Flink 笔记(一)
简介
Flink是一个低延迟、高吞吐、统一的大数据计算引擎, Flink的计算平台可以实现毫秒级的延迟情况下,每秒钟处理上亿次的消息或者事件。
同时Flink提供了一个Exactly-once的一致性语义, 保证了数据的正确性。(对比其他: At most once, At least once)
这样就使得Flink大数据引擎可以提供金融级的数据处理能力(安全)。
Flink作为主攻流计算的大数据引擎,它区别于Storm,Spark Streaming以及其他流式计算引擎的是:
- 它不仅是一个高吞吐、低延迟的计算引擎,同时还提供很多高级的功能。
- 比如它提供了有状态的计算,支持状态管理,支持强一致性的数据语义以及支持Event Time,WaterMark对消息乱序的处理。
发展历程
- Flink诞生于欧洲的一个大数据研究项目StratoSphere。
- 该项目是柏林工业大学的一个研究性项目。
- 早期,Flink是做Batch计算的,但是在2014年,StratoSphere里面的核心成员孵化出Flink,同年将Flink捐赠Apache,并在后来成为Apache的顶级大数据项目。
- Flink计算的主流方向被定位为Streaming,即用流式计算来做所有大数据的计算,这就是Flink技术诞生的背景。
与其他计算引擎的对比
开源大数据计算引擎
- 流计算(Streaming)
- Storm
- Flink
- SparkStreaming等
- 批处理(batch)
- Spark
- MapReduce
- Pig(好像已凉)
- Flink等
- 同时支持流处理和批处理的:
- Apache Spark
- Apache Flink
- 从技术, 生态等各方面综合考虑
- Spark的技术理念是基于批来模拟流的计算
- Flink则完全相反,它采用的是基于流计算来模拟批计算
- 可将批数据看做是一个有边界的流
- Flink最区别于其他流计算引擎的点:
- stateful, 即有状态计算。
- Flink提供了内置的对状态的一致性的处理,即如果任务发生了Failover,其状态不会丢失、不会被多算少算,同时提供了非常高的性能。
- 什么是状态?
- 例如开发一套流计算的系统或者任务做数据处理,可能经常要对数据进行统计,如Sum,Count,Min,Max,这些值是需要存储的。
- 因为要不断更新,这些值或者变量就可以理解为一种状态。
- 如果数据源是在读取Kafka,RocketMQ,可能要记录读取到什么位置,并记录Offset,这些Offset变量都是要计算的状态。
- Flink提供了内置的状态管理,可以把这些状态存储在Flink内部,而不需要把它存储在外部系统。
- 这样做的好处:
- 降低了计算引擎对外部系统的依赖以及部署,使运维更加简单
- 对性能带来了极大的提升
- 如果通过外部去访问,如Redis,HBase它一定是通过网络及RPC。
- 如果通过Flink内部去访问,它只通过自身的进程去访问这些变量。
- 同时Flink会定期将这些状态做Checkpoint持久化,把Checkpoint存储到一个分布式的持久化系统中,比如HDFS。
- 这样的话,当Flink的任务出现任何故障时,它都会从最近的一次Checkpoint将整个流的状态进行恢复,然后继续运行它的流处理。
- 对用户没有任何数据上的影响。
- 这样做的好处:
- 流计算(Streaming)
性能对比
Flink是一行一行处理,而SparkStream是基于数据片集合(RDD)进行小批量处理,所以Spark在流式处理方面,不可避免增加一些延时。
Flink的流式计算跟Storm性能差不多,支持毫秒级计算,而Spark则只能支持秒级计算。
Spark vs Flink vs Storm:
- Spark:
- 以批处理为核心,用微批去模拟流式处理
- 支持SQL处理,流处理,批处理
- 对于流处理:因为是微批处理,所有实时性弱,吞吐量高,延迟度高
- Flink:
- 以流式处理为核心,用流处理去模拟批处理
- 支持流处理,SQL处理,批处理
- u 对于流处理:实时性强,吞吐量高,延迟度低。
- Storm:
- 一条一条处理数据,实时性强,吞吐量低,延迟度低。
- Spark:
Flink 与 Storm的吞吐量对比
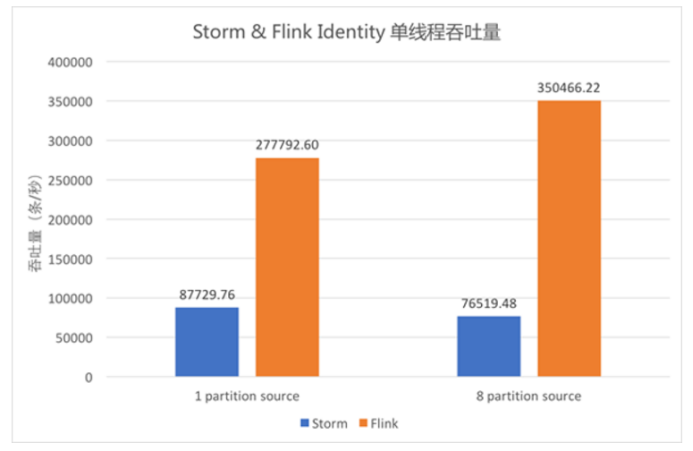
storm与flink延迟随着数据量增大而变化的对比
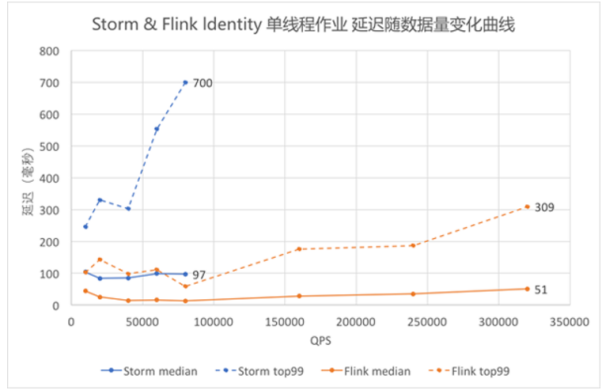
阿里使用Jstorm时遇到的问题:

后来他们将 JStorm 的作业迁移到 Flink集群上
Flink 是什么?
Apache Flink是一个分布式计算引擎,用于对无界和有界数据流进行状态计算
Flink可以在所有常见的集群环境中运行,并且能够对任何规模的数据进行计算。
这里的规模指的是既能批量处理(批计算)也能一条一条的处理(流计算)。
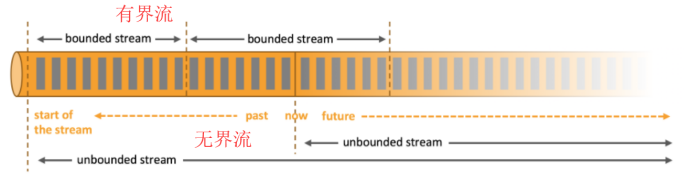
有界和无界数据:
Flink认为任何类型的数据都是作为事件流产生的。
比如:信用卡交易,传感器测量,机器日志或网站或移动应用程序,所有这
数据可以作为无界或有界流处理:
无界流:
- 它有开始时间但没有截止时间,它们在生成时提供数据,但不会被终止。
- 无界流必须连续处理数据,即必须在摄取事件后立即处理事件。
- 它无法等待所有输入数据到达,因为输入是无界的,如果是这样,在任何时间点都不会完成。
- 处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果完整性。
有界流:
- 具有起始时间和截止时间。
- 它可以在执行任何的计算之前,先通过摄取所有数据后再来处理有界流。
- 处理有界流不需要有序摄取,因为可以对有界数据集进行排序。
- 有界流的处理也称为批处理。
Flink 适用场景
事件驱动应用
欺诈识别
异常检测
基于规则的警报
业务流程监控
数据分析应用
电信网络的质量监控
分析移动应用程序中的产品更新和实验评估
对消费者技术中的实时数据进行特别分析
大规模图分析
数据管道 & ETL
- 电子商务中的实时搜索索引构建
- 电子商务中持续的 ETL
Flink 编程模型
Flink提供不同级别的抽象来开发流/批处理应用程序
抽象层次
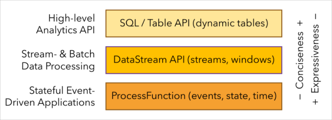
- 最低级抽象只是提供有状态流。它通过 Process Function 嵌入到 DataStream API 中
- 在实践中,大多数应用程序不需要上述低级抽象,而是针对DataStream API(有界/无界流)和DataSet API (有界数据集)
批处理: DataSet 案例
Scala 版:
package com.ronnie.batch object WordCount {
def main(args: Array[String]): Unit = {
// 引入隐式转换
import org.apache.flink.api.scala._
// 1. 初始化执行环境
val env = ExecutionEnvironment.getExecutionEnvironment
// 2. 读取数据源, -> dataset 集合, 类似spark的RDD
val data = env.readTextFile("/data/textfile")
// 3. 对数据进行转化 val result = data.flatMap(x=>x.split(" "))
.map((_,1))
.groupBy(0)
.sum(1)
// 4. 打印数据结果
result.print()
}
}
Java 版:
package com.shsxt.flink.batch; import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector; public class WordCount { public static void main(String[] args) throws Exception { //1:初始执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); //2:读取数据源
DataSet<String> text = env.readTextFile("data/textfile");
//3:对数据进行转化操作
DataSet<Tuple2<String, Integer>> wordCounts = text
.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> out) throws Exception {
for (String word : line.split(" ")) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
})
.groupBy(0)
.sum(1); //4:对数据进行输出
wordCounts.print();
} public static class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> out) {
for (String word : line.split(" ")) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
}
}
流处理: DataStream 案例
Scala 版:
package com.ronnie.streaming import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.streaming.api.windowing.time.Time object WordCount {
def main(args: Array[String]): Unit = {
//引入scala隐式转换..
import org.apache.flink.api.scala._
//1.初始化执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.获取数据源, 生成一个datastream
val text: DataStream[String] = env.socketTextStream("ronnie01", 9999)
//3.通过转换算子, 进行转换
val counts = text.flatMap{_.split(" ")}
.map{(_,1)}
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1) counts.print() env.execute()
}
}
Java 版:
package com.ronnie.flink.stream; import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector; public class WordCount {
public static void main(String[] args) throws Exception {
//1.初始化环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.读取数据源,并进行转换操作
DataStream<Tuple2<String, Integer>> dataStream = env
.socketTextStream("ronnie01", 9999)
.flatMap(new Splitter())
.keyBy(0)
//每5秒触发一批计算
.timeWindow(Time.seconds(5))
.sum(1);
//3.将结果进行输出
dataStream.print();
//4.流式计算需要手动触发执行操作,
env.execute("Window WordCount");
} public static class Splitter implements FlatMapFunction<String, Tuple2<String, Integer>> { public void flatMap(String sentence, Collector<Tuple2<String, Integer>> out) throws Exception {
for (String word: sentence.split(" ")) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
}
}
程序和数据流
Flink程序的基本构建是在流和转换操作上的, 执行时, Flink程序映射到流数据上,由流和转换运算符组成。
每个数据流都以一个或多个源开头,并以一个或多个接收器结束。
数据流类似于任意有向无环图 (DAG)

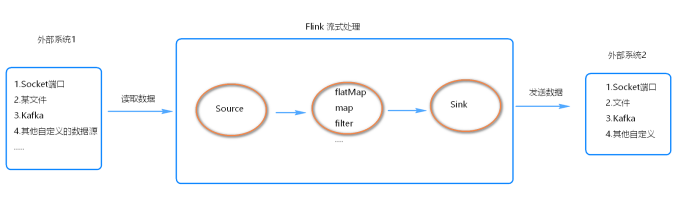
代码流程
- 创建ExecutionEnvironment/StreamExecutionEnvironment 执行环境对象
- 通过执行环境对象创建出source(源头)对象
- 基于source对象做各种转换,注意:在flink中转换算子也是懒执行的
- 定义结果输出到哪里(控制台,kafka,数据库等)
- 最后调用StreamExecutionEnvironment/ExecutionEnvironment 的excute方法,触发执行。
- 每个flink程序由source operator + transformation operator + sink operator组成
Flink中的Key
- 注意点:
- Flink处理数据不是K,V格式编程模型,没有xxByKey 算子,它是虚拟的key。
- Flink中Java Api编程中的Tuple需要使用Flink中的Tuple,最多支持25个
- 批处理用groupBY 算子,流式处理用keyBy算子
- Apache Flink 指定虚拟key
- 使用Tuples来指定key
- 使用Field Expression来指定key
- 使用Key Selector Functions来指定key
- 注意点:
Flink 笔记(一)的更多相关文章
- 01.Flink笔记-编译、部署
Flink开发环境部署配置 Flink是一个以Java及Scala作为开发语言的开源大数据项目,代码开源在github上,并使用maven来编译和构建项目.所需工具:Java.maven.Git. 本 ...
- flink笔记(三) flink架构及运行方式
架构图 Job Managers, Task Managers, Clients JobManager(Master) 用于协调分布式执行.它们用来调度task,协调检查点,协调失败时恢复等. Fli ...
- Flink笔记(二) DataStream Operator(数据流操作)
DataStream Source 基于文件 readTextFile(path) 读取 text 文件的数据 readFile(fileInputFormat, path) 通过自定义的读取方式, ...
- 02.Flink的单机wordcount、集群安装
一.单机安装 1.准备安装包 将源码编译出的安装包拷贝出来(编译请参照上一篇01.Flink笔记-编译.部署)或者在Flink官网下载bin包 2.配置 前置:jdk1.8+ 修改配置文件flink- ...
- Apache Flink学习笔记
Apache Flink学习笔记 简介 大数据的计算引擎分为4代 第一代:Hadoop承载的MapReduce.它将计算分为两个阶段,分别为Map和Reduce.对于上层应用来说,就要想办法去拆分算法 ...
- Flink学习笔记-新一代Flink计算引擎
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- Flink学习笔记:Flink Runtime
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Flink学习笔记:Flink开发环境搭建
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Flink学习笔记:Flink API 通用基本概念
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
随机推荐
- python之对象基础
目录 面向对象 1. 面向过程编程的优缺点 2. 面向对象编程的优缺点 3. 类 类和函数的区别 什么是类 现实世界中先有对象,后有类 python中先有类,再有对象 对象 如何实例化一个对象 对象属 ...
- 第1节 storm日志告警:1、 - 5、日志监控告警业务需求、代码、集群运行、总结
如何解决短信或者邮件频繁发送的问题:每次发送的时候都先查询数据库记录,看一下有没有给这个人发送消息,上一次发送消息的时间是什么时候,如果发送时间间隔小于半个小时,就不要再发了 ============ ...
- 华为轮值CEO,富士康却坚持独裁,二者究竟有什么不一样?
谈到深圳龙华的大企业,人们会很自然地想到华为和富士康,两家公司毗邻,有两个门仅仅隔着一条马路,都是世界500强,对国家,对社区的经济发展有着重要贡献,员工压力最大的时候,也都出现过自杀的情况,一个讲究 ...
- u盘装完centos系统恢复
1.使用windows的cmd窗口,执行diskpart命令 2.执行 list disk命令,查看u盘 3.执行 select disk 2,选中u盘,注意,这里的2是我自己的显示,千万不要选错 4 ...
- 082、Java数组之数组传递之简化理解
01.代码如下: package TIANPAN; /** * 此处为文档注释 * * @author 田攀 微信382477247 */ public class TestDemo { public ...
- nodejs(12)Express 中间件middleware
中间件 客户端的请求到达服务器时,他的生命周期是:request -- 服务器端处理 -- 响应 在服务器端处理过程中,业务逻辑复杂时,为了便于开发维护,需要把处理的事情分成几步,这里每一步就是一个中 ...
- ubuntu 怎么更新?ubuntu更新命令及方法
ubuntu 怎么更新?ubuntu更新命令及方法 安装Ubuntu系统后,第一件事就是更新系统源.由于系统安装的默认源地址在英国,作为Ubuntu的主源,国内连接速度非常慢,所以我们要将它换成就近的 ...
- ROS-5 : 自定义消息
自定义消息一般存储在功能包的msg文件夹下的.msg文件中,这些定义可告诉ROS这些数据的类型和名称,以便于在ROS 节点中使用.添加完这些自定义消息后,ROS会将其转为等效的C++节点,从而可在其他 ...
- C语言常用函数
一.数学函数 调用数学函数时,要求在源文件中包下以下命令行: #include <math.h> 函数原型说明 功能 返回值 说明 int abs( int x) 求整数x的绝对值 计算结 ...
- GNS3 模拟免费ARP
R2 : conf t int f0/0 no shutdown ip add 192.168.1.254 255.255.255.0 end R1 : conf t int f0/0 no shut ...