学好Spark/Kafka必须要掌握的Scala技术点(一)变量、表达式、循环、Option、方法和函数,数组、映射、元组、集合
前言
Scala是以JVM为运行环境的面向对象的函数式编程语言,它可以直接访问Java类库并且与Java框架进行交互操作。正如之前所介绍,Spark是用Scala语言编写的,Kafka server端也是,那么深入学习Scala对掌握Spark、Kafka是必备掌握技能。
本篇文章主要介绍,在学习、编写Spark程序时,至少要掌握的Scala语法,多以示例说明。建议在用Scala编写相关功能实现时,边学习、边应用、边摸索以加深对Scala的理解和应用。
1. 变量、表达式、循环、Option、方法和函数
1.1 声明变量
def main(args: Array[String]): Unit = {
//使用val定义的变量值是不可变的,相当于java里用final修饰的变量
val i = 1
//使用var定义的变量是可变的,在Scala中鼓励使用val
var s = "hello"
//Scala编译器会自动推断变量的类型,必要的时候可以指定类型
//变量名在前,类型在后
val str: String = "hello"
}
1.2 表达式
1.2.1 条件表达式
def main(args: Array[String]): Unit = {
val x = 1
// 判断x是否大于0,将最终结果赋给y,打印y
// 二者等效, Scala语言强调代码简洁
// var y = if(x > 0) {x} else {-1}
// val y = if(x > 0) x else -1
// 支持混合类型表达式,返回值类型是Any
// var y = if(x > 0) x else "no"
// 如果缺失else,相当于if (x > 0) 1 else ()
// scala表达式中有一个Unit类,写作(),相当于java中void
// val y = if(x > 0) 1
// if和else if
val f = if (x < 0) 0 else if (x >= 1) 1 else -1
println(y)
}
1.2.2 块表达式
def main(args: Array[String]): Unit = {
val x = 0
// scala中{}可包含一系列表达式,块中运行最终结果为块的值
val result = {
if(x < 0) -1 else if(x >= 1) 1 else "error"
}
println(result)
}
1.3 循环
Scala里面while循环和Java中的while循环使用方式类似,这里主要以for循环为例:
def main(args: Array[String]): Unit = {
// 表达式1 to 10返回一个Range区间,每次循环将区间中的一个值赋给i
for (i <- 1 to 3) {
println(i)
}
//i代表数组中的每个元素
val arr = Array("a", 1, "c")
for (i <- arr) {
println(i)
}
//高级for循环
//每个生成器都可以带一个条件,注意:if前面没有分号
//相当于双层for循环,i每获得一个值对1to3进行全部遍历并赋值给j然后进行条件判断
for (i <- 1 to 3; j <- 1 to 3 if (i != j)) {
println(i + j)
}
//for推导式:如果for的循环体以yield开头,则该循环会构建一个集合
// 每次迭代生成集合中的一个元素 集合类型为Vector
var v = for (i <- 1 to 3) yield i * i
println(v)
//遍历一个数组,to:包头包尾;until:包头不包尾
for (i <- arr.length - 1) {
println(arr(i))
}
for(i <- 0 until arr.length) {
println(arr(i))
}
}
1.4 Option类型
在Scala中Option类型样例类用来表示可能存在或也可能不存在的值(Option的子类有Some和None)。Some包装了某个值,None表示没有值:
def main(args: Array[String]): Unit = {
val map = Map("a"->1,"b"->2)
//根据key获取value匹配match中的逻辑有值返回Some类型(已封装数据),无值返回None
val v = map.get("b") match {
case Some(i) => i
case None => 0
}
println(v)
//更好的方式
val value = map.getOrElse("c",0)
println(value)
}
1.5 方法和函数
Scala中的+、-、*、/、%等操作符的作用与Java一样,位操作符&、|、^、>>、<<也一样。但在Scala中:这些操作符实际上是方法。例如:a + b是a.+(b)方法调用的简写:a 方法 b可以写成 a.方法(b)。
方法的返回值类型可以不写,编译器可以自动推断出来,但是对于递归函数,必须指定返回类型。
def str = "a" 成立,定义一个字符串
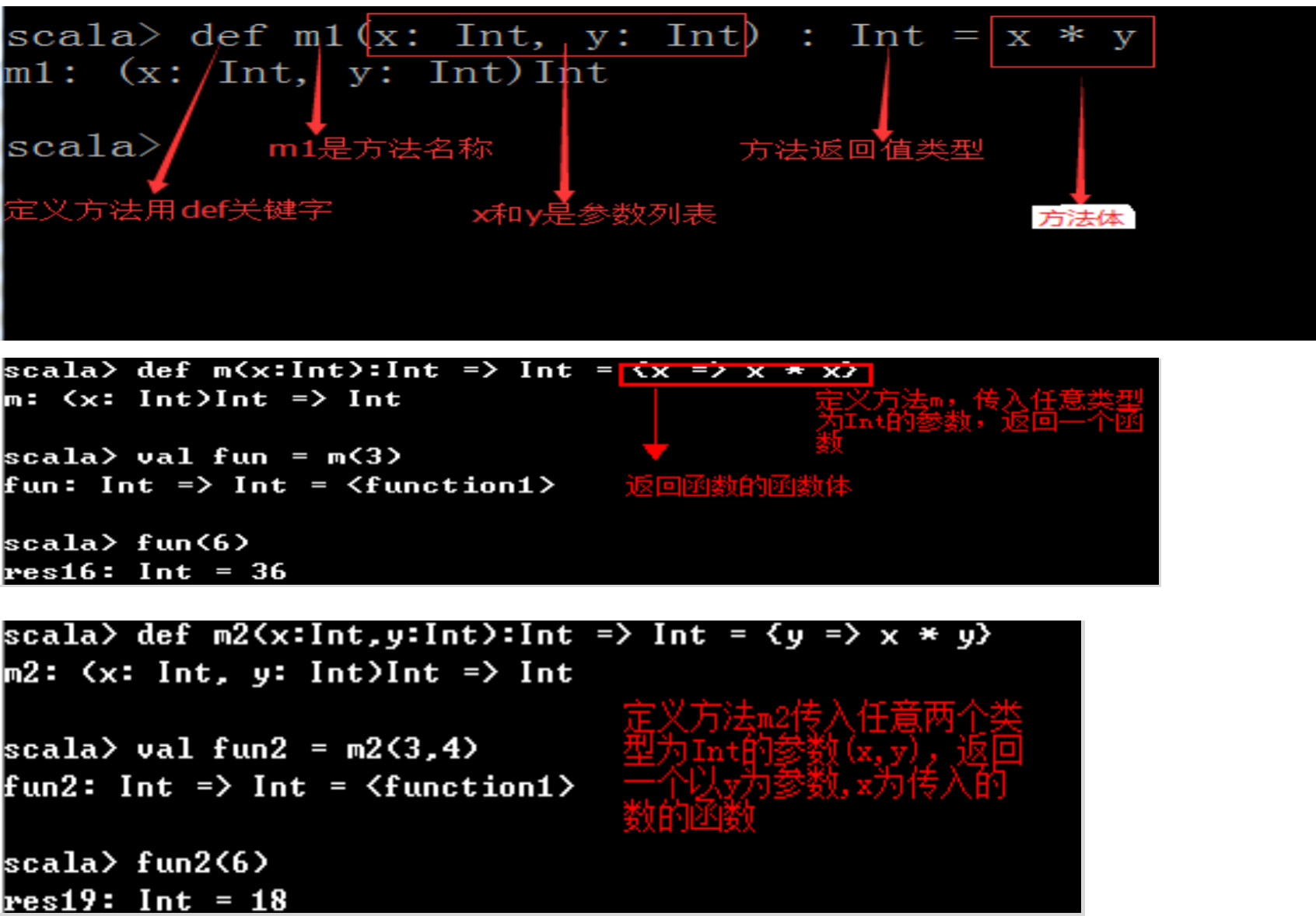
在函数式编程语言中,函数可以像任何其他数据类型一样被传递和操作:

偏函数:
//偏函数,它是PartialFunction[-A,+B]的一个实例,A代表参数类型,B代表返回值类型,常用作模式匹配(后文阐述)。
def func1: PartialFunction[String, Int] = {
case "one" => 1
case "two" => 2
case _ => -1
}
def func2(num: String): Int = num match {
case "one" => 1
case "two" => 2
case _ => -1
}
def main(args: Array[String]) {
println(func1("one"))
println(func2("three"))
}
2. 数组、映射、元组、集合
2.1 数组
import scala.collection.mutable.ArrayBuffer
//scala导包比如导入scala.collection.mutable下所有的类:scala.collection.mutable._
object ArrayDemo {
def main(args: Array[String]): Unit = {
println("======定长数组======")
// 初始化一个长度为8的定长数组,所有元素初始化值为0
var arr1 = new Array[Int](8)
// 底层调用的apply方法
var arr2 = Array[Int](8) //toBuffer会将数组转换成数组缓冲
println(arr1.toBuffer) // ArrayBuffer(0, 0, 0, 0, 0, 0, 0, 0)
println(arr1(2)) // 使用()来访问元素 println("=======变长数组(数组缓冲)======")
val varr = ArrayBuffer[Int]()
//向数组缓冲尾部追加一个或多个元素(+=)
varr += 1
varr += (2, 3) //追加一个数组用 ++=
varr ++= Array(4, 5)
varr ++= ArrayBuffer(6, 7) //指定位置插入元素-1和3;参数1:指定位置索引,参数2:插入的元素可以是多个
// def insert(n: Int, elems: A*) { insertAll(n, elems) }
varr.insert(0,-1,3) varr.remove(0) //删除指定索引处的元素
//从指定索引处开始删除,删除多个元素;参1:指定索引,参2:删除个数
varr.remove(0,2) // 从0索引开始删除n个元素
// varr.trimStart(2) //从最后一个元素开始删除,删除指定个数的元素(length-n max 0)
varr.trimEnd(2)
) //reduce ==>非并行化集合调用reduceLeft
//(((1+8)+3)+5)...
println(varr.reduce((x,y)=> x+y))
println(varr.reduce(_+_))
println(varr.reduce(_-_)) Array("one","two","three").max //two,字符串比较大小,按照字母表顺序
Array("one","two","three").mkString("-")//以"-"作为数组中元素间的分隔符one-two-three
Array("one","two","three").mkString("1","-","2")//1one-two-three2 //参1:arr元素的数组个数,参2:arr中每个数组中元素个数
val arr = Array.ofDim[Int](2, 3)
arr.head arr.last //数组的第一个和最后一个元素
}
}
yield关键字将原始的数组进行转换会产生一个新的数组,原始的数组不变
def main(args: Array[String]) {
//定义一个数组
val arr = Array(1, 2, 3, 4, 5, 6, 7, 8, 9)
//将偶数取出乘以10后再生成一个新的数组
val res = for (e <- arr if e % 2 == 0) yield e * 10
println(res.toBuffer)
//filter过滤接收一个返回值为boolean的函数,过滤掉返回值为false的元素
//map将数组中的每一个元素取出来(_)进行相应操作
val r = arr.filter(_ % 2 == 0).map(_ * 10)
println(r.toBuffer)
//数组元素求和,最大值,排序
println(arr.sum+":"+arr.max+":"+arr.sorted.toBuffer)
}
2.2 映射
在Scala中,把哈希表这种数据结构叫做映射,类似于Java中的Map。
在Scala中,有两种Map:
不可变Map:scala.collection.immutable.Map(可以存储一些配置或参数供多个线程访问,保证线程安全,具体还要结合业务实际场景),内容不更改
可变Map:scala.collection.mutable.Map==>类似于Java中的HashMap,可以进行put、get、remove等操作,内容可变
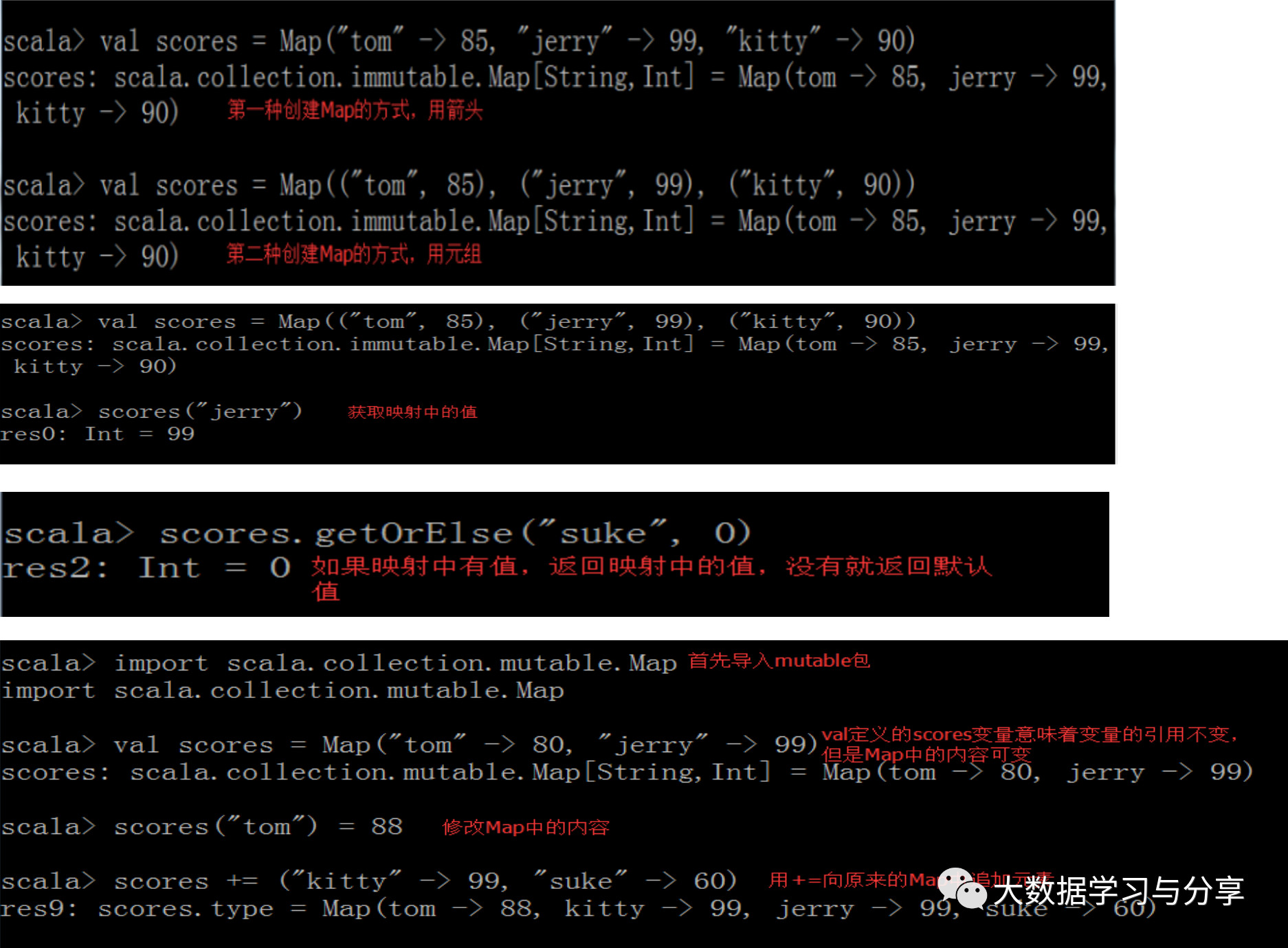
map += ("c" -> 3) map += (("d",4)) 增加元素 -=移除元素 +/-增加或移除一个元素并返回一个新的集合
注意:通常我们在创建一个集合时会用val这个关键字修饰一个变量,那么就意味着该变量的引用不可变,该引用中的内容是不是可变还取决于这个引用指向的集合的类型
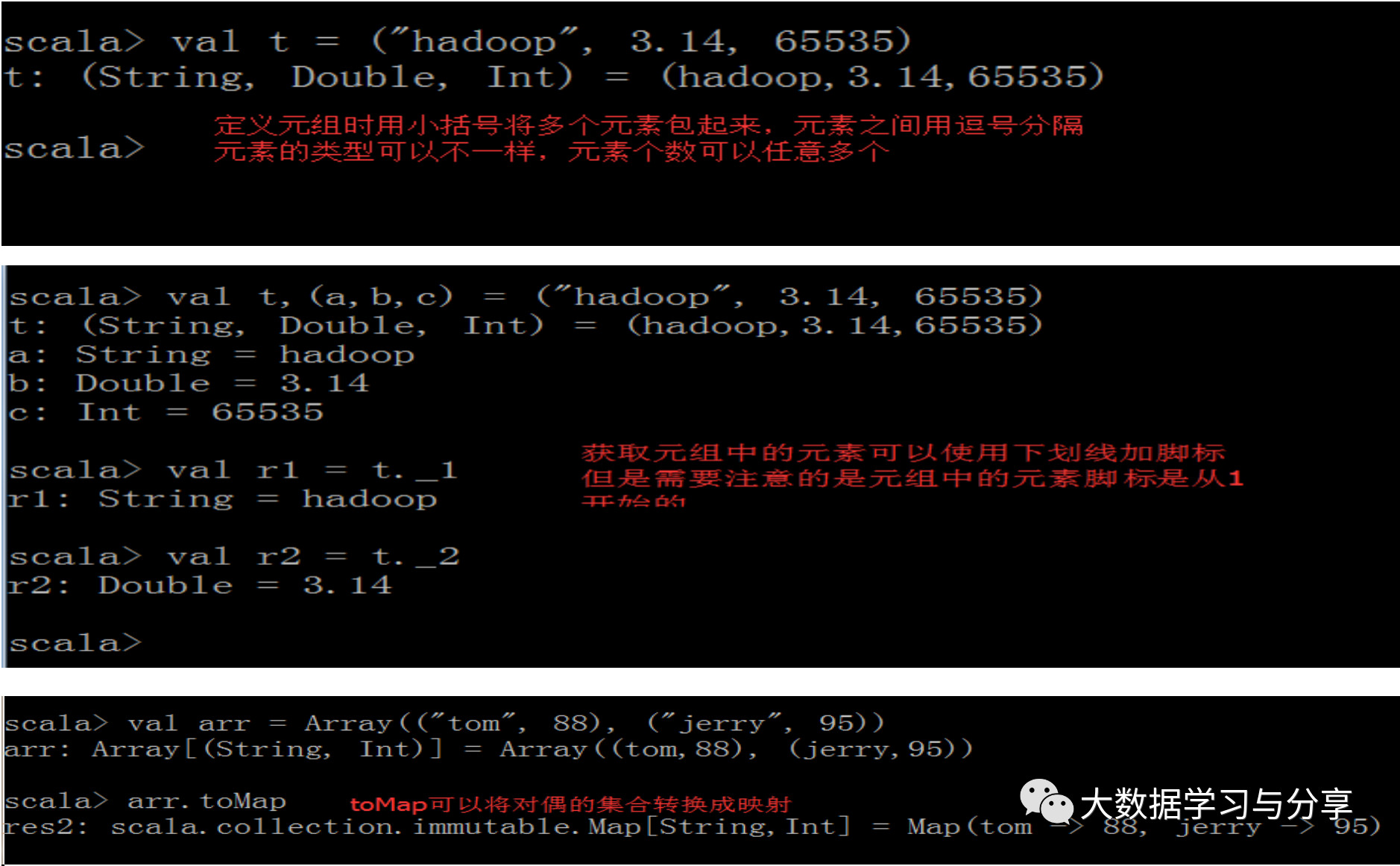
2.3 元组
映射是K/V对偶的集合,对偶是元组的最简单形式,元组可以装着多个不同类型的值,元组是不可变的
zip命令可以将多个值绑定在一起(将两个数组/集合的元素一一对偶):
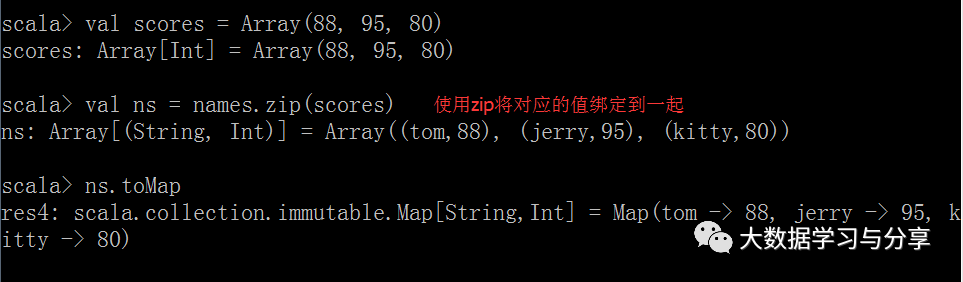
注意:如果两个数组的元素个数不一致,拉链操作后生成的数组的长度为较小的那个数组的元素个数
对于元组val t = (1, 3.14, "Fred"),val (first, second, _) = t // second等于3.14
2.4 集合
Scala的集合有三大类:序列Seq、集Set、映射Map,所有的集合都扩展自Iterable特质。集合分可变(mutable)和不可变(immutable)两种类型,immutable类型的集合初始化后长度和内容都不能改变(注意与val修饰的变量进行区别)
2.4.1 Seq/List
在Scala中列表要么为空(Nil表示空列表)要么是一个head元素加上一个tail列表。
9 :: List(5, 2) :: 操作符是将给定的头和尾创建一个新的列表【注意::: 操作符是右结合的,如9 :: 5 :: 2 :: Nil相当于 9 :: (5 :: (2 :: Nil))】
def main(args: Array[String]): Unit = {
//创建一个不可变集合
val lt = List(1, 2, 3)
/*//添加元素到lt前面生成一个新的List
val lt2 = ("a", -1, 0) :: lt
val lt3 = lt.::(0)
val lt4 = 0 +: lt
val lt5 = lt.+:(0)
println(lt + "==>" + lt2 + "==" + lt3 + "==" + lt4 + "==" + lt5)
val lt6 = lt :+ 4
println("添加元素到后面:"+lt6 )*/
//合并两个集合,lt0在lt前面
val lt0 = List(4,5,6,7)
val lt7 = lt0.union(lt)
val lt8 = lt0 ++ lt
println(lt7 +":"+lt8 )
println("lt0在lt后面"+lt ++ lt0)
//将两个集合中的元素一一绑定,如果元素数不一致以较少元素集合为准
println(lt0.zip(lt).toMap)
//将lt0插入到lt前面生成一个新的集合
println(lt0 ++: lt)
println(lt.:::(lt0))
}
def main(args: Array[String]): Unit = {
// 构建一个可变列表,初始有3个元素1,2,3 alt+enter导包
val lst0 = ListBuffer[Int](1,2,3)
//创建一个空的可变列表
val lst1 = new ListBuffer[Int]
//向lst1中追加元素,注意:没有生成新的集合
lst1 += 4
lst1.append(5)
println(lst1)
//将lst1中的元素最近到lst0中, 注意:没有生成新的集合
println(lst0 ++= lst1)
//将lst0和lst1合并成一个新的ListBuffer 注意:生成了一个集合
println(lst0 ++ lst1)
//将元素追加到lst0的后面生成一个新的ListBuffer
val lst3 = lst0 :+ 5
println(lst3)
}
def main(args: Array[String]): Unit = {
// 构建一个可变列表,初始有3个元素1,2,3 alt+enter导包
val lst0 = ListBuffer[Int](1,2,3)
//创建一个空的可变列表
val lst1 = new ListBuffer[Int]
//向lst1中追加元素,注意:没有生成新的集合
lst1 += 4
lst1.append(5)
println(lst1)
//将lst1中的元素最近到lst0中, 注意:没有生成新的集合
println(lst0 ++= lst1)
//将lst0和lst1合并成一个新的ListBuffer 注意:生成了一个集合
println(lst0 ++ lst1)
//将元素追加到lst0的后面生成一个新的ListBuffer
val lst3 = lst0 :+ 5
println(lst3)
}
def main(args: Array[String]): Unit = {
/* //创建一个List
val lst0 = List(1,7,9,8,0,3,5,4,6,2)
//将lst0中每个元素乘以10后生成一个新的集合
val lst1 = lst0.map(_*10)
val lst2 = for(i <- lst0) yield i * 10
println(lst1 + ":" +lst2)
//将lst0中的偶数取出来生成一个新的集合
val lst3 = lst0.filter(_ % 2 == 0)
val lst4 = for(i <- lst0 if(i % 2 == 0)) yield i
println(lst3 + ":" +lst4)
//将lst0排序后生成一个新的集合
val lst5 = lst0.sorted//升序
val lst6 = lst0.sortWith(_>_)//降序
val lst7 = lst0.sortBy(x => x)//升序
println(lst5 + ":" +lst6 + ":" +lst7)
//反转顺序
println(lst5.reverse)
//将lst0中的元素4个一组,类型为Iterator[List[Int]]
val it = lst0.grouped(4)
// println(it.toBuffer)
//将Iterator转换成List
val lst8 = it.toList
//将多个list压扁成一个List
println(lst8.flatten)
//先按空格切分,再压平
val lines = List("hello tom hello jerry", "hello jerry", "hello kitty")
lines.map(_.split(" ")).flatten
lines.flatMap(_.split(" "))//
//并行计算求和
println(lst0.par.sum)
println(lst0.par.reduce(_+_))//非指定顺序
println(lst0.par.reduceLeft(_+_))//指定顺序
//折叠:有初始值(无特定顺序)
val lst11 = lst0.fold(100)((x, y) => x + y)
//折叠:有初始值(有特定顺序)
val lst12 = lst0.foldLeft(100)((x, y) => x + y) */
//聚合
val arr = List(List(1, 2, 3), List(3, 4, 5), List(2), List(0))
// println(arr.flatten.sum)
/*先局部求和,再汇总
_+_.sum:第一个下划线是初始值和后面list.sum和,_.sum是list的和,非并行化时只初始化1次只携带1次
_+_:初始值和list元素和的和 */
val result = arr.aggregate(10)(_+_.sum,_+_)
val res = arr.aggregate(10)((x,y)=>x+y.sum,(a,b)=>a+b)
println(result+":"+res)
val l1 = List(5,6,4,7)
val l2 = List(1,2,3,4)
//求并集
val r1 = l1.union(l2)
//求交集
val r2 = l1.intersect(l2)
//求差集
val r3 = l1.diff(l2)
println(r3)
}
2.4.2 Set
def main(args: Array[String]): Unit = {
//不可变Set
/* val set1 = new HashSet[Int]()
//将元素和set1合并生成一个新的set,原有set不变
val set2 = set1 + 4
//set中元素不能重复
val set3 = set1 ++ Set(5, 6, 7)
val set0 = Set(1,3,5) ++ set3
println(set0)*/
//创建一个可变的HashSet
val set1 = new mutable.HashSet[Int]()
//向HashSet中添加元素
set1 += 2
//add等价于+=
set1.add(4)
set1 ++= Set(1,3,5)
println(set1)
//删除一个元素
set1 -= 5
set1.remove(2)
println(set1)
}
推荐文章:
学好Spark/Kafka必须要掌握的Scala技术点(一)变量、表达式、循环、Option、方法和函数,数组、映射、元组、集合的更多相关文章
- 学好Spark/Kafka必须要掌握的Scala技术点(三)高阶函数、方法、柯里化、隐式转换
5. 高阶函数 Scala中的高阶函数包含:作为值的函数.匿名函数.闭包.柯里化等,可以把函数作为参数传递给方法或函数. 5.1 作为值的函数 定义函数时格式: val 变量名 = (输入参数类型和个 ...
- 学好Spark/Kafka必须要掌握的Scala技术点(二)类、单例/伴生对象、继承和trait,模式匹配、样例类(case class)
3. 类.对象.继承和trait 3.1 类 3.1.1 类的定义 Scala中,可以在类中定义类.以在函数中定义函数.可以在类中定义object:可以在函数中定义类,类成员的缺省访问级别是:publ ...
- Scala学习——数组/映射/元组
[<快学Scala>笔记] 数组 / 映射 / 元组 一.数组 1.定长数组 声明数组的两种形式: 声明指定长度的数组 val 数组名= new Array[类型](数组长度) 提供数组初 ...
- Scala详解---------数组、元组、映射
一.数组 1.定长数组 声明数组的两种形式: 声明指定长度的数组 val 数组名= new Array[类型](数组长度) 提供数组初始值的数组,无需new关键字 Scala声明数组时,需要带有Arr ...
- Scala具体解释---------数组、元组、映射
一.数组 1.定长数组 声明数组的两种形式: 声明指定长度的数组 val 数组名= new Array[类型](数组长度) 提供数组初始值的数组,无需newkeyword Scala声明数组时.须要带 ...
- (升级版)Spark从入门到精通(Scala编程、案例实战、高级特性、Spark内核源码剖析、Hadoop高端)
本课程主要讲解目前大数据领域最热门.最火爆.最有前景的技术——Spark.在本课程中,会从浅入深,基于大量案例实战,深度剖析和讲解Spark,并且会包含完全从企业真实复杂业务需求中抽取出的案例实战.课 ...
- CDH下集成spark2.2.0与kafka(四十一):在spark+kafka流处理程序中抛出错误java.lang.NoSuchMethodError: org.apache.kafka.clients.consumer.KafkaConsumer.subscribe(Ljava/util/Collection;)V
错误信息 19/01/15 19:36:40 WARN consumer.ConsumerConfig: The configuration max.poll.records = 1 was supp ...
- 大数据Spark+Kafka实时数据分析案例
本案例利用Spark+Kafka实时分析男女生每秒购物人数,利用Spark Streaming实时处理用户购物日志,然后利用websocket将数据实时推送给浏览器,最后浏览器将接收到的数据实时展现, ...
- Spark+Kafka的Direct方式将偏移量发送到Zookeeper实现(转)
原文链接:Spark+Kafka的Direct方式将偏移量发送到Zookeeper实现 Apache Spark 1.3.0引入了Direct API,利用Kafka的低层次API从Kafka集群中读 ...
随机推荐
- 划分问题(Java 动态规划)
Description 给定一个正整数的集合A={a1,a2,-.,an},是否可以将其分割成两个子集合,使两个子集合的数加起来的和相等.例A = { 1, 3, 8, 4, 10} 可以分割:{1, ...
- PL/SQL Developer 13注册码(亲测可用)
product code: 4vkjwhfeh3ufnqnmpr9brvcuyujrx3n3le serial Number: 226959 password: xs374ca
- Python 调用接口添加头信息
import requests,jsonurl = 'http://47.108.115.193:9000/tb-store/store/getWechatAppHome'header={" ...
- Mac读写ntfs软件究竟哪一款适合我们?
生活中我们免不了会使用一些硬盘设备来存储文件或者是数据,然而绝大多数的移动硬盘都是ntfs格式.Mac读写ntfs软件有很多,究竟哪一款适合我们? 首先,我们一起了解一下什么是ntfs格式.ntfs, ...
- 【性能测试】【locust】场景性能测试步骤
场景设计 实现登陆基本功能,输出相应结果,脚本通 多用户实现随机登陆 添加初始化方法on_start: 每个用户只运行一次 添加检查点: catch_responses = True 脚本设计 # 导 ...
- 精尽MyBatis源码分析 - 插件机制
该系列文档是本人在学习 Mybatis 的源码过程中总结下来的,可能对读者不太友好,请结合我的源码注释(Mybatis源码分析 GitHub 地址.Mybatis-Spring 源码分析 GitHub ...
- 这几个很实用的Linux命令,千万别忘记了!
- Foreground-aware Image Inpainting
引言 语义分割得到边缘信息指导修复其三 存在问题:现在的图像修复方法主要的通过周围像素来修复,当修复区域与前景区域(显著物体)有交叠时,由于修复区域缺失前景与背景的时间内容导致修复结果不理想. 提出方 ...
- Docker 入门介绍
Docker是什么 从发布到现在 docker一直很受关注,在一定程度是改变了软件行业 如果你还不知道 docker 是什么是不是有点out了,接下来我们来介绍docker是什么,解决了什么问题,好处 ...
- 手把手教你使用Rollup打包📦并发布自己的工具库🔧
DevUI是一支兼具设计视角和工程视角的团队,服务于华为云DevCloud平台和华为内部数个中后台系统,服务于设计师和前端工程师. 官方网站:devui.design Ng组件库:ng-devui(欢 ...