监督学习-KNN最邻近分类算法
分类(Classification)指的是从数据中选出已经分好类的训练集,在该训练集上运用数据挖掘分类的技术建立分类模型,从而对没有分类的数据进行分类的分析方法。
分类问题的应用场景:用于将事物打上一个标签,通常结果为离散值。例如判断一副图片上的动物是一只猫还是一只狗,分类通常是建立在回归之上。
基本的分类方法—KNN最邻近分类算法,简称KNN,是最简单的机器学习算法之一。
核心逻辑:在距离空间里,如果一个样本的最接近的K个邻居里,绝大多数属于某个类别,则该样本也属于这个类别。
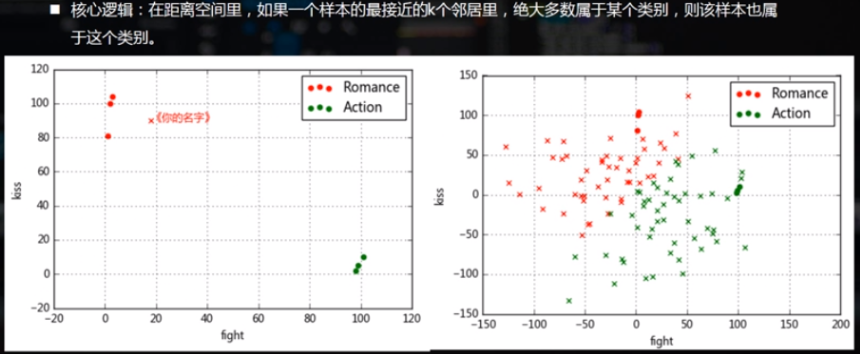
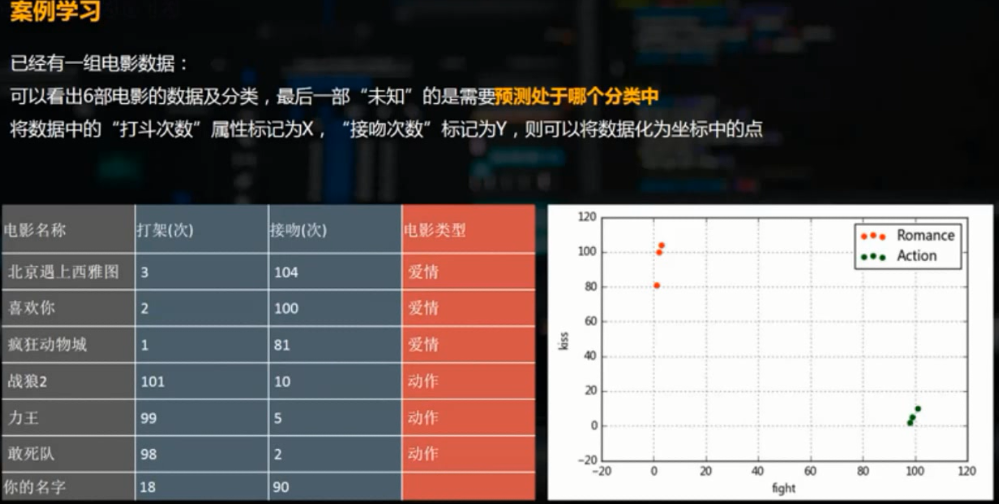
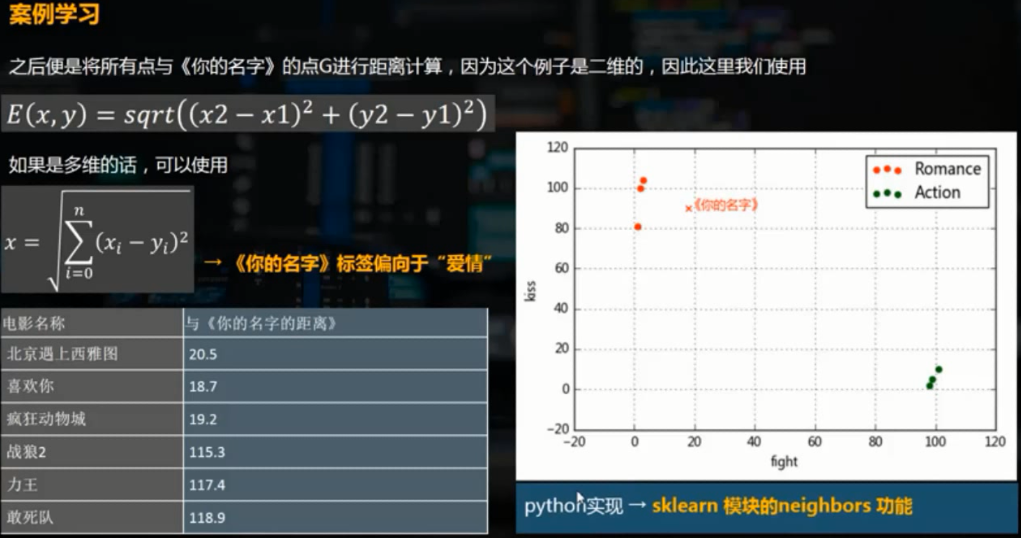
给定电影分类样例,预测某一电影的分类。
from sklearn import neighbors #导入模块
import warnings
warnings.filterwarnings('ignore') #不发出警告 df = pd.DataFrame({'name':['北京遇上西雅图','喜欢你','疯狂动物城','战狼2','力王','敢死队'],
'fight':[3,2,1,101,99,98],
'kiss':[104,100,81,10,5,2],
'type':['love','love','love','action','action','action']})
love = df[df['type']] == 'love']
action = df[df['type']== 'action']
plt.scatter(love['fight'],love['kiss'],color = 'red',label = 'love') # 类型为爱情的电影做红色散点图
plt.scatter(action['fight'],action['kiss'],color = 'green',label='action') # 类型为动作片的电影做绿色散点图
plt.legend() knn = neighbors.KNeighborsClassifier() # 创建KNN最邻近分类模型
knn.fit(df[['fight','kiss']],df['type']) # 给模型导入数据 k = knn.predict([[18, 90]]) # 预测数据,参数需要是二维的
print('预测电影类型为%s'%k,type(k)) # 预测电影类型为['love'],<class 'numpy.ndarray'>
plt.scatter(18,90,color = 'blue',marker='x',label=k)
plt.text(18,90,'《你的名字》',color='blue')

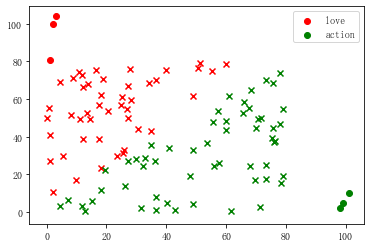
另外随机生成一组数据,用上面的knn分类模型进行分类
df2 = pd.DataFrame(np.random.rand(100,2)*80,columns=['fight','kiss'])
df2['predictType'] = knn.predict(df2) plt.scatter(love['fight'],love['kiss'],color = 'red',label = 'love')
plt.scatter(action['fight'],action['kiss'],color = 'green',label='action')
plt.legend() plt.scatter(df2[df2['predictType']=='love']['fight'],df2[df2['predictType']=='love']['kiss'],color = 'red',label = 'love',marker='x')
plt.scatter(df2[df2['predictType']=='action']['fight'],df2[df2['predictType']=='action']['kiss'],color = 'green',label='action',marker='x') df2.head()
案例2:植物分类
from sklearn import datasets
iris = datasets.load_iris()
print(iris.data[:5]) #类型为<class 'sklearn.utils.Bunch'>,数据部分为一个二维数组
print(iris.feature_names)
print(iris.target_names)
# print(iris.target) #表示每一个数据所属的分类,分类用数字表示,结果为数组 # [[5.1 3.5 1.4 0.2]
# [4.9 3. 1.4 0.2]
# [4.7 3.2 1.3 0.2]
# [4.6 3.1 1.5 0.2]
# [5. 3.6 1.4 0.2]]
#['sepal length (cm)','sepal width (cm)','petal length (cm)','petal width (cm)'],表示分类特征:萼片长度、萼片宽度、花瓣长度、花瓣宽度
#['setosa' 'versicolor' 'virginica'],表示分类名称
构建DataFrame方便查看数据,并使用数字分类和名称分类分别构建模型
data = pd.DataFrame(iris.data, columns = iris.feature_names) #构建DataFrame方便查看
data['target'] = iris.target
print(data.head())
print('----------------------------') d = pd.DataFrame({'target':[0, 1, 2],'target_names':iris.target_names})
print(d.head())
print('----------------------------') data = pd.merge(data,d,on='target') #最终形成的DataFrame包含四个分类特征、分类数值、分裂名称
print(data.head())
print('----------------------------') knn1 = neighbors.KNeighborsClassifier()
knn1.fit(iris.data,iris.target) #使用分类数值构建模型
t1 = knn1.predict([[0.1,0.2,0.3,0.4]])
print('所在分类(数字表示)为',t1) knn2 = neighbors.KNeighborsClassifier()
knn2.fit(iris.data,data['target_names']) #使用分类名称构建模型
t2 = knn2.predict([[0.1,0.2,0.3,0.4]])
print('所在分类(名称表示)为',t2)
# 上述输出结果
# sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) target
# 0 5.1 3.5 1.4 0.2 0
# 1 4.9 3.0 1.4 0.2 0
# 2 4.7 3.2 1.3 0.2 0
# 3 4.6 3.1 1.5 0.2 0
# 4 5.0 3.6 1.4 0.2 0
# ----------------------------
# target target_names
# 0 0 setosa
# 1 1 versicolor
# 2 2 virginica
# ----------------------------
# sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) target target_names
# 0 5.1 3.5 1.4 0.2 0 setosa
# 1 4.9 3.0 1.4 0.2 0 setosa
# 2 4.7 3.2 1.3 0.2 0 setosa
# 3 4.6 3.1 1.5 0.2 0 setosa
# 4 5.0 3.6 1.4 0.2 0 setosa
# ----------------------------
# 所在分类(数字表示)为 [0]
# 所在分类(名称表示)为 ['setosa']
监督学习-KNN最邻近分类算法的更多相关文章
- 数学建模:2.监督学习--分类分析- KNN最邻近分类算法
1.分类分析 分类(Classification)指的是从数据中选出已经分好类的训练集,在该训练集上运用数据挖掘分类的技术,建立分类模型,对于没有分类的数据进行分类的分析方法. 分类问题的应用场景:分 ...
- kNN算法:K最近邻(kNN,k-NearestNeighbor)分类算法
一.KNN算法概述 邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一.所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它 ...
- KNN邻近分类算法
K邻近(k-Nearest Neighbor,KNN)分类算法是最简单的机器学习算法了.它采用测量不同特征值之间的距离方法进行分类.它的思想很简单:计算一个点A与其他所有点之间的距离,取出与该点最近的 ...
- K邻近分类算法
# -*- coding: utf-8 -*- """ Created on Thu Jun 28 17:16:19 2018 @author: zhen "& ...
- 分类算法-----KNN
摘要: 所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用她最接近的k个邻居来代表.kNN算法的核心思想是如果一个样本在特征空间中的k个最相似的样本中的大多数属于某一个类别,则该样本也属于 ...
- KNN 与 K - Means 算法比较
KNN K-Means 1.分类算法 聚类算法 2.监督学习 非监督学习 3.数据类型:喂给它的数据集是带label的数据,已经是完全正确的数据 喂给它的数据集是无label的数据,是杂乱无章的,经过 ...
- K近邻分类算法实现 in Python
K近邻(KNN):分类算法 * KNN是non-parametric分类器(不做分布形式的假设,直接从数据估计概率密度),是memory-based learning. * KNN不适用于高维数据(c ...
- 什么是机器学习的分类算法?【K-近邻算法(KNN)、交叉验证、朴素贝叶斯算法、决策树、随机森林】
1.K-近邻算法(KNN) 1.1 定义 (KNN,K-NearestNeighbor) 如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类 ...
- [机器学习] ——KNN K-最邻近算法
KNN分类算法,是理论上比较成熟的方法,也是最简单的机器学习算法之一. 该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别 ...
随机推荐
- em(倍)与px的区别
在国内网站中,包括三大门户,以及“引领”中国网站设计潮流的蓝色理想,ChinaUI等都是使用了px作为字体单位.只有百度好歹做了个可调的表率.而 在大洋彼岸,几乎所有的主流站点都使用em作为字体单位, ...
- Demo_2:Qt实现猜字小游戏
1 环境 系统:windows 10 代码编写运行环境:Qt Creator 4.4.1 (community) Github: 2 简介 参考视频:https://www.bilibili.co ...
- css3增加的的属性值position:stricky
position:sticky sticky 英文字面意思是粘,粘贴.这是一个结合了 position:relative 和 position:fixed 两种定位功能于一体的特殊定位,适用于一些特殊 ...
- cf1216E2 Numerical Sequence (hard version)(思维)
cf1216E2 Numerical Sequence (hard version) 题目大意 一个无限长的数字序列,其组成为\(1 1 2 1 2 3 1.......1 2 ... n...\), ...
- 从上到下打印二叉树(剑指offer-22)
题目描述 从上往下打印出二叉树的每个节点,同层节点从左至右打印. 题目解析 使用队列来进行层次遍历,本质上就是宽搜. 题目解答 import java.util.*; /** public class ...
- day12 作业
1.通用文件copy工具实现 with open("a.txt","r",encoding="utf-8") as f ,open(&quo ...
- Scala 面向对象(四):import
1 Scala引入包基本介绍 Scala引入包也是使用import, 基本的原理和机制和Java一样,但是Scala中的import功能更加强大,也更灵活. 因为Scala语言源自于Java,所以ja ...
- scrapy 基础组件专题(十二):scrapy 模拟登录
1. scrapy有三种方法模拟登陆 1.1直接携带cookies 1.2找url地址,发送post请求存储cookie 1.3找到对应的form表单,自动解析input标签,自动解析post请求的u ...
- Django框架09 /ajax、crsf、settings导入
Django框架09 /ajax.crsf.settings导入 目录 Django框架09 /ajax.crsf.settings导入 1. ajax概述 2. ajax应用 3. ajax上传文件 ...
- 深度学习论文翻译解析(十):Visualizing and Understanding Convolutional Networks
论文标题:Visualizing and Understanding Convolutional Networks 标题翻译:可视化和理解卷积网络 论文作者:Matthew D. Zeiler Ro ...