value(即 me_value)有效;而在"splitted"模式下me_value无效,改用PyObject **ma_values。dk_refcnt在"splitted"模式下,一个
PyDictKeysObject被很多PyDictObject共用,这个引用计数就起作用了。dk_size字典哈希表空间大小,指实际申请的内存空间,类似C++里
vector的capacity属性的含义。这个值也是数组
dk_indices的大小,必须是 2 的整数次幂,不够用时再动态扩容。尽管好奇心害死猫,不过为什么必须是 2 的整数次幂?我摘出来几行代码。
#define DK_MASK(dk) (((dk)->dk_size)-1)
size_t mask = DK_MASK(k);
i = (size_t)hash & mask; // 通过哈希值计算哈希表索引
这就明白了,哈希值的数据类型是
size_t,可能导致哈希表访问越界,所以要对哈希表长度取余数,为了用与操作加速取余数运算,把dk_size规定为 2 的整数次幂。dk_lookup查找函数,从哈希表中找出指定元素。共有4个函数。
/* Function to lookup in the hash table (dk_indices):
- lookdict(): general-purpose, and may return DKIX_ERROR if (and
only if) a comparison raises an exception. - lookdict_unicode(): specialized to Unicode string keys, comparison of
which can never raise an exception; that function can never return
DKIX_ERROR. - lookdict_unicode_nodummy(): similar to lookdict_unicode() but further
specialized for Unicode string keys that cannot be the value. - lookdict_split(): Version of lookdict() for split tables. */
Python 里大量用到以字符串作为
key的字典,所以对它做了专门的优化,尽量多用字符串作为key吧!dk_usable字典里的可用
entry(hash-key-value)数量,为了降低哈希碰撞,只占dk_size的2/3,由USABLE_FRACTION宏设置。这个值在初始化时也是数组
dk_entries或ma_values的大小,不够用时再动态扩容。dk_nentries数组
dk_entries或ma_values的已用entry数量。dk_indices哈希索引表数组,它是一个哈希表,但是存储的内容是
dk_entries里元素的索引。参考 PEP 468 -- Preserving the order of **kwargs in a function.
PyDictKeyEntry dk_entries[dk_usable]Python 里管一个
hash-key-value的组合叫一个entry,这个概念会经常出现。注意它和ma_values的区别,dk_entries是一个数组,存储区域紧跟在dk_indices后面,而ma_values是一个指针,指向的存储区域并不在PyDictObject末尾。在分析dictresize()函数的时候,会看到这个特性带来的影响。me_hashme_keyme_value
...(下一个
PyDictKeyEntry)
PyObject **ma_valuesPython 3.3 引入了新的字典实现方式:
splitted dict,这是一个针对类属性实现的结构,想象这样的应用场景:一个类,定义好以后属性名字不变(假设不动态更改),它有很多不同的实例,这些实例属性值不同,但是属性名字相同,如果这些__dict__共用一套key,可以节约内存。参考 PEP 412 -- Key-Sharing Dictionary在这个模式下,多个不同的
PyDictObject对象里面的ma_keys指针指向同一个PyDictKeysObject对象。原来的字典里的entry(hash-key-value)是一个整体,牵一发而动全身,现在key合并了,也就意味着entry合并了,所以value也被迫合并了,但是我们不能让value合并,因为这种模式下不同的PyDictKeysObject对象的key一样,但是value不一样,没有办法,就只好在entry结构外面添加value数组,代替被迫合并的entry->value,这个外加的value数组就分别附加到多个不同的PyDictObject对象后面。这个做法分开了key和value,所以取名"splitted"/* If ma_values is NULL, the table is "combined": keys and values
are stored in ma_keys. If ma_values is not NULL, the table is splitted:
keys are stored in ma_keys and values are stored in ma_values */PyObject **ma_values;
此外,“splitted”模式还有2个条件,与类属性吻合:
Only string (unicode) keys are allowed.
All dicts sharing same key must have same insertion order.
源码
把 Python 3.5.9 版本和 3.6.0 版本的结构体拿出来对比一下,Python 3.6.0 加了很多在 Python 3.5.9 里面没有的注释,非常优秀的行为!!不过这里只保留了不同部分的注释。
/* ./Objects/dict-common.h */
/* Python 3.5.9 */
struct _dictkeysobject {
Py_ssize_t dk_refcnt;
Py_ssize_t dk_size;
dict_lookup_func dk_lookup;
Py_ssize_t dk_usable;
PyDictKeyEntry dk_entries[1];
};
/* Python 3.6.0 */
struct _dictkeysobject {
Py_ssize_t dk_refcnt;
Py_ssize_t dk_size;
dict_lookup_func dk_lookup;
Py_ssize_t dk_usable;
/* Number of used entries in dk_entries. */
Py_ssize_t dk_nentries;
/* Actual hash table of dk_size entries. It holds indices in dk_entries,
or DKIX_EMPTY(-1) or DKIX_DUMMY(-2).
Indices must be: 0 <= indice < USABLE_FRACTION(dk_size).
The size in bytes of an indice depends on dk_size:
- 1 byte if dk_size <= 0xff (char*)
- 2 bytes if dk_size <= 0xffff (int16_t*)
- 4 bytes if dk_size <= 0xffffffff (int32_t*)
- 8 bytes otherwise (int64_t*)
Dynamically sized, 8 is minimum. */
union {
int8_t as_1[8];
int16_t as_2[4];
int32_t as_4[2];
#if SIZEOF_VOID_P > 4
int64_t as_8[1];
#endif
} dk_indices;
/* "PyDictKeyEntry dk_entries[dk_usable];" array follows:
see the DK_ENTRIES() macro */
};
通过注释可以知道这些新添加的变量的用途,不过在结构体里面,dk_entries的定义注释掉了,这是怎么回事呢?根据注释的指引,找到DK_ENTRIES一探究竟。
/* Python 3.6.0 */
/* ./Objects/dictobject.c */
#define DK_SIZE(dk) ((dk)->dk_size)
#if SIZEOF_VOID_P > 4
#define DK_IXSIZE(dk) \
(DK_SIZE(dk) <= 0xff ? \
1 : DK_SIZE(dk) <= 0xffff ? \
2 : DK_SIZE(dk) <= 0xffffffff ? \
4 : sizeof(int64_t))
#else
#define DK_IXSIZE(dk) \
(DK_SIZE(dk) <= 0xff ? \
1 : DK_SIZE(dk) <= 0xffff ? \
2 : sizeof(int32_t))
#endif
#define DK_ENTRIES(dk) \
((PyDictKeyEntry*)(&(dk)->dk_indices.as_1[DK_SIZE(dk) * DK_IXSIZE(dk)]))
DK_SIZE取得dk_size,也就是数组dk_indices的元素数量DK_IXSIZE根据dk_size设置当前dk_indices每个元素占用的字节数DK_ENTRIES根据dk对象(PyDictKeysObject对象)取得dk_entries数组首地址
于是,dk_indices.as_1[DK_SIZE(dk) * DK_IXSIZE(dk)]就会定位到dk_indices后面的第一个地址,也就是dk_indices刚好越界的地方。什么?越界?对,因为后面紧跟着的就是dk_entries对应的空间,DK_ENTRIES宏取得的这个地址就是dk_entries数组的首地址。多么有趣的玩法 : )
为什么要搞这么麻烦呢?像 Python 3.5.9 里面那样直接定义dk_entries不好吗?我想这大概是因为dk_indices也是动态的。如果直接定义dk_entries,那它的首地址相对结构体而言就是固定的,当dk_indices数组长度动态变化的时候,使用&dk->dk_entries[0]这样的语句就会得到错误的地址。具体的内存分布还需要看new_keys_object()函数。
为什么小
接着上面的内容,分析new_keys_object()函数,从这里可以看到PyDictKeysObject对象的内存分布。我在关键位置加了注释,省略一些不影响理解流程的代码。
/* Python 3.6.0 */
/* ./Objects/dictobject.c */
...
/* Get the size of a structure member in bytes */
#define Py_MEMBER_SIZE(type, member) sizeof(((type *)0)->member)
...
static PyDictKeysObject *new_keys_object(Py_ssize_t size)
{
PyDictKeysObject *dk;
Py_ssize_t es, usable;
assert(size >= PyDict_MINSIZE);
assert(IS_POWER_OF_2(size));
// dk_indices 有 2/3 能用(usable), 1/3 不使用
// PyDictKeyEntry dk_entries[dk_usable] 只申请 usable 部分内存
usable = USABLE_FRACTION(size); // 2/3
if (size <= 0xff) {
es = 1; // 字节数
}
else if (size <= 0xffff) {
...
}
// 为 PyDictKeysObject *dk 申请内存
// 使用缓存池
if (size == PyDict_MINSIZE && numfreekeys > 0) {
dk = keys_free_list[--numfreekeys];
}
else {
dk = PyObject_MALLOC(// Py_MEMBER_SIZE 得到 dk_indices 之前的大小
sizeof(PyDictKeysObject)
- Py_MEMBER_SIZE(PyDictKeysObject, dk_indices)
// 字节数 * dk_indices元素数量
+ es * size
// PyDictKeyEntry dk_entries[dk_usable]
// 这部分内容没有在 struct _dictkeysobject 结构体里定义,但是实际申请了空间
// 因为 dk_indices 长度也是可变的,所以使用 DK_ENTRIES 宏来操作 dk_entries
// 为了节约空间,只申请 usable 部分,所以 dk_indices 比 dk_entries 长
+ sizeof(PyDictKeyEntry) * usable);
...
}
DK_DEBUG_INCREF dk->dk_refcnt = 1;
dk->dk_size = size;
dk->dk_usable = usable;
dk->dk_lookup = lookdict_unicode_nodummy;
dk->dk_nentries = 0;
// dk_indices 初始化为0xFF 对应 #define DKIX_EMPTY (-1)
memset(&dk->dk_indices.as_1[0], 0xff, es * size);
// dk_entries 初始化为 0
// DK_ENTRIES 宏用于定位 dk_entries,相当于 &dk->dk_entries[0]
memset(DK_ENTRIES(dk), 0, sizeof(PyDictKeyEntry) * usable);
return dk;
}
PyObject_MALLOC申请到的内存,就是这个字典的PyDictKeysObject对象,这个结构体内存可以分为3部分:
dk_indices之前的部分:sizeof(PyDictKeysObject) - Py_MEMBER_SIZE(PyDictKeysObject, dk_indices)用头文件定义的结构体大小减去
dk_indices的大小,就是dk_indices之前的部分,包含dk_refcnt, dk_size, dk_lookup, dk_usable, dk_nentriesdk_indices:es * size字节数 * dk_indices元素数量。
dk_entries:sizeof(PyDictKeyEntry) * usable)从这里可以看到,
dk_entries的长度不是size,只申请 usable 部分。
再对比一下 Python 3.5.9 的dk = PyMem_MALLOC(...)内存申请和dk_entries寻址,就可以明白二者巨大的差异。
/* Python 3.5.9 */
/* ./Objects/dictobject.c */
static PyDictKeysObject *new_keys_object(Py_ssize_t size)
{
PyDictKeysObject *dk;
Py_ssize_t i;
PyDictKeyEntry *ep0;
...
dk = PyMem_MALLOC(sizeof(PyDictKeysObject) +
// 结构体里面 PyDictKeyEntry dk_entries[1] 加上这里 size-1,共size个
sizeof(PyDictKeyEntry) * (size-1));
...
ep0 = &dk->dk_entries[0];
/* Hash value of slot 0 is used by popitem, so it must be initialized */
ep0->me_hash = 0;
for (i = 0; i < size; i++) {
ep0[i].me_key = NULL;
ep0[i].me_value = NULL;
}
dk->dk_lookup = lookdict_unicode_nodummy;
return dk;
}
对比一下这 2 个PyObject_MALLOC()函数申请的内存空间,就知道为什么新的字典占用内存更少了。
分析完内存布局, PEP 468 的改进就非常清晰了,现在可以对照 PEP 468 提供的资料确认一下,如果有一种豁然开朗的感觉,那就对了;如果没有,可能是茂密的头发阻碍了你变强,建议剃光。跟随 PEP 468 说明链接找到 [Python-Dev] More compact dictionaries with faster iteration ,里面描述的第一个entries数组对应 3.5.9 版本的dk_entries;后面的indices和entries对应 3.6.0 版本的dk_indices和dk_entries数组,跟上面的代码对上了。
The current memory layout for dictionaries is unnecessarily inefficient. It has a sparse table of 24-byte entries containing the hash value, key pointer, and value pointer.
Instead, the 24-byte entries should be stored in a dense table referenced by a sparse table of indices.
For example, the dictionary:
d = {'timmy': 'red', 'barry': 'green', 'guido': 'blue'}
is currently stored as:
entries = [['--', '--', '--'],
[-8522787127447073495, 'barry', 'green'],
['--', '--', '--'],
['--', '--', '--'],
['--', '--', '--'],
[-9092791511155847987, 'timmy', 'red'],
['--', '--', '--'],
[-6480567542315338377, 'guido', 'blue']]Instead, the data should be organized as follows:
indices = [None, 1, None, None, None, 0, None, 2]
entries = [[-9092791511155847987, 'timmy', 'red'],
[-8522787127447073495, 'barry', 'green'],
[-6480567542315338377, 'guido', 'blue']]Only the data layout needs to change. The hash table algorithms would stay the same. All of the current optimizations would be kept, including key-sharing dicts and custom lookup functions for string-only dicts. There is no change to the hash functions, the table search order, or collision statistics.
看完源码,对这个说明的理解就更加深刻了吧,嘿嘿 : )
不过,到这里还没完,new_keys_object()函数只是创建了PyDictKeysObject对象,最终目标应该是PyDictObject,创建PyDictObject对象的函数是PyDict_New()
/* Python 3.6.0 */
/* ./Objects/dictobject.c */
PyObject *
PyDict_New(void)
{
PyDictKeysObject *keys = new_keys_object(PyDict_MINSIZE);
if (keys == NULL)
return NULL;
return new_dict(keys, NULL); // combined 模式下 values 是 NULL
}
new_keys_object()看过了,接着看看new_dict(),仍然省略掉部分类型检查和异常检查代码。
/* Python 3.6.0 */
/* ./Objects/dictobject.c */
static PyObject *
new_dict(PyDictKeysObject *keys, PyObject **values)
{
PyDictObject *mp;
assert(keys != NULL);
if (numfree) {
// 缓存池
mp = free_list[--numfree];
...
_Py_NewReference((PyObject *)mp);
}
else {
mp = PyObject_GC_New(PyDictObject, &PyDict_Type);
...
}
mp->ma_keys = keys; // 传递 new_keys_object 函数生成的 PyDictKeysObject 对象
mp->ma_values = values; // combined 模式下 values 是 NULL
mp->ma_used = 0; // 初始化的字典没有元素
mp->ma_version_tag = DICT_NEXT_VERSION(); // 版本号,参考上面数据结构里的说明
assert(_PyDict_CheckConsistency(mp));
return (PyObject *)mp;
}
到这里,一个 dict 对象就算正式创建完成了,我们在 Python 里也可以开始愉快地玩耍了。不过注意,这里创建出来的字典是“combined”模式的。“splitted”模式的字典在“combined”模式基础上还初始化了ma_values,我这里就懒得详细介绍了。
为什么有序
通过前面分析的数据结构,我们知道,字典元素保存在dk_entries数组中。当一个数据结构有序,指的是它里面元素的顺序与插入顺序相同。元素插入哈希表的索引是哈希函数算出来的,应该是无序的,这就是之前的字典元素无序的原因。而 Python 3.6.0 引入了dk_indices数组,专门记录哈希表信息,那么元素插入的顺序信息就得以保留在dk_entries数组中。为了满足好奇心,下面分析一下插入函数。
/* Python 3.6.0 */
/* ./Objects/dictobject.c */
/*
Internal routine to insert a new item into the table.
Used both by the internal resize routine and by the public insert routine.
Returns -1 if an error occurred, or 0 on success.
*/
static int
insertdict(PyDictObject *mp, PyObject *key, Py_hash_t hash, PyObject *value)
{
PyObject *old_value;
PyObject **value_addr;
PyDictKeyEntry *ep, *ep0;
Py_ssize_t hashpos, ix;
...
ix = mp->ma_keys->dk_lookup(mp, key, hash, &value_addr, &hashpos);
...
Py_INCREF(value);
MAINTAIN_TRACKING(mp, key, value);
...
/* 插入新值 */
if (ix == DKIX_EMPTY) {
/* Insert into new slot. */
/* dk_entries 数组填满的时候给字典扩容 */
if (mp->ma_keys->dk_usable <= 0) {
/* Need to resize. */
if (insertion_resize(mp) < 0) {
Py_DECREF(value);
return -1;
}
find_empty_slot(mp, key, hash, &value_addr, &hashpos);
}
ep0 = DK_ENTRIES(mp->ma_keys);
ep = &ep0[mp->ma_keys->dk_nentries]; // 每次插入位置在最后
dk_set_index(mp->ma_keys, hashpos, mp->ma_keys->dk_nentries);
Py_INCREF(key);
ep->me_key = key;
ep->me_hash = hash;
if (mp->ma_values) {
assert (mp->ma_values[mp->ma_keys->dk_nentries] == NULL);
mp->ma_values[mp->ma_keys->dk_nentries] = value;
}
else {
ep->me_value = value;
}
mp->ma_used++;
mp->ma_version_tag = DICT_NEXT_VERSION();
mp->ma_keys->dk_usable--;
mp->ma_keys->dk_nentries++;
assert(mp->ma_keys->dk_usable >= 0);
assert(_PyDict_CheckConsistency(mp));
return 0;
}
assert(value_addr != NULL);
/* 替换旧值 */
old_value = *value_addr;
if (old_value != NULL) {
*value_addr = value;
mp->ma_version_tag = DICT_NEXT_VERSION();
assert(_PyDict_CheckConsistency(mp));
Py_DECREF(old_value); /* which **CAN** re-enter (see issue #22653) */
return 0;
}
/* pending state */
assert(_PyDict_HasSplitTable(mp));
assert(ix == mp->ma_used);
*value_addr = value;
mp->ma_used++;
mp->ma_version_tag = DICT_NEXT_VERSION();
assert(_PyDict_CheckConsistency(mp));
return 0;
}
在插入函数中,第一个重点关注对象应该是ix = mp->ma_keys->dk_lookup(mp, key, hash, &value_addr, &hashpos)这句代码。dk_lookup是一个函数指针,指向四大搜索函数的其中一个,这里有必要说明一下各参数和返回值:
参数
PyDictObject *mp(已知参数)字典对象,在该对象中查找。
PyObject *key(已知参数)entry里的key,代表key对象的引用,用于第一次判定,如果引用相同就找到了;如果不同再判断hashPy_hash_t hash(已知参数)entry里的hash,用于第二次判定,如果哈希值相同就找到了;如果不同就代表没找到。PyObject ***value_addr(未知参数,用指针返回数据)如果找到元素,则
value_addr返回对应的me_value的指针;如果没找到,*value_addr为NULLPy_ssize_t *hashpos(未知参数,用指针返回数据)hashpos返回元素在哈希表中的位置。
返回值
Py_ssize_t ix返回元素在
dk_entries数组中的索引。如果不是有效元素,ix可能是DKIX_EMPTY, DKIX_DUMMY, DKIX_ERROR中的一个,分别代表dk_entries数组中的 新空位,删除旧值留下的空位,错误。
了解了各个参数的作用,就可以继续愉快地看代码了。然后就看到了这一句ep = &ep0[mp->ma_keys->dk_nentries],根据它下面的代码可以知道,这个ep就是新元素插入的地方,代表一个PyDictKeyEntry对象指针,而mp->ma_keys->dk_nentries指向的位置,就是dk_entries数组的末尾。也就是说,每次的新元素插入字典,都会依次放到dk_entries数组里,保持了插入顺序。那么哈希函数计算出来的插入位置呢?答案就在dk_set_index(mp->ma_keys, hashpos, mp->ma_keys->dk_nentries)函数里。
/* Python 3.6.0 */
/* ./Objects/dictobject.c */
/* write to indices. */
static inline void
dk_set_index(PyDictKeysObject *keys, Py_ssize_t i, Py_ssize_t ix)
{
Py_ssize_t s = DK_SIZE(keys);
assert(ix >= DKIX_DUMMY);
if (s <= 0xff) {
int8_t *indices = keys->dk_indices.as_1;
assert(ix <= 0x7f);
indices[i] = (char)ix; // 填充 dk_indices 数组
}
else if (s <= 0xffff) {
...
}
}
可以看到,哈希函数计算出来的插入位置保存到了dk_indices数组里,而对应插入位置保存的信息就是这个元素在dk_entries数组里的索引。
如果没看明白,就再回顾一下 [Python-Dev] More compact dictionaries with faster iteration 中的描述。
For example, the dictionary:
d = {'timmy': 'red', 'barry': 'green', 'guido': 'blue'}
...
Instead, the data should be organized as follows:
indices = [None, 1, None, None, None, 0, None, 2]
entries = [[-9092791511155847987, 'timmy', 'red'],
[-8522787127447073495, 'barry', 'green'],
[-6480567542315338377, 'guido', 'blue']]
是时候了,现在拿出 Python 3.5.9 的代码对比一下,只对比 Empty 状态的 slot 插入代码即可。
/* Python 3.5.9 */
/* ./Objects/dictobject.c */
/*
Internal routine to insert a new item into the table.
Used both by the internal resize routine and by the public insert routine.
Returns -1 if an error occurred, or 0 on success.
*/
static int
insertdict(PyDictObject *mp, PyObject *key, Py_hash_t hash, PyObject *value)
{
PyObject *old_value;
PyObject **value_addr;
PyDictKeyEntry *ep;
assert(key != dummy);
Py_INCREF(key);
Py_INCREF(value);
...
ep = mp->ma_keys->dk_lookup(mp, key, hash, &value_addr);
...
old_value = *value_addr;
/* Active 状态 */
if (old_value != NULL) {
...
}
else {
/* Empty 状态 */
if (ep->me_key == NULL) {
if (mp->ma_keys->dk_usable <= 0) {
/* Need to resize. */
...
}
mp->ma_used++;
*value_addr = value; // 直接向 dk_entries 数组插入元素
mp->ma_keys->dk_usable--;
assert(mp->ma_keys->dk_usable >= 0);
ep->me_key = key;
ep->me_hash = hash;
assert(ep->me_key != NULL && ep->me_key != dummy);
}
/* Dummy 状态 */
else {
...
}
}
return 0;
...
}
可以看到*value_addr = value这句代码填充了dk_entries,但是这里信息是不够的,value_addr来自搜索函数,于是我找到通用搜索函数lookdict,来看下它里面获取插入位置的关键代码。
/* Python 3.5.9 */
/* ./Objects/dictobject.c */
static PyDictKeyEntry *
lookdict(PyDictObject *mp, PyObject *key,
Py_hash_t hash, PyObject ***value_addr)
{
...
mask = DK_MASK(mp->ma_keys);
ep0 = &mp->ma_keys->dk_entries[0];
i = (size_t)hash & mask; // 靠哈希值找到插入位置
ep = &ep0[i]; // 直接按照位置插入到 dk_entries 数组中
if (ep->me_key == NULL || ep->me_key == key) {
*value_addr = &ep->me_value; // 用指针返回 me_value 作为插入地址
return ep;
}
...
}
可以清晰地看到,哈希函数计算出来的位置是直接对应到dk_entries数组中的,元素也直接放进去,没有dk_indices数组。因为哈希值不是连续的,所以我们依次插入到dk_entries数组里的元素也就不连续了。
如果又没看明白,就再回顾一下 [Python-Dev] More compact dictionaries with faster iteration 中的描述。
For example, the dictionary:
d = {'timmy': 'red', 'barry': 'green', 'guido': 'blue'}
is currently stored as:
entries = [['--', '--', '--'],
[-8522787127447073495, 'barry', 'green'],
['--', '--', '--'],
['--', '--', '--'],
['--', '--', '--'],
[-9092791511155847987, 'timmy', 'red'],
['--', '--', '--'],
[-6480567542315338377, 'guido', 'blue']]
为什么快
迭代变快的原因源自dk_entries数组的密集化,迭代时遍历的数量少。Python 3.5.9 和 3.6.0 版本代码的写法差异不大,所以这里只摘取一段dictresize()的数据复制代码对比。对dictresize()函数的具体分析放在附录里。
/* ./Objects/dictobject.c */
/* Python 3.5.9 */
static int
dictresize(PyDictObject *mp, Py_ssize_t minused)
{
...
/* Main loop */
for (i = 0; i < oldsize; i++) {
PyDictKeyEntry *ep = &oldkeys->dk_entries[i];
if (ep->me_value != NULL) {
assert(ep->me_key != dummy);
insertdict_clean(mp, ep->me_key, ep->me_hash, ep->me_value);
}
}
mp->ma_keys->dk_usable -= mp->ma_used;
...
}
/* Python 3.6.0 */
static int
dictresize(PyDictObject *mp, Py_ssize_t minsize)
{
...
/* Main loop */
for (i = 0; i < oldkeys->dk_nentries; i++) {
PyDictKeyEntry *ep = &ep0[i];
if (ep->me_value != NULL) {
insertdict_clean(mp, ep->me_key, ep->me_hash, ep->me_value);
}
}
mp->ma_keys->dk_usable -= mp->ma_used;
...
}
现在知道是哪些代码节省了时间吗?就是所有for (i = 0; i < oldkeys->dk_nentries; i++){...}代码块。在 Python 3.5.9 中,它们对应for (i = 0; i < oldsize; i++){...},其中的oldsize等于oldkeys->dk_size,只看代码的写法,没有什么区别,但是根据USABLE_FRACTION的设置,dk_nentries只占dk_size的2/3,所以新的字典迭代次数少了1/3。在dict_items()函数中的迭代操作速度变快也是同样的原因。
现在再来看看 [Python-Dev] More compact dictionaries with faster iteration 里面的这几段话:
In addition to space savings, the new memory layout makes iteration faster. Currently, keys(), values, and items() loop over the sparse table, skipping-over free slots in the hash table. Now, keys/values/items can loop directly over the dense table, using fewer memory accesses.
Another benefit is that resizing is faster and touches fewer pieces of memory. Currently, every hash/key/value entry is moved or copied during a resize. In the new layout, only the indices are updated. For the most part, the hash/key/value entries never move (except for an occasional swap to fill a hole left by a deletion).
With the reduced memory footprint, we can also expect better cache utilization.
源码观后感
Python 的字典实现就是一套 tradeoff 的艺术,有太多的东西值得深思:
- 使用空间占申请空间的比重
- 哈希函数和探测函数的选用
- 初始化需要申请的最小空间
- 字典扩容时扩到多少
- 元素分布对 CPU 缓存的影响
目前 Python 里的各个参数都是通过大量测试得到的,考虑的场景很全面。然而,tradeoff 的艺术,也包括针对特定应用场景优化,如果能根据实际业务场景优化 Python 参数,性能还是可以提高的。
此外,几个性能优化的点:
缓存池只缓存小对象,大容量的字典的创建和扩容每次都要重新申请内存。多小算小呢?
#define PyDict_MINSIZE 8
8 allows dicts with no more than 5 active entries.
鉴于
lookdict_unicode()函数的存在,尽量用字符串作为key
参考./Objects/dictnotes.txt及./Objects/dictobject.c里的部分注释。
参考资料
- 《Python源码剖析》
- 关于python3.6中dict如何保证有序
- [Python-Dev] More compact dictionaries with faster iteration
- PEP 468 -- Preserving the order of **kwargs in a function.
- PEP 468: Preserving Keyword Argument Order
- issue27350
- https://morepypy.blogspot.hk/2015/01/faster-more-memory-efficient-and-more.html
- http://python-weekly.blogspot.com/2017/01/20-best-python-questions-at.html
附录
dict 扩容源码分析
扩容操作发生在元素插入的时候,当mp->ma_keys->dk_usable <= 0的时候,就对字典扩容,新容量使用GROWTH_RATE宏计算。dictresize()函数处理"combined"和"splitted"两种情况,需要分开看。
/* Python 3.6.0 */
/* ./Objects/dictobject.c */
/* GROWTH_RATE. Growth rate upon hitting maximum load.
* Currently set to used*2 + capacity/2.
* This means that dicts double in size when growing without deletions,
* but have more head room when the number of deletions is on a par with the
* number of insertions.
* Raising this to used*4 doubles memory consumption depending on the size of
* the dictionary, but results in half the number of resizes, less effort to
* resize.
* GROWTH_RATE was set to used*4 up to version 3.2.
* GROWTH_RATE was set to used*2 in version 3.3.0
*/
#define GROWTH_RATE(d) (((d)->ma_used*2)+((d)->ma_keys->dk_size>>1))
/*
Restructure the table by allocating a new table and reinserting all
items again. When entries have been deleted, the new table may
actually be smaller than the old one.
If a table is split (its keys and hashes are shared, its values are not),
then the values are temporarily copied into the table, it is resized as
a combined table, then the me_value slots in the old table are NULLed out.
After resizing a table is always combined,
but can be resplit by make_keys_shared().
*/
static int
dictresize(PyDictObject *mp, Py_ssize_t minsize)
{
Py_ssize_t i, newsize;
PyDictKeysObject *oldkeys;
PyObject **oldvalues;
PyDictKeyEntry *ep0;
/* Find the smallest table size > minused. */
/* 1. 计算新大小 */
for (newsize = PyDict_MINSIZE;
newsize < minsize && newsize > 0;
newsize <<= 1)
;
if (newsize <= 0) {
PyErr_NoMemory();
return -1;
}
/* 2. 申请新的 PyDictKeysObject 对象 */
oldkeys = mp->ma_keys;
oldvalues = mp->ma_values;
/* Allocate a new table. */
mp->ma_keys = new_keys_object(newsize);
if (mp->ma_keys == NULL) {
mp->ma_keys = oldkeys;
return -1;
}
// New table must be large enough.
assert(mp->ma_keys->dk_usable >= mp->ma_used);
if (oldkeys->dk_lookup == lookdict)
mp->ma_keys->dk_lookup = lookdict;
/* 3. 元素搬迁 */
mp->ma_values = NULL;
ep0 = DK_ENTRIES(oldkeys);
/* Main loop below assumes we can transfer refcount to new keys
* and that value is stored in me_value.
* Increment ref-counts and copy values here to compensate
* This (resizing a split table) should be relatively rare */
if (oldvalues != NULL) {
/* 3.1 splitted table 转换成 combined table */
for (i = 0; i < oldkeys->dk_nentries; i++) {
if (oldvalues[i] != NULL) {
Py_INCREF(ep0[i].me_key); // 要复制key,而原来的key也要用,所以增加引用计数
ep0[i].me_value = oldvalues[i];
}
}
}
/* Main loop */
for (i = 0; i < oldkeys->dk_nentries; i++) {
PyDictKeyEntry *ep = &ep0[i];
if (ep->me_value != NULL) {
insertdict_clean(mp, ep->me_key, ep->me_hash, ep->me_value);
}
}
mp->ma_keys->dk_usable -= mp->ma_used;
/* 4. 清理旧值 */
if (oldvalues != NULL) {
/* NULL out me_value slot in oldkeys, in case it was shared */
for (i = 0; i < oldkeys->dk_nentries; i++)
ep0[i].me_value = NULL;
DK_DECREF(oldkeys);
if (oldvalues != empty_values) {
free_values(oldvalues);
}
}
else {
assert(oldkeys->dk_lookup != lookdict_split);
assert(oldkeys->dk_refcnt == 1);
DK_DEBUG_DECREF PyObject_FREE(oldkeys);
}
return 0;
}
在分析函数内容前,先看下函数前面的说明:
Restructure the table by allocating a new table and reinserting all items again. When entries have been deleted, the new table may actually be smaller than the old one.
If a table is split (its keys and hashes are shared, its values are not), then the values are temporarily copied into the table, it is resized as a combined table, then the me_value slots in the old table are NULLed out. After resizing a table is always combined, but can be resplit by make_keys_shared().
这段说明告诉我们 2 件重要的事情:
新的字典可能比旧的小,因为旧字典可能存在一些删除的
entry。(字典删除元素后,为了保持探测序列不断开,元素状态转为dummy,创建新字典的时候去掉了这些dummy状态的元素)尽管如此,为了偷懒,我仍然把这个操作称为“扩容”。
“splitted”模式的字典经过扩容会永远变成"combined"模式,可以用
make_keys_shared()函数重新调整为"splitted"模式。扩容操作会把原来的分离的values拷贝到entry里。
我把这个函数分成了 4 个步骤:
计算新大小
程序重新计算了字典大小,可是参数
Py_ssize_t minsize不是字典大小吗?为什么要重新计算?minsize顾名思义,指定了调用者期望的字典大小,不过字典大小必须是 2 的整数次幂,所以重新算了下。翻看new_keys_object()函数,也会发现函数开头有这么一句:assert(IS_POWER_OF_2(size)),这是硬性要求,其原因已经在介绍数据结构的时候说过了,参考dk_size的说明。申请新的 PyDictKeysObject 对象
"combined"模式下,需要扩容的部分是
PyDictKeysObject对象里面的dk_indices和dk_entries,程序并没有直接扩容这部分,因为dk_indices和dk_entries不是指针,它们占用了PyDictKeysObject这个结构体后面连续的内存区域,所以直接重新申请了新的PyDictKeysObject对象。"splitted"模式下,本来还需要额外扩容
ma_values,不过因为扩容使字典转换为"combined"模式,所以实际上不需要扩容ma_values,直接申请新的PyDictKeysObject对象,把ma_values转移到dk_entries里面,再把ma_values指向NULL就好。好奇心又来了,为什么不把
dk_indices和dk_entries设置成指针,指向独立的数组呢?那样不就可以用realloc之类的函数扩容数组了吗?同时也不用重新申请PyDictKeysObject对象,也不用手动复制数组元素了。这个问题在网上和源码里都没找到答案,我就自己瞎猜一下吧。假如我现在换用指针,这两个数组在结构体外部申请独立的空间,那么会面临 2 个问题:
代码分散。本来只有一个
PyDictKeysObject对象,现在又多了 2 个外部数组,代码里除了添加相应的内存管理代码,还需要在每个函数里检测*dk_indices指针和*dk_entries指针是否为空;频繁的内存申请释放带来性能问题。现在的缓存池在
PyDictKeysObject对象释放的时候把对象加入缓存,并不立即销毁,原来的dk_indices和dk_entries都是结构体内部的数组,可以跟着结构体一起缓存,而换成指针的话就不行了。要解决这个问题,就要给外部数组单独加缓存池,这样又导致了代码分散的问题。
也不能说哪种方法就一定好或者一定差,这是一个 tradeoff 的问题,时间,空间,可维护性,不可兼得。
鱼与熊掌不可兼得。 --《鱼我所欲也》
Newton's third law. You got to leave something behind. --《Interstellar》
元素搬迁
splitted table 转换成 combined table
这一步把
ma_values转移到dk_entries里面的me_value,这样后面就可以按照"combined"模式操作这个 splitted table 了,操作完后,再把dk_entries里面的me_value还原。注意Py_INCREF(ep0[i].me_key)操作,即给每个key增加引用计数,为什么要这么做呢?原因还得到insertdict_clean()函数里去找。/* Python 3.6.0 */
/* ./Objects/dictobject.c */
/*
Internal routine used by dictresize() to insert an item which is
known to be absent from the dict. This routine also assumes that
the dict contains no deleted entries. Besides the performance benefit,
using insertdict() in dictresize() is dangerous (SF bug #1456209).
Note that no refcounts are changed by this routine; if needed, the caller
is responsible for incref'ing `key` and `value`.
Neither mp->ma_used nor k->dk_usable are modified by this routine; the caller
must set them correctly
*/
static void
insertdict_clean(PyDictObject *mp, PyObject *key, Py_hash_t hash,
PyObject *value)
{
size_t i;
PyDictKeysObject *k = mp->ma_keys;
size_t mask = (size_t)DK_SIZE(k)-1;
PyDictKeyEntry *ep0 = DK_ENTRIES(mp->ma_keys);
PyDictKeyEntry *ep;
...
i = hash & mask;
/* 探测处理哈希碰撞 */
for (size_t perturb = hash; dk_get_index(k, i) != DKIX_EMPTY;) {
perturb >>= PERTURB_SHIFT;
i = mask & ((i << 2) + i + perturb + 1);
}
/* 修改 PyDictKeysObject 对象参数 */
ep = &ep0[k->dk_nentries]; // 定位到 dk_entries 数组
assert(ep->me_value == NULL);
dk_set_index(k, i, k->dk_nentries); // 填充 dk_indices 数组
k->dk_nentries++;
/* 填充 dk_entries 数组 */
ep->me_key = key;
ep->me_hash = hash;
ep->me_value = value;
}
这个函数比
insertdict()函数更快,它的来历要参考 issue1456209 。留意函数前面说明注释里的这句话:Note that no refcounts are changed by this routine; if needed, the caller is responsible for incref'ing
keyandvalue.这个函数只是复制了值,并不改变任何引用计数。看到这里就明白了,旧的
PyDictKeysObject对象里面的key复制到新申请的PyDictKeysObject对象里去的时候,引用计数应该加一。那么问题又来了,为什么
value的引用计数没有增加呢?别忘了现在正在操作 split table, 旧的PyDictKeysObject对象是很多PyDictObject共用的,所以key也是共用的,为了不影响别的PyDictObject对象,需要把key复制到新PyDictKeysObject对象里;而oldvalues = mp->ma_values在PyDictObject对象里,是私有的,移动到新PyDictKeysObject对象里即可,不需保留原值,所以不需要修改引用计数。为了便于理解,打个比方:我抄李华的作业,抄完以后,李华的作业要还给李华,他也要交,于是作业的引用计数增加了我的一份,这就是复制
key的情况。而我转念一想,抄得太像会被老师发现,所以自己又重新改抄了部分内容,之前抄的扔了就行,所以虽然我写了 2 遍作业,但是最终只上交 1 份,作业的引用计数不变,这就是移动value的情况。为了更加便于理解,再说简单一点:
key是复制,引用计数+1;value是移动,引用计数+0
清理旧值
"combined"模式下,直接释放旧的
PyDictKeysObject对象;"splitted"模式下,需要还原旧的
PyDictKeysObject对象里的dk_entries里的me_value为NULL,原因参考 3.1 里面的第一句话。最后释放ma_values数组。
细说 PEP 468: Preserving Keyword Argument Order的更多相关文章
- senlin __init__() got an unexpected keyword argument 'additional_headers'
从senlin源码重新编译更新了服务,然后执行 senlin的 cli就遇到了错误: __init__() got an unexpected keyword argument 'additional ...
- TypeError: 'encoding' is an invalid keyword argument for this function
python 2.7 问题 data_file = open("F:\\MyPro\\data.yaml", "r", encoding='utf-8') 运行 ...
- TypeError: parse() got an unexpected keyword argument 'transport_encoding'
错误: TypeError: parse() got an unexpected keyword argument 'transport_encoding'You are using pip vers ...
- get() got an unexpected keyword argument
TypeError: get() got an unexpected keyword argument 'news_id'ERROR basehttp 154 "GET /news/3/ H ...
- TypeError: __init__() got an unexpected keyword argument 't_command'
python .\manage.py migrate 报错如下 λ python .\manage.py migrateTraceback (most recent call last): File ...
- TypeError: while_loop() got an unexpected keyword argument 'maximum_iterations'
错误: TypeError: while_loop() got an unexpected keyword argument 'maximum_iterations' 参照https://blog.c ...
- Django--bug--__init__() got an unexpected keyword argument 'qnique'
建立模型之后,执行迁移,报如下错误: __init__() got an unexpected keyword argument 'qnique' 错误原因:模型的属性的约束添加错误,这种错误一般就是 ...
- TypeError: to_categorical() got an unexpected keyword argument 'nb_classes'
在学习莫烦教程中keras教程时,报错:TypeError: to_categorical() got an unexpected keyword argument 'nb_classes',代码如下 ...
- TypeError: pivot_table() got an unexpected keyword argument 'rows'
利用Python进行数据分析>第二章,处理MovieLens 1M数据集,有句代码总是报错: mean_rating = data.pivot_table('rating', rows='tit ...
随机推荐
- python3(二十) module
# 在Python中,一个.py文件就称之为一个模块(Module) # 1.最大的好处是大大提高了代码的可维护性. # 2.可以被其他地方引用 # 3.python内置的模块和来自第三方的模块 # ...
- Java序列化机制中的类版本问题 serialVersionUID的静态字段 含义
Java序列化机制中的类版本问题 分类: [Java 基础]2014-10-31 21:13 480人阅读 评论(0) 收藏 举报 目录(?)[+] 原文地址:http://yanwu ...
- AJ学IOS 之ipad开发qq空间项目横竖屏幕适配
AJ分享,必须精品 一:效果图 先看效果 二:结构图 如图所示: 其中用到了UIView+extension分类 Masonry第三方框架做子控制器的适配 NYHomeViewController对应 ...
- Linux下配置mail使用外部SMTP发送邮件
修改/etc/mail.rc,增加两行:指定外部的smtp服务器地址.帐号密码等. # vi /etc/mail.rc set from=demo@qq.com smtp=smtp.qq.com se ...
- 猜数字和飞机大战(Python零基础入门)
前言 最近有很多零基础初学者问我,有没有适合零基础学习案例,毕竟零基础入门的知识点是非常的枯燥乏味的,如果没有实现效果展示出来,感觉学习起来特别的累,今天就给大家介绍两个零基础入门的基础案例:猜数字游 ...
- ASE课程总结 by 朱玉影
收获: 最大的收获应该就是对待选题要慎重吧,虽然前期做了一下调研,但是还是不够,所以到最后我们的项目才会不能公开发布,项目中间也是波折不断,导致我们走了很多弯路,浪费了很多时间吧.选题一定要慎重,慎重 ...
- 全平台阅读器 StartReader
前段时间在网上闲逛, 发现了一款全平台阅读器 StartReader, 用了一阵子感觉还不错,网址是: https://www.startreader.com/ 感觉这款阅读器是程序员的福音,it人员 ...
- 重装anaconda的记录,包含设置jupyter kernel
anaconda安装记录 官网下载最新版 linux:sh xx.sh 注意不要敲太多回车,容易错过配置bash的部分,还要手动添加 (vim ~/.bashrc 手动添加新bash,卸载时也要删掉此 ...
- SQL Server 之T-SQL基本语句 (1)
花了一天的时间看完了一本<SQL必知必会>,举个范例,来总结一下零碎的知识点.一般关于数据库操作的项目都会涉及到数据库的基本查询语句.在这里面就主要讲解一些基本常用的sql使用方法. 注: ...
- ASP.Net内置对象之网页之间传参(一)
Response对象 主要运用于数据从服务器发送到浏览器,可以输出数据.页面跳转.各个网页之间传参数等操作. 以下讲解几个常用例子: 在页面中输出数据 主要通过Write .WriteFile方法输出 ...