Flink-v1.12官方网站翻译-P010-Fault Tolerance via State Snapshots
通过状态快照进行容错
状态后台
Flink管理的键控状态是一种碎片化的、键/值存储,每项键控状态的工作副本都被保存在负责该键的任务管理员的本地某处。操作员的状态也被保存在需要它的机器的本地。Flink会定期对所有状态进行持久化快照,并将这些快照复制到某个更持久的地方,比如分布式文件系统。
在发生故障的情况下,Flink可以恢复你的应用程序的完整状态,并恢复处理,就像什么都没有发生过一样。
Flink管理的这种状态被存储在状态后端中。状态后端有两种实现--一种是基于RocksDB的,它是一个嵌入式的键/值存储,将其工作状态保存在磁盘上;另一种是基于堆的状态后端,将其工作状态保存在内存中,在Java堆上。这种基于堆的状态后端有两种口味:将其状态快照持久化到分布式文件系统的FsStateBackend和使用JobManager的堆的MemoryStateBackend。
| 名称 | 工作状态 | 状态备份 | 快照 |
|---|---|---|---|
| RocksDB状态备份 | 本地磁盘(临时文件夹) | 分布式文件系统 | 全量/增量 |
|
|||
| Fs状态备份 | JVM 堆 | 分布式文件系统 | 全量 |
|
|||
| Memory状态备份 | JVM 堆 | JobManager JVM 堆 | 全量 |
|
|||
当处理保存在基于堆的状态后端的状态时,访问和更新涉及到在堆上读写对象。但是对于保存在RocksDBStateBackend中的对象,访问和更新涉及到序列化和反序列化,因此成本更高。但是使用RocksDB可以拥有的状态数量只受限于本地磁盘的大小。还要注意的是,只有RocksDBStateBackend能够进行增量快照,这对于有大量缓慢变化的状态的应用来说是一个很大的好处。
所有这些状态后端都能够进行异步快照,这意味着它们可以在不妨碍正在进行的流处理的情况下进行快照。
状态快照
定义
- 快照--一个通用术语,指的是一个Flink作业状态的全局、一致的图像。快照包括进入每个数据源的指针(例如,进入文件或Kafka分区的偏移),以及来自每个作业的有状态操作符的状态副本,这些操作符是在处理了所有事件后产生的,直到源中的这些位置。
- 检查点--Flink为了能够从故障中恢复而自动拍摄的快照。检查点可以是增量的,并为快速恢复进行了优化。
- 外部化检查点--通常检查点不打算被用户操纵。Flink只在作业运行时保留n个最近的检查点(n是可配置的),并在作业取消时删除它们。但你也可以配置它们被保留,在这种情况下,你可以手动从它们恢复。
- 保存点--由用户(或API调用)手动触发的快照,用于某些操作目的,如有状态的重新部署/升级/重新缩放操作。保存点始终是完整的,并为操作的灵活性进行了优化。
状态快照如何运作?
Flink使用了Chandy-Lamport算法的一个变体,称为异步障碍快照。
当检查点协调器(作业管理器的一部分)指示任务管理器开始检查点时,它让所有的源记录它们的偏移量,并在它们的流中插入编号的检查点障碍。这些障碍物在作业图中流动,表明每个检查点前后的流的部分。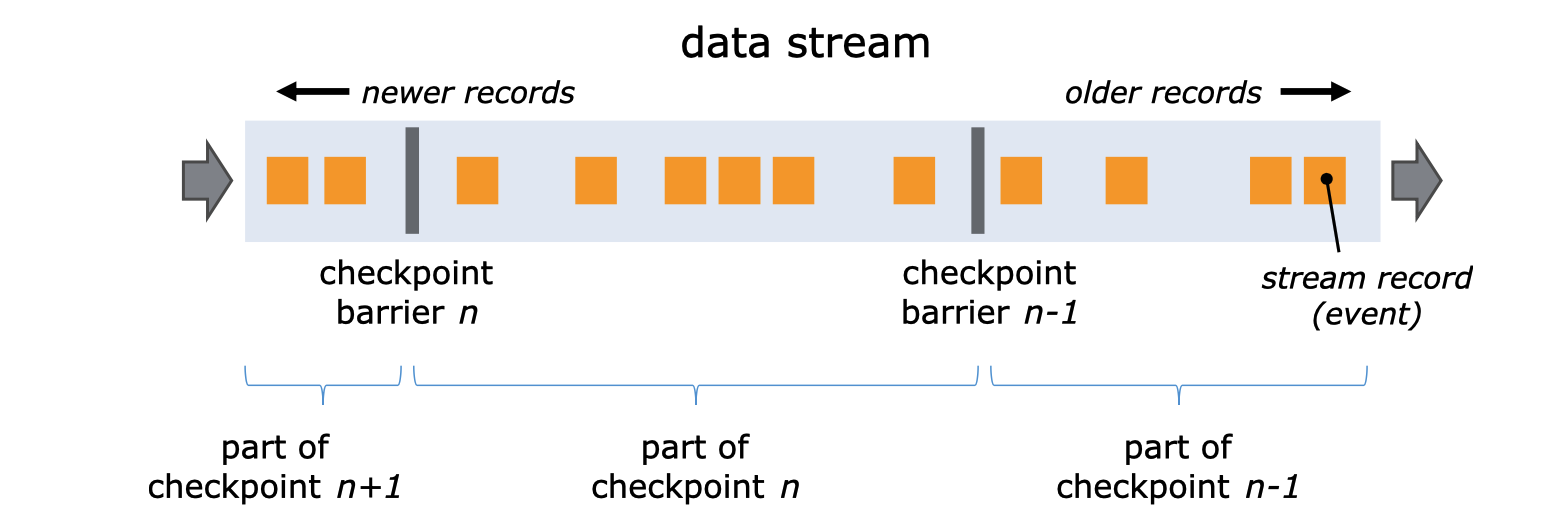
检查点n将包含每个操作者的状态,这些状态是由于消耗了检查点障碍n之前的每个事件,而没有消耗它之后的任何事件。
当作业图中的每个操作者接收到这些障碍之一时,它就会记录其状态。具有两个输入流(如CoProcessFunction)的操作者执行屏障对齐,这样快照将反映消耗两个输入流的事件所产生的状态,直到(但不超过)两个屏障。

Flink的状态后端使用复制-写机制,允许在异步快照状态的旧版本时,流处理不受阻碍地继续。只有当快照被持久化后,这些旧版本的状态才会被垃圾回收。
确切的一次保证
当流处理应用中出现问题时,有可能出现丢失,或者重复的结果。在Flink中,根据你对应用的选择和你运行它的集群,这些结果中的任何一种都是可能的。
- Flink不努力从故障中恢复(最多一次)。
- 没有任何损失,但您可能会遇到重复的结果(至少一次)。
- 没有任何东西丢失或重复(精确地一次)。
鉴于Flink通过倒带和重放源数据流从故障中恢复,当理想情况被描述为精确一次时,这并不意味着每个事件都将被精确处理一次。相反,它意味着每一个事件都会对Flink所管理的状态产生一次确切的影响。
Barrier alignment只需要用于提供精确的一次保证。如果你不需要这个,你可以通过配置Flink使用CheckpointingMode.AT_LEAST_ONCE来获得一些性能,这样做的效果是禁用屏障对齐。
端到端精准一次
为了实现端到端精确的一次,让源的每个事件精确地影响汇,以下几点必须是真的。
- 你的源必须是可重播的,并且
- 你的汇必须是事务性的(或幂等的)
实践
Flink Operations Playground包括观察故障和恢复的部分。
下一步阅读
- Stateful Stream Processing
- State Backends
- Fault Tolerance Guarantees of Data Sources and Sinks
- Enabling and Configuring Checkpointing
- Checkpoints
- Savepoints
- Tuning Checkpoints and Large State
- Monitoring Checkpointing
- Task Failure Recovery
Flink-v1.12官方网站翻译-P010-Fault Tolerance via State Snapshots的更多相关文章
- Flink-v1.12官方网站翻译-P021-State & Fault Tolerance-overview
状态和容错 在本节中,您将了解Flink为编写有状态程序提供的API.请看一下Stateful Stream Processing来了解有状态流处理背后的概念. 下一步去哪里? Working wit ...
- Flink-v1.12官方网站翻译-P028-Custom Serialization for Managed State
管理状态的自定义序列化 本页面的目标是为需要使用自定义状态序列化的用户提供指导,涵盖了如何提供自定义状态序列化器,以及实现允许状态模式演化的序列化器的指南和最佳实践. 如果你只是简单地使用Flink自 ...
- Flink-v1.12官方网站翻译-P016-Flink DataStream API Programming Guide
Flink DataStream API编程指南 Flink中的DataStream程序是对数据流实现转换的常规程序(如过滤.更新状态.定义窗口.聚合).数据流最初是由各种来源(如消息队列.套接字流. ...
- Flink-v1.12官方网站翻译-P005-Learn Flink: Hands-on Training
学习Flink:实践培训 本次培训的目标和范围 本培训介绍了Apache Flink,包括足够的内容让你开始编写可扩展的流式ETL,分析和事件驱动的应用程序,同时省略了很多(最终重要的)细节.本书的重 ...
- Flink-v1.12官方网站翻译-P025-Queryable State Beta
可查询的状态 注意:可查询状态的客户端API目前处于不断发展的状态,对所提供接口的稳定性不做保证.在即将到来的Flink版本中,客户端的API很可能会有突破性的变化. 简而言之,该功能将Flink的托 ...
- Flink-v1.12官方网站翻译-P002-Fraud Detection with the DataStream API
使用DataStream API进行欺诈检测 Apache Flink提供了一个DataStream API,用于构建强大的.有状态的流式应用.它提供了对状态和时间的精细控制,这使得高级事件驱动系统的 ...
- Flink-v1.12官方网站翻译-P015-Glossary
术语表 Flink Application Cluster Flink应用集群是一个专用的Flink集群,它只执行一个Flink应用的Flink作业.Flink集群的寿命与Flink应用的寿命绑定. ...
- Flink-v1.12官方网站翻译-P008-Streaming Analytics
流式分析 事件时间和水印 介绍 Flink明确支持三种不同的时间概念. 事件时间:事件发生的时间,由产生(或存储)该事件的设备记录的时间 摄取时间:Flink在摄取事件时记录的时间戳. 处理时间:您的 ...
- Flink-v1.12官方网站翻译-P004-Flink Operations Playground
Flink操作训练场 在各种环境中部署和操作Apache Flink的方法有很多.无论这种多样性如何,Flink集群的基本构件保持不变,类似的操作原则也适用. 在这个操场上,你将学习如何管理和运行Fl ...
随机推荐
- JavaScript基础知识梳理
一.简单数据类型 Number.String.Boolean.Undefined.Null 1.Number: 方法: toPrecision( ) 返回指定长度的数字(范围是1到100) toFix ...
- spark的 structStreaming 一些介绍
转发 https://www.toutiao.com/a6696339998905467403/?tt_from=mobile_qq&utm_campaign=client_share& ...
- 安装Linux Deploy和Termux之后,再安装ftp服务软件都是多余的!
之前以为Debian 9 running via Linux Deploy或者Termux在安卓系统部署之后,一定要安装vsftpd或者pure-ftpd这些专门的ftp服务器软件,才能提供ftp服务 ...
- Spark学习进度10-DS&DF基础操作
有类型操作 flatMap 通过 flatMap 可以将一条数据转为一个数组, 后再展开这个数组放入 Dataset val ds1=Seq("hello spark"," ...
- ThinkPHP5表单令牌刷新
制作登录页面的时候,加入了表单令牌,账号和密码输入错误后,再登录的话,会提示表单令牌错误, 这是因为旧的令牌已经过期了,我们要处理下前端的token,修复的办法,在路由文件下加入 //刷新表单令牌,然 ...
- MyBatis初级实战之二:增删改查
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- docker 镜像导入load、导出save以及重命名
docker 导入导出操作 save 保存(导出)镜像 # 把镜像打包成 .tar # -o 要保存路径.tar # > 要保存路径.tar # docker save 镜像id > /存 ...
- 通过trace分析优化其如何选择执行计划
mysql5.6提供了对sql的跟踪trace,通过trace文件能够进一步了解为什么优化其选择执行计划a而不选b执行计划,帮助我们更好的理解优化其的行为. 使用方式:首先打开trace,设置格式为j ...
- 大文件上传FTP
需求 将本地大文件通过浏览器上传到FTP服务器. 原有方法 将本地文件整个上传到浏览器,然后发送到node服务器,最后由node发送到FTP服务器. 存在问题 浏览器缓存有限且上传速率受网速影响,当文 ...
- Kubernetes 升级过程记录:从 1.17.0 升级至最新版 1.20.2
本文记录的是将 kubernetes 集群从 1.17.0 升级至最新版 1.20.2 的实际操作步骤,由于 1.17.0 无法直接升级到 1.20.2,需要进行2次过滤升级,1.17.0 -> ...