YOLO V1、V2、V3算法 精要解说
前言
之前无论是传统目标检测,还是RCNN,亦或是SPP NET,Faste Rcnn,Faster Rcnn,都是二阶段目标检测方法,即分为“定位目标区域”与“检测目标”两步,而YOLO V1,V2,V3都是一阶段的目标检测。
从R-CNN到FasterR-CNN网络的发展中,都是基于proposal+分类的方式来进行目标检测的,检测精度比较高,但是检测速度不行,YOLO提供了一种更加直接的思路:
直接在输出层回归boundingbox的位置和boundingbox所属类别的置信度,相比于R-CNN体系的目标检测,YOLO将目标检测从分类问题转换为回归问题。其主要特点是:
•速度快,能够达到实时的要求,在TitanX的GPU上达到45fps;
•使用全图Context信息,背景错误(把背景当做物体)比较少;
•泛化能力强;

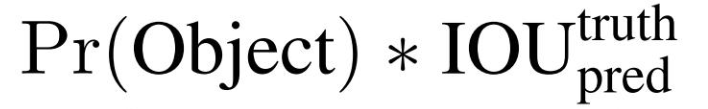
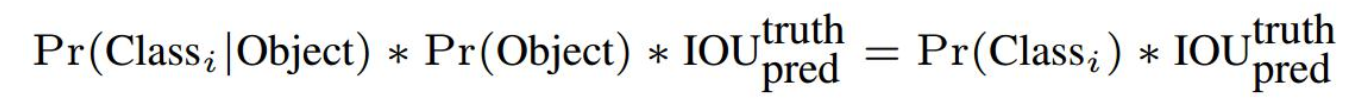
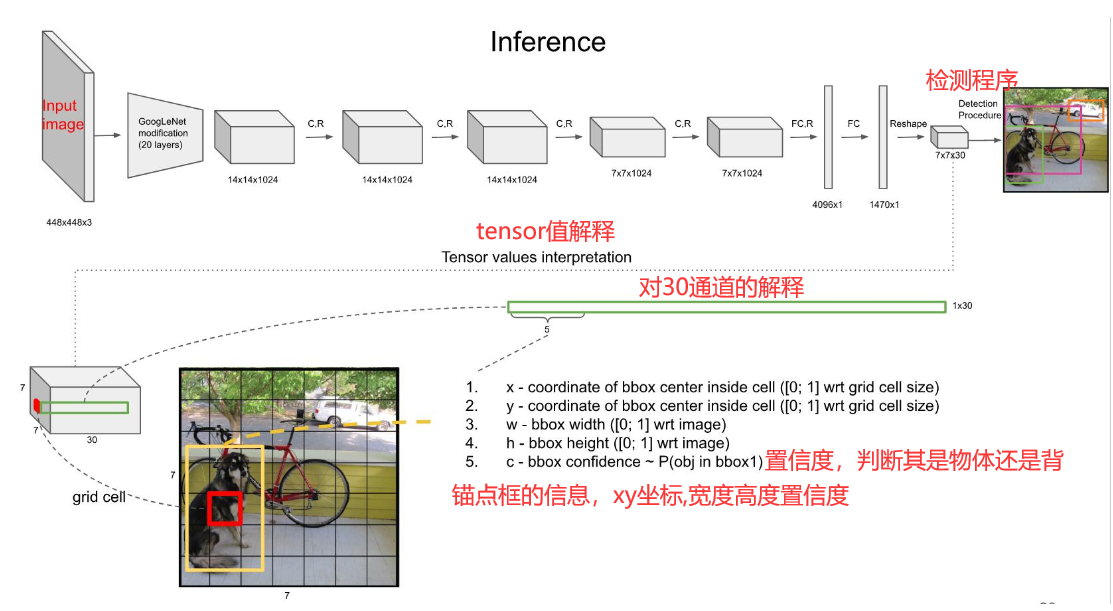
其想做的事如此看来很清晰,先判断是目标还是背景,若是目标,则再判断是属于这20个类别的哪个类(此VOC数据集是20个类别,别的数据集就是别的类别)
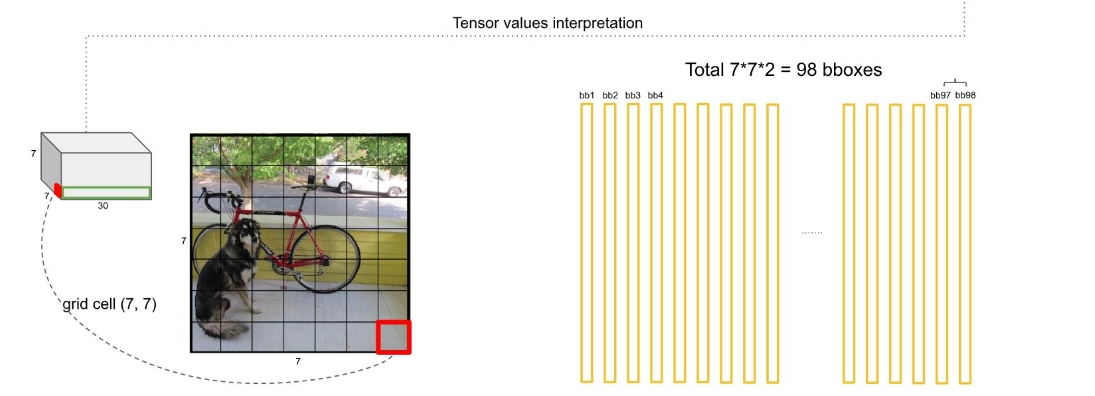
因为论文建议了我们一个grid cell最好是承载着两个边框,即bounding box,那么,这幅7*7个cell的图就有98个边框了,如下图
每个边框都是上面公式计算来的,我有写的,即背景还是物体的概率*20个类哪个类别的概率,如下图
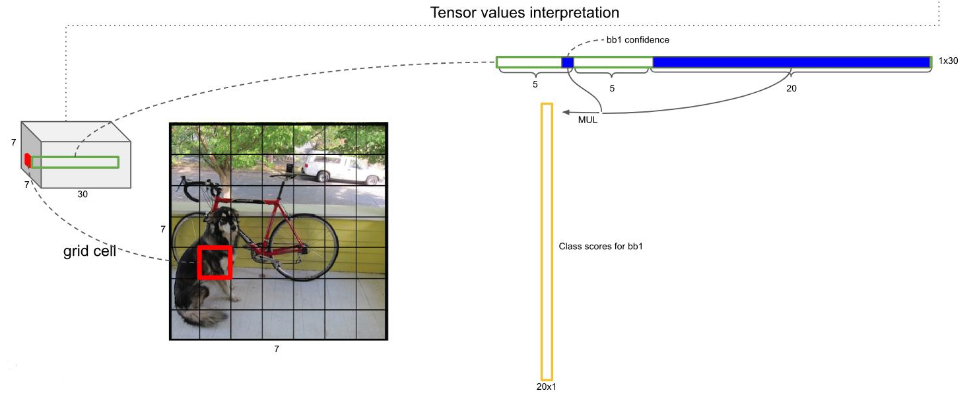
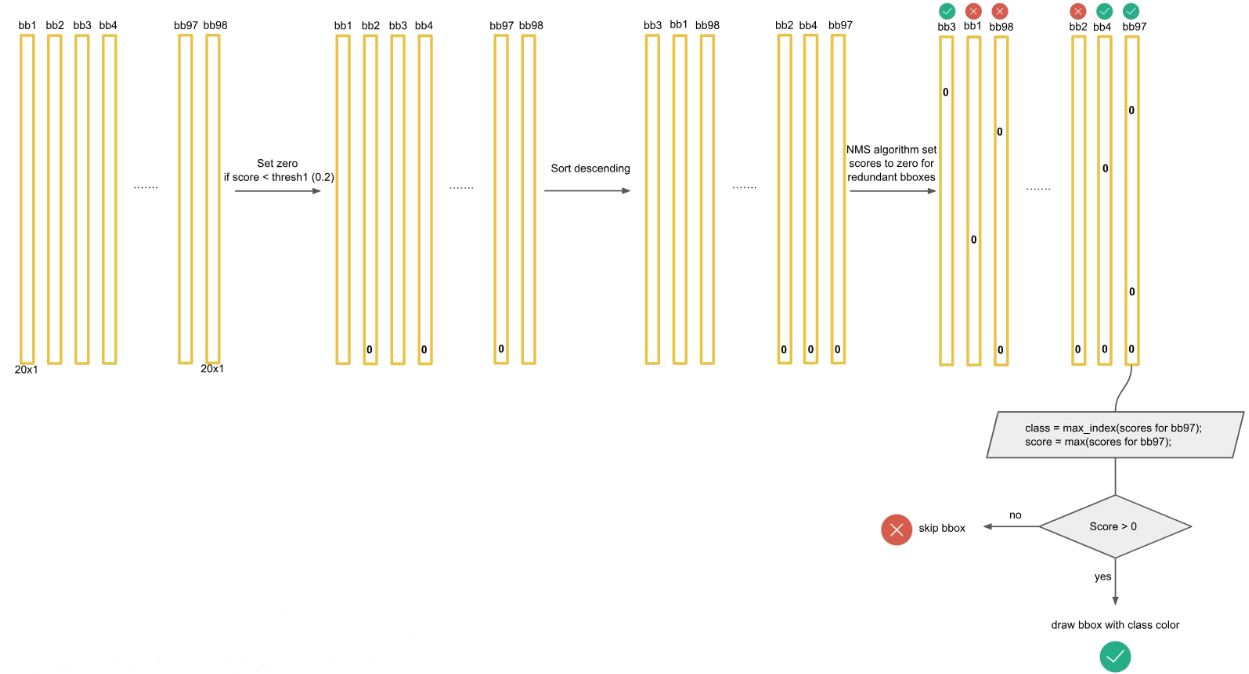
然后呢 ,就是处理这98个框框,如下图

这总共是20个类别,一行行的这么处理,直到20行处理完毕
然后对结果遍历,如果置信度的评分大于0,那这个框就可以代表此物体,如果得分小于0,就不行,如下图
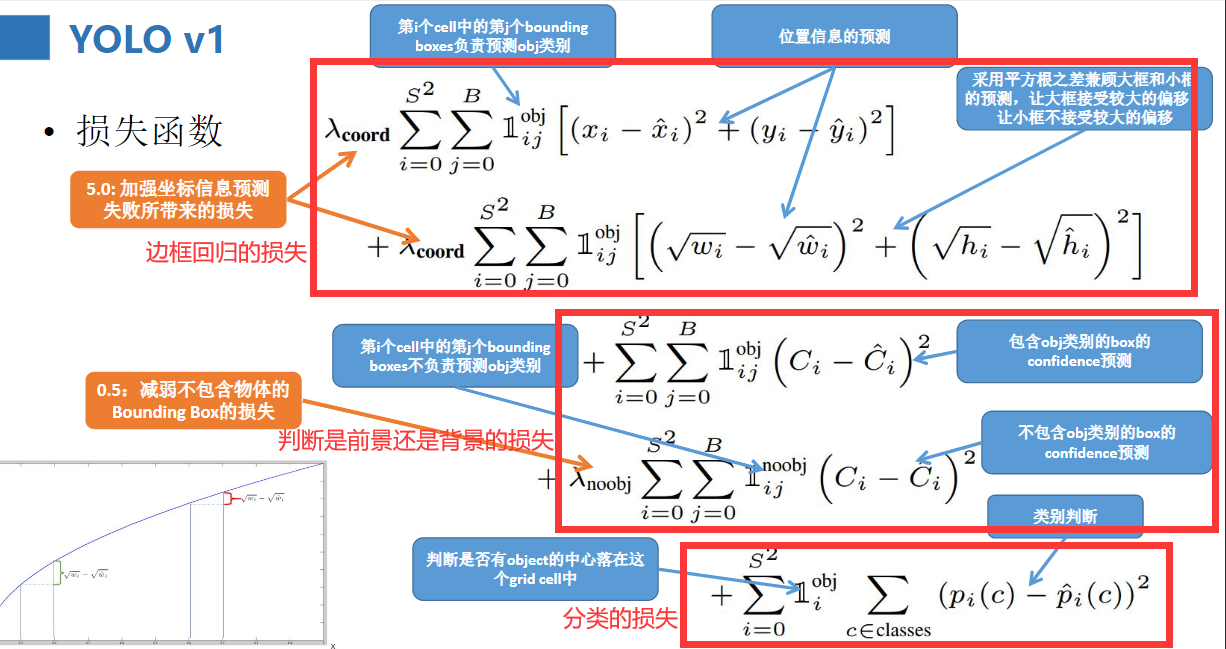
来看一下损失函数吧,我把它分成了三类
总结一下,并分析一下优缺点:


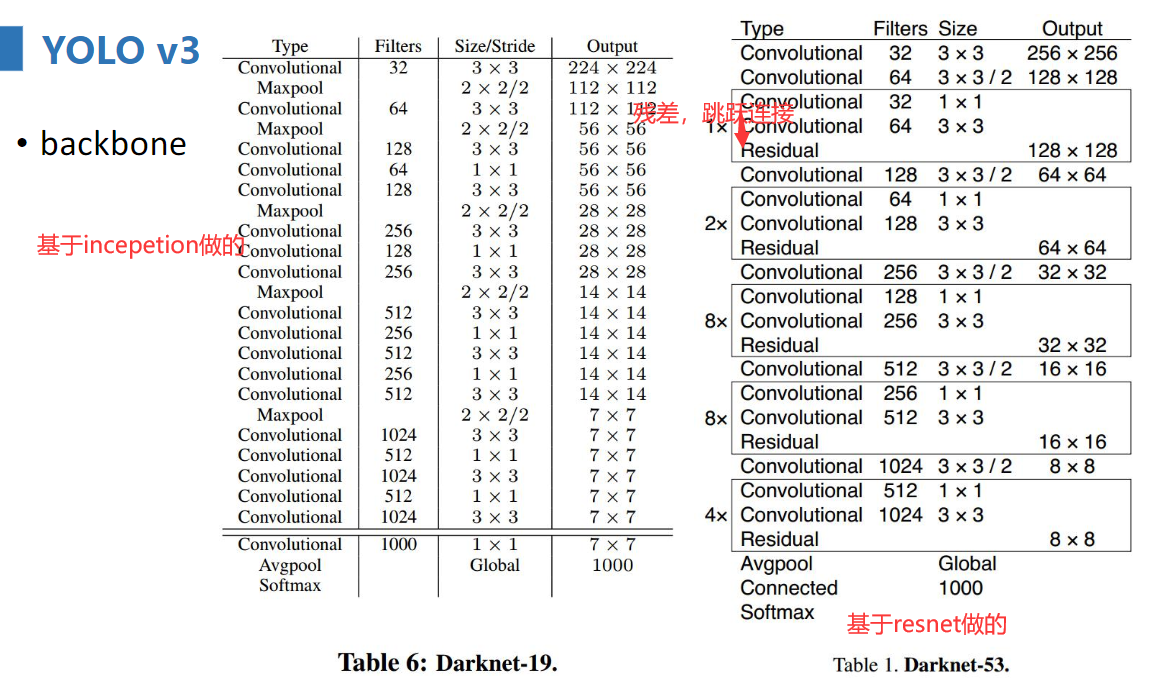
YOLO V2
算法的增强正是有了对原来的基础不断改进才得来的,YOLO V2相对于V1主要有三方面变化。
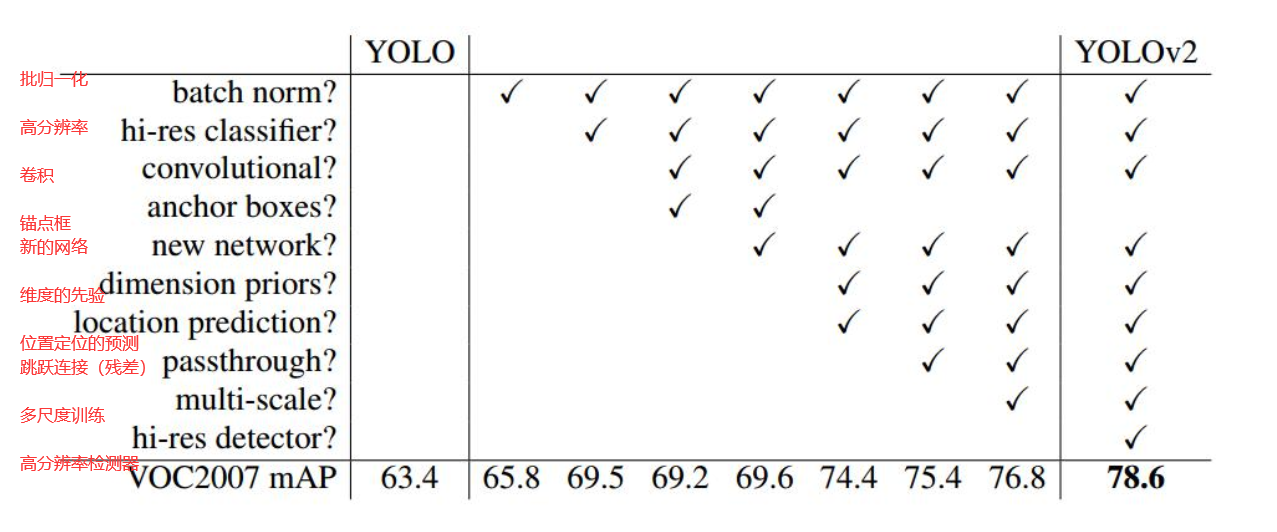
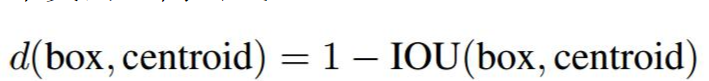
下图是聚类的不同标准下的平均IOU值
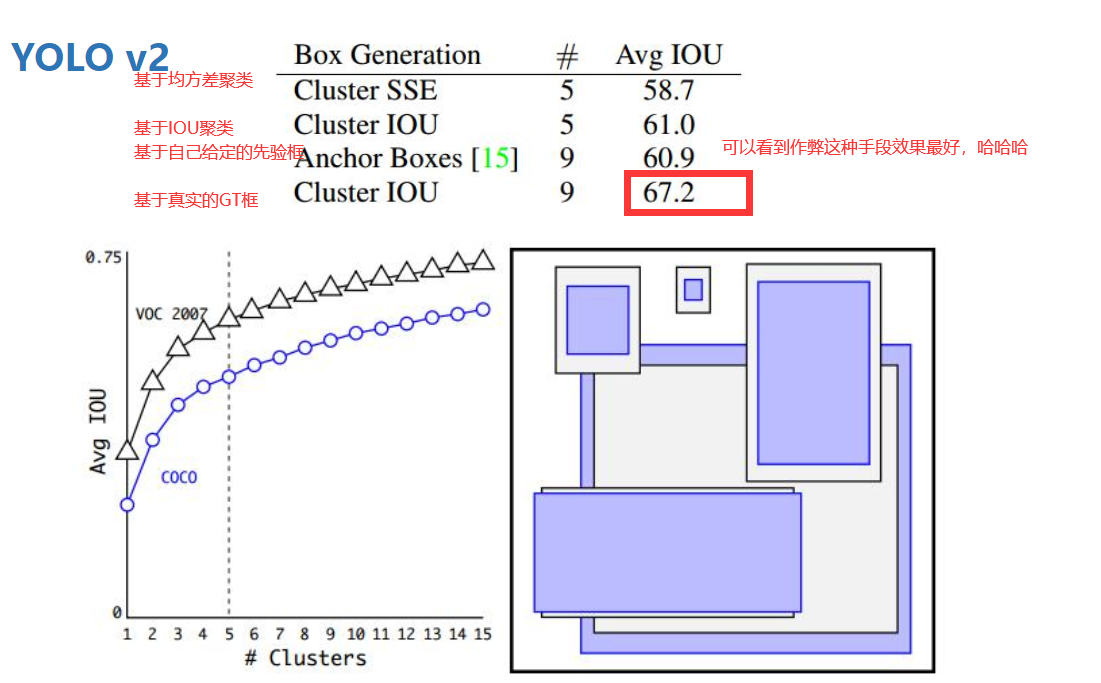
其沿用了Faster RCNN中Anchor box(锚点框)的思想,通过kmeans方法在VOC数据集(COCO数据集)上对检测物体的宽高进行了聚类分析,得出了5个聚类中心,因此选取5个anchor的宽高: (聚类时衡量指标distance = 1-IOU(bbox, cluster))
COCO: (0.57273, 0.677385), (1.87446, 2.06253), (3.33843, 5.47434), (7.88282, 3.52778), (9.77052, 9.16828)
VOC: (1.3221, 1.73145), (3.19275, 4.00944), (5.05587, 8.09892), (9.47112, 4.84053), (11.2364, 10.0071)
这样每个grid cell将对应5个不同宽高的anchor, 如下图所示:(上面给出的宽高是相对于grid cell,对应的实际宽高还需要乘以32(2的5次方),因为这里给出的原图大小是416*416大小的,经过卷积啊池化啊下采样了5次后变成了13*13大小的)

关于预测的bbox的计算:(416*416-------13*13 为例),卷积池化等经历了5次下采样,缩小了2的5次方倍(看下面这三段话的时候,记得看此行往上数第9到12行字,相信你会明白的)
(1) 输入图片尺寸为416*416, 最后输出结果为13*13*125,这里的125指5*(5 + 20),5表示5个anchor,25表示[x, y, w, h, confidence ] + 20 class ),即每一个anchor预测一组值。
(2) 对于每一anchor预测的25个值, x, y是相对于该grid cell左上角的偏移值,需要通过logistic函数将其处理到0-1之间。如13*13大小的grid,对于index为(6, 6)的cell,预测的x, y通过logistic计算为xoffset, yoffset, 则对应的实际x = 6 + xoffset, y = 6+yoffset, 由于0<xoffset<1, 0<yoffset<1, 预测的实际x, y总是在(6,6)的cell内。对于预测的w, h是相对于anchor的宽高,还需乘以anchor的(w, h), 就得到相应的宽高
(3) 由于上述尺度是在13*13下的,需要还原为实际的图片对应大小,还需乘以缩放倍数32



YOLO V1、V2、V3算法 精要解说的更多相关文章
- android google map v1 v2 v3 参考
V1,V2已经不被推荐使用,谷歌强烈推荐使用V3. 本人在选择时着实纠结了良久,现在总结如下: 对于V1,现在已经申请不到API KEY了,所以不要使用这个版本.这个是网址:https://devel ...
- 目标检测:YOLO(v1 to v3)——学习笔记
前段时间看了YOLO的论文,打算用YOLO模型做一个迁移学习,看看能不能用于项目中去.但在实践过程中感觉到对于YOLO的一些细节和技巧还是没有很好的理解,现学习其他人的博客总结(所有参考连接都附于最后 ...
- GoogLeNet 之 Inception v1 v2 v3 v4
论文地址 Inception V1 :Going Deeper with Convolutions Inception-v2 :Batch Normalization: Accelerating De ...
- 从Inception v1,v2,v3,v4,RexNeXt到Xception再到MobileNets,ShuffleNet,MobileNetV2
from:https://blog.csdn.net/qq_14845119/article/details/73648100 Inception v1的网络,主要提出了Inceptionmodule ...
- 51nod Bash游戏(V1,V2,V3,V4(斐波那契博弈))
Bash游戏V1 有一堆石子共同拥有N个. A B两个人轮流拿.A先拿.每次最少拿1颗.最多拿K颗.拿到最后1颗石子的人获胜.如果A B都很聪明,拿石子的过程中不会出现失误.给出N和K,问最后谁能赢得 ...
- 51Nod 最大M子段和系列 V1 V2 V3
前言 \(HE\)沾\(BJ\)的光成功滚回家里了...这堆最大子段和的题抠了半天,然而各位\(dalao\)们都已经去做概率了...先%为敬. 引流之主:老姚的博客 最大M子段和 V1 思路 最简单 ...
- 51Nod 最大公约数之和V1,V2,V3;最小公倍数之和V1,V2,V3
1040 最大公约数之和 给出一个n,求1-n这n个数,同n的最大公约数的和.比如:n = 6 1,2,3,4,5,6 同6的最大公约数分别为1,2,3,2,1,6,加在一起 = 15 输入 1个数N ...
- DNN:windows使用 YOLO V1,V2
本文有修改,如有疑问,请移步原文. 原文链接: YOLO v1之总结篇(linux+windows) 此外: YOLO-V2总结篇 Yolo9000的改进还是非常大的 由于原版的官方YOLOv ...
- Object Detection(RCNN, SPPNet, Fast RCNN, Faster RCNN, YOLO v1)
RCNN -> SPPNet -> Fast-RCNN -> Faster-RCNN -> FPN YOLO v1-v3 Reference RCNN: Rich featur ...
随机推荐
- Jquery 动态交换两个div位置并添加Css动画效果
前端网页开发中我们经常会遇到需要动态置换两个DIV元素的位置,常见的思路大多是不考虑原始位置,直接采用append或者appendTo方式将两元素进行添加,该法未考虑原始位置,仅会添加为元素的最后一子 ...
- Python 爬取 热词并进行分类数据分析-[数据修复]
日期:2020.02.01 博客期:140 星期六 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] 所有相关跳转: a.[简单准备] b.[云图制作+数据导入] c.[拓扑 ...
- K8S-OVS使用Openvswitch为提供SDN功能支持单租户模式和多租户模式
k8s-ovs ============================== 最近在寻求一些工作机会,如果有kubernetes相关研发招聘的朋友,欢迎随时联系我.我的个人简历可以通过百度网盘:htt ...
- npm安装包时报错:Error: EPERM: operation not permitted, rename
解决方法:先执行 npm cache clean -force在安装需要的包.
- Codeforces #617 (Div. 3) C. Yet Another Walking Robot
There is a robot on a coordinate plane. Initially, the robot is located at the point (0,0)(0,0) . It ...
- 【剑指Offer面试编程题】题目1360:乐透之猜数游戏--九度OJ
题目描述: 六一儿童节到了,YZ买了很多丰厚的礼品,准备奖励给JOBDU里辛劳的员工.为了增添一点趣味性,他还准备了一些不同类型的骰子,打算以掷骰子猜数字的方式发放奖品.例如,有的骰子有6个点数(点数 ...
- Laravel 6.X + Vue.js 2.X + Element UI +vue-router 配置
Laravel 版本:6.X Vue 版本:2.X Laravel配置: Laravel使用的是Laragon安装 选择Laravel:接下来弹出框,输入项目名,laravel会自动创建一个数据库,数 ...
- ImageSwitcher和GridView的案例开发
(一)ImageSwitcher之手机相册的滑动查看 首先在布局文件上加一个ImageSwitcher,设置它的宽度和高度为match_parent. 在主程序中:首先设置一个存储照片资源的数组,在设 ...
- 在linux命令行无界面下,使用selenium进行自动化测试
- C++ STL vector容量(capacity)和大小(size)的区别
很多初学者分不清楚 vector 容器的容量(capacity)和大小(size)之间的区别,甚至有人认为它们表达的是一个意思.本节将对 vector 容量和大小各自的含义做一个详细的介绍. vect ...