5分钟看懂系列:Python 线程池原理及实现
概述
传统多线程方案会使用“即时创建, 即时销毁”的策略。尽管与创建进程相比,创建线程的时间已经大大的缩短,但是如果提交给线程的任务是执行时间较短,而且执行次数极其频繁,那么服务器将处于不停的创建线程,销毁线程的状态。
一个线程的运行时间可以分为3部分:线程的启动时间、线程体的运行时间和线程的销毁时间。在多线程处理的情景中,如果线程不能被重用,就意味着每次创建都需要经过启动、销毁和运行3个过程。这必然会增加系统相应的时间,降低了效率。
使用线程池:由于线程预先被创建并放入线程池中,同时处理完当前任务之后并不销毁而是被安排处理下一个任务,因此能够避免多次创建线程,从而节省线程创建和销毁的开销,能带来更好的性能和系统稳定性。
![]()
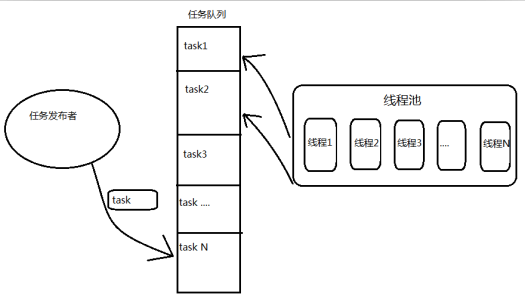
线程池模型
这里使用创建Thread()实例来实现,下面会再用继承threading.Thread()的类来实现
# 创建队列实例, 用于存储任务
queue = Queue()
# 定义需要线程池执行的任务
def do_job():
while True:
i = queue.get()
time.sleep(1)
print 'index %s, curent: %s' % (i, threading.current_thread())
queue.task_done()
if __name__ == '__main__':
# 创建包括3个线程的线程池
for i in range(3):
t = Thread(target=do_job)
t.daemon=True # 设置线程daemon 主线程退出,daemon线程也会推出,即时正在运行
t.start()
# 模拟创建线程池3秒后塞进10个任务到队列
time.sleep(3)
for i in range(10):
queue.put(i)
queue.join()复制代码![]()
- daemon说明:
如果某个子线程的daemon属性为False,主线程结束时会检测该子线程是否结束,如果该子线程还在运行,则主线程会等待它完成后再退出;
如果某个子线程的daemon属性为True,主线程运行结束时不对这个子线程进行检查而直接退出,同时所有daemon值为True的子线程将随主线程一起结束,而不论是否运行完成。
daemon=True 说明线程是守护线程,守护线程外部没法触发它的退出,所以主线程退出就直接让子线程跟随退出 - queue.task_done() 说明:
queue.join()的作用是让主程序阻塞等待队列完成,就结束退出,但是怎么让主程序知道队列已经全部取出并且完成呢?queue.get() 只能让主程序知道队列取完了,但不代表队列里的任务都完成,所以程序需要调用queue.task_done() 告诉主程序,又一个任务完成了,直到全部任务完成,主程序退出
输出结果
index 1, curent: <Thread(Thread-2, started daemon 139652180764416)>
index 0, curent: <Thread(Thread-1, started daemon 139652189157120)>
index 2, curent: <Thread(Thread-3, started daemon 139652172371712)>
index 4, curent: <Thread(Thread-1, started daemon 139652189157120)>
index 3, curent: <Thread(Thread-2, started daemon 139652180764416)>
index 5, curent: <Thread(Thread-3, started daemon 139652172371712)>
index 6, curent: <Thread(Thread-1, started daemon 139652189157120)>
index 7, curent: <Thread(Thread-2, started daemon 139652180764416)>
index 8, curent: <Thread(Thread-3, started daemon 139652172371712)>
index 9, curent: <Thread(Thread-1, started daemon 139652189157120)>
finish复制代码![]()
可以看到所有任务都是在这几个线程中完成Thread-(1-3)
线程池原理
线程池基本原理: 我们把任务放进队列中去,然后开N个线程,每个线程都去队列中取一个任务,执行完了之后告诉系统说我执行完了,然后接着去队列中取下一个任务,直至队列中所有任务取空,退出线程。
上面这个例子生成一个有3个线程的线程池,每个线程都无限循环阻塞读取Queue队列的任务所有任务都只会让这3个预生成的线程来处理。
具体工作描述如下:
- 创建Queue.Queue()实例,然后对它填充数据或任务
- 生成守护线程池,把线程设置成了daemon守护线程
- 每个线程无限循环阻塞读取queue队列的项目item,并处理
- 每次完成一次工作后,使用queue.task_done()函数向任务已经完成的队列发送一个信号
- 主线程设置queue.join()阻塞,直到任务队列已经清空了,解除阻塞,向下执行
这个模式下有几个注意的点:
- 将线程池的线程设置成daemon守护进程,意味着主线程退出时,守护线程也会自动退出,如果使用默认
daemon=False的话, 非daemon的线程会阻塞主线程的退出,所以即使queue队列的任务已经完成
线程池依然阻塞无限循环等待任务,使得主线程也不会退出。 - 当主线程使用了queue.join()的时候,说明主线程会阻塞直到queue已经是清空的,而主线程怎么知道queue已经是清空的呢?就是通过每次线程queue.get()后并处理任务后,发送queue.task_done()信号,queue的数据就会减1,直到queue的数据是空的,queue.join()解除阻塞,向下执行。
- 这个模式主要是以队列queue的任务来做主导的,做完任务就退出,由于线程池是daemon的,所以主退出线程池所有线程都会退出。 有别于我们平时可能以队列主导thread.join()阻塞,这种线程完成之前阻塞主线程。看需求使用哪个join():
如果是想做完一定数量任务的队列就结束,使用queue.join(),比如爬取指定数量的网页
如果是想线程做完任务就结束,使用thread.join()
示例:使用线程池写web服务器
import socket
import threading
from threading import Thread
import threading
import sys
import time
import random
from Queue import Queue
host = ''
port = 8888
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.bind((host, port))
s.listen(3)
class ThreadPoolManger():
"""线程池管理器"""
def __init__(self, thread_num):
# 初始化参数
self.work_queue = Queue()
self.thread_num = thread_num
self.__init_threading_pool(self.thread_num)
def __init_threading_pool(self, thread_num):
# 初始化线程池,创建指定数量的线程池
for i in range(thread_num):
thread = ThreadManger(self.work_queue)
thread.start()
def add_job(self, func, *args):
# 将任务放入队列,等待线程池阻塞读取,参数是被执行的函数和函数的参数
self.work_queue.put((func, args))
class ThreadManger(Thread):
"""定义线程类,继承threading.Thread"""
def __init__(self, work_queue):
Thread.__init__(self)
self.work_queue = work_queue
self.daemon = True
def run(self):
# 启动线程
while True:
target, args = self.work_queue.get()
target(*args)
self.work_queue.task_done()
# 创建一个有4个线程的线程池
thread_pool = ThreadPoolManger(4)
# 处理http请求,这里简单返回200 hello world
def handle_request(conn_socket):
recv_data = conn_socket.recv(1024)
reply = 'HTTP/1.1 200 OK \r\n\r\n'
reply += 'hello world'
print 'thread %s is running ' % threading.current_thread().name
conn_socket.send(reply)
conn_socket.close()
# 循环等待接收客户端请求
while True:
# 阻塞等待请求
conn_socket, addr = s.accept()
# 一旦有请求了,把socket扔到我们指定处理函数handle_request处理,等待线程池分配线程处理
thread_pool.add_job(handle_request, *(conn_socket, ))
s.close()复制代码![]()
# 运行进程
[master][/data/web/advance_python/socket]$ python sock_s_threading_pool.py
# 查看线程池状况
[master][/data/web/advance_python/socket]$ ps -eLf|grep sock_s_threading_pool
lisa+ 27488 23705 27488 0 5 23:22 pts/30 00:00:00 python sock_s_threading_pool.py
lisa+ 27488 23705 27489 0 5 23:22 pts/30 00:00:00 python sock_s_threading_pool.py
lisa+ 27488 23705 27490 0 5 23:22 pts/30 00:00:00 python sock_s_threading_pool.py
lisa+ 27488 23705 27491 0 5 23:22 pts/30 00:00:00 python sock_s_threading_pool.py
lisa+ 27488 23705 27492 0 5 23:22 pts/30 00:00:00 python sock_s_threading_pool.py
# 跟我们预期一样一共有5个线程,一个主线程,4个线程池线程复制代码![]()
这个线程池web服务器编写框架包括下面几个组成部分及步骤:
- 定义线程池管理器ThreadPoolManger,用于创建并管理线程池,提供add_job()接口,给线程池加任务
- 定义工作线程ThreadManger, 定义run()方法,负责无限循环工作队列,并完成队列任务
- 定义socket监听请求s.accept() 和处理请求 handle_requests() 任务。
- 初始化一个4个线程的线程池,都阻塞等待这读取队列queue的任务
- 当socket.accept()有请求,则把connsocket做为参数,handlerequest方法,丢给线程池,等待线程池分配线程处理
GIL 对多线程的影响
因为Python的线程虽然是真正的线程,但解释器执行代码时,有一个GIL锁:Global Interpreter Lock,任何Python线程执行前,必须先获得GIL锁,然后,每执行100条字节码,解释器就自动释放GIL锁,让别的线程有机会执行。这个GIL全局锁实际上把所有线程的执行代码都给上了锁,所以,多线程在Python中只能交替执行,即使100个线程跑在100核CPU上,也只能用到1个核。
但是对于IO密集型的任务,多线程还是起到很大效率提升,这是协同式多任务当一项任务比如网络 I/O启动,而在长的或不确定的时间,没有运行任何 Python 代码的需要,一个线程便会让出GIL,从而其他线程可以获取 GIL 而运行 Python。这种礼貌行为称为协同式多任务处理,它允许并发;多个线程同时等待不同事件。
两个线程在同一时刻只能有一个执行 Python ,但一旦线程开始连接,它就会放弃 GIL ,这样其他线程就可以运行。这意味着两个线程可以并发等待套接字连接,这是一件好事。在同样的时间内它们可以做更多的工作。
线程池要设置为多少?
服务器CPU核数有限,能够同时并发的线程数有限,并不是开得越多越好,以及线程切换是有开销的,如果线程切换过于频繁,反而会使性能降低
线程执行过程中,计算时间分为两部分:
- CPU计算,占用CPU
- 不需要CPU计算,不占用CPU,等待IO返回,比如recv(), accept(), sleep()等操作,具体操作就是比如
访问cache、RPC调用下游service、访问DB,等需要网络调用的操作
那么如果计算时间占50%, 等待时间50%,那么为了利用率达到最高,可以开2个线程:假如工作时间是2秒, CPU计算完1秒后,线程等待IO的时候需要1秒,此时CPU空闲了,这时就可以切换到另外一个线程,让CPU工作1秒后,线程等待IO需要1秒,此时CPU又可以切回去,第一个线程这时刚好完成了1秒的IO等待,可以让CPU继续工作,就这样循环的在两个线程之前切换操作。
那么如果计算时间占20%, 等待时间80%,那么为了利用率达到最高,可以开5个线程:可以想象成完成任务需要5秒,CPU占用1秒,等待时间4秒,CPU在线程等待时,可以同时再激活4个线程,这样就把CPU和IO等待时间,最大化的重叠起来
抽象一下,计算线程数设置的公式就是:N核服务器,通过执行业务的单线程分析出本地计算时间为x,等待时间为y,则工作线程数(线程池线程数)设置为 N*(x+y)/x,能让CPU的利用率最大化。由于有GIL的影响,python只能使用到1个核,所以这里设置N=1
关于我
如果文章对你有收获,可以收藏转发,这会给我一个大大鼓励哟!
想要获取更多Python学习资料可以加
QQ:2955637827私聊
或加Q群630390733
大家一起来学习讨论吧!
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理
5分钟看懂系列:Python 线程池原理及实现的更多相关文章
- java多线程系列(六)---线程池原理及其使用
线程池 前言:如有不正确的地方,还望指正. 目录 认识cpu.核心与线程 java多线程系列(一)之java多线程技能 java多线程系列(二)之对象变量的并发访问 java多线程系列(三)之等待通知 ...
- 5分钟看懂系列:HTTP缓存机制详解
原创文章首发于公众号:「码农富哥」,欢迎收藏和关注,如转载请注明出处! 什么是HTTP缓存 HTTP 缓存可以说是HTTP性能优化中简单高效的一种优化方式了,缓存是一种保存资源副本并在下次请求时直接使 ...
- 10分钟看懂, Java NIO 底层原理
目录 写在前面 1.1. Java IO读写原理 1.1.1. 内核缓冲与进程缓冲区 1.1.2. java IO读写的底层流程 1.2. 四种主要的IO模型 1.3. 同步阻塞IO(Blocking ...
- Java多线程系列--“JUC线程池”03之 线程池原理(二)
概要 在前面一章"Java多线程系列--“JUC线程池”02之 线程池原理(一)"中介绍了线程池的数据结构,本章会通过分析线程池的源码,对线程池进行说明.内容包括:线程池示例参考代 ...
- 线程池原理及python实现
为什么需要线程池 目前的大多数网络服务器,包括Web服务器.Email服务器以及数据库服务器等都具有一个共同点,就是单位时间内必须处理数目巨大的连接请求,但处理时间却相对较短. 传统多线程方案中我们采 ...
- 对Python线程池
本文对Python线程池进行详细说明介绍,IDE选择及编码的解决方案进行了一番详细的描述,实为Python初学者必读的Python学习经验心得. AD: 干货来了,不要等!WOT2015 北京站演讲P ...
- Java并发包源码学习系列:线程池ScheduledThreadPoolExecutor源码解析
目录 ScheduledThreadPoolExecutor概述 类图结构 ScheduledExecutorService ScheduledFutureTask FutureTask schedu ...
- Java多线程系列--“JUC线程池”06之 Callable和Future
概要 本章介绍线程池中的Callable和Future.Callable 和 Future 简介示例和源码分析(基于JDK1.7.0_40) 转载请注明出处:http://www.cnblogs.co ...
- Java多线程系列--“JUC线程池”02之 线程池原理(一)
概要 在上一章"Java多线程系列--“JUC线程池”01之 线程池架构"中,我们了解了线程池的架构.线程池的实现类是ThreadPoolExecutor类.本章,我们通过分析Th ...
随机推荐
- 【移动自动化】【四】获取Toast
什么是Toast Android中的Toast是一种简易的消息提示框. 如何识别Toast 使用 xpath 查找 推荐 //*[@class='android.widget.Toast'] (固定这 ...
- PHP 统计文件数和文件大小
/** * 统计文件数和文件大小 */private function getFileCacheCount($pathName){ $data = [ 'num' => 0, 'size' =& ...
- Linux(CentOS 7下httpd的安装)
Linux(CentOS 7下httpd的安装) 自己是个linux小白.最近几天在学linux,看到视频教程中安装源码包httpd所以自己想试一试,安装过程中有很多的错误,在网上找了很久也没找到,要 ...
- 2016年第七届蓝桥杯【C++省赛B组】F、G、H、J 题解
F. 方格填数 #深搜 题意 有\(10\)个格子,填入0~9的数字.要求:连续的两个数字不能相邻.(左右.上下.对角都算相邻),求可能的填数方案数. +--+--+--+ | | | | +--+- ...
- java40
时隔小半年,重新捡起Java的学习 问题: 1.eclipse好久没用,再打开时,eclipse的项目都没有了,如何找回? 打开switch-workplace-other点开,选择以前的文件所在处. ...
- java12(eclipse断点调试)
选择结构switch 1.格式: switch(整型数据){ case 值A:System.out.println("");break; case 值B:System.out.pr ...
- Django的下载及命令
安装 命令行 pip3 install django==1.11.11 测试是否安装成功 django-admin 创建django项目 django-admin startproject 项目名称( ...
- Centos7配置阿里epel源|yum源
这一步非常重要.重要.重要.在这解释一下源的概念,打个比方如果手机想获取一个软件,可以选择很多途径,如华为的华为商店,小米的应用商店,苹果的App store,源就相当于各种手机获取软件的商店.因为国 ...
- JZOJ 【NOIP2016提高A组集训第16场11.15】兔子
JZOJ [NOIP2016提高A组集训第16场11.15]兔子 题目 Description 在一片草原上有N个兔子窝,每个窝里住着一只兔子,有M条路径连接这些窝.更特殊地是,至多只有一个兔子窝有3 ...
- Kotlin for Java Developers 学习笔记
Kotlin for Java Developers 学习笔记 ★ Coursera 课程 Kotlin for Java Developers(由 JetBrains 提供)的学习笔记 " ...