LRU Cache & Bloom Filter

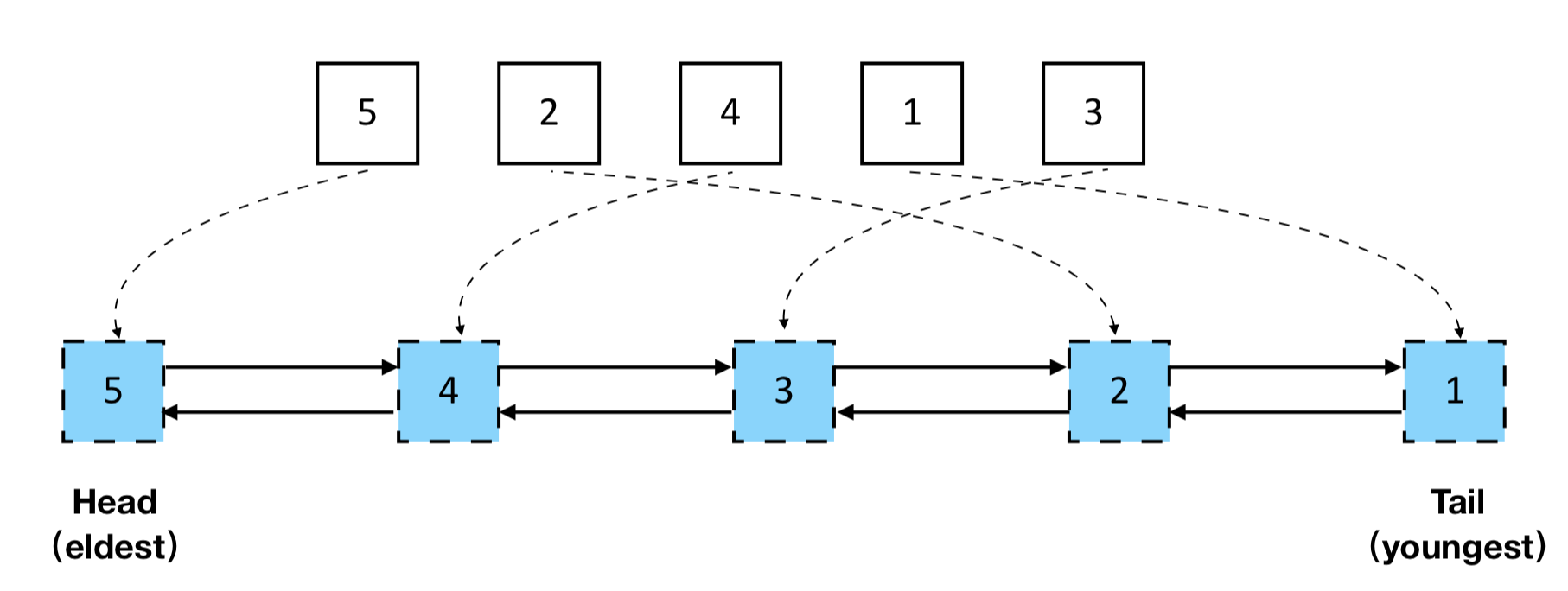
LFU Cache
也记录元素出现的频次,即使最近刚出现的,也未必就会挪到最前面。
缓存内始终按频次排序,如果超了缓存空间限制,还是新进的元素把原先频次最低的顶走。
1. LFU - least frequently used(最近最不常用⻚⾯置换算法,频次越高的放越前面)
2. LRU - least recently usd(最近最少使⽤页⾯置换算法)
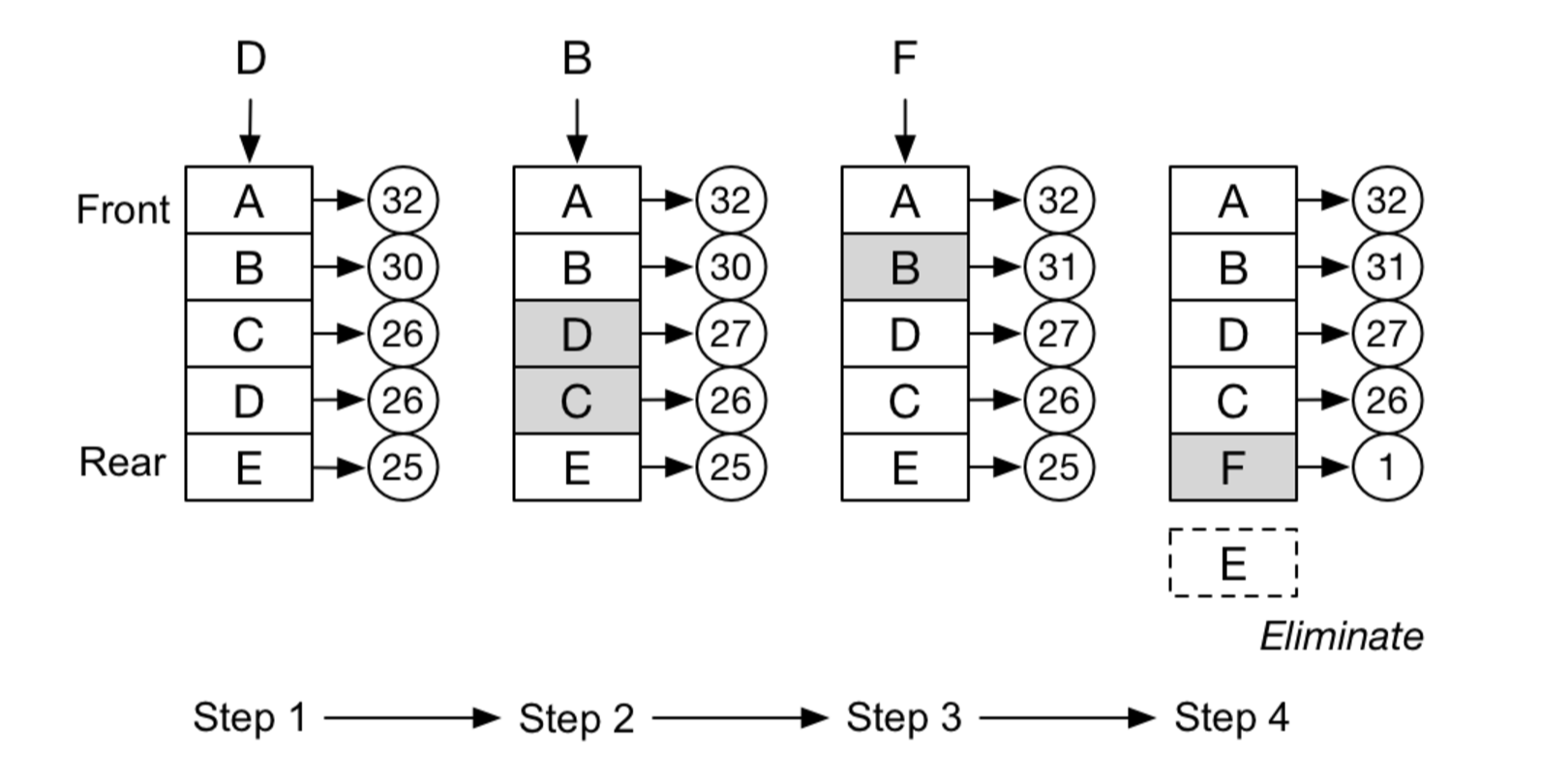
Leetcode 146. LRU缓存机制 https://leetcode-cn.com/problems/lru-cache/
运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制。它应该支持以下操作: 获取数据 get 和 写入数据 put 。
获取数据 get(key) - 如果密钥 (key) 存在于缓存中,则获取密钥的值(总是正数),否则返回 -1。
写入数据 put(key, value) - 如果密钥不存在,则写入其数据值。当缓存容量达到上限时,它应该在写入新数据之前删除最近最少使用的数据值,从而为新的数据值留出空间。
进阶:
你是否可以在 O(1) 时间复杂度内完成这两种操作?
解:
考虑用 ordered dict 实现
1 import collections
2 class LRUCache:
3 def __init__(self, capacity: int):
4 self.dic = collections.OrderedDict()
5 self.remain = capacity
6
7 def get(self, key: int) -> int:
8 if key not in self.dic:
9 return -1
10 v = self.dic.pop(key)
11 self.dic[key] = v # 如果在key在dict中,就pop出来后再set成最新的key
12 return v
13
14 def put(self, key: int, value: int) -> None:
15 if key in self.dic:
16 self.dic.pop(key)
17 else:
18 if self.remain > 0:
19 self.remain -= 1
20 else: # 如果已经满了,就删除第一个key-value对(即最早put的键值对。令last=False即可)
21 self.dic.popitem(last=False)
22
23 self.dic[key] = value # put进去作为最新的键值对
24
25
26 # Your LRUCache object will be instantiated and called as such:
27 # obj = LRUCache(capacity)
28 # param_1 = obj.get(key)
29 # obj.put(key,value)
布隆过滤器 Bloom Filter
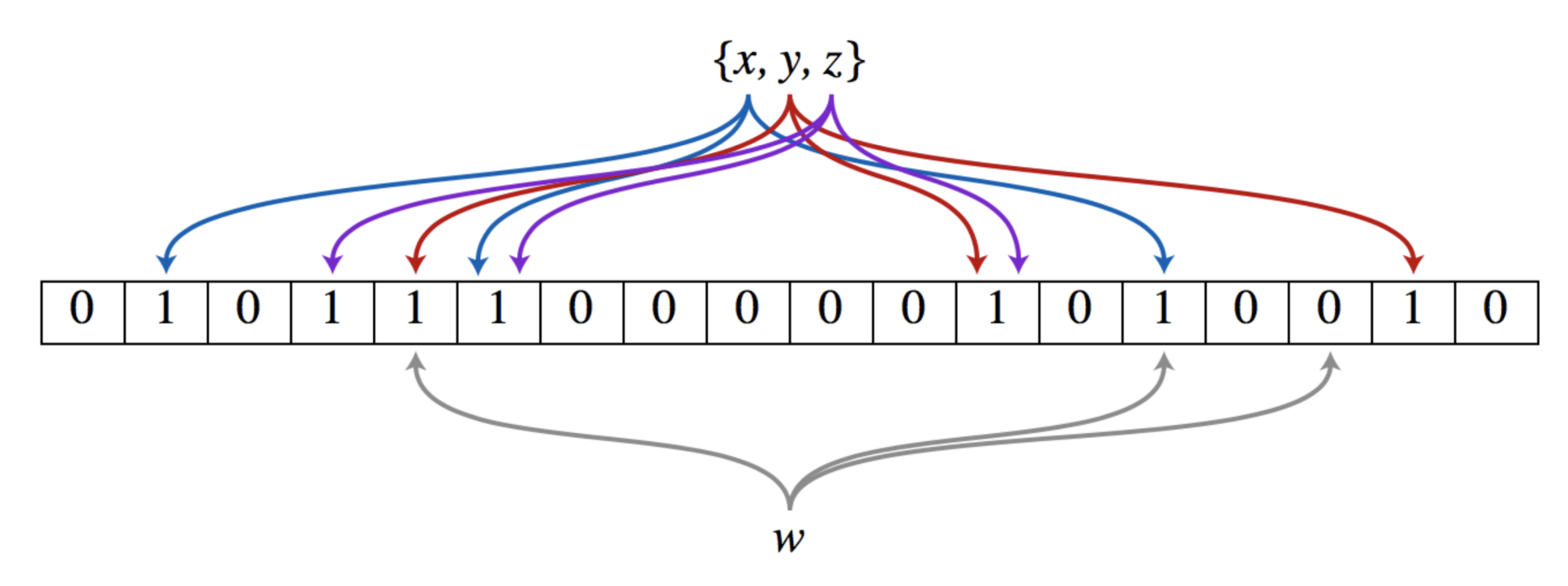
过滤器的作用:判断元素在还是不在。(如图查询 w 在不在集合中)
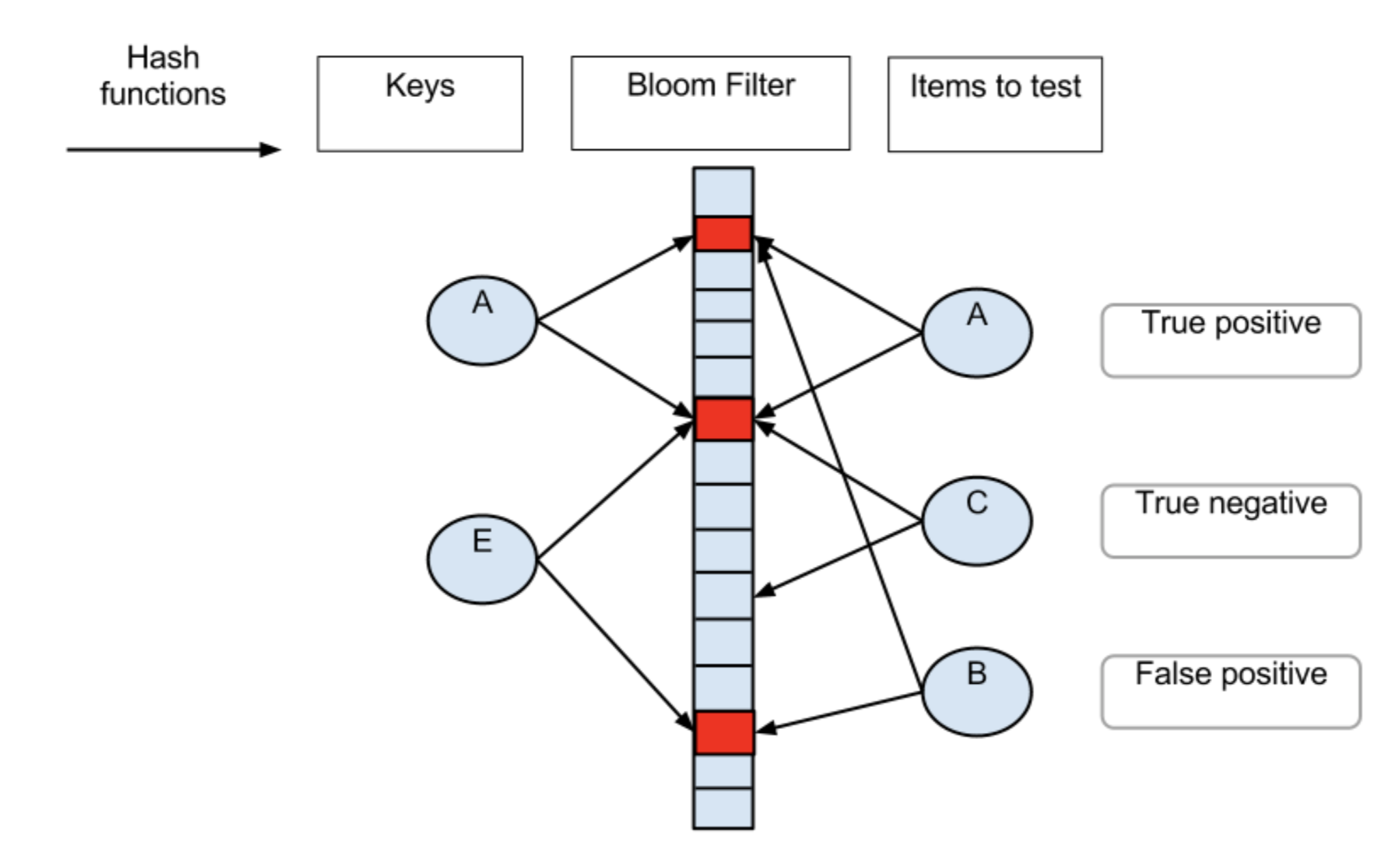
案例
1. ⽐特币网络
2. 分布式系统(Map-Reduce)
LRU Cache & Bloom Filter的更多相关文章
- 布隆过滤器(Bloom Filter)详解——基于多hash的概率查找思想
转自:http://www.cnblogs.com/haippy/archive/2012/07/13/2590351.html 布隆过滤器[1](Bloom Filter)是由布隆(Burton ...
- Bloom Filter 原理与应用
介绍 Bloom Filter是一种简单的节省空间的随机化的数据结构,支持用户查询的集合.一般我们使用STL的std::set, stdext::hash_set,std::set是用红黑树实现的,s ...
- 海量数据处理算法—Bloom Filter
海量数据处理算法—Bloom Filter 1. Bloom-Filter算法简介 Bloom-Filter,即布隆过滤器,1970年由Bloom中提出.它可以用于检索一个元素是否在一个集合中. Bl ...
- [转载] 布隆过滤器(Bloom Filter)详解
转载自http://www.cnblogs.com/haippy/archive/2012/07/13/2590351.html 布隆过滤器[1](Bloom Filter)是由布隆(Burton ...
- 布隆过滤器(Bloom Filter)详解
直观的说,bloom算法类似一个hash set,用来判断某个元素(key)是否在某个集合中.和一般的hash set不同的是,这个算法无需存储key的值,对于每个key,只需要k个比特位,每个存储一 ...
- Java Bloom filter几种实现比较
英文原始出处: Bloom filter for Scala, the fastest for JVM 本文介绍的是用Scala实现的Bloom filter. 源代码在github上.依照性能测试结 ...
- 大数据处理算法--Bloom Filter布隆过滤
1. Bloom-Filter算法简介 Bloom-Filter,即布隆过滤器,1970年由Bloom中提出.它可以用于检索一个元素是否在一个集合中. Bloom Filter(BF)是一种空间效率很 ...
- 【转】海量数据处理算法-Bloom Filter
1. Bloom-Filter算法简介 Bloom Filter(BF)是一种空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合.它是一个判断元素是否存在于 ...
- 浅谈布隆过滤器Bloom Filter
先从一道面试题开始: 给A,B两个文件,各存放50亿条URL,每条URL占用64字节,内存限制是4G,让你找出A,B文件共同的URL. 这个问题的本质在于判断一个元素是否在一个集合中.哈希表以O(1) ...
随机推荐
- py_二分查找
''' 查找:在一些数据元素中,通过一定的方法找出与关键字相同元素的过程, 列表查找:从列表中查找指定元素 输入:列表.待查找元素 输出:元素下标(未找到元素时一般返回None或-1) 内置列表查找函 ...
- 攻防世界——Misc新手练习区解题总结<2>(5-8题)
第五题gif: 下载附件后,解压得到这样一个文件 几经寻找无果后,发现是不是可以将gif中的黑白图片看做二进制的数字,进而进行解密 最后用二进制转文本得到flag 第六题掀桌子: 看起来是16进制的密 ...
- lidar激光雷达领域的分类
lidar领域可以按分为以下五方面: 激光雷达系统与装备 激光雷达系统与开发 激光雷达光源 激光雷达探测 多光谱激光雷达系统 单光子激光雷达系统 低成本RGB-D距离传感器 激光雷达元器件及装备等 激 ...
- 大厂运维必备技能:PB级数据仓库性能调优
摘要:众所周知,数据量大了之后,性能是大家关注的一点,所以我们在业务开发的时候,特别关注性能,做为一个架构师,必须对性能要了解,要懂.才能设计出高性能的业务系统. 一.GaussDB分布式架构 所谓集 ...
- 小程序开发-使用Loading和Toast提示框
小程序提示框 Loading提示框使用方式 1. 在wxml中作为组件使用 <loading hidden="{{hidden}}"> 加载中... </load ...
- Template DB MySQL学习总结
Zabbix 5.0下如何应用Template DB MySQL来监控MySQL数据库呢?下面简单整理一下如何配置.应用Zabbix下自带的模板Template DB MySQL.其实非常简单. Te ...
- [Oracle/SQL]找出id为0的科目考试成绩及格的学生名单的四种等效SQL语句
本文是受网文 <一次非常有意思的SQL优化经历:从30248.271s到0.001s>启发而产生的. 网文没讲创建表的数据过程,我帮他给出. 创建科目表及数据: CREATE TABLE ...
- SpringMVC-结果跳转方式
结果跳转方式 目录 结果跳转方式 1. ModelAndView 2. ServletAPI 3. SpringMVC实现 1. 无需视图解析器 2. 使用视图解析器 1. ModelAndView ...
- TP6.0 获取请求对象的五种方式
目录 1. 门面类 2. 依赖注入 3. 框架提供的基础控制器的 request 属性 4. request() 助手函数 5. app() 超级助手函数 think\Request.think\fa ...
- get、post请求方式在postman中使用步骤
1.get请求方式:不需要借助任何工具,在浏览器里面就可以发送请求,直接在浏览器里面输入访问 url?参数名=参数值 url?parma=abc&name=abcd 2.post请 ...