python与正则不得不说的故事
今日所得
正则表达式
re模块
正则表达式:字符
| 元字符 | 匹配内容 |
| . | 匹配除换行符以外的任意字符 |
| \w | 匹配字母或数字或下划线 |
| \s | 匹配任意的空白符 |
| \d | 匹配数字 |
| \n | 匹配一个换行符 |
| \t | 匹配一个制表符 |
| \b | 匹配一个单词的结尾 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结尾 |
| \W | 匹配非字母或数字或下划线 |
| \D | 匹配非数字 |
| \S | 匹配非空白符 |
| a|b | 匹配字符a或字符b |
| () | 匹配括号内的表达式,也表示一个组 |
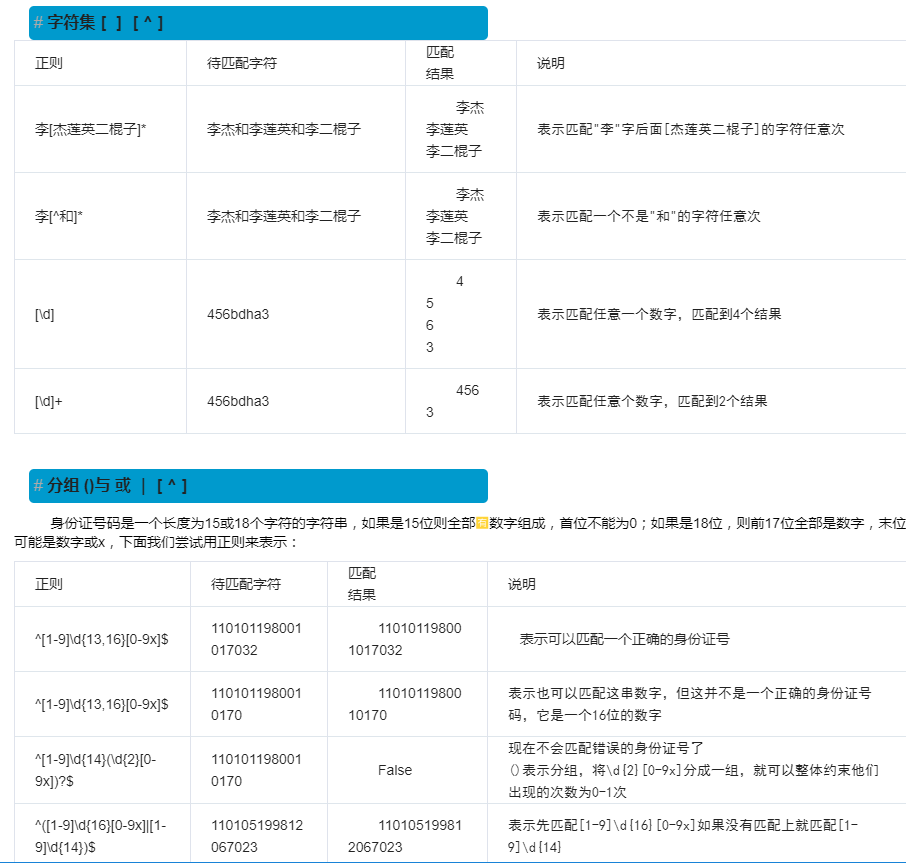
| [...] | 匹配字符组中的字符 |
| [^...] | 匹配除了字符组中字符的所有字符 |
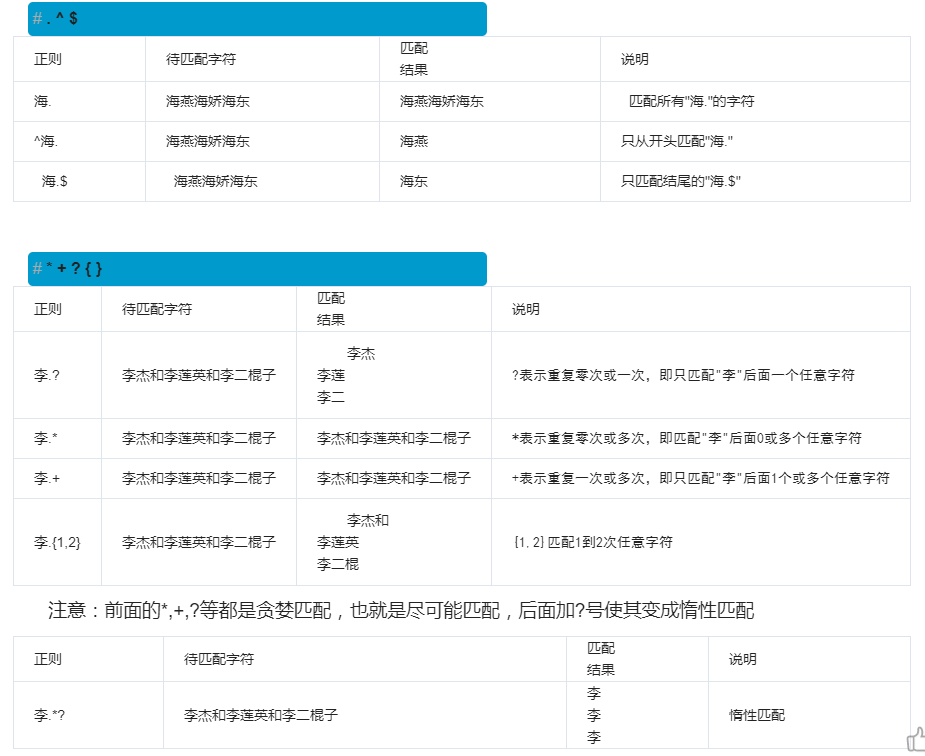
量词:
| 量词 | 用法说明 |
| * | 重复零次 |
| + | 重复一次或者更多次 |
| ? | 重复零次或者一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
分组()与或 | [^ ]
| 正则 | 待匹配字符 | 匹配结果 | 说明 |
| ^[1-9]\d{13,16}[0-9x]$ | 110101198001017032 | 110101198001017032 | 表示可以匹配一个正确的身份证号 |
| ^[1-9]\d{13,16}[0-9x]$ | 1101011980010170 | 1101011980010170 |
表示也可以匹配这串数字, |
| ^[1-9]\d{14}(\d{2}[0-9x])?$ | 1101011980010170 | False |
现在不会匹配错误的身份证号了 |
| ^([1-9]\d{16}[0-9x]|[1-9]\d{14})$ | 110105199812067023 | 110105199812067023 |
表示先匹配[1-9]\d{16}[0-9x]
|
转义符 \
| 正则 | 待匹配字符 | 匹配结果 | 说明 |
| \n | \n | False |
因为在正则表达式中\是有特殊意义的字符, |
| \\n | \n | True |
转义\之后变成\\,即可匹配 |
| "\\\\n" | '\\n' | True |
如果在python中, |
| r'\\n' | r'\n' | True |
在字符串之前加r,让整个字符串不转义 |
贪婪匹配:在满足匹配时,匹配尽可能长的字符串,默认情况下,采用贪婪匹配
| 正则 | 待匹配字符 | 匹配结果 | 说明 |
| <.*> | <script>...<script> | <script>...<script> |
默认为贪婪匹配模式, |
| <.*?> | <script>...<script> | <script> <script> |
加上?为将贪婪匹配模式转为非贪婪匹配模式, |
几个常用的非贪婪匹配Pattern
*? 重复任意次,但尽可能少重复
+? 重复1次或更多次,但尽可能少重复
?? 重复0次或1次,但尽可能少重复
{n,m}? 重复n到m次,但尽可能少重复
{n,}? 重复n次以上,但尽可能少重复
re模块下的常用方法
import re
ret = re.findall('a', 'eva egon yuan') # 返回所有满足匹配条件的结果,放在列表里
print(ret) #结果 : ['a', 'a']
ret = re.search('a', 'eva egon yuan').group()
print(ret) #结果 : 'a'
# 函数会在字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以
# 通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。
"""
注意:
1.search只会依据正则查一次 只要查到了结果 就不会再往后查找
2.当查找的结果不存在的情况下 调用group直接报错
"""
ret = re.match('a', 'abc').group() # 同search,不过尽在字符串开始处进行匹配
print(ret)
#结果 : 'a'
"""
注意:
1.match只会匹配字符串的开头部分
2.当字符串的开头不符合匹配规则的情况下 返回的也是None 调用group也会报错
"""
ret = re.split('[ab]', 'abcd') # 先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割
print(ret) # ['', '', 'cd']
ret = re.sub('\d', 'H', 'eva3egon4yuan4', 1)#将数字替换成'H',参数1表示只替换1个
print(ret) #evaHegon4yuan4
ret = re.subn('\d', 'H', 'eva3egon4yuan4')#将数字替换成'H',返回元组(替换的结果,替换了多少次)
print(ret)
obj = re.compile('\d{3}') #将正则表达式编译成为一个 正则表达式对象,规则要匹配的是3个数字
ret = obj.search('abc123eeee') #正则表达式对象调用search,参数为待匹配的字符串
print(ret.group()) #结果 : 123
import re
ret = re.finditer('\d', 'ds3sy4784a') #finditer返回一个存放匹配结果的迭代器
print(ret) # <callable_iterator object at 0x10195f940>
print(next(ret).group()) #查看第一个结果
print(next(ret).group()) #查看第二个结果
print([i.group() for i in ret]) #查看剩余的左右结果
注意:
1.findall的优先级查询:
import re
ret = re.findall('www.(baidu|oldboy).com', 'www.oldboy.com')
print(ret) # ['oldboy'] 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可
ret = re.findall('www.(?:baidu|oldboy).com', 'www.oldboy.com')
print(ret) # ['www.oldboy.com']
2.split的优先级查询
ret=re.split("\d+","eva3egon4yuan")
print(ret) #结果 : ['eva', 'egon', 'yuan']
ret=re.split("(\d+)","eva3egon4yuan")
print(ret) #结果 : ['eva', '3', 'egon', '4', 'yuan']
#在匹配部分加上()之后所切出的结果是不同的,
#没有()的没有保留所匹配的项,但是有()的却能够保留了匹配的项,
#这个在某些需要保留匹配部分的使用过程是非常重要的。
python与正则不得不说的故事的更多相关文章
- python re 正则
*:first-child { margin-top: 0 !important; } body>*:last-child { margin-bottom: 0 !important; } /* ...
- 与《YII框架》不得不说的故事—5篇目录
与<YII框架>不得不说的故事—基础篇 第1章 课程目标 1-1 课程目标 (00:54) 第2章 课前知识准备 2-1 YII的启动和安装 (05:12) 2-2 YII请求处理流程 ( ...
- python 速记正则使用(转)
目录 python 速记正则使用(转) 正则表达式语法 字符与字符类 量词 组与捕获 断言与标记 条件匹配 正则表达式的标志 Python正则表达式模块 四大功能 两种方法 常用方法 匹配对象的属性与 ...
- 【征文】Hadoop十周年特别策划——我与Hadoop不得不说的故事
2016年是Hadoop的十周年生日,在今年,CSDN将以技术和实战为主题与大家共同为Hadoop庆生.其主要内容包含Hadoop专业词典.系列视频技术解析.Hadoop行业实践.线上问答.线下沙龙. ...
- python的正则re模块
一. python的正则 python的正则模块re,是其内置模块,可以直接导入,即import re.python的正则和其他应用的正则及其相似,有其他基础的话,学起来还是比较简单的. 二. 正则前 ...
- python - 手机号正则匹配
Python 手机号正则匹配 # -*- coding:utf-8 -*- import re def is_phone(phone): phone_pat = re.compile('^(13\d| ...
- asList和ArrayList不得不说的故事
目录 简介 创建ArrayList UnsupportedOperationException asList 转换 总结 asList和ArrayList不得不说的故事 简介 提到集合类,ArrayL ...
- Python字符编码和二进制不得不说的故事
二进制 核心思想: 冯诺依曼 + 图灵机 电如何表示状态,才能稳定? 计算机开始设计的时候并不是考虑简单,而是考虑能自动完成任务与结果的可靠性, 简单始终是建立再稳定.可靠基础上 经过尝试10进制,但 ...
- Python(正则 Time datatime os sys random json pickle模块)
正则表达式: import re #导入模块名 p = re.compile(-]代表匹配0至9的任意一个数字, 所以这里的意思是对传进来的字符串进行匹配,如果这个字符串的开头第一个字符是数字,就代表 ...
随机推荐
- Linux-异步IO
1.何为异步IO (1).几乎可以这么认为:异步IO就是操作系统用软件实现的一套中断响应系统. (2).异步IO的工作方法:我们当前进程注册一个异步IO事件(使用signal注册一个信号SIGIO的处 ...
- 第37章 socket编程 之练习:实现简单的web服务器
一.参考网址 1.linux C学习之实现简单的web服务器 2.C语言实现简单Web服务器(一)
- delphpi tcp 服务和客户端 例子
//服务器端unit Unit1; interface uses Winapi.Windows, Winapi.Messages, System.SysUtils, System.Variants, ...
- ServletContext实现网站计数器
在网站开发中,有很多功能需要使用ServletContext,比如: 1.网站计数器 2.网站在线用户的显示 3.简单的聊天系统 总之,如果是涉及到不用用户共享数据,而这些数据量不大,同时又不希望写入 ...
- -bash: fultter: command not found
flutter build apk bash: flutter: command not found 在studio中的控制台出现上面错误(如图所示) 解决办法: 安装flutter时,安装时可以执行 ...
- CocoaPods-Alcatraz插件
Alcatraz:Xcode的插件管理工具,可通过它添加CocoaPods插件 下载地址:https://github.com/alcatraz/Alcatraz 建议: 不提倡通过终端命令下载Alc ...
- 创建Git仓库
创建Git仓库 一.什么是版本仓库 什么是版本库呢?版本库又名仓库,英文名repository,你可以简单理解成一个目录,这个目录里面的所有文件都可以被Git管理起来,每个文件的修改.删除,Git都能 ...
- Matlab高级教程_第二篇:Matlab相见恨晚的模块_02_并行运算-1
1 更高级的算法牵扯到更多重的循环和复杂的计算,尤其是现在人工智能的算法尤其如此.有些历史知识的人能够了解到,人工智能的很多基本算法其实近百年之前就有了,但是当时的计算机技术达不到去实现这些算法的要求 ...
- winEdt 使用
晚上摘抄的方法: 1.点选Options -> Options Interface 2.右边会跳出一个介面,点选Advance Configuration... -> Event Hand ...
- mysql引擎与物理文件
SELECT VERSION();show GLOBAL VARIABLES like '%PARTITION%';-- 查看分区情况 show GLOBAL VARIABLES like '%dat ...